Binaire
La base même de l'informatique est la manipulation de données binaires, sur la base de bits
Le mot « bit » est la contraction des mots anglais binary digit, qui signifient « chiffre binaire », avec un jeu de mot sur bit, « petit morceau ».
Un bit ne peut prendre que deux valeurs. Selon le contexte, numérique, logique (voir algèbre de Boole), ou magnétique, on les appelle « zéro » et « un » ce qui équivaut respectivement à « faux » et « vrai », « ouvert » et « fermé », ...
Unités de bits Ordre de
grandeurSystème
internationalUnité Notation Valeur 1 bit bit 1 bit 103 kilobit kbit 103 bits 106 mégabit Mbit 106 bits 109 gigabit Gbit 109 bits 1012 térabit Tbit 1012 bits 1015 pétabit Pbit 1015 bits 1018 exabit Ebit 1018 bits 1021 zettabit Zbit 1021 bits 1024 yottabit Ybit 1024 bits Abréviations usuelles
les bits sont regroupés par groupe de 8, nommés Byte, Octet en Français.
pour des raisons de lisibilité, on donne la représentation hexadécimale de la partie gauche (hors texte) et de la partie droite (digits)sous la forme X'C1', suivant cette série de valeurs
Déc. héxa Binaire 0 0 0000 1 1 0001 2 2 0010 3 3 0011 4 4 0100 5 5 0101 6 6 0110 7 7 0111 8 8 1000 9 9 1001 10 A 1010 11 B 1011 12 C 1100 13 D 1101 14 E 1110 15 F 1111 le format numérique binaire ou BCD est basé sur cette table :
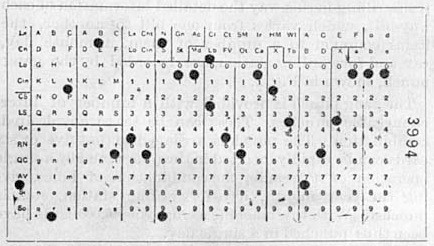
Pour les caractères, revenons sur la base de la codification qui est, à l'origine, la carte perforée (voir les cartes pour le Métier Jacquard)
Les cartes perforées IBM utilisaient le code Hollerith; ce code allait de 0 à 9 pour les codes numériques et des perforations hors texte 12, 11, 0. Le code hors texte servait avec les combinaisons des perforations numériques à représenter les codes alphabétiques. Ainsi le A était représenté par les perforations 12 et1 dans la la même colonne, le B 12 et 2, le C 12 et 3, le J 11 et 1, le R 11 et 9, le S 0 et 1, le Z 0 et 8.
Ces cartes étaient stockées par boîtes de 2 000, et le coin tronqué servait de repère pour les insérer dans le bon sens dans un chargeur de cartes ou pour les remettre à l'endroit quand la boîte tombait par terre.
Ce fut une étape notable dans la définition du codage de caractères (BCD, EBCDIC ou ASCII).
En 1960, IBM, Univac, Burrough, Honeywell et d'autres, se sont regroupés en consortium pour définir un standard commun
1963 : naissance de l'Extended Binary Coded Decimal Interchange Code ( EBCDIC) sur 8-bit.
Chaque caractère est noté sur deux caractères hexadécimaux X'C1' représentant un caractère (ici le A en notation EBCDIC)
Grille de codification
Jeu de caractères EBCDIC Quartet
hautQuartet bas ...0 ...1 ...2 ...3 ...4 ...5 ...6 ...7 ...8 ...9 ...A ...B ...C ...D ...E ...F 0... NUL
0000SOH
0001STX
0002ETX
0003ST
009CHT
0009SSA
0086DEL
007FEPA
0097RI
008DSS2
008EVT
000BFF
000CCR
000DSO
000ESI
000F1... DLE
0010DC1
0011DC2
0012DC3
0013OSC
009DLF
000ABS
0008ESA
0087CAN
0018EM
0019PU2
0092SS3
008FFS
001CGS
001DRS
001EUS
001F2... PAD
0080HOP
0081BPH
0082NBH
0083IND
0084NEL
0085ETB
0017ESC
001BHTS
0088HTJ
0089VTS
008APLD
008BPLU
008CENQ
0005ACK
0006BEL
00073... DCS
0090PU1
0091SYN
0016STS
0093CCH
0094MW
0095SPA
0096EOT
0004SOS
0098SGCI
0099SCI
009ACSI
009BDC4
0014NAK
0015PM
009ESUB
001A4... SP
0020NBSP
00A0¡
00A1¢
00A2£
00A3¤
00A4¥
00A5¦
00A6§
00A7¨
00A8©
00A9.
