un critère de tri particulier (index)
un format d'enregistrement particulier (sélection de
lignes, reformatage des colonnes, jointure)
Historiquement les fichiers sont créés avec un langage
propriétaire : SDD (ou DDS en Anglais) :
######################## ## FICHIER PHYSIQUE ## ######################## |
######################## ## FICHIER PHYSIQUE ## ######################## |
######################## ## FICHIER PHYSIQUE ## ######################## |
######################## ## FICHIER PHYSIQUE ## ######################## |
######################## ## FICHIER PHYSIQUE ## ######################## |
######################## ## FICHIER PHYSIQUE ## ######################## MOTS-CLE COMPLEMENTAIRES. |
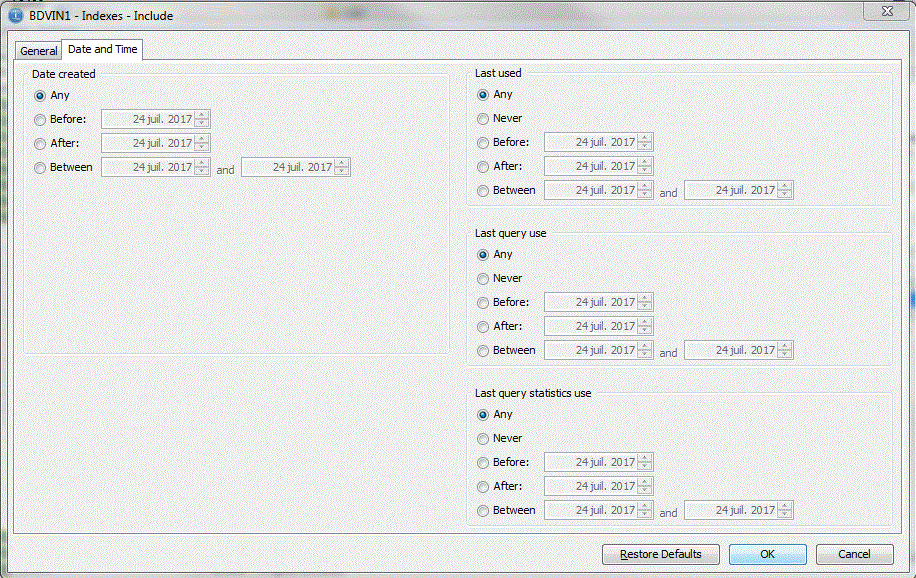
5) NOUVEAUTES V2R11
VARLEN variable à lg variable
|
######################## ## FICHIER PHYSIQUE ## ######################## |
| Exemple :
|
Pour éditer votre membre source, utilisez RDI
Il est conseillé d'utiliser la fonction Répertoire pour la définition de votre base de données. |
|
VUE D'ENSEMBLE. ________ ------------ DSPF REPERTOIRE <________> ! déf. ! ! déf. ! ---------------> ! formats ! ! unique ! ------------ ------------ ! zones ! ! / / !---- <________> ---! ! ------------ PRTF ___v____ _____v___ ! ---------------- PF1 <________> PF2 <_________> !--------> ! déf. ----/ <<<<<! déf. !>> <<! déf. !>>> ! formats/ << !--------! >> << !---------! >>>> !-------/ << ! données! ><< ! données ! >> >> << <________> >< <_________> >> >>>>>>>>>>>>>>> LF11 __v_____ ____v____ __v_____ ___v_____ <________> LFJx <_________> LF21 <________> LF22 <_________> ! déf. ! ! déf jonc! ! déf. ! ! déf. ! !--------! !---------! !--------! !---------! ! index ! ! index ! ! index ! ! index ! <________> <_________> <________> <_________> |
Aujourd'hui , SQL est de plus en plus utilisé :
Exemple de script : |
Outils de conception de la base.
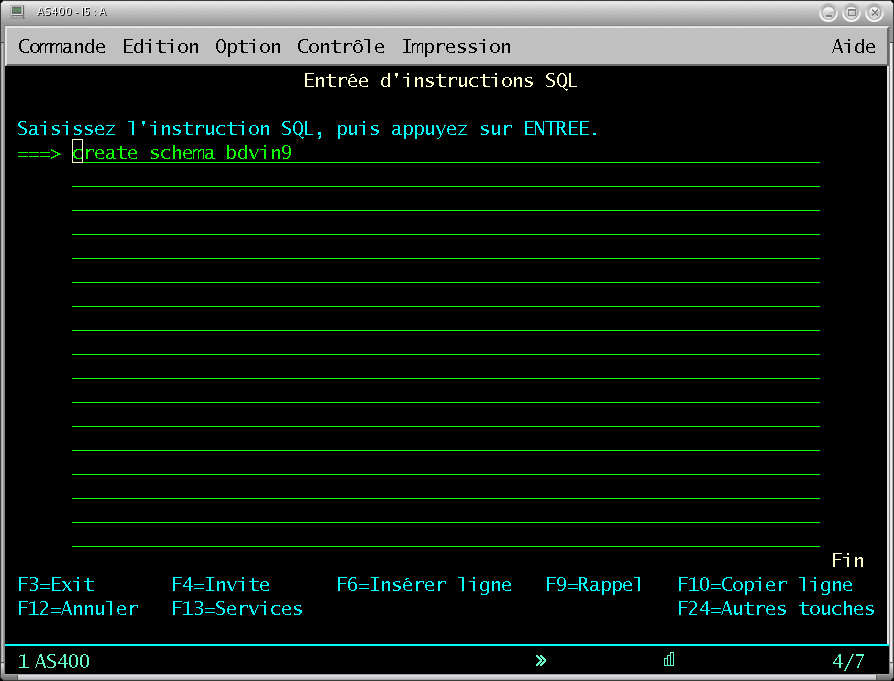
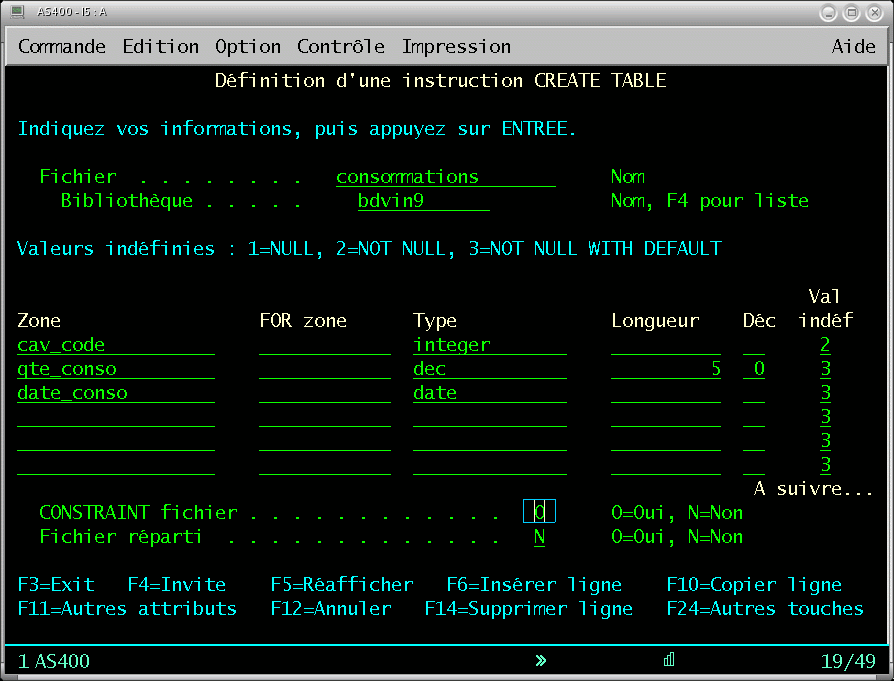
les paramètres sont renseignés différemment [SIZE(*nomax) REUSEDLT(*yes) et MAXMBRS(1) ]
|
- CPYF copie de fichiers |
|
QUERY/400, est un outils (orienté
utilisateurs) d'extraction de données.
Vos requêtes sont mémorisées dans
des objets *QRYDFN
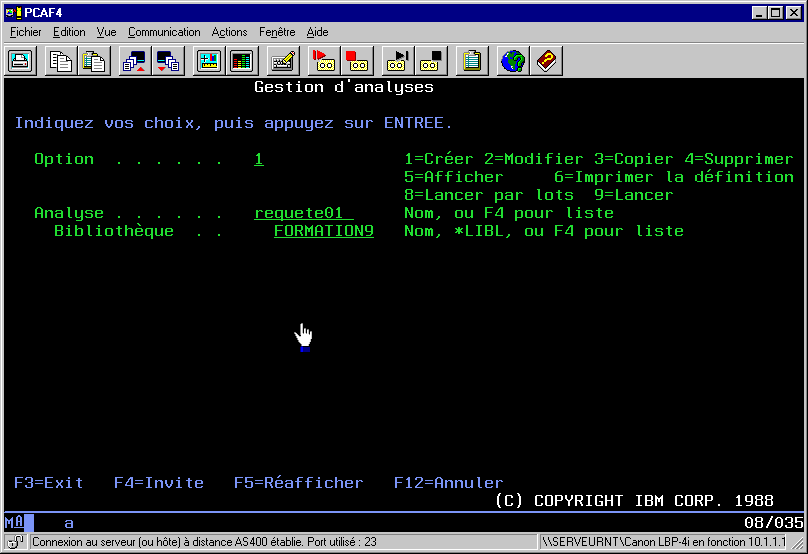
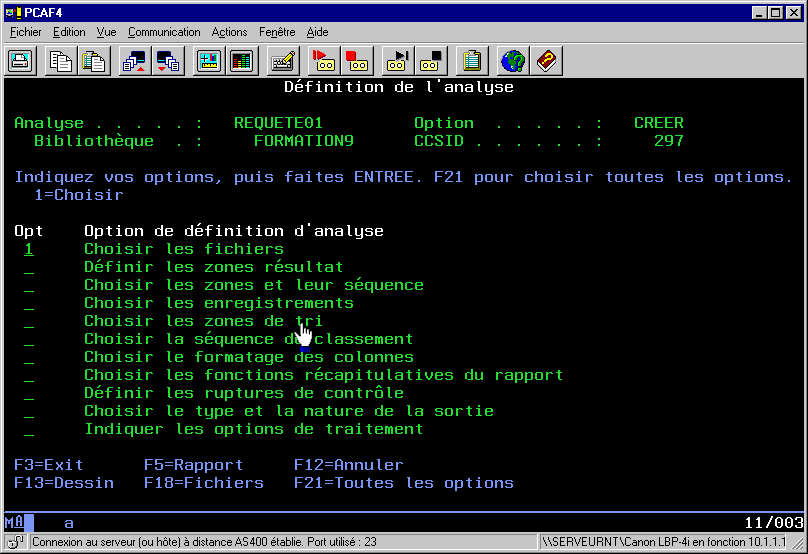
voici, les différentes étapes de QUERY :
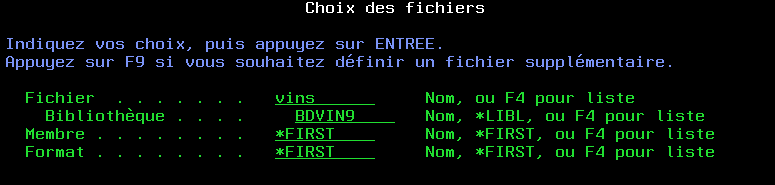
la première vous permet de choisir un fichier
:
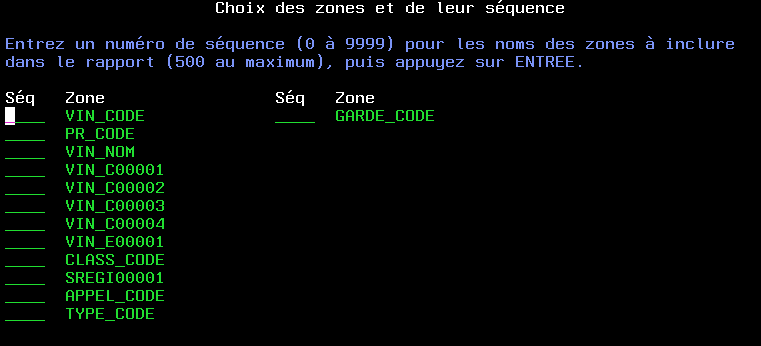
Vous pourrez aussi choisir les champs à
afficher sur l'état (la numérotation indique l'ordre sur
la ligne d'impression)
et bien sûr, choisir les enregistrements
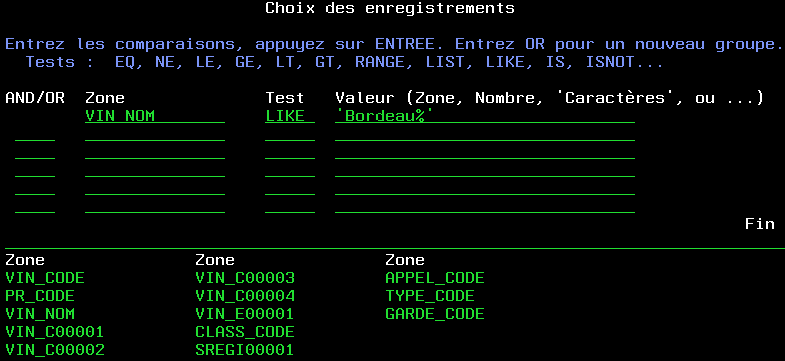
Vous pourrez aussi, faire des totaux (sommes,
moyennes, comptage, ...)
indiquer des ruptures afin d'imprimer et de remettre
à zéro, ces totaux.
et définir des options d'impression (mise en
page, taille d'une page, etc...)
|
|
|
|
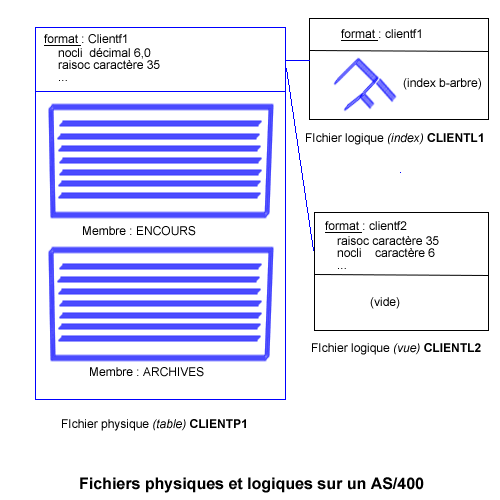
REGARDONS MAINTENANT LE MEME EXEMPLE MAIS CETTE FOIS-CI AVEC UN DESSIN D'ENREGISTREMENT DIFFERENT DU FICHIER PHYSIQUE. |
|
|
Exemple : Soit les fichiers physiques suivants :
Source :
* JDFTVAL permet une jointure "externe"
|
Rappel sur des fonctions de DB2 for i
récentes et donc, parfois, sous-employées :
Remarques : ce n'est supporté QUE par le compilateur ILE/RPG-IV ET SQL
Remarques : le support de la valeur nulle est disponible pour ILE/RPG-IV Version 3.70.
