
pause-café
destinée aux informaticiens sur plateforme IBM i.
Pause-café #70
Évolutions IBM i et stratégie
-
les technology refresh 2 (7.2) et 10 (7.1) viennent d'être annoncées
Ces PTF sont planifiées tous les 6 mois (entre deux versions) la TR3 est déjà "dans les tuyaux"
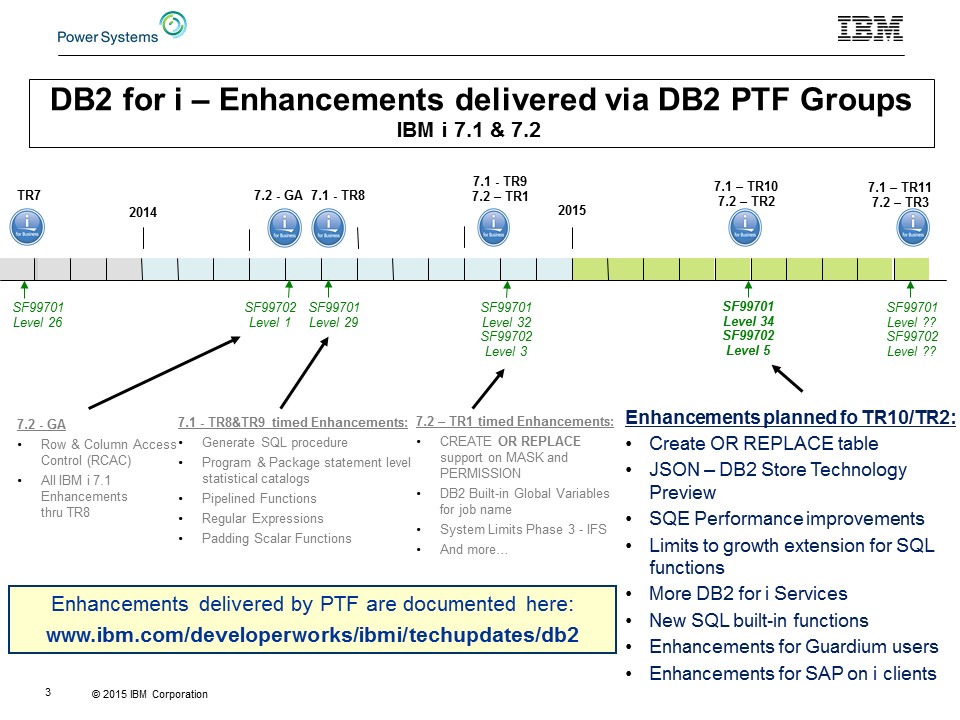
source Scott Forstie sur MCpressOnline
Et dans le même temps Steve Will, nous parle déjà de "IBM i Next" et, parce qu'ils ne pourrons pas tout mettre dedans, "Next +1"

nous parlant alors d'un support allant jusqu'en 2026 !

Source : Le blog de Steve Will
-
Mais, pour mettre tout cela en perspective, regardons un peu dans le rétroviseur....
-
Amélioration DB2
Déjà, quels sont les avantages de SQL pour la création de tables (vs PF) ?
- plus de types de données disponibles
- Dates/Heures et valeur nulle sont intégrés au SQL de base
- BLOB /CLOB (champs images, PDF, JSON en TR2)
- OmniFind sait indexer de tels champs
- DATALINK
- champs de type URL avec possibilité de contrôle de l'existence du fichier dans l'IFS.
- NCHAR
- DECFLOAT
- ROWID
- zones auto-incrémentées (AS IDENTITY)
- SEQUENCES
- attribut HIDDEN
- cette colonne est cachée par défaut (SELECT * FROM ... ne la montre pas)
- attribut AS ROW CHANGE TIMESTAMP
- ce TIMESTAMP contient automatiquement date/heure de dernière modification.
- XML
- Intégrité référentielle, directement définie avec la table (syntaxe SQL)
- les contraintes sont définies dans le même source, le même langage
(nocli dec(6 , 0) primary key ,
raisoc char(25) ) ;CREATE TABLE commandes
( nocde dec(8 , 0) PRIMARY KEY,
nocli dec(6 , 0) REFERENCES clients,
datcde DATE, datliv DATE,
check (datliv > datcde + 1 day) ) ;
- noms plus longs
- 30 c. pour les noms de zone
- 128c pour les noms de table
(numero_client for nocli dec(6 , 0) primary key ,
raison_sociale for raisoc char(25) ) ;
- FIELDPROC pour crypter les données
- TRIGGER à la colonne
- lectures plus rapides
- Historiquement, journalisation automatique. Désormais nous pouvons aussi utiliser STRJRNLIB
- Possibilité d'utiliser des outils de modélisation
- 7.2, RCAC
Droits à la colonne
| CREATE [or REPLACE] MASK tel_MASK ON bdvin1/producteurs FOR COLUMN pr_tel RETURN CASE WHEN SESSION_USER = 'QSECOFR' THEN PR_TEL WHEN SESSION_USER = 'CM' THEN left(pr_tel , 3) concat 'XXXXXXXXXXXXX' ELSE NULL END ENABLE |
Droits à la ligne
| CREATE [or REPLACE] PERMISSION VINS_ROW_ACCESS ON bdvin1/vins FOR ROWS WHERE SESSION_USER <> 'CM' OR (SESSION_USER = 'CM' and (appel_code <> 13 or appel_code IS NULL) ) ENFORCED FOR ALL ACCESS ENABLE |
on indique ce qui peut être vu (une affirmation, donc)
- 7.2 TR2
- CREATE OR REPLACE TABLE ...
simplification des scripts de mise en place, de déploiement

Cette instruction fonctionne sur un fichier physique (DDS) existant, facilitant la transition d'un monde à l'autre.
D'ailleurs la Génération d'instruction SQL sous System i navigator, le propose sous forme d'option