002E<
003C(
0028+
002B|
007C5... &
0026ª
00AA«
00AB¬
00ACSHY
00AD®
00AE¯
00AF°
00B0±
00B1²
00B2!
0021$
0024*
002A)
0029;
003B^
005E6... -
002D/
002F³
00B3´
00B4µ
00B5¶
00B6·
00B7¸
00B8¹
00B9º
00BA»
00BB,
002C%
0025_
005F>
003E?
003F7... ¼
00BC½
00BD¾
00BE¿
00BFÀ
00C0Á
00C1Â
00C2Ã
00C3Ä
00C4`
0060:
003A#
0023@
0040'
0027=
003D"
00228... Å
00C5a
0061b
0062c
0063d
0064e
0065f
0066g
0067h
0068i
0069Æ
00C6Ç
00C7È
00C8É
00C9Ê
00CAË
00CB9... Ì
00CCj
006Ak
006Bl
006Cm
006Dn
006Eo
006Fp
0070q
0071r
0072Í
00CDÎ
00CEÏ
00CFÐ
00D0Ñ
00D1Ò
00D2A... Ó
00D3~
007Es
0073t
0074u
0075v
0076w
0077x
0078y
0079z
007AÔ
00D4Õ
00D5Ö
00D6[
005B×
00D7Ø
00D8B... Ù
00D9Ú
00DAÛ
00DBÜ
00DCÝ
00DDÞ
00DEß
00DFà
00E0á
00E1â
00E2ã
00E3ä
00E4å
00E5]
005Dæ
00E6ç
00E7C... {
007BA
0041B
0042C
0043D
0044E
0045F
0046G
0047H
0048I
0049è
00E8é
00E9ê
00EAë
00EBì
00ECí
00EDD... }
007DJ
004AK
004BL
004CM
004DN
004EO
004FP
0050Q
0051R
0052î
00EEï
00EFð
00F0ñ
00F1ò
00F2ó
00F3E... \
005Cô
00F4S
0053T
0054U
0055V
0056W
0057X
0058Y
0059Z
005Aõ
00F5ö
00F6÷
00F7ø
00F8ù
00F9ú
00FAF... 0
00301
00312
00323
00334
00345
00356
00367
00378
00389
0039û
00FBü
00FCý
00FDþ
00FEÿ
00FFAPC
009F
La grille de codification varie d'un pays à l'autre, même si elle contient des caractères invariants
Page de code 297 (variante de l’EBCDIC pour la France) Quartet
hautQuartet bas ...0 ...1 ...2 ...3 ...4 ...5 ...6 ...7 ...8 ...9 ...A ...B ...C ...D ...E ...F 0... NUL
0000SOH
0001STX
0002ETX
0003ST
009CHT
0009SSA
0086DEL
007FEPA
0097RI
008DSS2
008EVT
000BFF
000CCR
000DSO
000ESI
000F1... DLE
0010DC1
0011DC2
0012DC3
0013OSC
009DLF
000ABS
0008ESA
0087CAN
0018EM
0019PU2
0092SS3
008FFS
001CGS
001DRS
001EUS
001F2... PAD
0080HOP
0081BPH
0082NBH
0083IND
0084NEL
0085ETB
0017ESC
001BHTS
0088HTJ
0089VTS
008APLD
008BPLU
008CENQ
0005ACK
0006BEL
00073... DCS
0090PU1
0091SYN
0016STS
0093CCH
0094MW
0095SPA
0096EOT
0004SOS
0098SGCI
0099SCI
009ACSI
009BDC4
0014NAK
0015PM
009ESUB
001A4... SP
0020NBSP
00A0â
00E2ä
00E4@
0040á
00E1ã
00E3å
00E5\
005Cñ
00F1°
00B0.