(elles sont dans de nombreux cas plus puissantes
que les fichiers logiques SDD):
On admet des vues portant
sur des vues, des calculs, des
sélections complexes, la clause GROUP BY
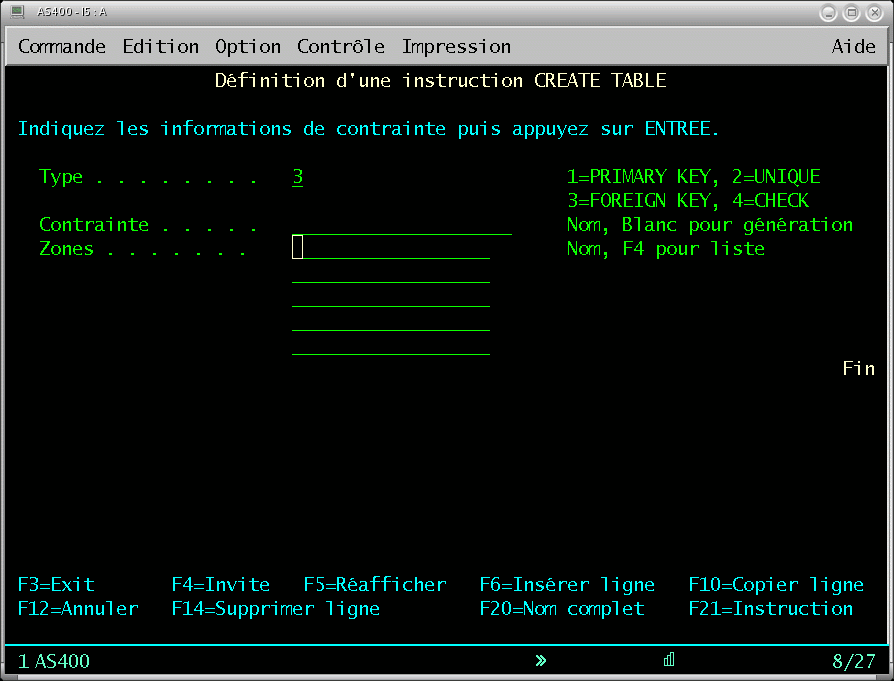
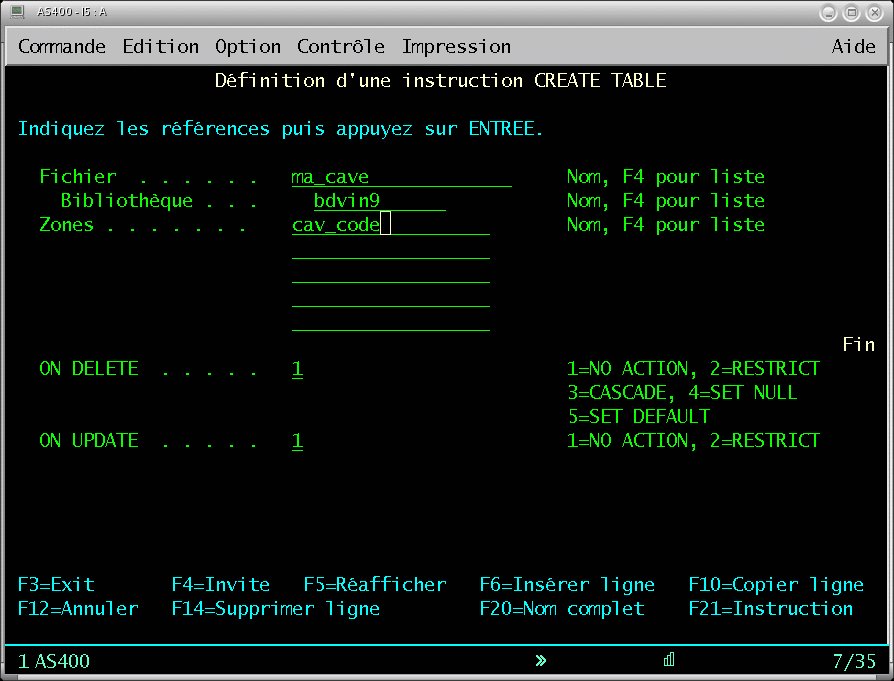
contrainte d'entité :
intégrité référentielle
une clé étrangère doit se rapporter à une clé primaire d'une table déclarée parente.
(On ne peut pas insérer une commande se rapportant à un client non enregistré dans le fichier client)
il est alors possible de préciser comment
gérer l'intégrité dans le sens parent/enfant.
C'est à dire que faire si l'on tente de supprimer un client
ayant des commandes.
l'utilisation du commit est fortement
conseillée, et dans certains cas, obligatoire.(
particulièrement la suppression en cascade)
|
|
|
|
|
V4R20 : |
|
|
vérification de type comp, range, values avec des constantes ou avec d'autres colonnes du même fichier.
quelques exemples
En version 7.2, Nouvelle clause VIOLATION sur les Check constraint :
ON INSERT VIOLATION SET column-name = DEFAULT
L'erreur n'est pas signalée, la valeur par défaut est insérée
ON UPDATE VIOLATION PRESERVE column-name
L'erreur n'est pas signalée, la valeur précédente est conservée
Triggers
Associé à une action base de donnée
(on associe un pgm "maison" à l'action «insérer un client» ou «modifier un client» ou «supprimer un client».)
Remarques :
depuis la V3R70 un trigger peut modifier l'enregistrement base de données qu'il a recu en tant que paramètre.
|
En V5R10, les triggers peuvent être écrits en PL/SQL ils peuvent être liés à une colonne (300 Triggers possibles par fichier) |
Les triggers peuvent être écrit
dans n'importe quel langage
C, RPG III ou IV ,COBOL,
depuis la V5R10 enPL/SQL
exemple :
ou bien CREATE TRIGGER ...c'est le dernier paramètre qui autorise la mise à jour de l'enregistrement
DB2/400 admet maintenant la jonction norme SQL-92
C'est à dire SELECT * FROM CLIENT JOIN COMMANDE cde ON client.NOCLI = cde.NOCLI [WHERE ...]
Ce qui autorise les jointures externes :
(LEFT OUTER JOIN, c.a.d, tous les clients qu'ils possèdent ou non des commandes)
et les différences :
(EXCEPTION JOIN, c.a.d, les clients SANS
commande))
|
V5R10, le RIGHT OUTER JOIN est
admis
|
EN V5r30 la clause USING peut être utilisée : select * from vins join
producteurs using(pr_code)
ainsi que les opérateurs EXCEPT et INTERSECT
|
Possibilité de travailler avec une base (DB2) éloignée, par CONNECT TO (le nom est paramétré dans WRKRDBDIRE)
Two PHASES COMMIT
il est possible d'inclure dans une même transaction des fichiers se trouvant sur des bases de données différentes (dans le cadre de DRDA)
Exemple :
connect to base 1
moins 100 dans la quantité pour le produit A1
connect to base 2
plus 100 dans la quantité pour le produit A1
Commit
la phase de validation sera
réalisée en deux temps :
•demande de préparation à la
validation (prepared wave)
•validation effective (commited wave)
Dénomination en trois partie
Si l'on admet une connexion automatique (SSO ou un identifiant enregistré par ADDSVRAUTE) alors on peut utiliser
SELECT * from AUTREBASE.schéma.table |
Un ensemble d'actions base de données devant être réalisées sur une base distante peut être demandé par l'appel à une procédure (un programme) stockée sur le serveur distant.
Cela normalise un ordre CALL (en tant qu'ordre SQL), avec passage de paramètres et ce, en étant affranchi de l'OS du serveur.
Sur l'AS/400 les procédures cataloguées peuvent être écrites dans n'importe quel langage et leur déclaration est optionnelle.
V4R20, on reconnait le PL/SQL pour
l'écriture des procédures cataloguées.
V5R10 le compilateur C n'est plus obligatoire.
exemple :
Create Procedure bib/p1
(in nomatin DEC(6, 0),
in newcoef DEC(3, 0),
out codert int)
language SQL
P1:
Begin
Declare coeflu DEC(3, 0);
Declare Exit handler for SQLExecption Set codert=SQLCODE;
Select coef from personp1 into coeflu where nomat = nomatin;
if newcoef > coeflu then
update personp1 set coef = newcoef where
nomat = nomatin;
end if;
End
L'ordre ALTER TABLE permet maintenant de modifier la structure d'une table, dynamiquement :
Pour les programmes réalisant leur entrés/sorties à l'aide de SQL, cette seule action suffit, pour les autres il faut recompiler.
Sous Sélections
la notion de sous-sélection permettait de mettre un ordre SELECT dans la
clause WHERE d'un ordre SQL.
SUPPRIMER les clients sans commande :
supprimer les commandes quand la clause SELECT ne trouve pas de ligne (NOT EXISTS) ayant le n° de client lu dans le fichier client (C.nocli) |
Cette synatxe est maintenant acceptée dans la clause SET de UPDATE
UPDATE command C set priha = (select pritarif from article |
- Les sous selections sous admises aussi dans l'ordres SELECT
• Historiquement dans la clause WHERE
• Depuis la V4R40 dans le from
• Depuis la V5R10 dans la liste des colonnes
Select codart , qte * prix as montant, (select sum(qte * prix) from commandes where
famcod = c1.famcod) as totfam
from commandes c1
on peut indiquer un ordre SELECT dans la clause from d'un ordre SELECT
ou bien déclarer juste avant le SELECT une "vue temporaire" par WITH.
exemple , soit un fichier des cours, chaque cours est enregistré sous
un module de cours.
je veux le nombre de cours du module qui en a le plus.
| with temp as
(select count(*) as nbr from Fmodules group by codmodul)
select max(nbr) from temp |
Deux nouveaux types de données apparaissent en V4R40
• les types de données LARGES (jusqu'à 15 Mo
en V4, 2Go en V5)
• les DATALINK (ou URL)
1/ les LOB (Large Object)
ils sont de trois sortes
+ CLOB Character Large Object, supportent la notion de CCSID
+ DBCLOB Double Byte CLOB, idem CLOB mais en DBCS
+ BLOB Binary Large Object, binaires, donc prévus pour les images
la video, etc...
ex: CREATE TABLE VOITURE (image as BLOB 2M)
2/ les types de colonne DATA LINK
il s'agit de colonnes dont le contenu référence un fichier externe.
a/ le nom du fichier est donné sous forme d'URL
b/ le fichier reste à l'exterieur de la base de données
(utilisable par votre serveur WEB, par exemple)
c/ le serveur Base de données peut vous fournir un contrôle
de type:
- je vérifie que le fichier existe lors de l'insertion
- je vérifie la présence du fichier tant qu'il est
référencé dans la base.
vous devez lancer un serveur TCP/IP appelé DLFM
(DATA LINK FILE MANAGER), pour gérer ces contrôles temps réel.
ET ENFIN, orientation objets (V4R40)
CREATE FUNCTION AF4TEST/N8_DATE (DEC(8 , 0) )
RETURNS DATE
EXTERNAL NAME 'AF4TEST/DT_SQL(N8_DATE)'
(1)
PARAMETER STYLE GENERAL (2)
RETURNS NULL ON NULL INPUT ; (3)
(1) fait référence à N8_DATE dans DT_SQL
(2) le passage de paramètres se fait sans gestion de la val. nulle
(3) la fonction retourne nulle si un des argument est nul (il n'y aura pas d'appel)
Vous pouvez aussi créer des fonctions à l'aide du PL/SQL
CREATE FUNCTION BDVIN0.TODATE ( |
V5R20 SQL admet maintenant
les fonctions définies par l'utilisateur [UDF] de type TABLE
utilisable par SELECT * FROM TABLE (nom-fonction() ) AS alias
une fonction est un programme ou une procédure dans un programme de service
enregistré(e) dans les catalogues SQL par CREATE FUNCTION.
par exemple :
CREATE FUNCTION QGPL/TBLIBL ( )
RETURNS TABLE (LIB CHAR(10) , LIBTEXT CHAR(50) )
EXTERNAL NAME 'AF4TEST/TBLIBL
PARAMETER STYLE DB2SQL
DISALLOW PARALLEL ;
-- DISALLOW PARRALLEL est obligatoire pour une fonction table
Utilisation
----------- select * from TABLE( qgpl/tblibl() ) as libl
where libtext like '%AF400%'
D'ailleur IBM écrit de plus en plus de fonctions TABLE pour accèder à des informations système (IBM i services)
Les versions 5.2 et 5.3 amènent aussi les clés
générées automatiquement
La version 7 propose le Type XML
CREATE SCHEMA POSAMPLE; |
Les champs de type XML peuvent faire jusqu'à 2 Go, la totalité d'une ligne ne peut pas dépasser 3,5 Go.
Puis insertion de données,
INSERT INTO Customer (Cid, Info) VALUES (1000, |
Vous pouvez aussi utiliser les fonctions SQL, nouvelles en V7 :
| GET_BLOB_FROM_FILE(chemin , option) | retourne un BLOB LOCATOR, sans conversion du CCSID |
| GET_CLOB_FROM_FILE(chemin , option) | retourne un CLOB LOCATOR dans le CCSID du job |
| GET_DBCLOB_FROM_FILE(chemin , option) | retourne un DBCLOB LOCATOR dans le CCSID DBCS par défaut |
| GET_XML_FILE(chemin) | retourne un BLOB LOCATOR en UTF-8, si ce dernier ne possède pas de déclaration XML la fonction l'ajoute. |
le document doit être bien formé, sinon vous recevrez SQ20398
Il est possible d'associer un schéma XSD par la procédure XRS_REGISTER
la validation étant réalisée ensuite par XMLVALIDATE, SQL20399, signalant un flux XML non valide
INSERT INTO POSAMPLE.Customer(Cid, Info) VALUES (1004, |
le schéma pouvant contenir des annotations propres à DB2 (Ajouter l'espace de nommage db2-xdb), permettant un "mapping" xml -> relationnel,
c'est à dire une décomposition des données XML dans une ou des tables par la procédure XDBDECOMPXML
SQL admet aussi à cette version (V7) de nouvelles fonctions pour produire du XML
A l'inverse la nouvelle fonction XMLTABLE "parse" le flux XML et permet de réaliser un Select sur celui-ci.