- CREATE OR REPLACE TABLE ...
Quels sont les avantages de SQL pour la création d'index (vs LF)
- Choix du type (b-arbre ou EVI)
- Index EVI pour le BI
- ces derniers peuvent contenir des fonctions d'agrégation (Count, SUM, ...)
- Pages de 64 K
- Ces index à larges pages sont plus efficaces lors de manipulation de volumes
- les index créés par SDD ont des pages de 8k plus efficaces pour recherche une donnée unitaire (CHAIN en RPG)
- Depuis la V6, les index peuvent avoir
- une clé composée
- une clé composée
- une sélection
where raisoc <> ' ' and nocli > 1 ;
- un format particulier
RCDFMT clientf8 add raisoc ; -- en plus de la clé
Quels sont les avantages de SQL pour la création de vue (vs LF)
- Beaucoup plus de puissance
- une vue peut avoir une jointure interne et les autres externes gauche
- une vue peut retourner des données agrégées (GROUP BY, GROUP BY ROLLUP)
- une vue peut avoir une sélection utilisant toute la puissance du WHERE SQL (CASE par exemple)
- une vue peut utiliser une fonction "maison" c.a.d une UDF
(select nocli, raisoc, dispo(nocli)
from clients) ;
- une vue peut utiliser une UDTF (fonction retournant une table à partir de données non BdeD)
(select * FROM TABLE (litrepertoire('/PDF') as PDF);
- Attention, les vues ne sont pas indexées
- C'est un problème pour remplacer un LF par une vue sur une spécif F RPG
(mais revoyez les nouvelles possibilités des index SQL) - Ce n'est pas un problème lors d'un accès SQL, c'est le moteur qui trouve tout seul le meilleur chemin
- C'est un problème pour remplacer un LF par une vue sur une spécif F RPG
Avancées syntaxique SQL (voyez aussi notre mémo)
- WITH admet UNION et ORDER BY, permettant des requêtes récursives
-
(Requête récursive) WITH temp (composant, compose, quantite)
as (select L.composant, L.compose, L.quantite
from liens L where composant = 'voiture'
UNION ALL
select fils.composant , fils.compose, fils.quantite
from temp AS Pere join liens AS Fils
on pere.compose=Fils.composant
)
SELECT * FROM TEMP
EN version 7 utilisez plutôt cette syntaxe
-
(Requête récursive
ou hiérarchique V7)SELECT chef, matricule, nom
FROM personnel
START WITH chef = ‘Mr le Directeur’
CONNECT BY PRIOR matricule =chef
options liées :ORDER SIBLINGS BY nom
Tri les lignes ayant le même parent CONNECT BY NOCYCLE PRIOR
évite l'arrêt en erreur lors d'une boucle infinie
(la ligne qui provoque la boucle est affichée une deuxième fois)CONNECT_BY_ISCYCLE
retourne 1 si la ligne en cours aurait provoqué une boucle CONNECT_BY_ISLEAF
retourne 1 si la ligne en cours n'a pas d'enfant LEVEL
indique le niveau dans la hiérarchie pour cette ligne CONNECT_BY_ROOT
indique l'élément racine (le parent d'origine) pour cette ligne SYS_CONNECT_BY_PATH(
<élément>
, <séparateur>)retourne le chemin complet (suite de <élément> séparés par <séparateur>)
par exemple :
SELECT SYS_CONNECT_BY_PATH(trim(chef), '/') AS chemin
retourne sous forme de CLOB : /Mr le Directeur
/Mr le Directeur/Michelle
/Mr le Directeur/Michelle/Françoise
/Mr le Directeur/Michelle/Françoise/Yves
- Fonctions dites "OLAP"
-
ROW_NUMBER() numérote les lignes sur un critère de tri
select ROW_NUMBER() over (order by prix), codart, libart from articles
[order by autre-chose]RANK() attribue un rang à chaque ligne
(en gérant les ex-aequo, par exemple 1-1-3-4-4-4-7)select RANK() over (order by prix), codart, libart from articles DENSE_RANK() attribue un rang consécutif
(par exemple 1-1-2-3-3-3-4)select DENSE_RANK() over (order by prix), codart, libart from articles V6 : évolution GROUP BY soit le SELECT basique suivant -->
SELECT SOC, DEP, Count(*) .../... GROUP BY soc, Dep
SOC DEP Count(*) 01 22 15 01 44 20 02 22 5 02 44 10 ROLLUP affiche 1 total par groupe puis des ruptures de niveau supérieur
SELECT SOC, DEP, Count(*) ... GROUP BY ROLLUP (soc, Dep)
SOC DEP Count(*) 01 22 15 01 44 20 01 - 35 02 22 5 02 44 10 02 - 15 - - 50
- Instruction MERGE
-
MERGE MERGE INTO cible C
USING (SELECT source1 , source2 FROM source) S
ON (C.zonecle = S.zonecle)
WHEN MATCHED THEN
UPDATE SET cible2 = source2
WHEN NOT MATCHED THEN
INSERT (cible1, cible2) VALUES(source1, source2)
- instruction TRUNCATE (7.2)
- équivalent à CLRPFM
- équivalent à CLRPFM
- V7 : intégration du XML (voir Pause Café 56)
- le XML peut être stocké, il est vérifié lors du stockage
- on peut associer un schéma XSD à un champ XML
- un fichier de l'IFS peut être lu par GET_XML_FILE pour produire du XML
- un flux http peut être reçu (HTTPxxxCLOB) pour produire du XML
- de nombreuses fonctions permettent de "fabriquer" du XML (XMLROW, XMLAGG)
- on peut "parser" du XML en SQL et présenter les data sous forme relationnelle (XMLTABLE)
- un champs XML peut être indexé (ainsi que les champs Texte et BLOB) par Omnifind, permettant :
- un recherche poussée (XPath)
- avec de bons temps de réponse
- Exemple, le code
SELECT * FROM XMLTABLE('$result/rss/channel/item'
PASSING XMLPARSE( DOCUMENT
SYSTOOLS.HTTPGETBLOB('http://www.redbooks.ibm.com/rss/iseries.xml','')
) as "result"
COLUMNS
title VARCHAR(128) PATH 'title',
description VARCHAR(1024) PATH 'description',
link VARCHAR(255) PATH 'link',
pubDate VARCHAR(20) PATH 'substring(pubDate, 1, 16)'
) AS RESULT;permet de lire les un flux RSS de manière structurée :
TR1
- de nouvelles fonctions, basées sur les expressions régulières (voir Pause-Café 69)
TR2
- Intégration du format JSON (dans des champs BLOB)
- via les API Java
- création de collections (table à un seul champ BLOB)
- en mode commande
- en SQL
- fonction d'exportation BSON2JSON
- deux nouvelles fonctions (gestion des UUID)
- VARBINARY_FORMAT
- VARCHAR_FORMAT_BINARY
- CREATE OR REPLACE TABLE ...
- ON REPLACE
PRESERVE ALL ROWS
conservation de toutes les lignes, y compris sur une table partitionnée
PRESERVE ROWS
si une plage (pour un table partitionnée) est enlevée, les lignes correspondantes disparaissent
DELETE ROWS
aucune ligne n'est conservée.
DB2 for I Service
- SQL est devenu le langage de choix pour IBM afin d'accéder aux informations Système (SQL as a service)
•SF99702 level 5 arrive en même temps que la TR2
•SF99701 level 34 arrive en même temps que la TR10
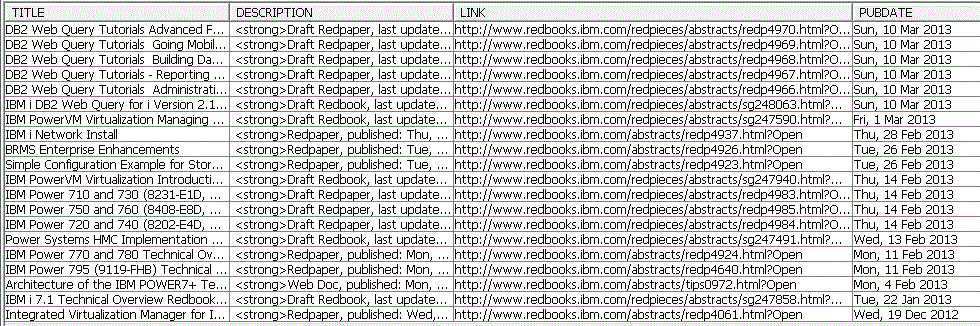
-
DB2 for i Service
Type IBM i 7.2IBM i 7.1IBM i 6.1PTF Services QSYS2.PTF_INFO Vue Base SF99701 Level 23 SF99601 Level 29 QSYS2.GROUP_PTF_INFO Vue Base SF99701 Level 6 SF99601 Level 19 SYSTOOLS.GROUP_PTF_CURRENCY Vue SF99702 Level 3 SF99701 Level 32 - Security Services QSYS2.USER_INFO Vue Base livré: SF99701 Level 26
Modifié: SF99701 Level 29livré: SF99601 Level 31
Modifié: SF99601 Level 32QSYS2.FUNCTION_INFO Vue Base SF99701 Level 26 SF99601 Level 31 QSYS2.FUNCTION_USAGE Vue Base SF99701 Level 26 SF99601 Level 31 QSYS2.GROUP_PROFILE_ENTRIES Vue Base SF99701 Level 23 SF99601 Level 29 QSYS2.SQL_CHECK_AUTHORITY() UDF Base SF99701 Level 21 SF99601 Level 29 QSYS2.SET_COLUMN_ATTRIBUTE() Procédure Base Base SF99601 Level 8 QSYS2.DRDA_AUTHENTICATION_ENTRY_INFO Vue SF99702 Level 5 SF99701 Level 34 - Message Handling Services QSYS2.REPLY_LIST_INFO Vue SF99702 Level 3 SF99701 Level 32 SF99601 Level 33 QSYS2.JOBLOG_INFO UDTF SF99702 Level 3 SF99701 Level 32 SF99601 Level 33 Librarian Services QSYS2.LIBRARY_LIST_INFO Vue SF99702 Level 3 SF99701 Level 32 SF99601 Level 33 QSYS2.OBJECT_STATISTICS() UDTF livré: Base
Modifié: SF99702 Level 5livré: SF99701 Level 3
Modifié: SF99701 Level 34SF99601 Level 16 Work Management Services QSYS2.SYSTEM_VALUE_INFO Vue Base SF99701 Level 26 SF99601 Level 31 QSYS2.GET_JOB_INFO() UDTF livré: Base
Modifié: SF99702 Level 5livré: SF99701 Level 23
Modifié: SF99701 Level 29
Modifié: SF99701 Level 34livré: SF99601 Level 29
Modifié: SF99601 Level 32QSYS2.ACTIVE_JOB_INFO() UDTF SF99702 Level 5 SF99701 Level 34 - QSYS2.SCHEDULED_JOB_INFO Vue SF99702 Level 5 SF99701 Level 34 - TCP/IP Services SYSIBMADM.ENV_SYS_INFO Vue Base SF99701 Level 23 SF99601 Level 29 QSYS2.TCPIP_INFO Vue Base SF99701 Level 6 SF99601 Level 19 QSYS2.SET_SERVER_SBS_ROUTING() Procédure SF99702 Level 5 SF99701 Level 34 - QSYS2.SERVER_SBS_ROUTING Vue SF99702 Level 5 SF99701 Level 34 - Storage Services QSYS2.USER_STORAGE Vue Base SF99701 Level 26 SF99601 Level 31 QSYS2.SYSTMPSTG Vue Base - - QSYS2.SYSDISKSTAT Vue Base SF99701 Level 12 SF99601 Level 21 System Health Services QSYS2.SYSLIMTBL Table livré: Base
Modifié: SF99702 Level 3
Modifié: SF99702 Level 5livré: SF99701 Level 23
Modifié: SF99701 Level 26
Modifié: SF99701 Level 34livré: SF99601 Level 29
Modifié: SF99601 Level 31QSYS2.SYSLIMITS Vue livré: Base
Modifié: SF99702 Level 3
Modifié: SF99702 Level 5livré: SF99701 Level 23
Modifié: SF99701 Level 26
Modifié: SF99701 Level 34livré: SF99601 Level 29
Modifié: SF99601 Level 31Journal Services QSYS2.JOURNAL_INFO Vue SF99702 Level 3 SF99701 Level 32 SF99601 Level 33 QSYS2.DISPLAY_JOURNAL() UDTF Base livré: Base
Modifié: SF99701 Level 26livré: SF99601 Level 15
Modifié: SF99601 Level 31Java Services QSYS2.SET_JVM() Procédure SF99702 Level 5 SF99701 Level 34 - QSYS2.JVM_INFO Vue SF99702 Level 5 SF99701 Level 34 - Application Services QSYS2.QCMDEXC() Procédure Base livré: Base
Modifié: SF99701 Level 26livré: SF99601 Level 15
Modifié: SF99601 Level 3
Source : Developer Works
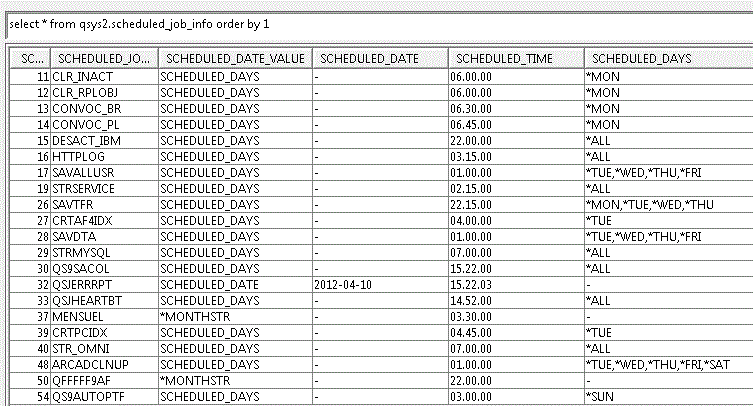
TR2 : DRDA_AUTHENTICATION_ENTRY_INFO
ACTIVE_JOB_INFO
SCHEDULED_JOB_INFO
RPG
- Le langage est devenu très puissant (voir la liste des instructions et des fonctions intégrées)
- DS à occurrences
- on peut rechercher par %LOOKUP
- on peut trier par SORTA( A | D)
- DS dans des DS
- intégration du XML (XML-INTO)
- DS à occurrences
- le langage est devenu lisible (y compris par un jeune développeur), bien intégré à RDI
Free-Form RPG (voir les pause-Café 65 et 66)