002E<
003C(
0028+
002B!
00215... &
0026{
007Bê
00EAë
00EB}
007Dí
00EDî
00EEï
00EFì
00ECß
00DF§
00A7$
0024*
002A)
0029;
003B^
005B6... -
002D/
002FÂ
00C2Ä
00C4À
00C0Á
00C1Ã
00C3Å
00C5Ç
00C7Ñ
00D1ù
00F9,
002C%
0025_
005F>
003E?
003F7... ø
00F8É
00C9Ê
00CAË
00CBÈ
00C8Í
00CDÎ
00CEÏ
00CFÌ
00CCµ
00B5:
003A£
00A3à
00E0'
0027=
003D"
00228... Ø
00D8a
0061b
0062c
0063d
0064e
0065f
0066g
0067h
0068i
0069«
00AB»
00BBð
00F0ý
00FDþ
00FE±
00B19... [
005Bj
006Ak
006Bl
006Cm
006Dn
006Eo
006Fp
0070q
0071r
0072ª
00AAº
00BAæ
00E6¸
00B8Æ
00C6¤
00A4A... `
0060¨
00A8s
0073t
0074u
0075v
0076w
0077x
0078y
0079z
007A¡
00A1¿
00BFÐ
00D0Ý
00DDÞ
00DE®
00AEB... ¢
00A2#
0023¥
00A5·
00B7©
00A9]
005D¶
00B6¼
00BC½
00BD¾
00BE¬
00AC|
007C¯
00AF~
007E´
00B4×
00D7C... é
00E9A
0041B
0042C
0043D
0044E
0045F
0046G
0047H
0048I
0049SHY
00ADô
00F4ö
00F6ò
00F2ó
00F3õ
00F5D... è
00E8J
004AK
004BL
004CM
004DN
004EO
004FP
0050Q
0051R
0052¹
00B9û
00FBü
00FC¦
00A6ú
00FAÿ
00FFE... ç
00E7÷
00F7S
0053T
0054U
0055V
0056W
0057X
0058Y
0059Z
005A²
00B2Ô
00D4Ö
00D6Ò
00D2Ó
00D3Õ
00D5F... 0
00301
00312
00323
00334
00345
00356
00367
00378
00389
0039³
00B3Û
00DBÜ
00DCÙ
00D9Ú
00DAAPC
009F
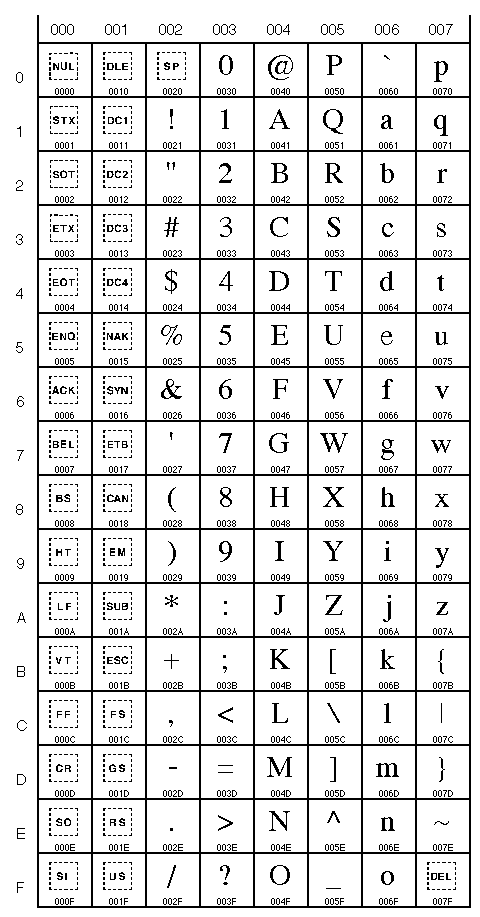
Parallèlement les autres système utilisent un système de codification différent : ASCII (American Standard Code for Information Interchange )
On peut aussi présenter la table des caractères ASCII sous cette forme condensée
Il arrive souvent d'utiliser les codes de 128 à 255 pour les accents, mais comme dans l'EBCDIC, ces codes sont différents d'un pays à l'autre !