Soit les données suivantes :
INSERT INTO Customer (Cid, Info) VALUES (1000, |
SELECT X.NOM, X.RUE, X.VILLE FROM Customer,
XMLTABLE ('$c/customerinfo' passing INFO as "c"
COLUMNS
NOM CHAR(30) PATH 'name',
RUE VARCHAR(25) PATH 'addr/street',
VILLE VARCHAR(25) PATH 'addr/city'
) AS X
Affiche
....+....1....+....2....+....3....+....4....+....5....+....6....+....7
NOM RUE VILLE
Kathy Smith 5 Rosewood Toronto
Jim Noodle 1150 Maple Drive Newtown
Robert Shoemaker 1596 Baseline Aurora
******** Fin de données ********
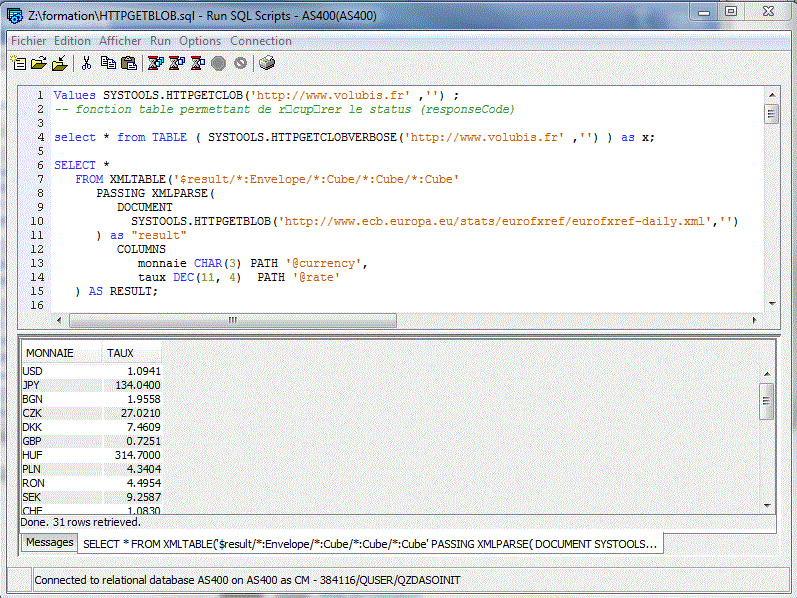
Ce flux pouvant être lut directement depuis le Net par HTTPGETBLOB | HTTPGETCLOB
select * from XMLTABLE(
'$bce/*:Envelope/*:Cube/*:Cube/*:Cube'
PASSING XMLPARSE(DOCUMENT
systools.httpgetblob('http://www.ecb.europa.eu/stats/eurofxref/eurofxref-daily.xml', '') ) as "bce"
COLUMNS
devise char(5) PATH '@currency',
taux dec(7 , 2) PATH '@rate'
) as txml
where devise = 'USD';
Affiche
....+....1....+...
DEVISE TAUX
USD 1,08
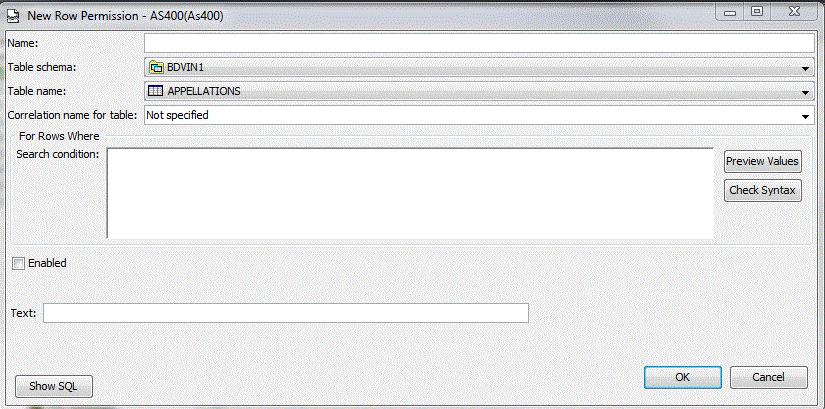
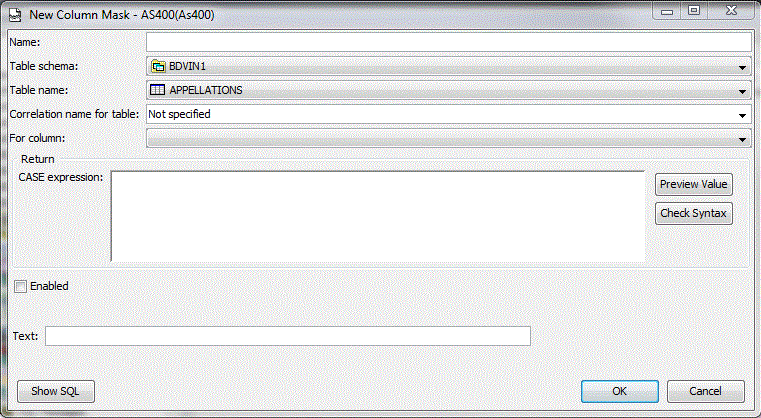
La version 7.2 propose une gestion plus fine des droits : RCAC
Row and Column Access Control
Il s'agit de pouvoir indiquer des « droits » à la colonne ou à la ligne qui s'appliquent y compris aux personnes ayant les droits d'administrateur
•CREATE MASK indique si une colonne est retournée tel que ou totalement/partiellement masquée ('xxx-xxx-xxx-1234' pour un n° de CB)
| CREATE [or REPLACE] MASK tel_MASK ON bdvin1/producteurs FOR COLUMN pr_tel RETURN CASE WHEN SESSION_USER = 'QSECOFR' THEN PR_TEL WHEN SESSION_USER = 'CM' THEN left(pr_tel , 3) concat 'XXXXXXXXXXXXX' ELSE NULL END ENABLE |
| ALTER TABLE bdvin1/producteurs ACTIVATE COLUMN ACCESS CONTROL |
•CREATE PERMISSION indique la(les) règles(s) qui font qu'une ligne peut être vue
Toute ligne ne correspondant pas à la règle est masquée
:
Exemple CM ne doit pas voir l'appellation 13 :
| CREATE [or REPLACE] PERMISSION VINS_ROW_ACCESS ON bdvin1/vins FOR ROWS WHERE SESSION_USER <> 'CM' OR (SESSION_USER = 'CM' and (appel_code <> 13 or appel_code IS NULL) ) ENFORCED FOR ALL ACCESS ENABLE |
| ALTER TABLE bdvin1/vins ACTIVATE ROW ACCESS CONTROL |
ET une option a CREATE TABLE : CREATE OR REPLACE TABLE

Enfin un correctif de Juin 2015 (TR2) ajoute une intégration du format JSON
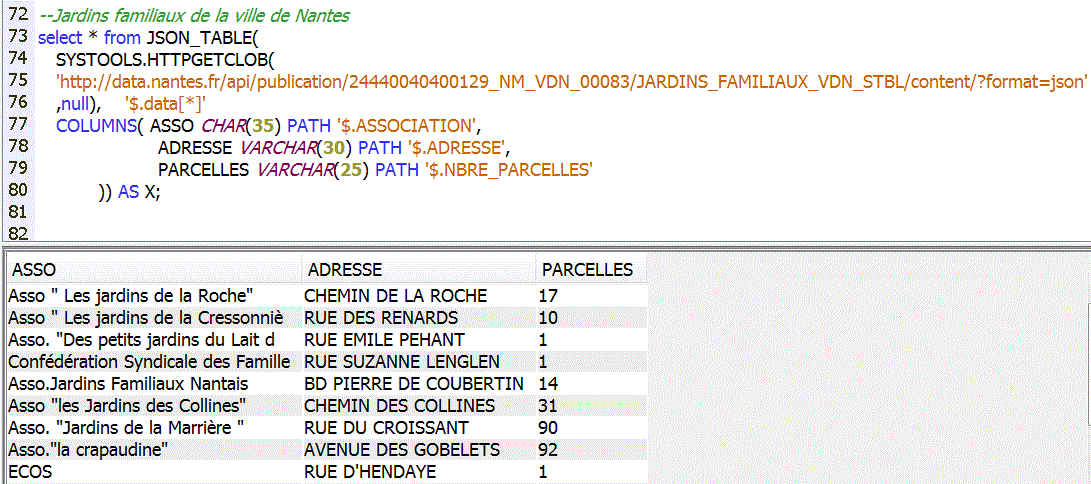