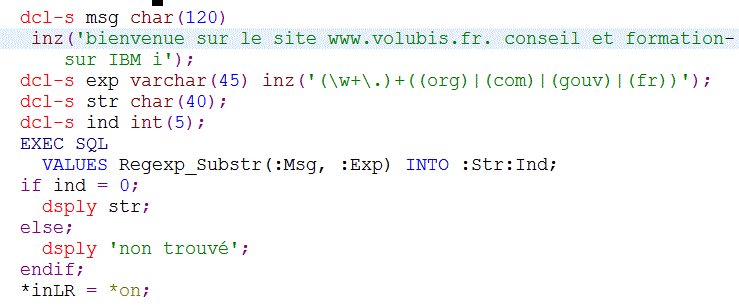
Exemple avec du SQL embarqué (utilisation des expressions régulières)
- Modulaire
- une fonction (au sens ILE) peut aisément devenir une fonction SQL (UDF)
- un programme avec des paramètres en entrée (même CL et GAP III) peut facilement devenir
- une procédure stockées, appelée via ODBC/ JDBC /DB2connect (PHP)
- un service Web (SOAP ou REST)
- Inter opérable
- API LDAP/EIM (pour ceux qui font du SSO)
- API IFS pour traiter directement des fichiers ou des répertoires
- Sockets IP pour dialoguer avec des équipements
- JNI, le projet JDBCR4 permet de se connecter aux principales bases de données (MYSQL, MSSQL, Oracle, ...)
- TR2, quelques modifications
- PCML (langage de description des paramètres, utilisé lors de la génération de web services)
- Nom des procédures généré en respectant la casse : ctl-opt PGMINFO(*PCML : *MODULE : *DCLCASE)
- choix des procédures à exposer dans le PCML : PGMINFO(*YES | *NO) sur la procédure
- voir http://www-01.ibm.com/support/knowledgecenter/ssw_ibm_i_72/rzasd/rpgrelv7r2post.htm
- PCML (langage de description des paramètres, utilisé lors de la génération de web services)
- RPG n'est pas le seul à avoir évolué, regarder le CL :
- V5R30 :
- Variables binaires
DCL VAR(&CPT) TYPE(*INT)
- support de fichiers multiples (jusqu'à 5)
DCLF FILE(ECRAN1) OPNID(ECRAN)
- Structuration du code
- DOWHILE COND( même test que sur un IF)
- DOUNTIL COND( même test que sur un IF)
- DOFOR VAR(&cpt) FROM(1) TO(22) BY(3)
- SELECT
WHEN COND( ) THEN( )
WHEN COND( ) THEN()
OTHERWISE CMD( )
ENDSELECT
- Variables binaires
- V5R40
- Pointeurs
DCL VAR(&pointeur) TYPE(*PTR)
- Sous programmes
CALLSUBR SUBR(TEST)
SUBR SUBR(TEST)
.../...
ENDSUBR
- Pointeurs
- V7
- nombreuses nouvelles fonctions intégrées
%TRIM,%CHECK,%SCAN
%CHAR,%DEC,%INT
%LOWER,%UPPER,%LEN,%SIZE
- nombreuses nouvelles fonctions intégrées
- V5R30 :
Réseau
- de nombreux produits ont fait leur apparition :
- Samba (enfin documenté) vs Netserver
- 5733SC1
- OpenSSL
- SSH /SFTP
- lancez STRTCPSVR *SSHD
- connectez vous avec Putty ou WINSCP .....
- Sous PASE vous pouvez aussi installer plein de choses... à la main.
- WGET par exemple
- SNDSMTPEMM permet d'envoyer des mails (CPYSPLF génère du PDF)
Web
- le serveur livré est Apache 2.4, serveur d'application intégré Liberty
- on peut installer Tomcat, WAS (version complète)
- TR2 : intégration de Java 8
- Il n'a jamais été aussi simple d'exposer en tant que web service un pgm RPG.
- à l'origine SOAP
- à l'origine SOAP
- Le serveur de web services, dernière version (2.6)
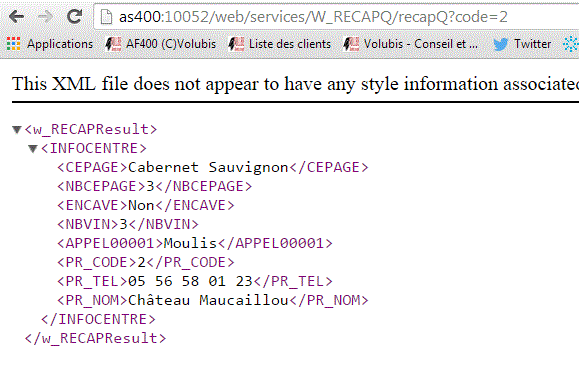
permet de créer des web services REST

Format de sortie XML
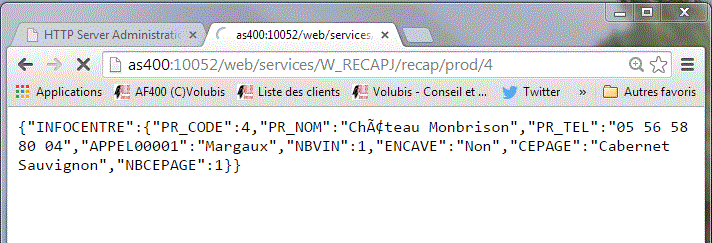
Format de sortie JSON
- TR2, ce produit est amélioré
- il est plus simple d'indiquer le nombre d'occurrences retournées
- il est possible d'indiquer le format retourné (ce n'est plus limité à XML/JSON)
- il devrait être possible (fin juin) de placer une structure à occurrences variables dans une structure
- IBM propose via un nouveau produit, l'intégration de projets Open source : 5733OPS
- Node.JS (modifié en TR2 pour intégrer une techno. FastCGI, comme PHP)
- TR 2 : PYTHON avec tous les connecteurs pour DB2.
- Vous avez donc le choix aujourd'hui
- Java
- CGI (CGIDEV2 en RPG), CGI en Python
- NetData (et oui, toujours là)
- PHP (voyez la dernière version de Zend avec Z-RAY)
- Ruby On rails
- Node.JS
- Bien sur vous pouvez aussi externaliser le serveur web/serveur d'application
- sur un serveur Linux externe
- sur une partition Linux (vous avez, pour certains, un ou deux processeurs disponibles)
- sur un serveur Windows
- Pour cela tous les connecteurs ci-dessous sont disponibles :
- JDBC (java)
- ODBC/Windows
- ODBC/Linux
- OleDB
- .Net
- DB2Connect (PHP)
- Ils permettent aussi d'envisager une architecture client serveur
- et bien sûr, les Web services (IBM i : serveur et client)
Nos outils aussi évoluent
RDI
- RSE (LE "plug-in" pour travailler avec des applications traditionnelles IBM i),
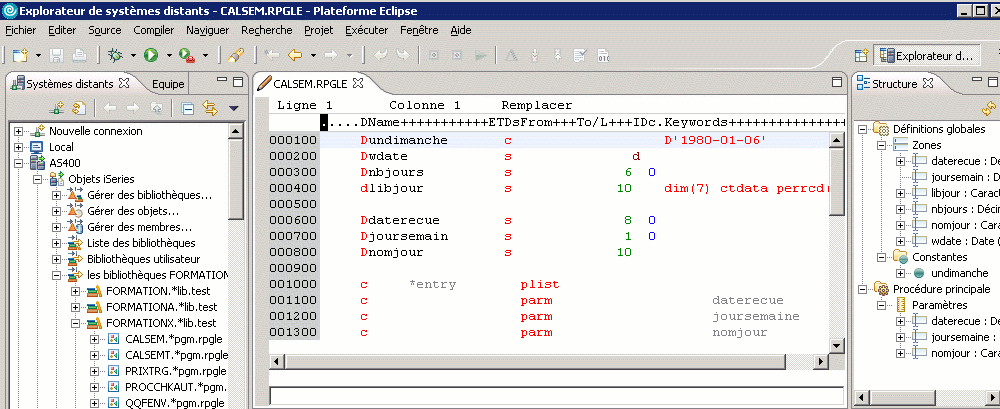
l'éditeur est bourré de trucs & astuces, comme par exemple : (Ctrl Maj+O)