Pas pratique pour échanger des documents.Il faut donc trouver un code plus pratique, plus universel. Il existe: c'est l'UNICODE.
Le standard Unicode est constitué d'un répertoire de plus de 110 000 caractères couvrant 100 écritures, d'un ensemble de tableaux de codes pour référence visuelle (braille), d'une méthode de codage et de plusieurs codages de caractères standard, d'une énumération des propriétés de caractère (lettres majuscules, minuscules, symboles, ponctuation, etc.) d'un ensemble de fichiers de référence des données informatiques, et d'un certain nombre d'éléments liés, tels que des règles de normalisation, de décomposition, de tri, de rendu et d'ordre d'affichage bidirectionnel (pour l'affichage correct de texte contenant à la fois des caractères d'écritures droite à gauche, comme l'arabe et l'hébreu, et de gauche à droite).En pratique, Unicode reprend intégralement la norme ISO/CEI 10646, puisque cette dernière ne normalise que les caractères individuels en leur assignant un nom et un numéro normatif (appelé point de code) et une description informative très limitée.
Voici une toute petite partie des tables UNICODE (les nombres sont présentés en notation hexadécimal):
Caractères Unicode
0000 à 007F (0 à 127)
(caractères latins)Caractères Unicode
0080 à 00FF (128 à 255)
(caractères latins, dont accentués)Caractères Unicode
0900 à 097F (2304 à 2431)
(caractères devanagari/sanskrit)Caractères Unicode
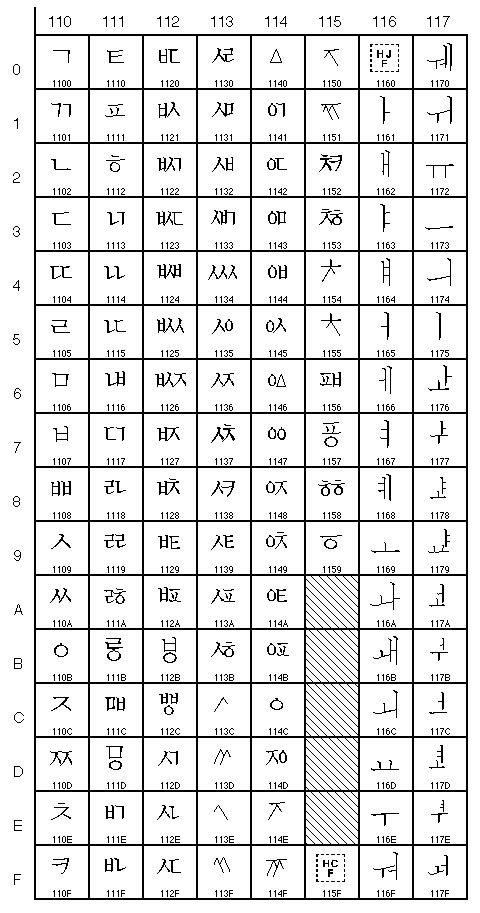
1100 à 117F (4352 à 4479)
(caractères hangul jamo/coréen)Vous pourrez trouver plus d'informations sur l'UNICODE sur http://www.unicode.org.