La version 7.3 propose de nombreuses fonctions de statistique (correlation, régression lineaire, etc...)
et les tables temporelles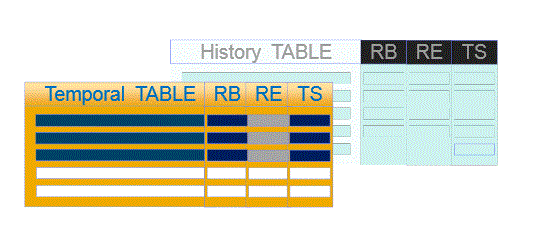
Chaque action (Insert, Update, Delete) est automatiquement historisée dans la table historique
Définition de CLIENTS (association avec la table temporelle)
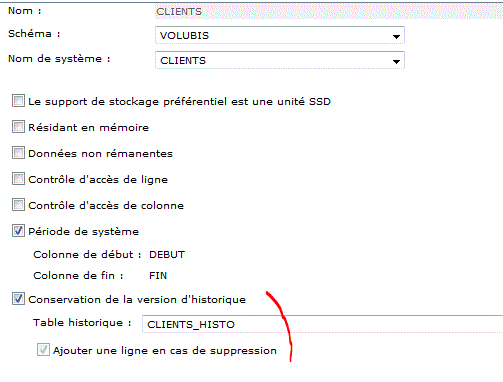
Permettant
Select * From clients
for system_time as of '2016-02-10-12.00.00.00000000000'
Qui affiche les clients comme si on était le 10 Février 2016
Cette version propose des fonctions pour produire du JSON
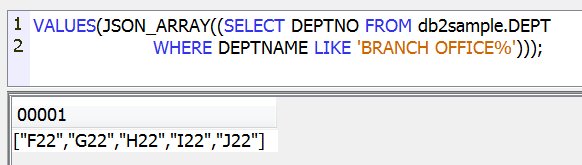
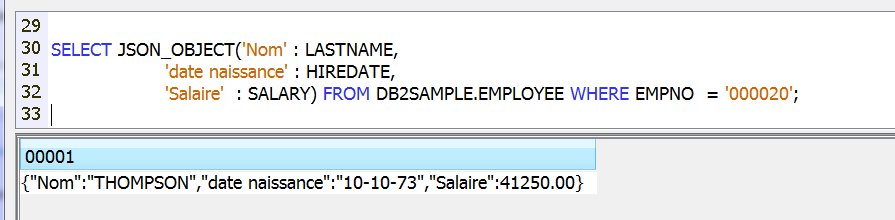


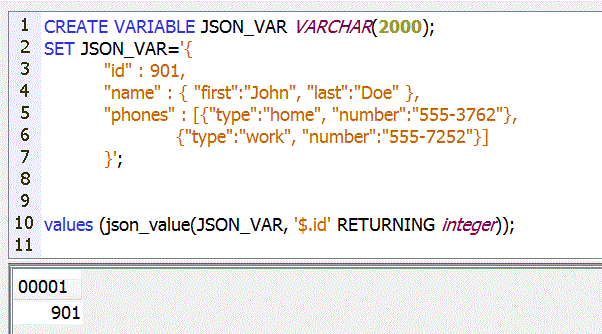

Enfin, LIMIT est accepté sur DELETE et UPDATE
| -- supprimer les 10 plus anciennes commandes DELETE FROM Commandes where nocli = 45 order by DATCMD LIMIT 10 Exemple  |
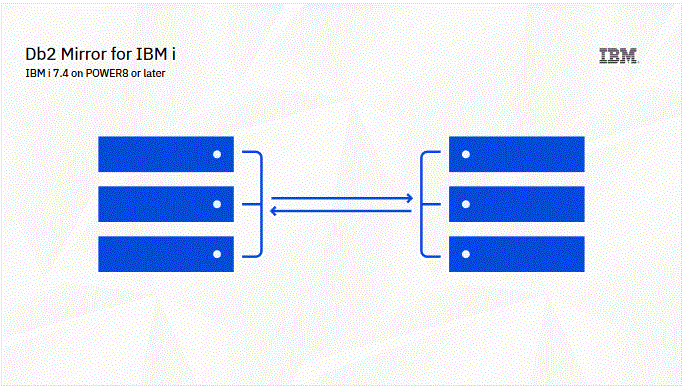
Le produit DB2 mirror for i représente la nouveauté la plus remarquable de la version 7.4
Pour terminer, au fur et à mesure des versions, nous avons la possibilité d'avoir une vision graphique de la base de données, d'abord via System I Navigator :
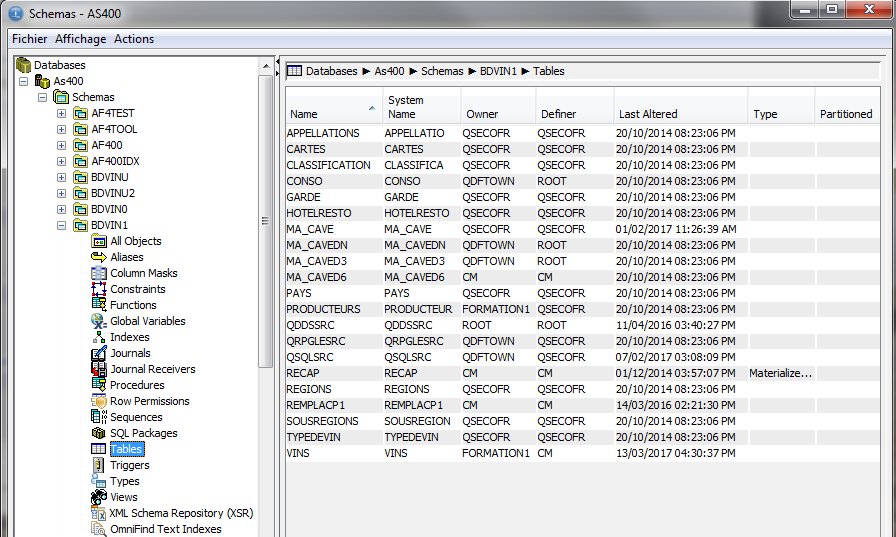
Puis, maintenant, avec IBM i Access client solution
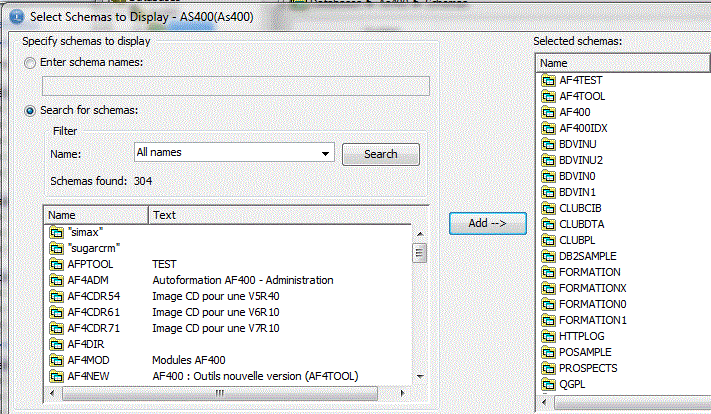
Include permet de choisir les bibliothèques à afficher
Toutes les listes peuvent être sauvegardées
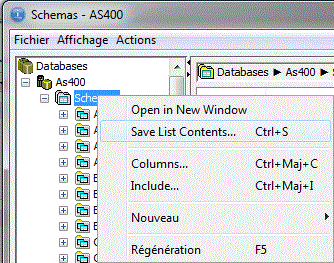
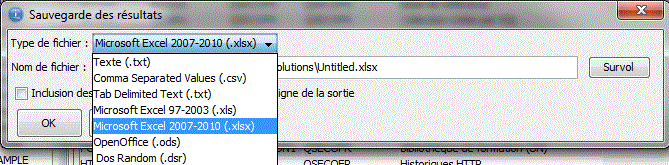
Toutes les listes peuvent être paramétrées

(dans l'ordre des trois boutons)
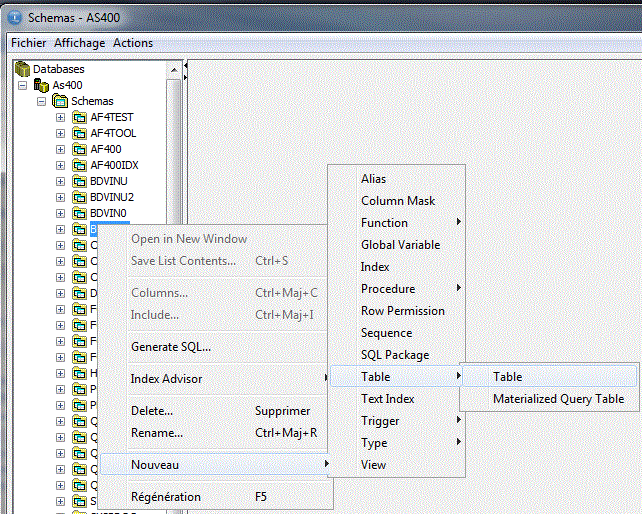
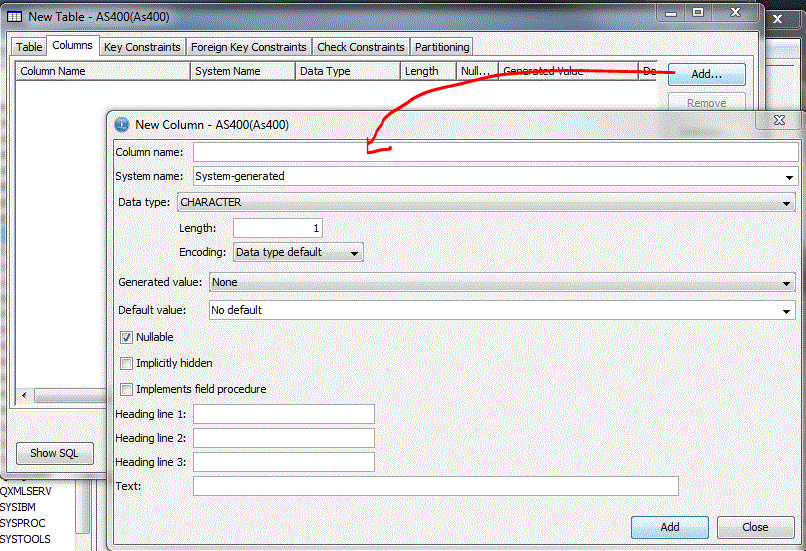
Pour créer, en mode assistance, cliquez avec le bouton droit : "nouveau/table"
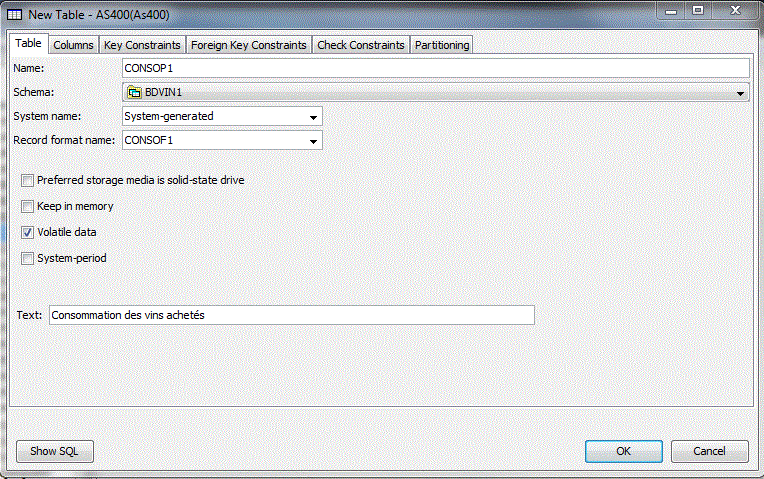
Paramètres généraux
Définition des colonnes
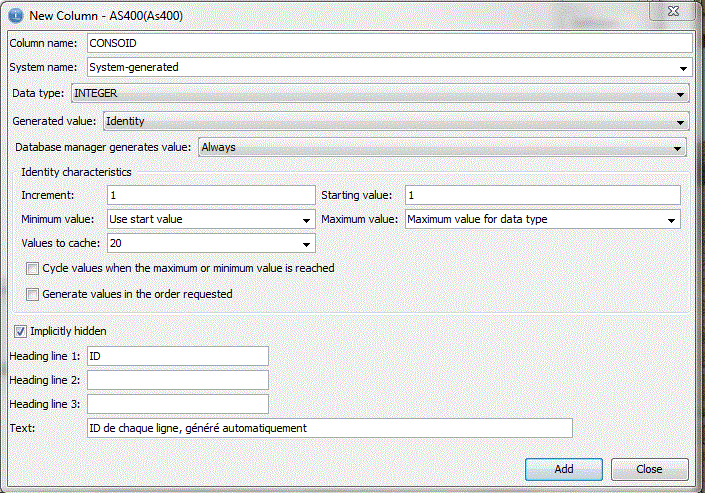
Exemple d'une colonne "Identity"
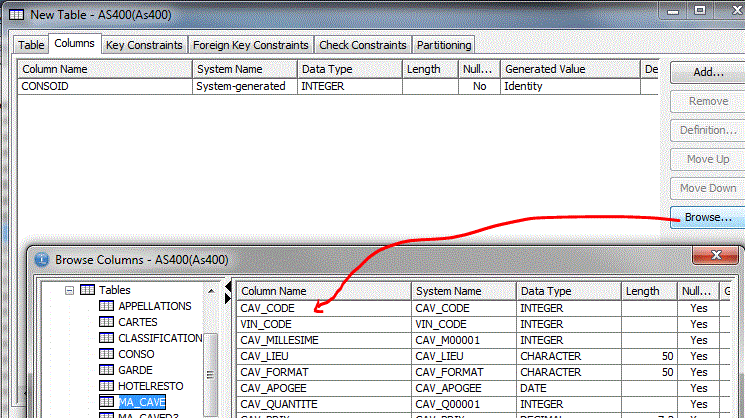
Vous pouvez aller "copier" une définition existante
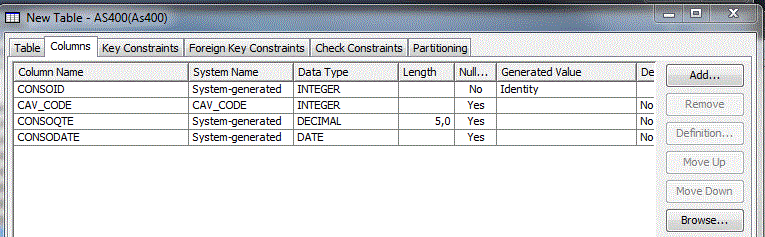
et voilà !
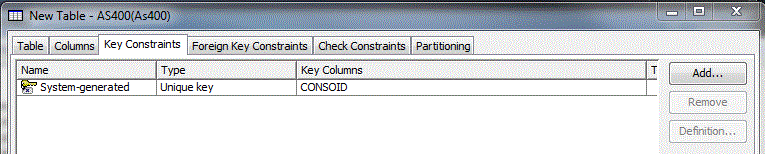
Primary Key
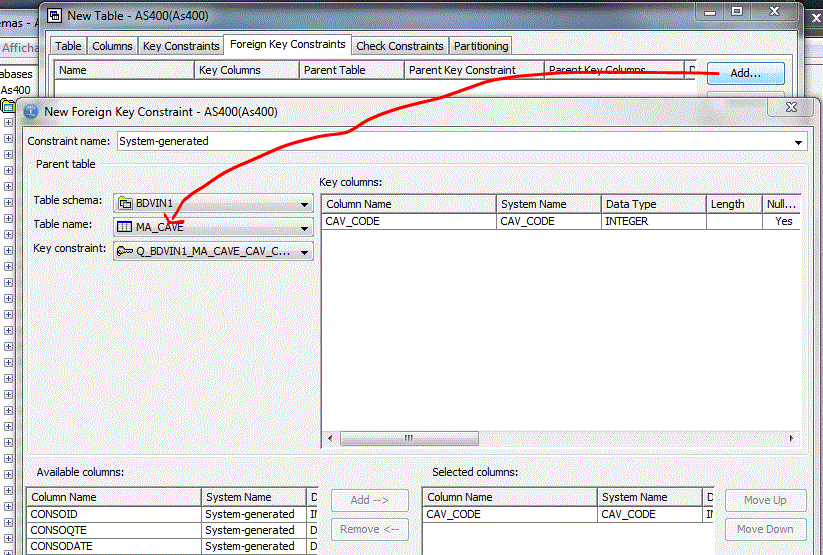
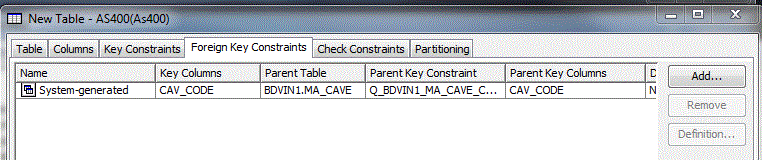
Foreign Key
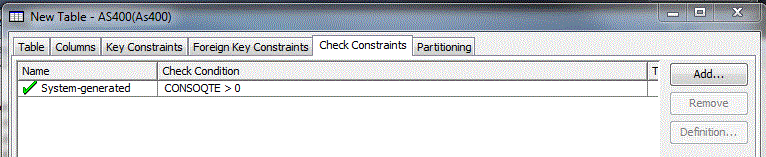
Check Constraint
Retrouvons l'ordre SQL qui va être lancé (Show SQL)
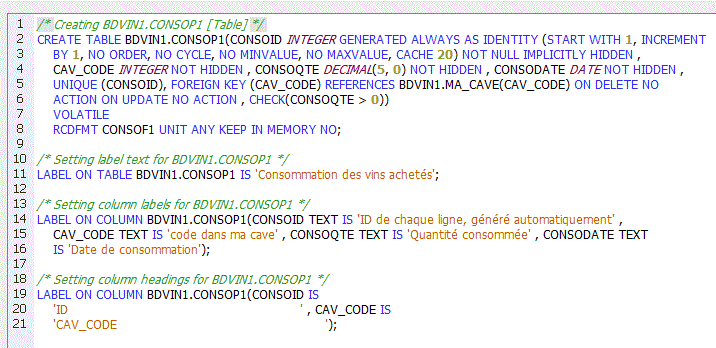
Sur un objet existant , nous pouvons
retrouver le code à partir du catalogue SQL.