un debugger vous est proposé
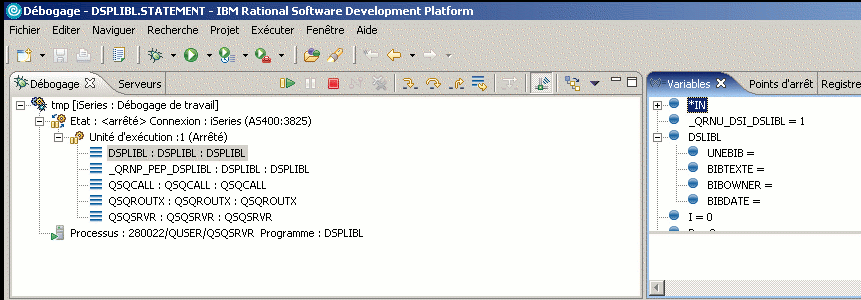
proposant une fonctionnalité très innovante : le point d'entrée de service

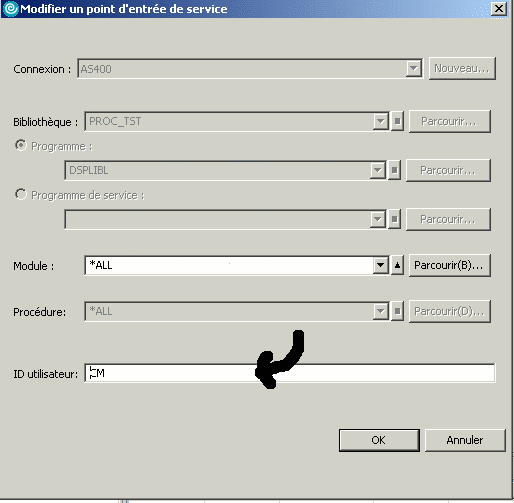
Dès qu'un programme (ici DSPLIBL dans PROC_TST) est lancé par un utilisateur donné (CM sur l'image), le debug démarre !
- Aujourd'hui, RDI est en version 9.11 (c'est un correctif, non une nouvelle version)
- le code coverage (couverture de code) accepte maintenant les programmes interactifs
Cela permet lors de vos tests (batch avant 9.11, interactif ensuite) de voir le taux de couverture de vos tests (% de lignes sur lesquelles vous êtes passé)Tout programme qui peut être débogué, peux être testé.
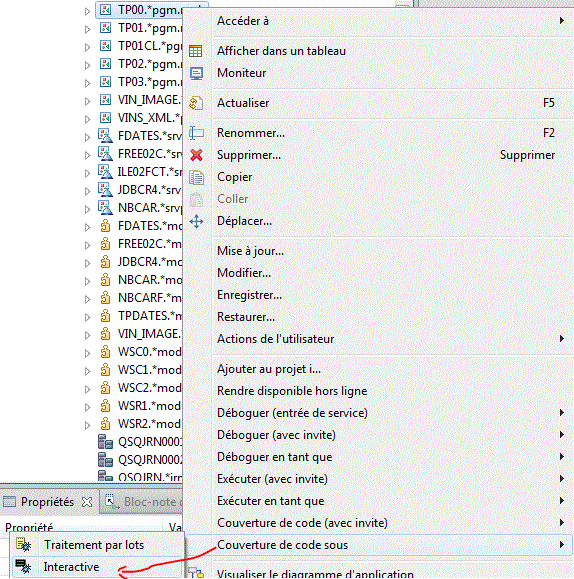
Quand l'exécution est terminé, cliquez sur la ligne
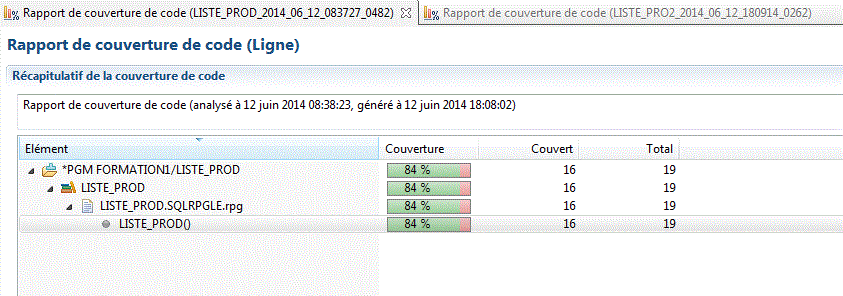
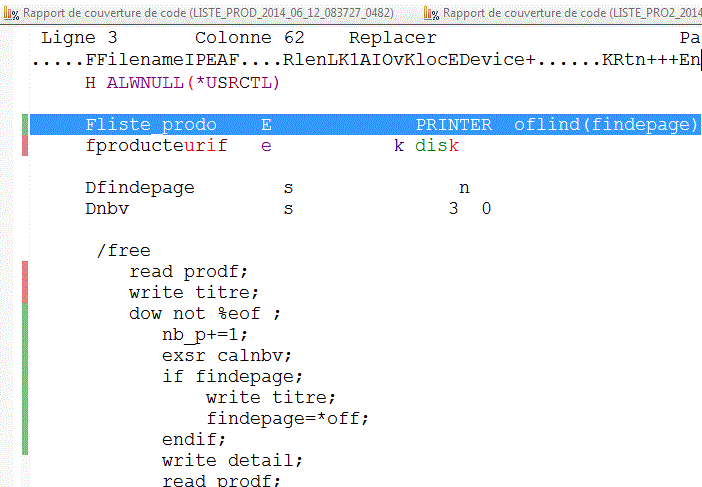
vous pouvez lancer l'éditeur :
- en vert les lignes sur lesquelles vous êtes passé
- en rouge les autres
un mécanisme de partage des ressources (filtre, actions utilisateurs, modèle) est intégré à cette version
Query vs DB2 Web Query
les dernières versions de DB2 Web QUERY, proposent
- un connecteur pour les fichiers CSV et EXCEL
- un assistant pour télécharger des feuilles Excel dans le produit (UPLOAD)
- un assistant pour la création de méta-données et de dimensions
Voyez les deux dernières vidéos de ce wiki pour survoler ces nouveautés
https://www.ibm.com/developerworks/community/wikis/home?lang=en#!/wiki/W516d8b60d32c_4fc5_a811_5f3d840bf524/page/Getting%20Started%20Videos
- Enfin, depuis fin Mars, un ETL (facturation supplémentaire) : Data Migrator
Client Access
LE produit stratégique c'est ACS (5733XJ1 , version Java), il évolue en TR2 (V1R1M4)
La version WEB (XH2) intègre une version pour mobiles

