Il s'agit de rechercher si une chaîne de caractère ressemble à un modèle (un peu comme LIKE, mais en plus puissant)
>>-REGEXP_xxxx--(--origine--,--'modèle recherché'---------------->
>--+----------+--+-----------+--)----------------------------->
'-,--début-' '-,--option-'
| \w | tout caractère alpha ou numérique (pouvant constituer un mot) |
| \W | tout sauf caractère alpha ou numérique |
| \d | un chiffre |
| \D | tout sauf un chiffre |
| \s | caractère espace |
| \S | tout sauf un espace |
| [modèle] | tout caractère respectant le modèle |
| (suite) | regroupement (voir exemple après les opérateurs logiques) |
| . | tout caractère |
| ^ | début de ligne |
| $ | fin de ligne |
| \ | déspécialise le caractère suivant (\. pour chercher un point) |
| \N | caractère Unicode du nom indiqué (voir unicode.org) |
| \u | caractère Unicode de la valeur héxa indiquée (voir unicode.org) |
| \U | tout sauf le caractère Unicode indiqué |
| \p{propriété Unicode} (voir Unicode Categories ) |
\p{L} -> une lettre |
| \P{propriété Unicode} |
\P{L} -> tout sauf une lettre |
Quelques exemples de modèles
| [abc] | un a ou un b ou un c |
| [^abc] | tout sauf a, b et c |
| [C-M] | toute lettre comprise entre C et M |
| [a-z] | une minuscule |
| [A-Z] | une majuscule |
| [0-9] | un chiffre |
| [a-zA-Z0-9] | une minuscule ou une majuscule ou un chiffre |
| [a-z][A-Z][0-9] | une minuscule puis une majuscule puis un chiffre |
Opérateurs logiques (extrait)
| | | ou (a|b -> a ou b) |
| * | 0 à n fois l'expression précédente |
| + | 1 à n fois l'expression précédente |
| ? | 0 ou 1 fois l'expression précédente |
| {n} | n fois exactement l'expression précédente |
| {n,} | n fois ou plus l'expression précédente |
| {n,m} | entre n et m fois l'expression précédente |
| *? | 0 fois ou plus, le moins de fois possible |
| +? | 1 fois ou plus, le moins de fois possible |
| ?? | 0 ou 1 fois, 0 de préférence |
les parenthèses servent à regrouper des caractères ou des méta-caractères, particulièrement pour les opérateurs logiques
• abc|def signifie a,b,(c ou d), e, f
• (abc)|(def) signifie abc ou def
• abc+ est vrai pour abc, abcc, abccc, abccccccc
• (abc)+ est vrai pour abc, abcabc, abcabcabc, etc...
par exemple, cette expression
(\w+\.)+((org)|(com)|(gouv)|(fr))
permet de rechercher un suite de caractères alphanumériques \w+ , suivie d'un point \. , cette série étant présente éventuellement plusieurs fois (\w+\.)+
puis soit org, soit com, soit gouv, soit fr : (org)|(com)|(gouv)|(fr)
Pour découvrir pas à pas, je vous conseille Openclassroom (les exemples sont en PHP, mais c'est transposable)
| c | case sensitif |
| i | case insensitif |
| x | espaces ignorés |
| n | fin de ligne matérialisé par . |
| m | multi-ligne |
pour cette dernière option, par défaut ^ indique le début de la zone d'origine et $ la fin, sauf option m ou ^ indique le début de chaque ligne et $ la fin de chaque ligne.
une fin de ligne étant matérialisée par le couple "CR+LF" ou un point (.) si option n

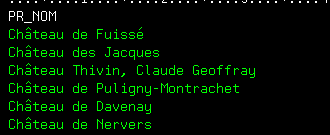




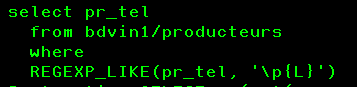


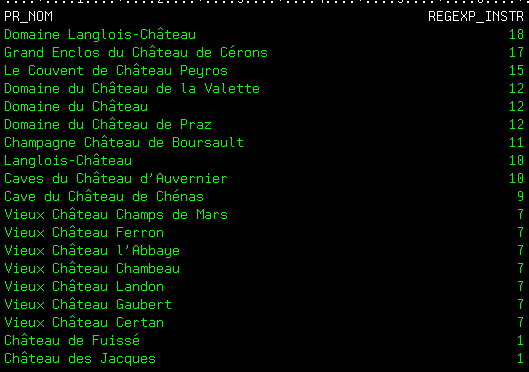

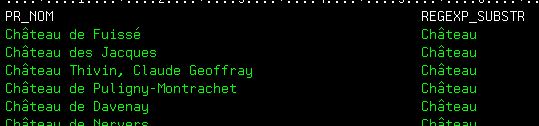


Toutes ces fonctions peuvent, bien sûr, être utilisées directement dans les programmes SQLRPG, SQLRPGLE (ou Cobol)