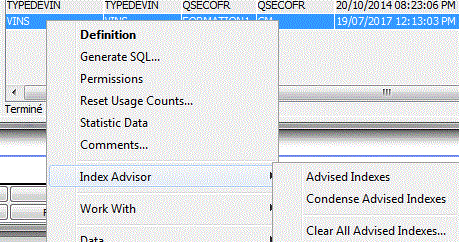
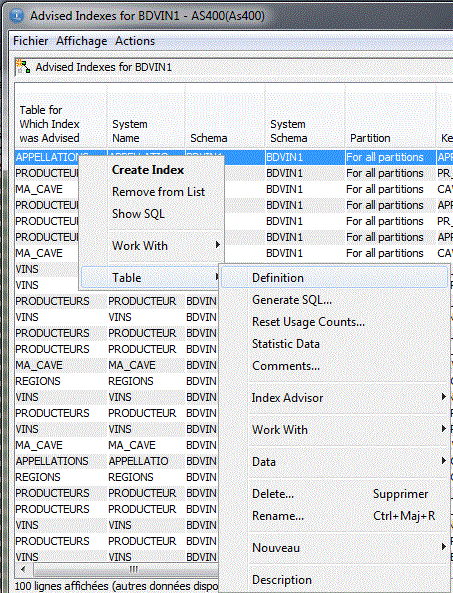
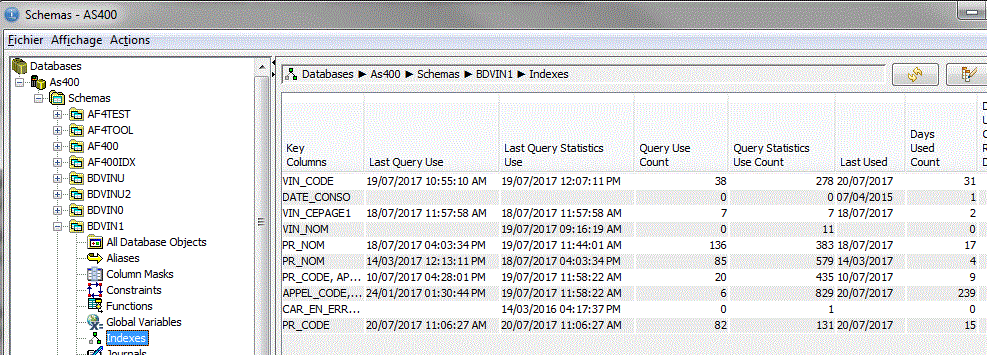
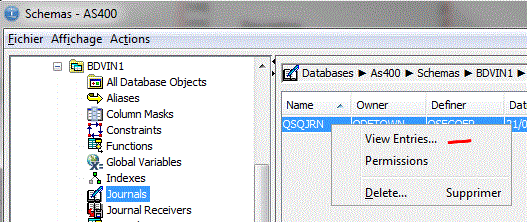
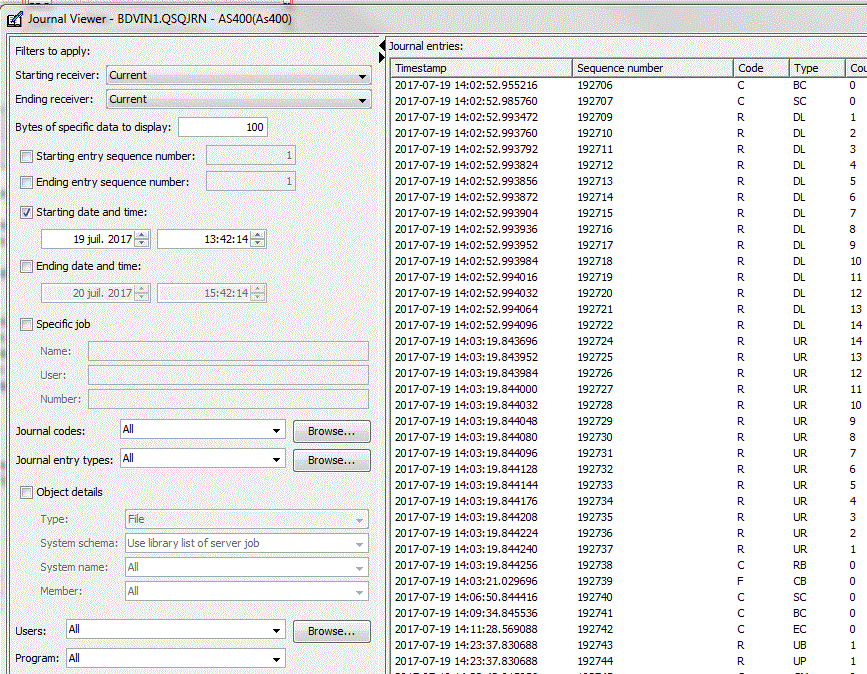
• Gestion des index
Vous pouvez demander la liste des index pour un bibliothèque entière
ou bien, table par table
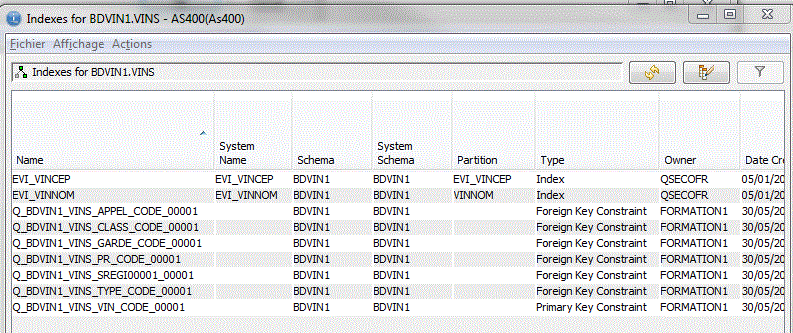
Création d'un Index
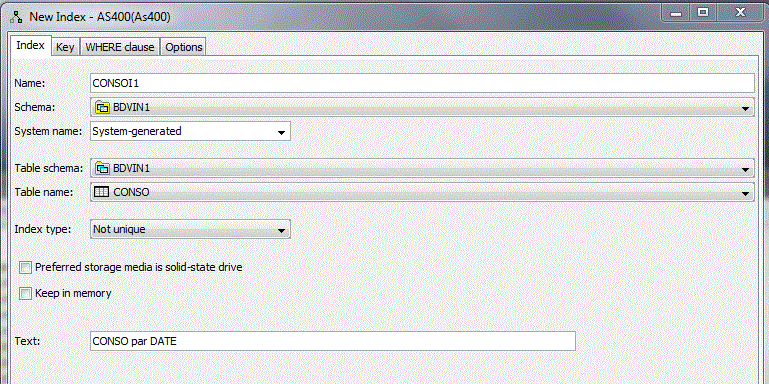

• Création d'une vue
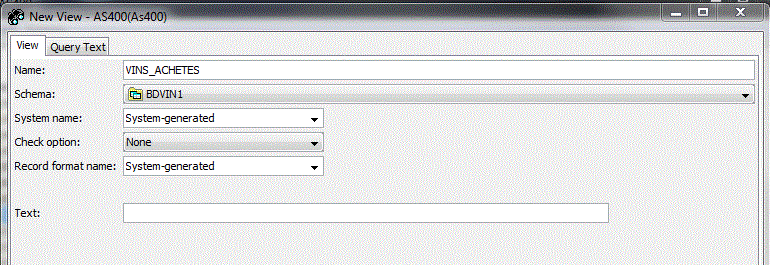

• Création d'une fonction (ici Externe, c'est à dire existant déjà en tant qu'objet *PGM ou *SRVPGM))
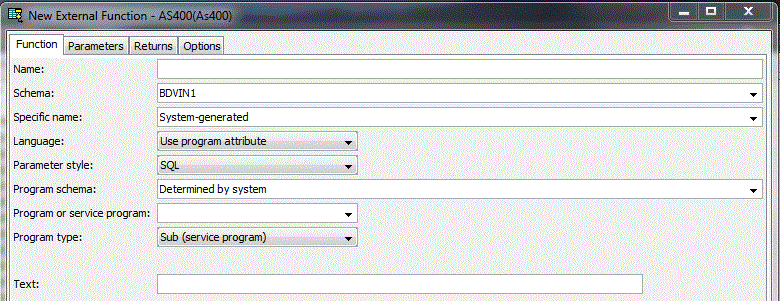
• Création d'une procédure (toujours externe)
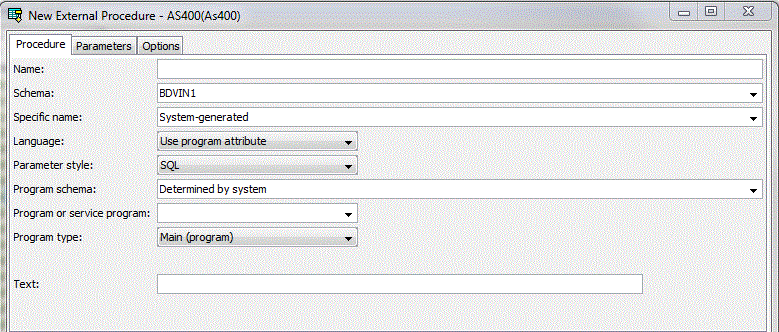
• Création d'un Trigger (SQL cette fois)
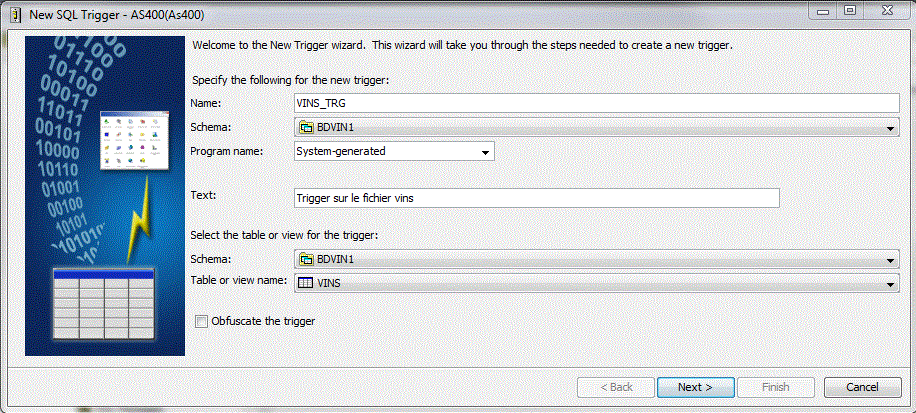
Choix des événements déclencheurs
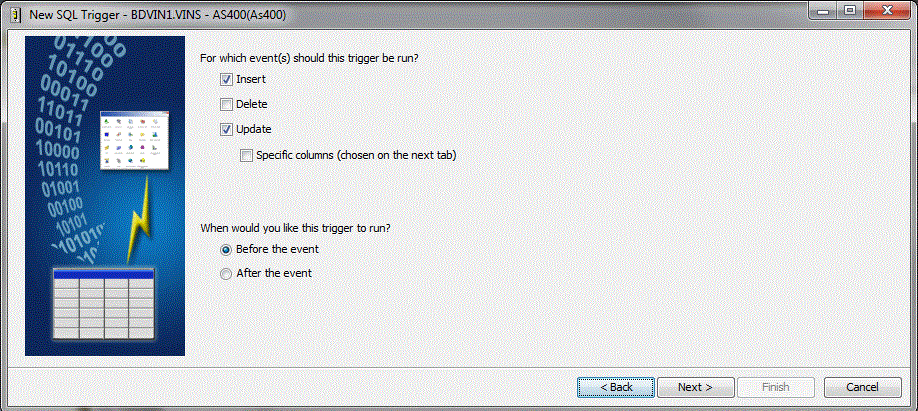
Corps du Trigger
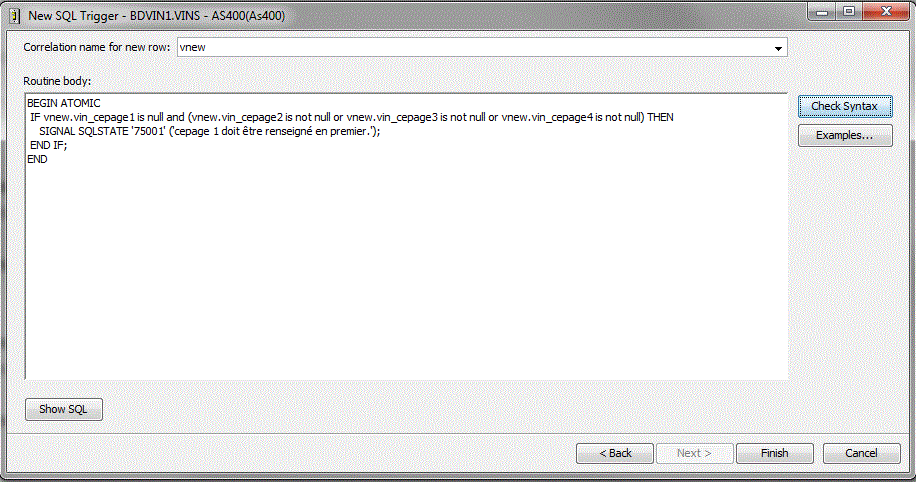
Création d'une permission (qui a le droit à la ligne ? dans le cadre de RCAC)
• Création d'un masque (qui a le droit de voir la colonne ? toujours RCAC)
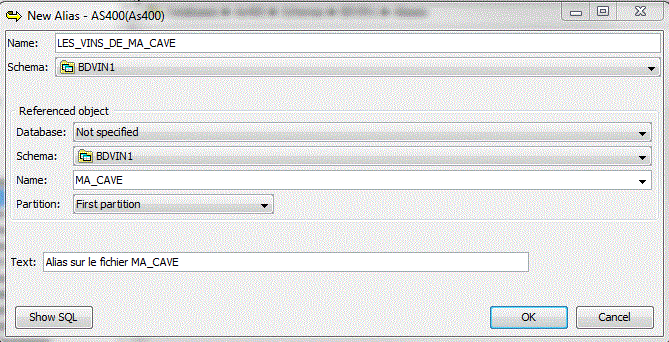
• Création d'un Alias
• Création d'une Séquence
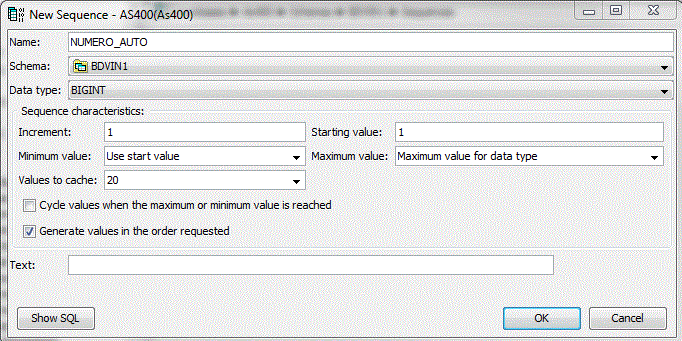
• Création d'une Variable globale
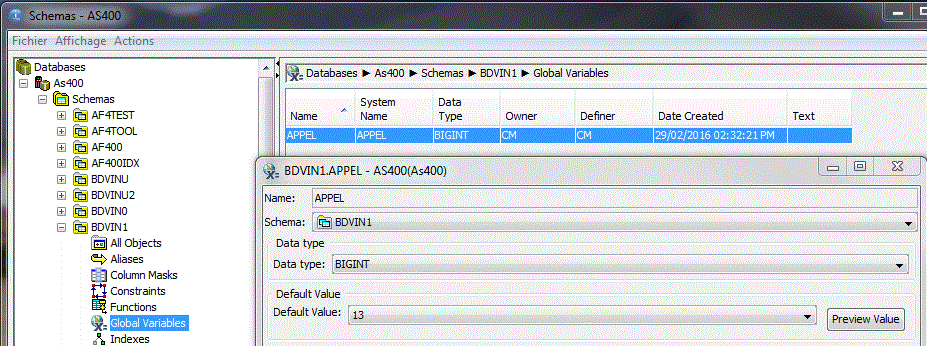
Une fois la base créée, ACS permet une administration complète
Enfin, vous pouvez lancer le gestionnaire de scripts SQL
Vous pouvez :
sauvegarder
et relire un script SQL
lancer
tout ou partie du script
demander
l'inclusion des messages Debug et voir l'historique du travail sur
le serveur
une option ALLOW SAVE RESULT, permet la sauvegarde des
enregistrements extraits:
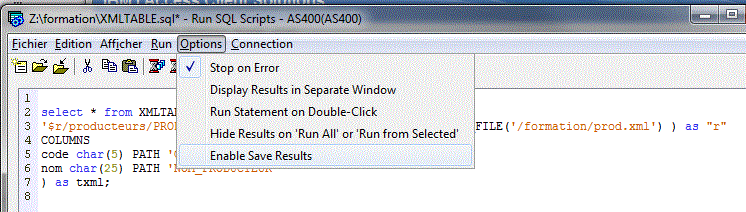
ensuite, avec un clic droit sur les lignes affichées :
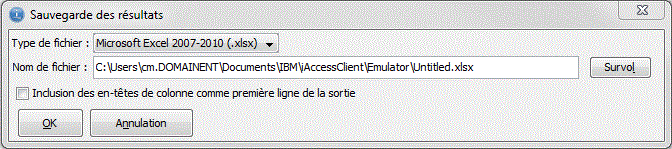
Les formats admis, sont :
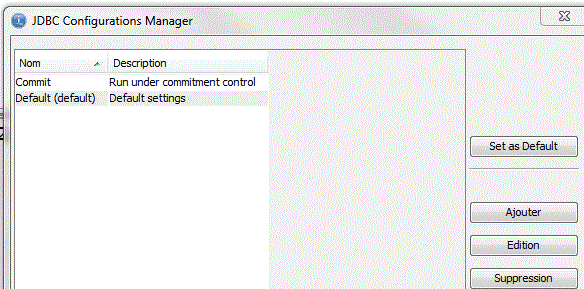
Plusieurs paramètrages de la connexion (JDBC) peuvent être mémorisés
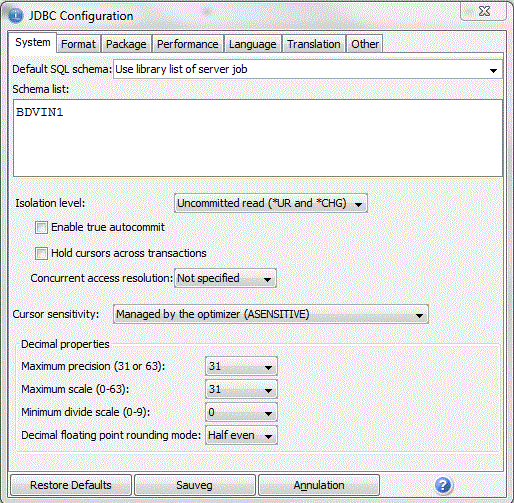
Vous choisissez ensuite comme ceci :
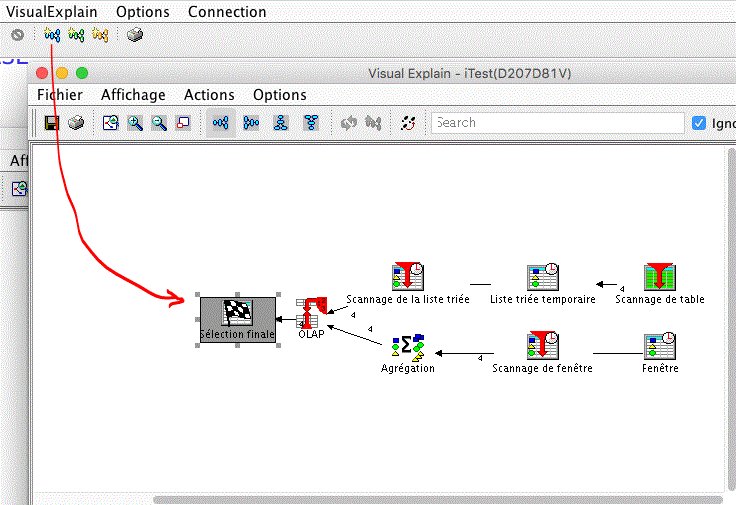
Enfin,lancer l'outils d'analyse Visual Explain
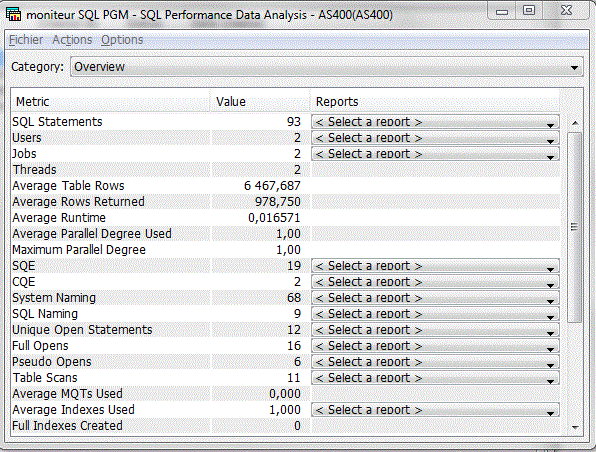
Pour une surveillance globale des performances base de données, vous aurez
le choix entre :
1/ les moniteurs de performance
cliquez sur moniteur de Base de données / nouveau ...