Tout en ayant été déclaré stabilisé en version 7.1, System i navigator continue d'intégrer les nouveautés DB2
Particulièrement tout ce qui est surveillance des performances SQL
En V5R40
- Le centre de santé affiche des informations sur vos bases en % des maximas DB2
C'est lui qui permet de voir graphiquement le contenu de QSYS2.SYSLIMTBL
- Les moniteurs SQL proposent des sélections (bibliothèque, tables, durée) au lancement et à l'affichage
- en TR2, DATABASE_MONITOR_INFO() donne la liste des moniteurs
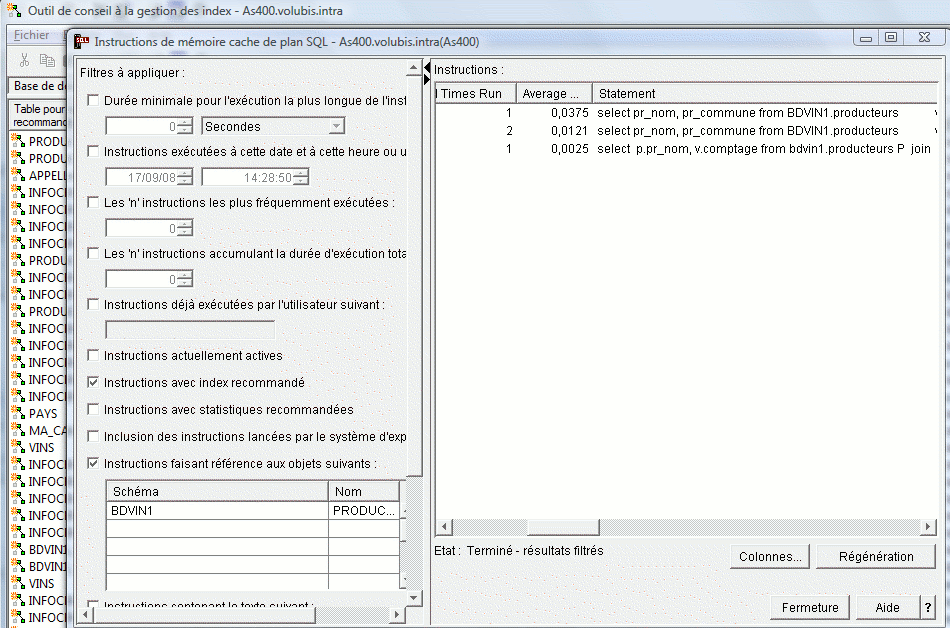
- Consultation du cache des plans d'accès avec le même affichage que les moniteurs
- Ce dernier suggérant les index manquant en temps réel (assistant de gestion des index)
- La liste des index indique quand un index a été utilisé, même implicitement pour la dernière fois
En V6R10
• Moniteurs
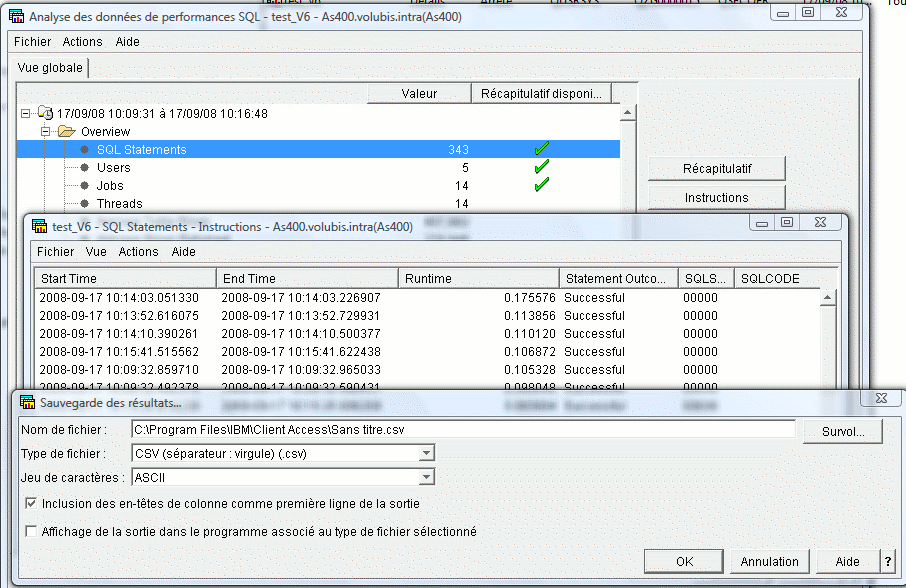
Sur un affichage récapitulatif, à l'affichage des instructions (Analyse, puis clic droit sur une ligne / instructions),
l'option fichier propose, maintenant, une sauvegarde de la liste des instructions SQL
Sur le même affichage, vous pouvez maintenant, placer la requête SQL dans le gestionnaire de script avec les valeurs des variables, ou les marqueurs SQL (?)
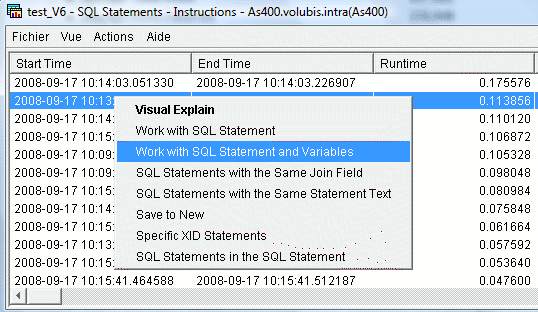
Enfin, vous pouvez comparer deux moniteurs 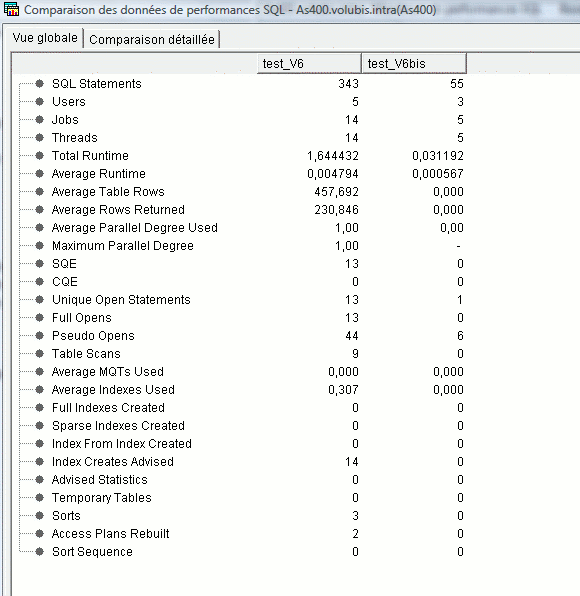
TR2, vous pouvez demander un récapitulatif :
- par Travail
- par Nom de travail
- un récapitulatif par Table
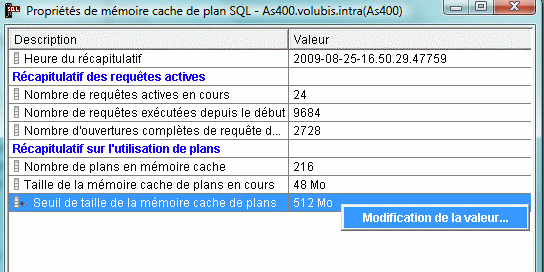
• Cache des plans d'accès
- la taille peut être ajustée par CALL QQQOOOCACH PARM('R:1024')
ou par iSeries Navigator (Mémoire cache de plan SQL/propriétés)
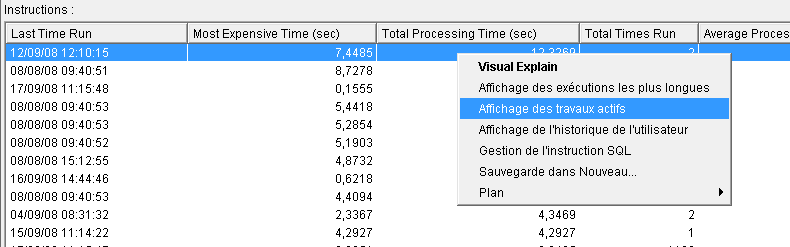
Les possibilités d'affichage sur une instruction ont été étendues :
- l'affichage des instructions les plus longues est limité aux 500 premières
- vous pouvez demandez la liste des travaux utilisant actuellement cette instruction
- et la liste des utilisateurs ayant utilisé cette instruction (historique de l'utilisateur)
Vous pouviez déjà en V5R40 sauvegarder le cache sous forme d'images instantanées :
par l'interface graphique sous Images instantanées de mémoire cache de plan SQL
par la procédure cataloguée DUMP_PLAN_CACHE , qui en V6 est automatiquement enregistrée au même endroit.Quand le cache est plein il est automatiquement épuré, en V6 il est possible de placer un moniteur sur cet événement afin de le sauvegarder en fichier avant
• Gestion des index
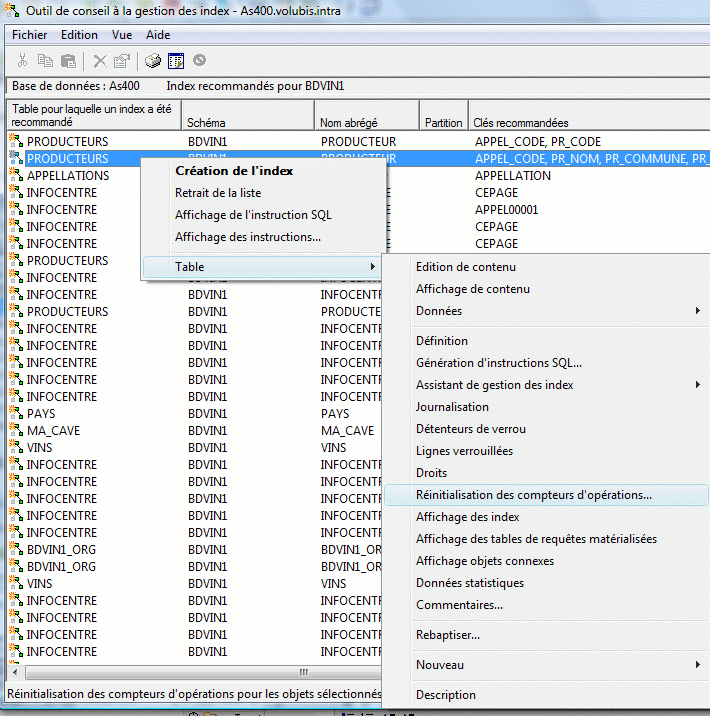
l'assistant de gestion d'index (qui affiche les index suggérés, globalement, pour une bibliothèque ou pour une table) a été amélioré :
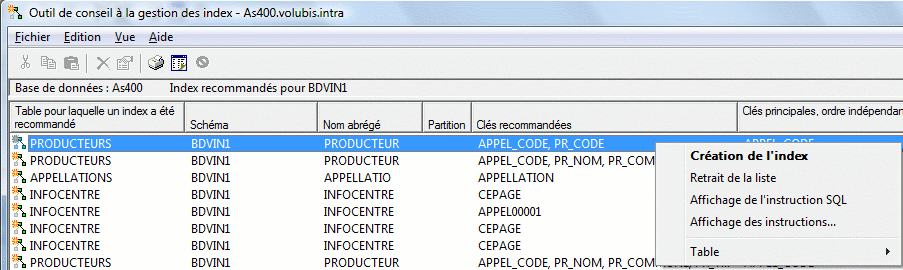
- Affichage de l'instruction SQL est nouveau en V6
- ainsi que l'accès direct aux instructions qui ont provoqué cette suggestion (dans le cache)
- l'assistant affiche aussi le nombre de fois ou un index a été suggéré et, s'il a été créé automatiquement (MTI), le nombre de fois ou il a été utilisé
Ce compteur peut-être réinitialisé pour la table, par le menu contextuel suivant :
Les procédures fournies à titre d'exemple dans SYSTOOLS, permettent d'automatiser des traitements
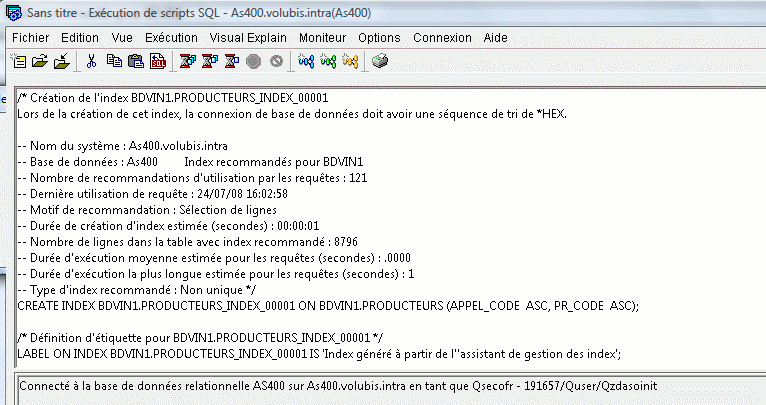
- ACT_ON_INDEX_ADVICE, création d'index suggérés (sur critères)
- HARVEST_INDEX_ADVICE, génération des instructions de création d'index dans un membre source
- REMOVE_INDEXES, suppression (sur critères) des index inutiles
TR2 : la nouvelle procédure CLEAR_PLAN_CACHE permet d'éviter un IPL sur les machines de test.
Comme vous le voyez, les possibilités d'analyse de l'activité Base de Données sont immenses !
D'ou la question posée à Mike CAIN, nous faut-il un DBA ?
| Could you explain why a company must point someone as DBE? – There is so much science and art in the are of information management these day, someone must be responsible for understanding the subject, and applying the techniques to get the most value out of data. This is no longer an optional thing. The world runs on data, and you need to be good at. http://db2fori.blogspot.com/2012/11/db2-for-i-database-engineer-description.html |
Bon, et qu'est-ce qu'on fait ?
Ci-dessous quelques éléments de réflexion :
- le pire serait de ne rien faire !
- Nous allons avoir de nouveaux besoins (web , mobiles, etc....)
- Nous allons avoir de nouveaux collaborateurs (forcement !)
Je vous propose d'analyser le problème selon cinq axes :
- L'interface
- La base de données
- le code
- les outils
- l'architecture
L'interface (5250)
- Autant les terminaux peuvent être utiles dans certains cas, autant on ne peut pas considérer le 5250 comme une interface d'avenir ;-)
- revoir l'interface avec des outils plus ou moins automatiques, est un bon moyen :
- de redorer le blason de l'IBM i (voire de faire croire qu'il a disparu)
- d'avoir du temps pour le fond (ce qui suit)
La base de données.
- Pour nous cela est clair, à partir de maintenant, il faut concevoir la base en SQL (pour les nouveaux fichiers) et penser "data centric", c'est à dire faire faire à DB2 tout ce qu'il sait faire, ca fait ça de moins dans les programmes, ca fait de moins comme aller/retour si nous pensons web/mobiles.
- faut-il revoir l'existant ?
- des outils vous le proposent
- A la main, c'est possible (pour la partie structure c'est automatisable)
- trigger, pourquoi pas, quand ça ce justifie.
- intégrité référentielle, attention aux traitements existants !
- est-ce la priorité, si vous êtes contingenté par le temps ? (c'est souvent une litote)
Le code (RPG particulièrement)
- Pour nous cela est clair, à partir de maintenant, il faut écrire vos programmes en free-form RPG
- plus lisible (si ! si !)
- plus facile d'intégrer les jeunes
- plus facile d'évoluer, de basculer vers d'autres langages
- faut-il revoir l'existant ?
- des outils vous le proposent
- A la main, c'est compliqué (CVTRPGSRC ne fait pas vraiment le boulot !)
- mais apprendre le GAP III (ou II) au moins de 30 ans, est-ce raisonnable ?
Les outils
- On imagine pas se passer du mode commandes, mais vous n'imaginez pas comme nos jeunes stagiaires sont rassurés quand ils découvrent System i Navigator !
- Pourquoi ce faire du mal volontairement (essayez Linux sans interface...)
- de toutes façons, il y a pleins de fonctionnalités qui ne sont valides que dans ce monde là
- surveillance des performances base de données
- surveillance des performances systèmes avec PDI sous Navigator for i.
- gestion centralisée (notre prochain cours en ligne)
- configuration des principaux serveurs IP (DHCP, DNS, Netserver, FTP, ...)
- et puis essayez RDI, passé les 15 premiers jours, vous ne reviendrez pas en arrière
- colorisation syntaxique
- gestion des boucles
- complétion de code (ctrl+espace)
- fenêtre structure
- gestion des erreurs de compilation
- Degug !
- de toutes façons, il y a pleins de fonctionnalités qui ne sont valides que dans ce monde là
Architecture
- Les millions de lignes écrite ces 25 (30 ?) dernières années représentent une valeur,voire une fortune !
Ce qui est confirmé par le "vice-président de la force de vente " Power i" (Alex Gogh)
"We have an opportunity in Power i that we've never had," Gogh said. "I've been around Power i for all of my 32 years in IBM. . . This is our moment in Power i and this is our opportunity and here's why." So what, exactly, is that opportunity? The way Gogh sees it, the investments that IBM i customers have made in their core applications and systems makes them well-positioned to take their businesses to the next level, and to start benefiting from the explosion of new capabilities that can be found in the world of (brace yourself) cloud, mobile, social, and analytics. |
source ItJungle, mai 2015
- MVC