Dans la table des caractères Unicode on ajoute un index numérique associé à chaque caractère. Notons bien qu’il ne s’agit pas d’une représentation en mémoire, juste d’un nombre entier, appelé point de code. L'espace de codage de ces nombres est divisé en 17 zones de 65 536 points de codes. Ces zones sont appelées plans.
Le point de code est noté U+xxxx où xxxx est en hexadécimal, et comporte 4 à 6 chiffres :
- 4 chiffres pour le premier plan, appelé plan multilingue de base (donc entre U+0000 et U+FFFF);
- 5 chiffres pour les 15 plans suivants (entre U+10000 et U+FFFFF);
- 6 chiffres pour le dernier plan (entre U+100000 et U+10FFFF).
Ainsi, le caractère nommé « Lettre majuscule latine c cédille » a un index de U+00C7.
Il appartient au premier plan.
En principe toutes les positions de code entre U+0000 et U+10FFFF sont disponibles, mais certains intervalles sont perpétuellement réservés à des usages particuliers, notamment une zone d'indirection exclue pour permettre le codage UTF-16 (cf. ci-dessous), les zones à usage privé et quelques régions (par exemple U+FFFE ou U+FFFF) contenant des non-caractères dont l'usage est interdit dans un échange de données conforme. Les autres positions de code sont soit déjà assignées à des caractères, soit réservées pour normalisation future.
Unicode 6 a 7 catégories de caractères:
- Letter (L) Mark (M)
- Number (N) Punctuation (P)
- Symbol (S) Separator (Z)
- Other (C): caractères de contrôle , etc…
UTF-8
Techniquement, il s’agit de coder les caractères Unicode sous forme de séquences de un à quatre codets d’un octet chacun. La norme Unicode définit entre autres un ensemble (ou répertoire) de caractères. Chaque caractère est repéré dans cet ensemble par un index entier aussi appelé « point de code ». Par exemple le caractère « € » (euro) est le 8365e caractère du répertoire Unicode, son index, ou point de code, est donc 8364 (on commence à compter à partir de 0).
Le répertoire Unicode peut contenir plus d’un million de caractères, ce qui est bien trop grand pour être codé par un seul octet (limité à des valeurs entre 0 et 255). La norme Unicode définit donc des méthodes standardisées pour coder et stocker cet index sous forme de séquence d’octets : UTF-8 est l'une d’entre elles, avec UTF-16, UTF-32 et leurs différentes variantes.
La principale caractéristique d’UTF-8 est qu’elle est rétro-compatible avec la norme ASCII, c’est-à-dire que tout caractère ASCII se code en UTF-8 sous forme d’un unique octet, identique au code ASCII. Par exemple « A » (A majuscule) a pour code ASCII 65 et se code en UTF-8 par l'octet 65. Chaque caractère dont le point de code est supérieur à 127 (caractère non ASCII) se code sur 2 à 4 octets. Le caractère « € » (euro) se code par exemple sur 3 octets : 226, 130, et 172.
UTF-16
L’UTF-16 est un bon compromis lorsque la place mémoire n’est pas trop restreinte, car la grande majorité des caractères Unicode assignés pour les écritures des langues modernes (dont les caractères les plus fréquemment utilisés) le sont dans le plan multilingue de base et peuvent donc être représentés sur 16 bits.
Codage UTF-16hi \ lo
DC00
DC01
…
DFFF
D800
10000
10001
…
103FF
D801
10400
10401
…
107FF
:
/
/
...