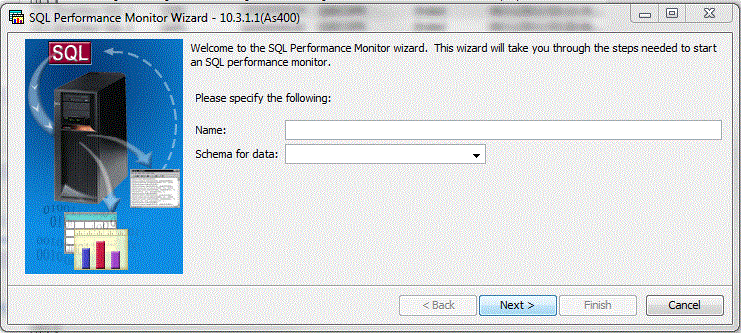
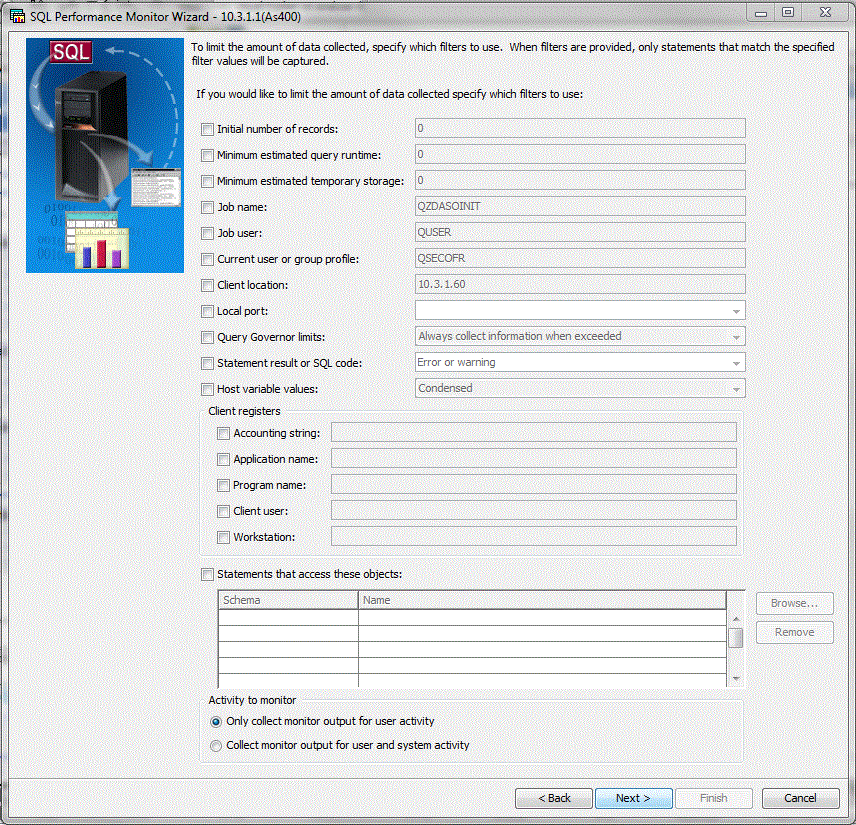
remarquez :
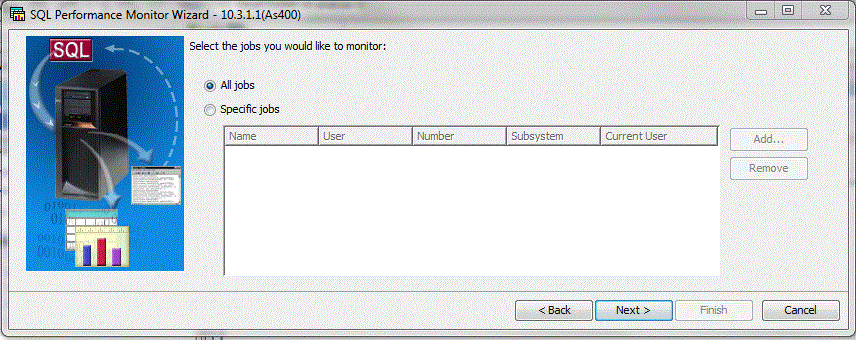
Choix des travaux
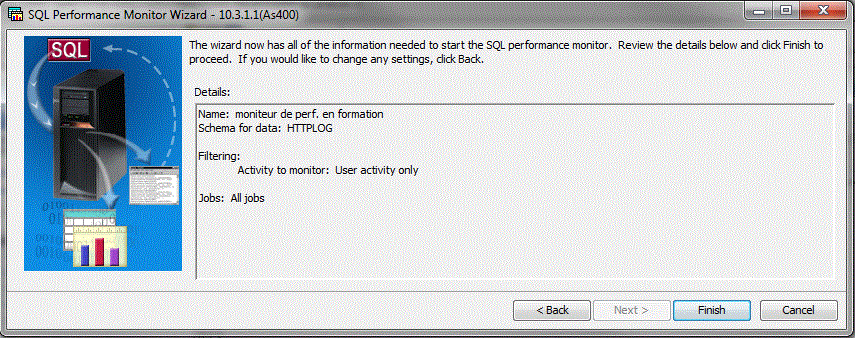
et récapitulatif final.
Quand la trace est terminée (l'arrêt est à votre charge), choisissez une vue (les données à afficher)
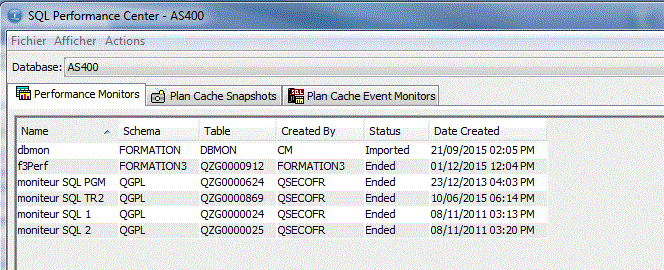
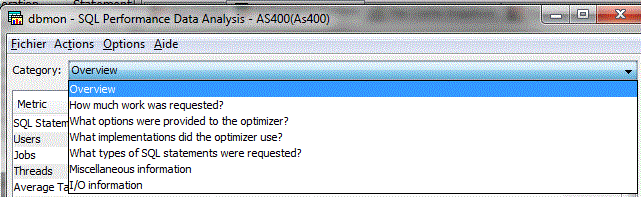
Avec un classement par catégorie
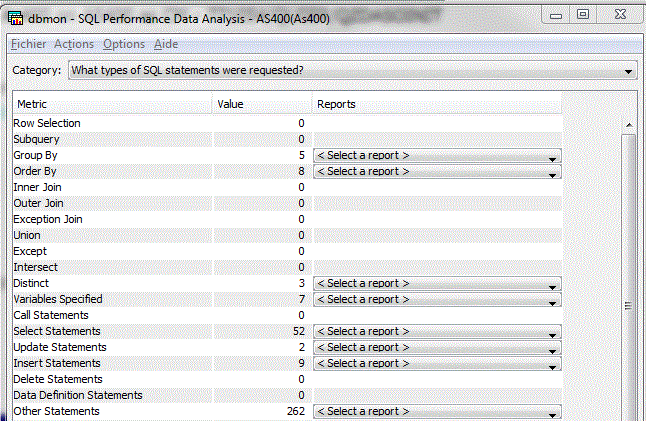
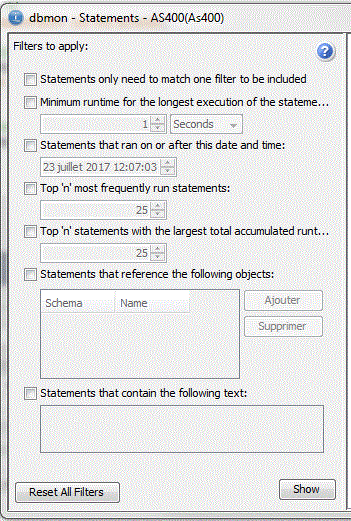
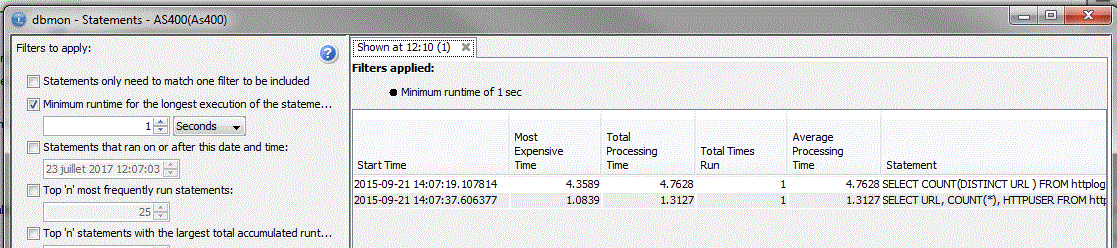
Résultat
Avec accès à Visual Explain et à l'instruction dans le gestionnaire de scripts

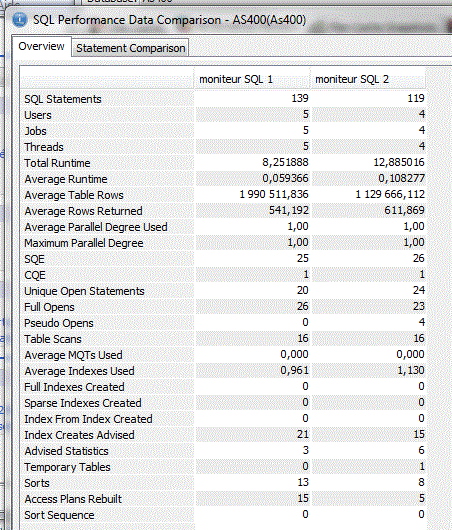
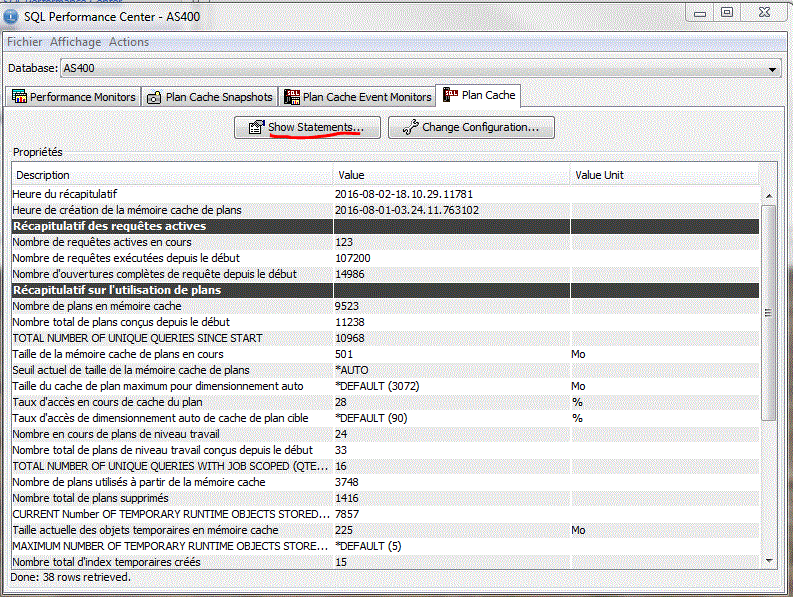
2/ le cache des plans d'accès
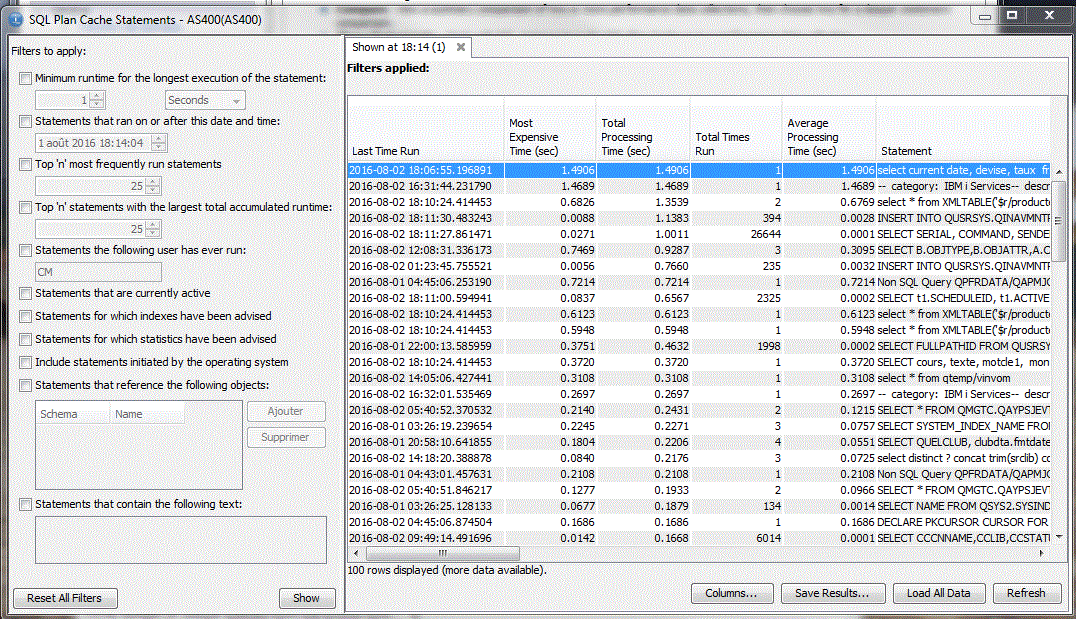
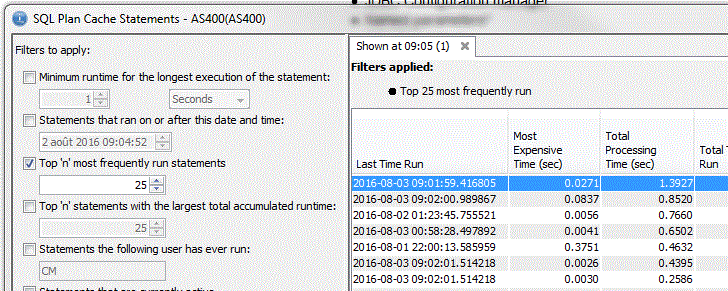
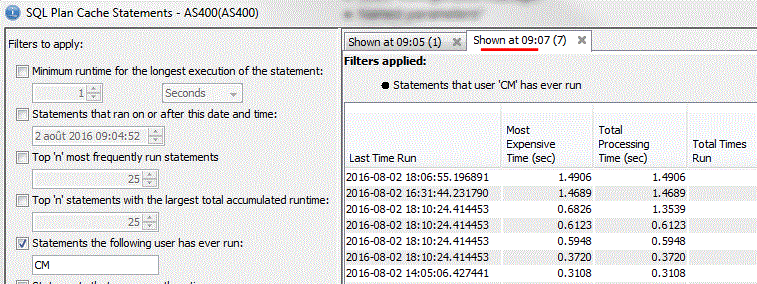
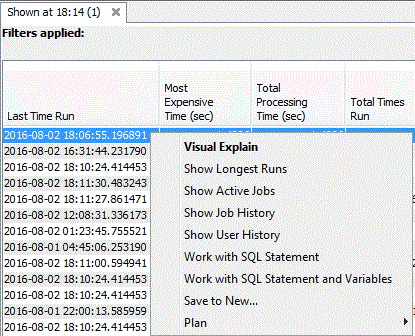
Longuest Run
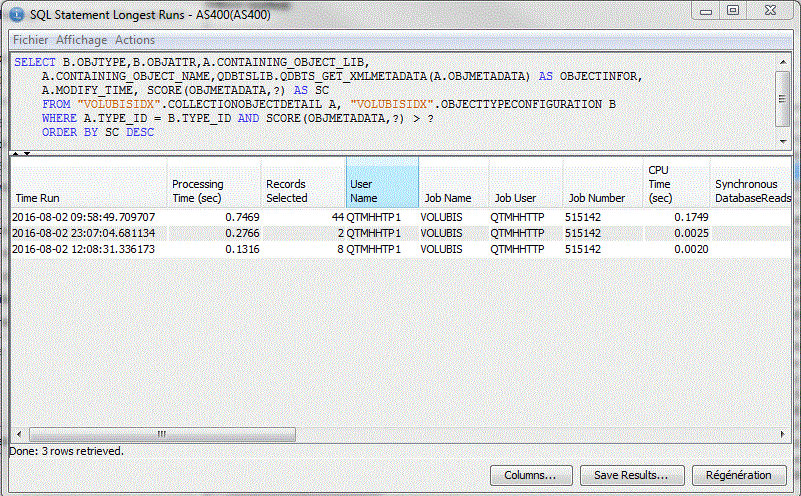
Job History
User History
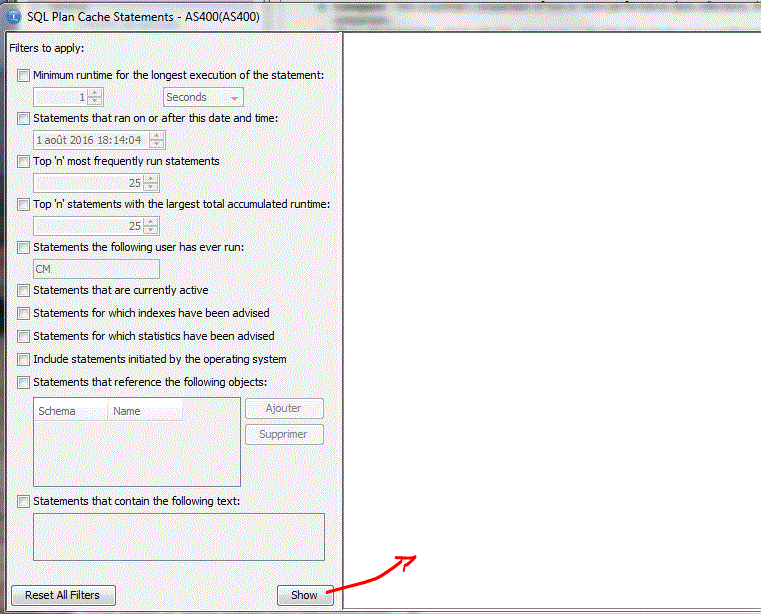
Work with SQL Statement, place la requête dans le gestionnaire de scripts, vu plus haut.
Le jeu d'instructions actuellement en cache pouvant être
sauvegardé sous forme d'image (snapshot).
(sinon, il y a mise à blanc à l'IPL)
•Depuis Performance Center
•Par appel à la procédure cataloguée QSYS2/DUMP_PLAN_CACHE(bibliothèque, nom_de_sauvegarde)
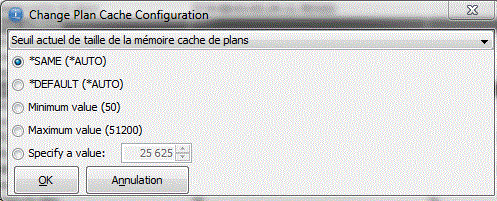
- Quand le cache est plein il est automatiquement épuré, il est possible de placer un moniteur sur cet événement afin de le sauvegarder en fichier avant (Event Monitor)
Tout en gardant la possibilité de choisir les instructions sauvegardées (comme un moniteur)

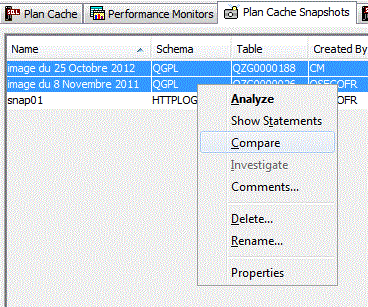
Cette sauvegarde peut ensuite, être réutilisée pour une comparaison :
il n'est pas possible de comparer un jeu d'instructions venant du cache et un moniteur
3/ et enfin, nous pouvons demander à voir les recommandations faites pendant
la constituion de ce cache.
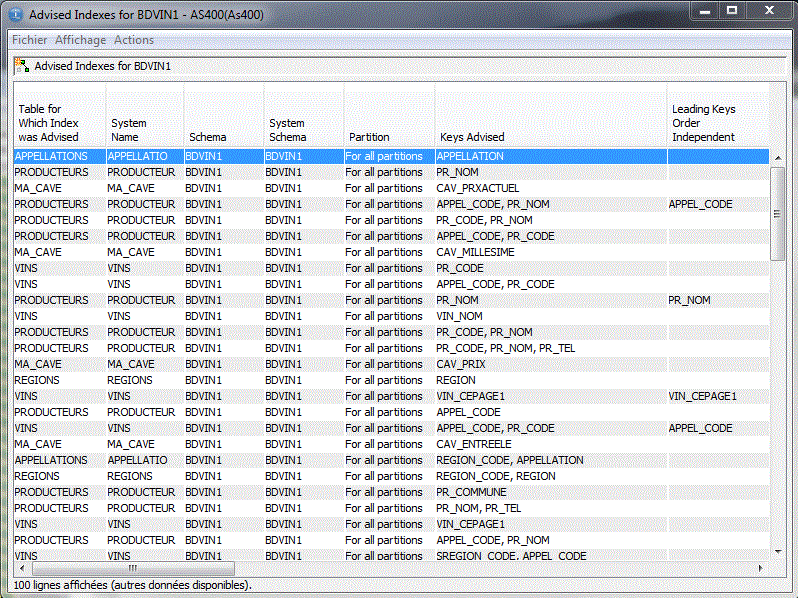
Depuis la V5R40, le système note les index qui lui paraissent
manquant dans QSYS2/SYSIXADV.
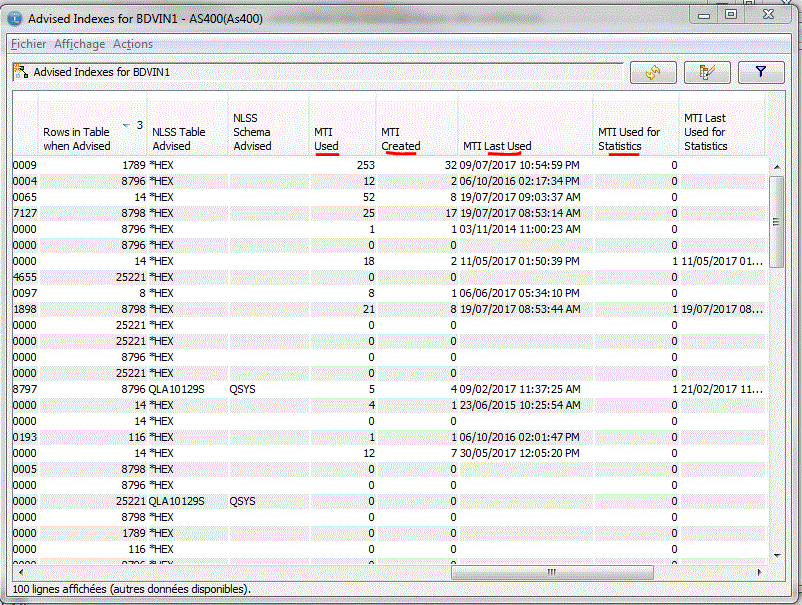
Depuis la V5R4, le système créé lui même sous forme d'index temporaires, les index qu'il juge nécessaires .
(fonction MTI soit Maintained Temporary Indexes), ces index disparaissent à l'IPL.vous pourrez le constater, toujours en demandant l'assistant de gestion d'index