Le pgm qui constitue la donnée (qui fait la liste, qui valorise la données, etc...) n'est PAS le programme qui affiche !
Le pgm qui écrit/met à jour la donnée, est autonome, unique !
- SOA

un programme=un service / un service(un besoin)=un programme
les autres concepts sont un peu plus compliqués à matérialiser, surtout sur des langages procéduraux.
Tout programme, peut ainsi devenir : - une fonction SQL utilisable dans tous les contextes
- une procédure stockées pour ODBC/JDBC
- un service web (Couplages externes "lâches") qui respectent le mieux l'architecture SOA
Il est ainsi possible d'envisager l'urbanisation du Système d'information
Il s'agit de mettre en place un Plan d'urbanisme en s"appuyant sur une cartographie fonctionnelle du SI et un découpage en entités autonomes, de description de plus en plus fine (source Wikipedia) :
- les zones,
- les quartiers,
- les îlots,
- et enfin les blocs fonctionnels ou encore les briques
L'urbanisation répond à deux règles de bases :
- Une application doit appartenir -à terme- à un et un seul bloc.
- Les dépendances doivent respecter les notions de Cohérence Forte / Couplage Faible
- entre les applications,
- au sein d'une application : entre les différents modules,
- au sein d'un module : entre les différents composants, d'où l'extrême modularité
cette démarche peut se mettre en œuvre :
- de manière opportuniste : à l’occasion d’un projet de développement, de refonte ou de maintenance,
- de manière plus volontariste : dans le cadre d’un chantier d’urbanisation.
Exemple
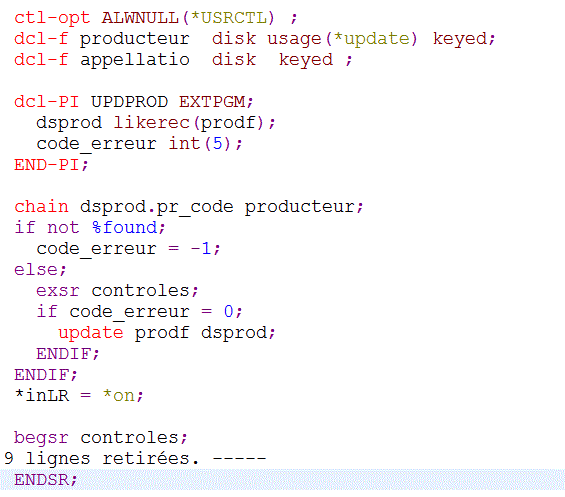
Il parait assez simple d'imaginer un programme réalisant (de manière autonome) la mise à jour d'un fichier
- réception de l'enregistrement en tant que paramètre
- d'un code erreur à retourner
- si les contrôles ne positionnent pas de code erreur => mise à jour
Ce pgm sera invoqué comme ceci :