/
DBFF
10FC00
10FC01
…
10FFFF
Les points de code des seize plans supplémentaires nécessitent une transformation sur deux mots de 16 bits :
- on soustrait 0x10000 au point de code, ce qui laisse un nombre de 20 bits dans l'étendue 0..0xFFFFF
- les 10 bits de poids fort (un nombre entre 0 et 0x3FF) sont additionnés à 0xD800, et donnent la première unité de code dans la demi-zone haute (0xD800..0xDBFF)
- les 10 bits de poids faible (un nombre entre 0 et 0x3FF) sont additionnés à 0xDC00, et donnent la seconde unité de code dans la demi-zone basse (0xDC00..0xDFFF)
En résumé, il y a 2 plages réservées :Haute : X'D800' – X'DBFF' = 4 * 256 combinaisonsBasse : X'DC00' – X'DFFF' = 4 * 256 combinaisonssoit 1024 * 1024 caractères supplémentaires
codage sur 2 octets pour les 63488 premiers caractères (comme UCS-2 ci-dessous)codage sur 4 octets pour les autres caractères (subrogate characters)
UCS-2 est la version simplifié de UTF-16 ne prévoyant pas les indirections et ne permet donc que de stocker des caractères appartenant au premier plan.(obsolète aujourd’hui)
UTF-32L’UTF-32 est utilisé lorsque la place mémoire n’est pas un problème et que l’on a besoin d’avoir accès à des caractères de manière directe et sans changement de taille (hiéroglyphes).
Sur IBM i , les différentes versions Unicode sont représentées par un code page
UCS-2 -> CCSID(13488)
UTF-8 -> CCSID(1208)
UTF-16 -> CCSID(1200)
UTF-32 -> (non implémentée)Il faut parallèlement avoir installé la bibliothèque ICU (option 39 du système)
Voir http://unicodebook.readthedocs.org/en/latest/unicode_encodings.html
Formats numériques
sur 1 octet compris entre 0 et 255 (x'FF)
sur 2 octets compris entre 0 et 65535 (x'FFFF')
sur 4 octets
compris entre 0 et 4294967295
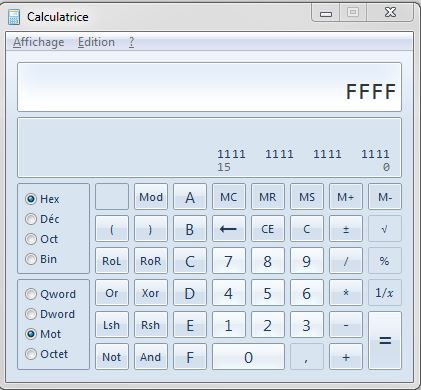
Il s'agit précisément du binaire non signé, pour pouvoir représenter la notion de signe (+/-) le bit le plus à gauche est utilisé
0 ce chiffre est positif -> maxi x'7FFF' (0111111) soit 32767
1 ce chiffre est négatif, il faut faire un complément à 2 pour avoir la valeur -> mini X'8000' soit -32768
Au début on a utilisé le complément à 1 (inversion de bits) mais cela générait +0 (X'0000') et -0(X'FFFF)
La technique du complément à 2, consiste à réaliser un complément à un de la valeur puis d'ajouter 1 au résultat.Par exemple pour obtenir –1 (X'FFFF') :
00000001 codage de 1 en binaire
11111110 complément à un
11111111 on ajoute 1Par exemple pour calculer x'8001' (-32766)
10000010 codage en binaire
10000001 on retranche 1
01111110 complément à un = 32766
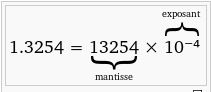
Les calculs en virgule flottante sont pratiques, mais présentent divers désagréments, notamment :
Ce qui est fait que ce format est peu utilisé dans le monde de la gestion, sur gros systèmes IBM.
Format numérique à position de virgule fixe, proche de la représentation caractère EBCDIC, la partie Hors texte du dernier octet indique le signe
F1F2F3F7 = 1237
F1F2F3D7 = -1237
F1F2F3C7 = +1237
le COBOL gros systèmes reconnaissait le + numérique et le "neutre", sur IBM i (AS/400), seul existe 1237 qui vaut +1237 et -1237
Format numérique proche du numérique étendu (virgule fixe), mais on cherche à optimiser le stockage, pour cela les parties gauche (hors-texte) de chaque octet est abandonnée, sauf le derneir indiquant le signe qui est placé à droite :
1237F = 1237
1237D = -1237
C'est le format par défaut de DB2 (DEC ou décimal) et du compilateur RPG sur IBM i.