(sur la machine , sur un nom de schéma, sur un nom de table).
l'information se trouve tout à droite de cette fenêtre
- SQL plan Cache
- affiche les instructions qui ont provoqué cette suggestion
- l'assistant affiche aussi le nombre de fois ou un index a été suggéré et, s'il a été créé automatiquement (MTI), le nombre de fois ou il a été utilisé
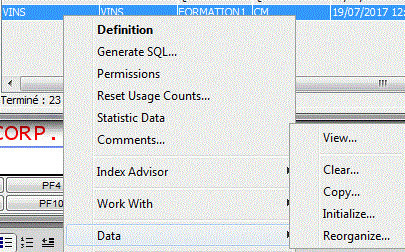
Ce compteur peut-être réinitialisé pour la table, par le menu contextuel suivant :
Initiation au développement
Comme la définition de la base de données qui peut être fait de deux manières :
- Langage historique SDD ou DDS
- SQL, permettant le support de plus de types de données (voir ci-dessous)
L'accès à la base peut se faire selon deux modes :
- Accès séquentiel indexé (dit "natif")
- SQL embarqué
L'accès natif :
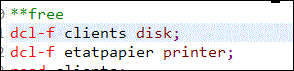
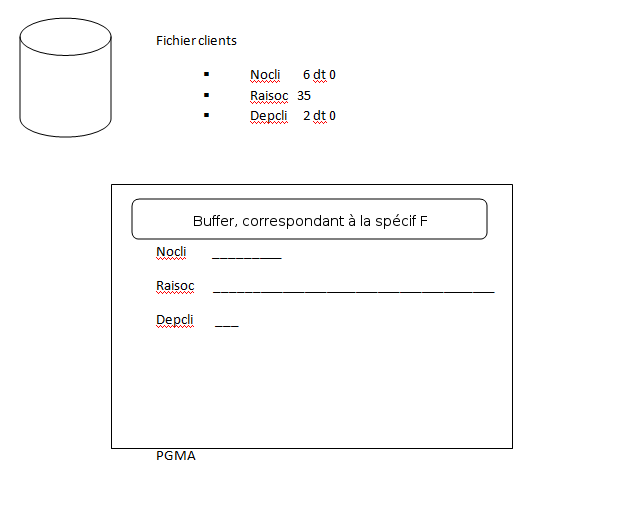
Les fichiers sont déclarés par le biais de "spécif F"ou DCL-F (une déclaration par fichier manipulé) :
Attention, chaque nom doit être unique, les exemples suivants posent problème :
noms de zone identiques ayant des attributs différents
nom de fichier ET nom de format
(par défaut, SQL donne un nom de format identique à la table, il faut alors utiliser RENAME)
nom de fichier ET nom de zone
(nocli qui fait 6 dans le fichier clients et 7 dans le fichier commandes)
- types de fichiers reconnus
- DISK, base de données
- PRINTER, imprimante, génère un spool
- WORKSTN, gère l'affichage sur un terminal
Quand le fichier est déclaré, le compilateur prévoit un "buffer" pour recevoir les lignes lues :
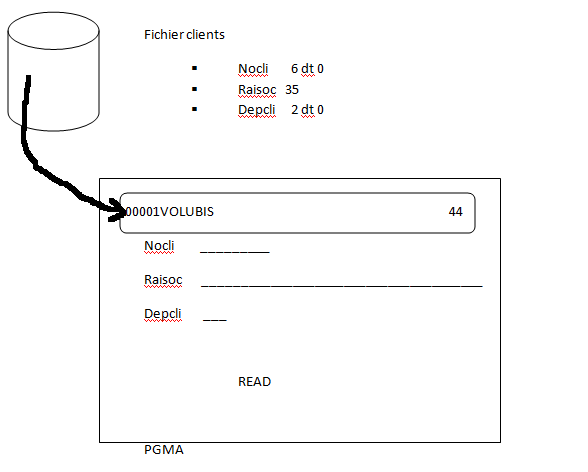
- READ, accès séquentiel de la ligne suivante
- CHAIN, accès direct à une ligne dont on fournit la clé
mais aussi
- WRITE, écriture d'une nouvelle ligne
- UPDATE, mise à jour de la dernière ligne lue
- DELETE, suppression de la dernière ligne lue
Le compilateur RPG a aussi prévu une variable RPG par colonne base de données, et celles-ci sont automatiquement alimentées par des spécif "I"
A noter qu'il se passe exactement l'opération inverse lors d'une écriture
- Alimentation du buffer à partir des variables RPG
- écriture de ce buffer
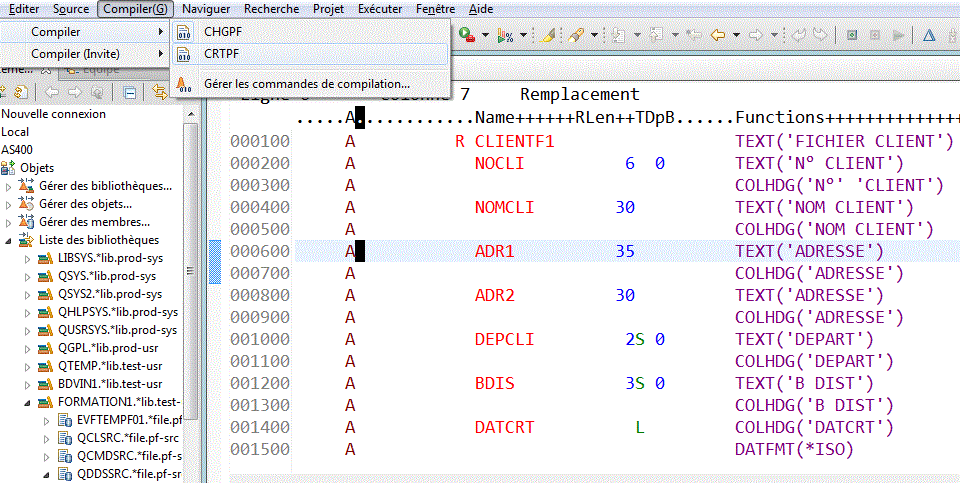
Le compilateur doit être appelé, il va créé un objet *PGM, autonome quant à son exécution.