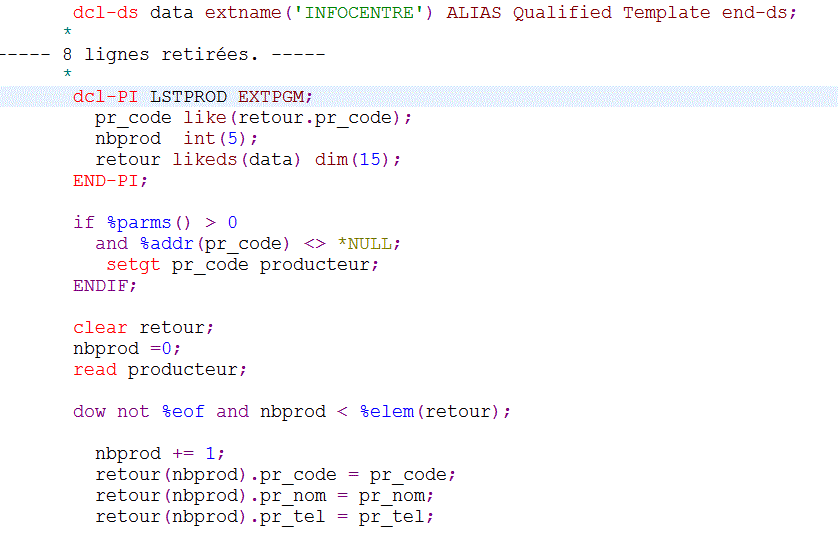
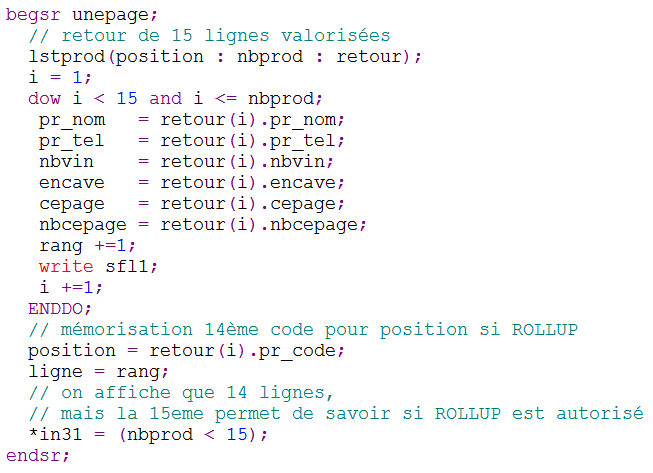
Regardons plutôt un programme de constitution d'une liste de données valorisées.
Soit un programme (sans doute avec une partie du code hérité d'un ancien traitement)
Qui retourne des informations concernant les 15 producteurs qui suivent (SETGT) celui passé en paramètre
Ce pgm a trois paramètres en entrée
- Pr_Code pour le positionnement dans le fichier producteur
- NbProd pour retourner le nombre de producteurs réellement lus
- Retour une DS à 15 occurrences (pas forcément toutes chargées)
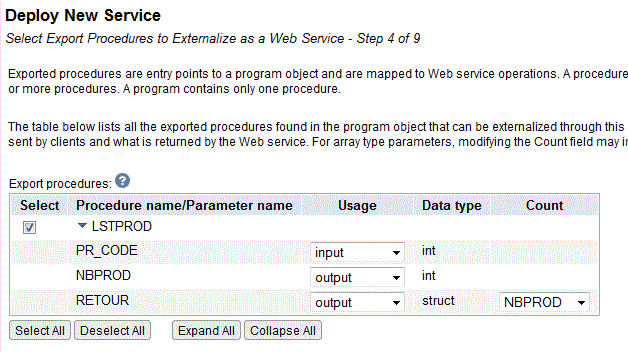
Ce programme peut facilement être transformé en Web service (ici SOAP)
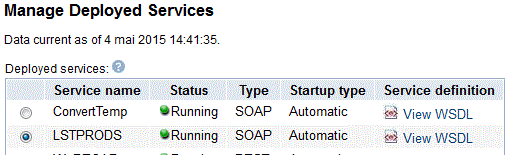
Testons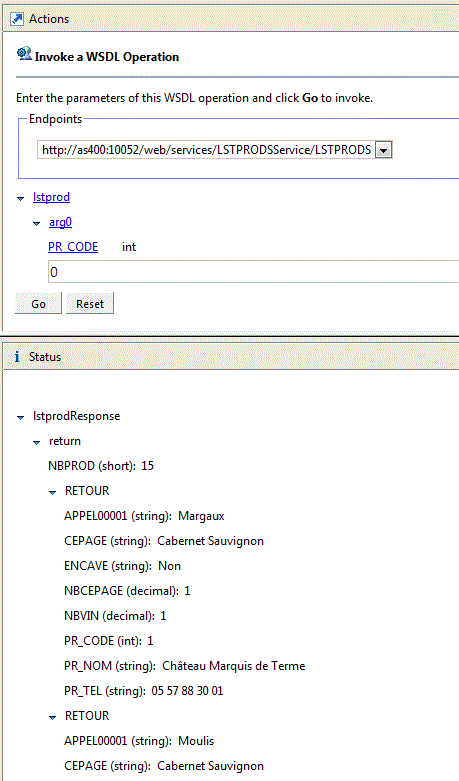
ou bien, avec les derniers niveaux de PTF, en web service REST
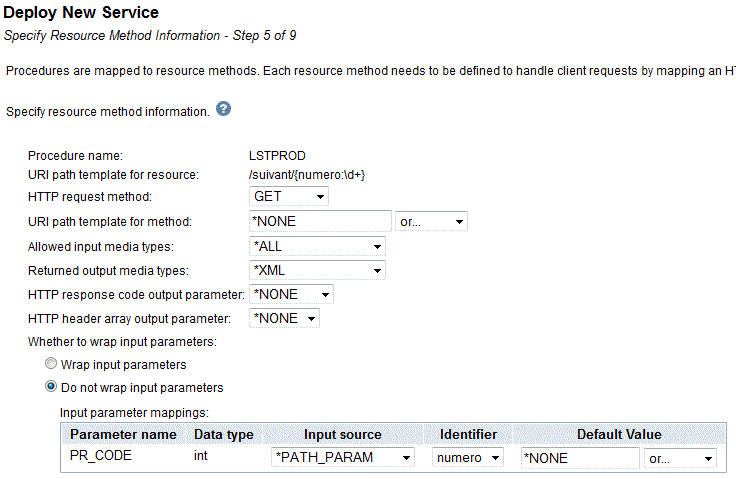
et voilà
Donc lancé, depuis une simple URL
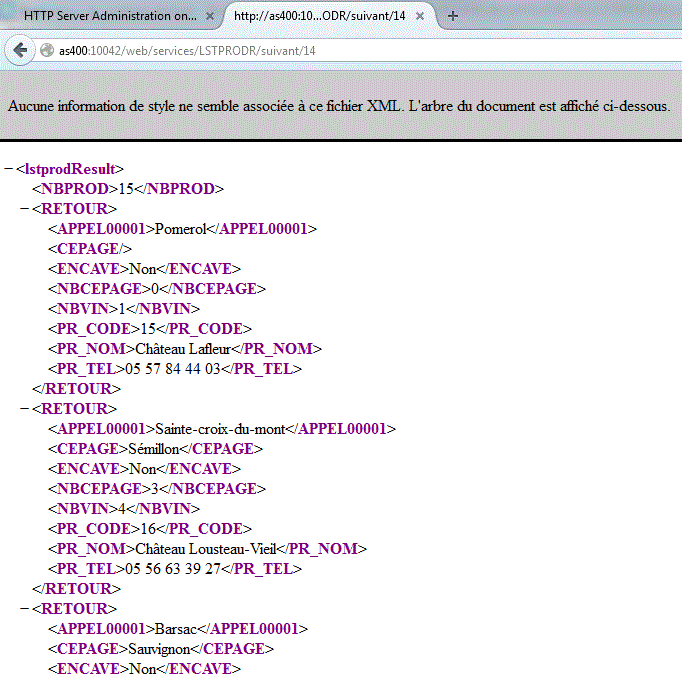
voire, utilisé en SQL (fonction HTTPGETBLOB + XMLTABLE)
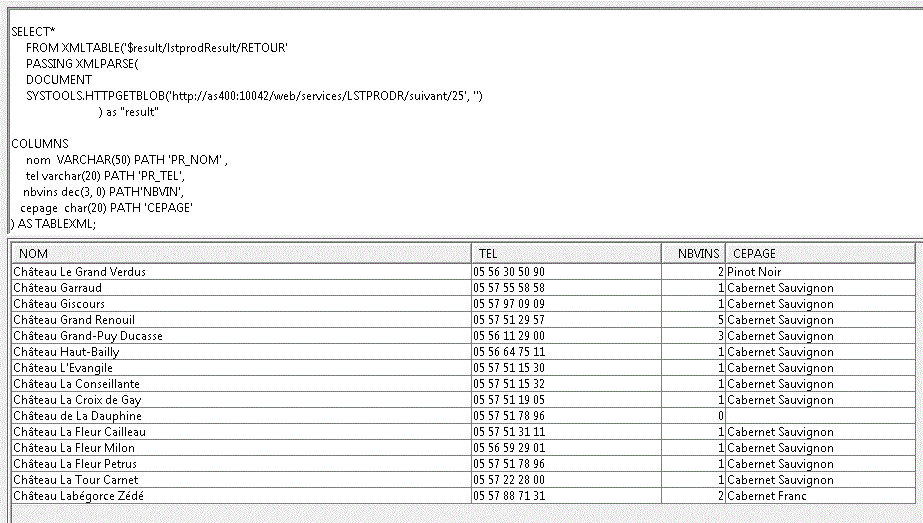
Ou si vous le préférez, transformé en Procédure stockée (on ajoute une interface pour gérer le RESULT SET SQL)
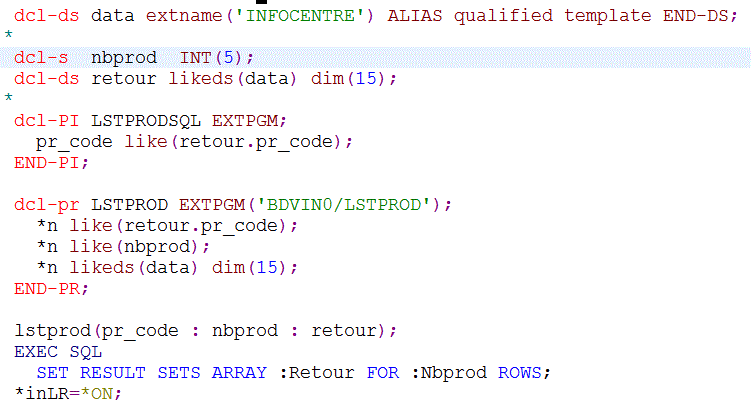
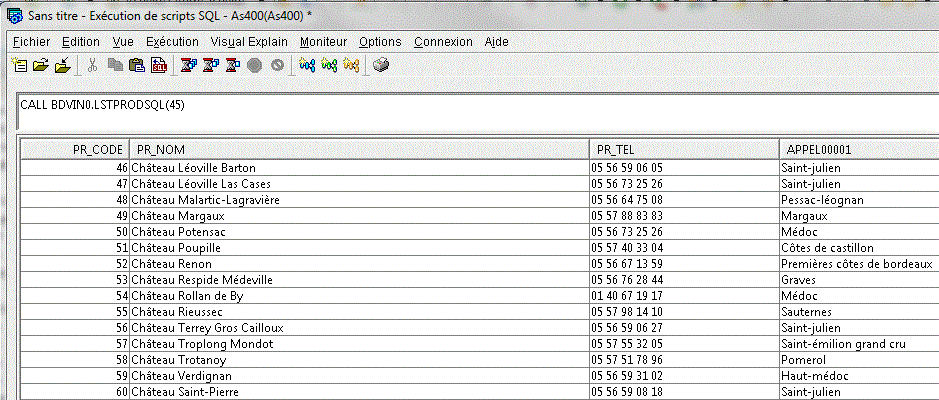
Et il devient utilisable directement, via JDBC/ODBC
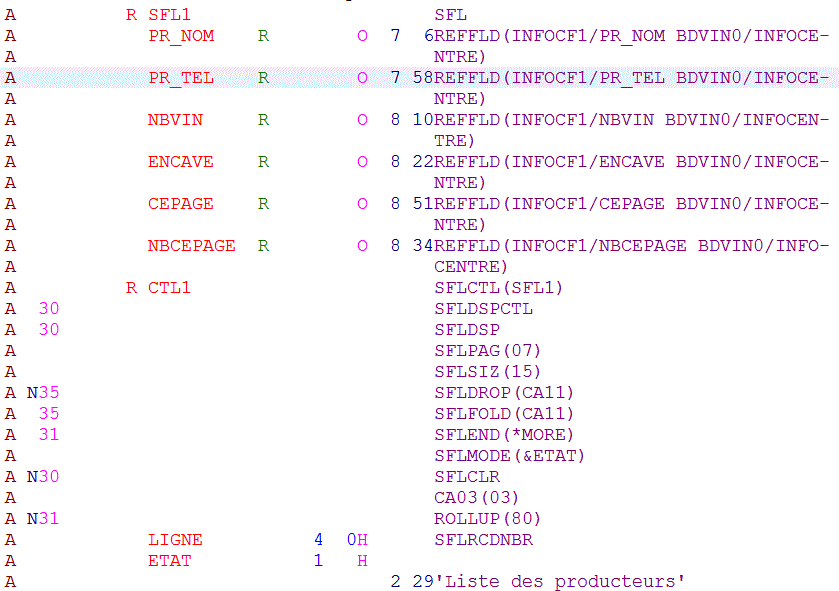
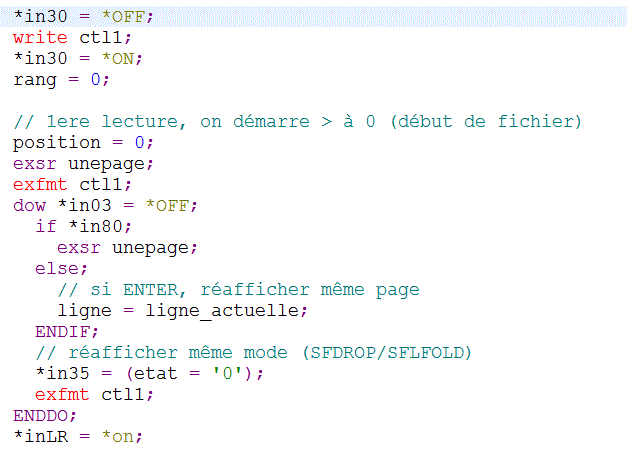
Enfin, le monde 5250 n'est pas oublié pour autantsoi le DSPF suivant (avec sous fichier)
SFLMODE retourne dans ETAT :
- '1' quand l'affichage est tronqué
- '0' quand l'affichage est multi-ligne
ET le PGM RPG
déclarations
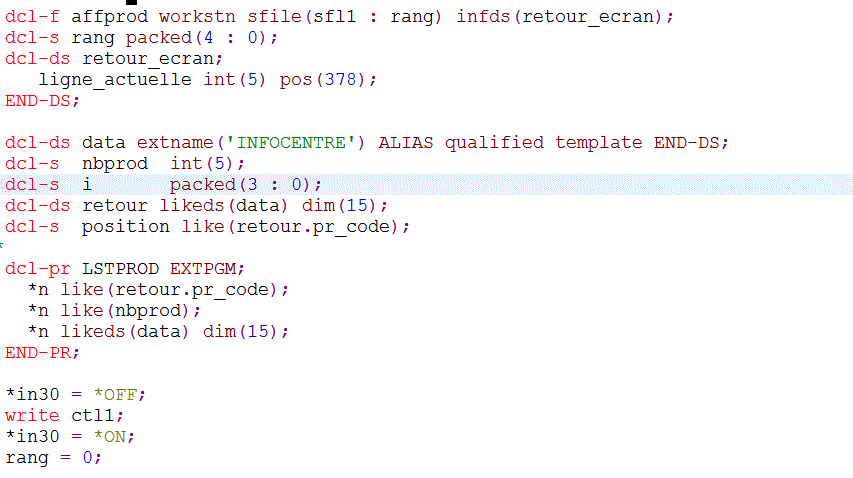
boucle principale
Sous programme de chargement d'une page
On ne charge que 14 lignes par page (SFLPAG)
Remarquez la gestion de l'indicateur 31, qui teste s'il y a 15 lignes (au moins encore une ligne = ROLLUP autorisé)
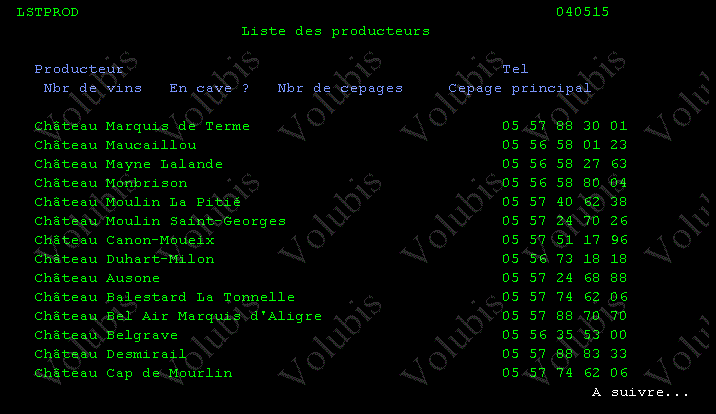
Résultat

Notons aussi l'apparition d'un produit dans le même esprit : OpenLegacy
Voyez l'article dans ITJungle http://www.itjungle.com/tfh/tfh060115-story03.html
Il s'agit d'un produit Open Source (il y a une version payante avec support) qui possède des connecteurs

Dont un connecteur "Telnet", fournissant des API pour exposer en tant que services REST des applications existantes (IBM i et Z/OS)

Le produit est livré sous forme de Plug-In pour Eclipse et tourne ensuite sous Apache/Tomcat.