En cas de modification de la structure, pour éviter un décalage lors des lectures :
- le système affecte à chaque fichier un Format Level Identifier
- ce niveau de format est mémorisé dans le programme par le compilateur
- il testé lors de l'exécution (précisément lors de l'OPEN)
- si le niveau mémorisé n'est pas le niveau rencontré => génération d'une ERREUR GRAVE !
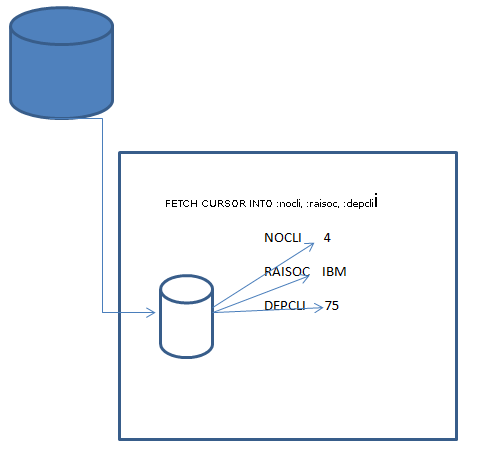
Ce n'est pas le cas avec SQL qui utilise des curseurs
et place directement les données du curseur dans des variables RPG (pas de buffer)
Comment moderniser la base de données / SQL vs DDS.
Le langage SQL est composé de sous ensembles
DDL
Data Definition Language (DDL) , instructions de création et de maintenance de la structure base de données
- CREATE - création d'objets
- ALTER - modification de structure
- DROP - suppression d'objets
- LABEL / COMMENT - documentation
- RENAME - renommage d'objet
DML
Data Manipulation Language (DML) instructions de manipulation de données:
- SELECT - lecture de données
- INSERT - insertion de données
- UPDATE - mise à jour de données
- DELETE - suppression de données
- MERGE - (insert or update)
- CALL - Appel d'une procédure cataloguée
DCL
Data Control Language (DCL) instructions de gestion des droits:
- GRANT - accord de droits
- REVOKE - retrait de droits
Autant l'utilisation de DML se démocratise chez les clients IBM i , autant DDL reste minoritaire...
Pourtant IBM préconise l'utilisation de SQL (DDL) pour concevoir la base de données.
- Les dernières modifications importantes de SDD datent de la V2R11 (1992 de mémoire...), sont mineures ensuite.
- variables dates/heures , valeur nulle (V2)
- support UNICODE (V5)
- PAGESIZE sur CRTLF (V5)
- Support disques SSD (V6)
- paramètre KEEPINMEM (V7)
- Toutes les autres avancées sont liées à SQL
- Nouveaux types
- Dates/Heures et valeur nulle sont intégrés au SQL de base
- BLOB /CLOB (champs images, PDF)
- OmniFind sait indexer de tels champs
- DATALINK
- champs de type URL avec possibilité de contrôle de l'existence du fichier dans l'IFS.
- NCHAR
- DECFLOAT
- ROWID
- zones auto-incrémentées (AS IDENTITY)
- SEQUENCES
- attribut HIDDEN
- cette colonne est cachée par défaut (SELECT * FROM ... ne la montre pas)
- attribut AS ROW CHANGE TIMESTAMP
- ce TIMESTAMP contient automatiquement date/heure de dernière modification.
- XML
- Intégrité référentielle directement définie avec la table (syntaxe SQL)
- Index EVI pour le BI
- FIELDPROC pour crypter les données
- TRIGGER à la colonne
Attention à la terminologie
Quels sont les avantages de SQL pour la création de tables
- plus de types de données disponibles, nous venons de le voir
- les contraintes sont définies dans le même source, le même langage
- noms plus longs
- 30 c. pour les noms de zone
- 128c pour les noms de table
- lectures plus rapides
En effet, pour des raisons historiques (fichiers décrits en internes) les fichiers créés par SDD ne controlent pas la données insérée.
(il est ainsi possible de stocker "ABC" dans une zone numérique, si vous utilisez des spécifs O en RPG).
En contrepartie, lors de l'utilisation de ces fichiers sur un mode externe ou par SQL la donnée est controlée lors de la lecture,
d'où une perte de temps (nous réalisons en général plus d electures que d'écritures sur nos bases)
- Historiquement, journalisation automatique. Désormais nous pouvons utiliser STRJRNLIB
- Possibilité d'utiliser des outils de modélisation (IBM Infosphere Data Architect, Mega Database Builder ou XCASE, par exemple)
Quels sont les inconvénients de SQL pour la création de tables
- Ecritures plus lentes (contrôle de la donnée)
- pas de DDM (possibilité d'utiliser DRDA)
- gestion plus complexe des Multi-membres (ALIAS)
Quels sont les avantages de SQL pour la création d'index (vs LF)
- Choix du type (b-arbre ou EVI)
- Pages de 64 K
- Ces index à larges pages sont plus efficaces lors de manipulation de volumes
- les indexs créés par SDD ont des pages de 8k plus efficaces pour recherche une donnée unitaire (CHAIN en RPG)
- Depuis la V6, les index peuvent avoir
- une clé composée
- une sélection
where raisoc <> ' ' and nocli > 1 ;- un format particulier
RCDFMT clientf8 add raisoc ; -- en plus de la clé- depuis la 7.3(TR6)/7.4, on peut renommer les zones du format
Quels sont les avantages de SQL pour la création de vue (vs LF)
- Beaucoup plus de puissance
- une vue peut avoir une jointure interne et les autres externes gauche
- une vue peut retourner des données agrégées (GROUP BY, GROUP BY ROLLUP)
- une vue peut avoir une sélection utilisant toute la puissance du WHERE SQL (CASE par exemple)
- une vue peut utiliser une fonction "maison" c.a.d une UDF
(select nocli, raisoc, dispo(nocli)
from clients) ;- une vue peut utiliser une UDTF (fonction retournant une table à partir de données non BdeD)
(select * FROM TABLE (litrepertoire('/PDF') as PDF);
- Attention, les vues ne sont pas indexées
- C'est un problème pour remplacer un LF par une vue sur une spécif F RPG
(mais revoyez les nouvelles possibilités des index SQL)- Ce n'est pas un problème lors d'un accès SQL, c'est le moteur qui trouve tout seul le meilleur chemin
Nous savions déjà que SQL sait utiliser des objets créés par SDD, mais les programmes natifs peuvent aussi utiliser des objets SQL
- Bien sûr SQL sait utiliser des fichiers physiques créés par SDD
- Un INDEX SQL fait une bonne spécif F en RPG.
- Une vue SQL peut-être utiliser en progammation RPG (accès séquentiel uniquement)
- on peut :
- créer des index ou des vues SQL sur des physiques SDD
- créer des logiques SDD sur des tables SQL, ce que nous allons voir
Tout cela en attendant d'être FULL SQL ;-)
Voici la vision d'IBM concernant la phase de transition de modernisation de la base de données
Modernisation, phase 1
la phase 2 consiste à faire des modules d'accès à la base (*SRVPGM par exemple)la phase 3 à reporter sur la base de données un maximum de logique métier
- Intégrité référentielle
- contraintes
- Cryptage de données
- Auto-Incrémentation
enfin, la phase 4 propose d'externaliser l'accès aux données
- User Defined Fonction (UDF et UDTF)
- Procédures cataloguées
- etc....
Revenons à l'étape 1, le principe est le suivant :
- Conversion des fichiers physiques en tables SQL
- Création d'un logique SDD ayant le même format que l'ancien physique
- Recréation des différents logiques
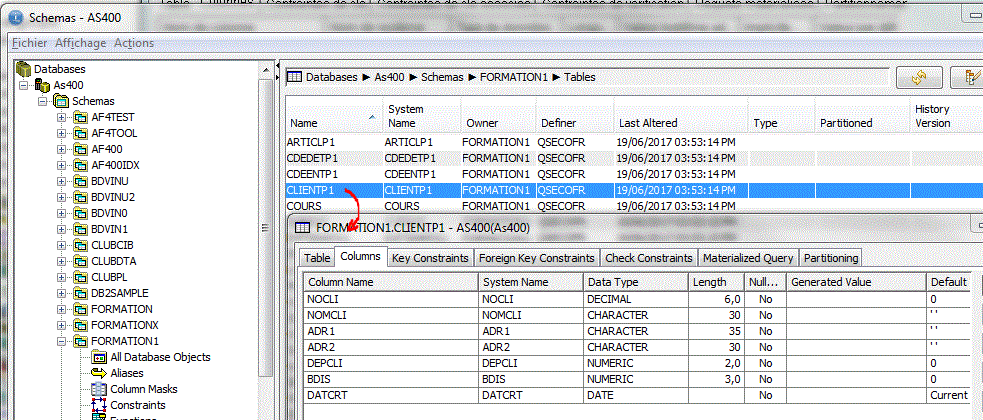
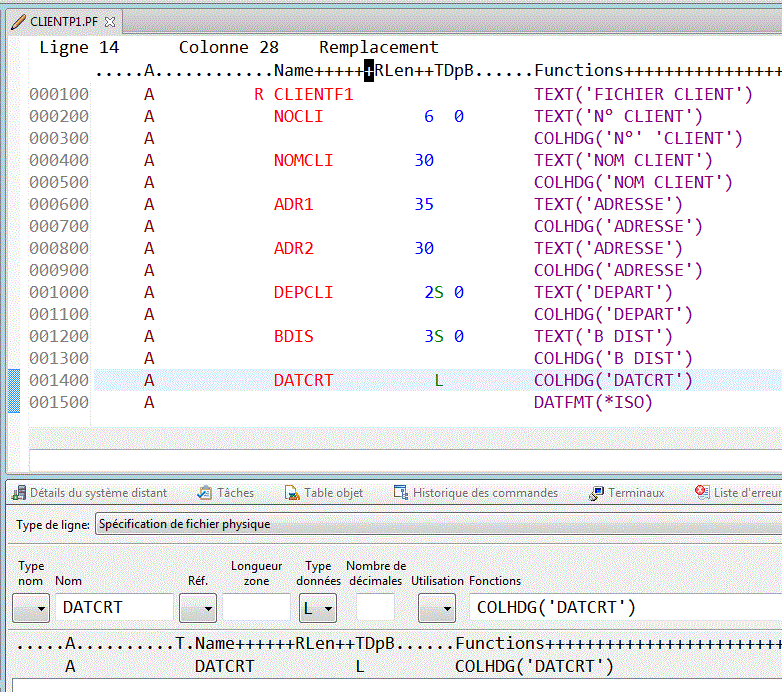
Partons donc d'un fichier physique existant (bibliothèque FORMATION1) que nous souhaitons "moderniser" dans le Schéma TEST1
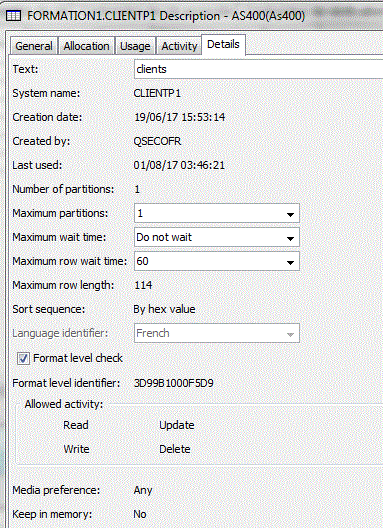
dont voici l'identifiant de format (3D99B1000F5D9)
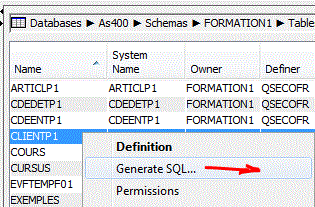
La fonction génération d'instructions SQL permet de retrouver le source SQL
y compris des fichiers créés par SDD
Les fonctions non supportées sont notées en commentaire
- SQL1509 nom de format ignoré (inutile depuis que SQL admet la clause RCDFMT)
- SQL150B attribut de la table ignoré, REUSEDLT(*NO) par exemple
- SQL150D attribut de la colonne ignoré, EDTCDE par exemple
Que nous transformons en :
Nous aurions aussi pu ajouter une zone AS ROW CHANGE TIMESTAMP, par exemple.
Créons ensuite le logique portant le même nom que l'ancien physique SDD (CLIENTP1)
Vérifions
© AF400 - Volubis