
pause-café
destinée aux informaticiens sur plateforme IBM i.
Pause-café #56
IBM i , V7.1 - suite...
Intégration XML à DB2
La version 7.1 de IBM i apporte à SQL l'intégration du langage XML.
Cette intégration a été normalisée sous le nom de SQLXML, elle propose :
- Champs de type XML avec possibilité de validation d'un schéma XSD lors de l'insertion
- Fonctions pour produire du XML à partir de données élémentaires
- Sérialisation du XML en types simples (CHAR, BLOB, ...)
- Transformation du XML avec XSLT
- possibilité d'import/export avec des annotations XSD.
- dans le même temps le produit OmniFind (5733OMF) est livré en V1R2 et permet l'indexation et la recherche de champs XML.
Le type XML
commençons par la création d'une table avec le type de champs XML, tel que donné par la documentation
SET CURRENT SCHEMA POSAMPLE;
CREATE TABLE CUSTOMER ( CID BIGINT NOT NULL PRIMARY KEY , INFO XML ) ;Les champs de type XML peuvent faire jusqu'à 2 Go, la totalité d'une ligne ne peut pas dépasser 3,5 Go.
Ils sont stockés dans le CCSID indiqué par SQL_XML_DATA_CCSID dans QAQQINI, UTF-8 (1208) par défaut.
Puis insertion de données, le parsing (la conversion CHAR -> XML) est automatique lors des insertions,
mais vous pouvez parser de manière explicite avec XMLPARSE() pour utiliser des options (voir cette fonction)
'<customerinfo xmlns="http://posample.org" Cid="1000">
<name>Kathy Smith</name>
<addr country="Canada">
<street>5 Rosewood</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
<pcode-zip>M6W 1E6</pcode-zip>
</addr>
<phone type="work">416-555-1358</phone>
</customerinfo>') INSERT INTO Customer (Cid, Info) VALUES (1002,
'<customerinfo xmlns="http://posample.org" Cid="1002">
<name>Jim Noodle</name>
<addr country="Canada">
<street>25 EastCreek</street>
<city>Markham</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N9C 3T6</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
</customerinfo>') INSERT INTO Customer (Cid, Info) VALUES (1003,
'<customerinfo xmlns="http://posample.org" Cid="1003">
<name>Robert Shoemaker</name>
<addr country="Canada">
<street>1596 Baseline</street>
<city>Aurora</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N8X 7F8</pcode-zip>
</addr>
<phone type="work">905-555-2937</phone>
</customerinfo>')le document doit être bien formé, sinon vous recevrez SQ20398
ID message . . . . . . : SQ20398
Message . . . . : Echec de l'analyse syntaxique XML.
Cause . . . . . : L'analyse syntaxique XML a échoué pendant le traitement
SQL. Le décalage en octets dans la valeur XML en cours de traitement après
conversion en UTF-8 est de 203. La description de l'erreur de l'analyseur
syntaxique XML est la suivante : Element type "addr" must be followed by
either attribute specifications, ">" or "/>".
Que faire . . . : Corrigez la valeur XML. Renouvelez ensuite votre demande.
Voyons le résultat
Attention : Client Access V7 impératif !
Sous une session 5250, la sérialisation (conversion en une chaîne simple) n'est pas faite par défaut :
il faut utiliser XMLSERIALIZE(INFO as CHAR(2000) ) pour voir le contenu, le CCSID du job doit être renseigné (pas de 65535).
La zone INFO doit être manipulée dans sa totalité, il n'est pas possible de n'afficher ou de ne modifier que la ville du flux xml précédent.
par exemple
'<customerinfo xmlns="http://posample.org" Cid="1002">
<name>Jim Noodle</name>
<addr country="Canada">
<street>1150 Maple Drive</street>
<city>Newtown</city>ity>
<prov-state>Ontario</prov-state>
<pcode-zip>Z9Z 2P2</pcode-zip>
</addr>r>
<phone type="work">905-555-7258</phone>
</customerinfo>'
where cid = 1002
Comment manipuler du XML en programmation (RPG et COBOL particulièrement)
Il faut pour cela revoir la manipulation des BLOB et CLOB tel que vue en V4R40.
> Une colonne de type LOB peut-être manipulée par
-son contenu (si votre langage supporte des variables aussi grandes)
vous devez déclarer en RPG par:
DMYBLOB S SQLTYPE(BLOB:500)
ce qui génère :
D MYBLOB DS D MYBLOB_LEN 10U 0 D MYBLOB_DATA 500A
L'exemple suivant montre comment utiliser les BLOB en JAVA:
Blob img = resultSet.getBlob ; long lg = blob.length (); byte[] R = img.getBytes (0, (int) lg);
-vous pouvez utiliser un identifiant appelé "LOCATOR", qui permet :
+ de ne pas transférer les data dans le programme (donc sur le PC)
+ de faire des copies de fichiers ...
vous devez déclarer en RPG par:
D MYCLOB S SQLTYPE(CLOB_LOCATOR)
ce qui génère :
D MYCLOB S 10U 0
vous pouvez utiliser l'identifiant en lieu et place de la colonne par les nouvelles instructions SET et VALUE.
C/EXEC SQL C+ VALUE POSSTR(:MYCLOB, 'formation') INTO :debut C/END-EXEC
-vous pouvez utiliser un fichier appelé "FILE LOCATOR", qui permet :
+ de copier le contenu d'un LOB dans un fichier IFS
+ de renseigner un LOB à partir du contenu d'un fichier IFS.
vous devez déclarer en RPG par:
D MYFILE S SQLTYPE(CLOB_FILE)
ce qui génère :
D MYFILE DS D MYFILE_NL 10U 0 [lg du nom] D MYFILE_DL 10U 0 [lg des Data] D MYFILE_FO 10U 0 [file permission] * SQL génère SQFRD (2), SQFCRT (8), SQFOVR(16) et SQFAPP(32) D MYFILE_NAME 255A [nom du fichier]
en Working Storage Section :
01 rapport USAGE IS SQL TYPE IS CLOB-FILE
puis en traitement
move "RAPPORT.TXT" to rapport-NAME. move 11 to rapport-LENGTH. move SQL-FILE-OVERWRITE to rapport-FILE-OPTIONS.
EXEC SQL SELECT rapport INTO :rapport FROM ... WHERE ... END-EXEC.
ce traitement place copie du contenu de la colonne "rapport" dans le fichier "RAPPORT.TXT" qui est un fichier IFS. un ordre INSERT aurait renseigné la colonne par copie du fichier.
LE XML se manipule de la même manière avec les types suivants
- XML_BLOB
- XML_CLOB
- XML_DBCLOB (à privilégier, pour rappel le XML est par défaut stocké en CCSID 1208)
La déclaration suivanteD MON_XML S SQLTYPE(XML_DBCLOB:2500)Génère :
D MON_XML DS D MON_XML_LEN 10U D MON_XML_DATA C LEN(2500)
- XML_LOCATOR
- XML_BLOB_FILE
- XML_CLOB_FILE
- XML_DBCLOB_FILE
La déclaration suivanteD MON_FICHIERXML S SQLTYPE(XML_CLOB_FILE)Génère :
D MON_FICHIERXML DS D MON_FICHIERXML_NL 10U D MON_FICHIERXML_DL 10U D MON_FICHIERXML_FO 10U D MON_FICHIERXML_NAME 255A
Exemples en RPG (rappel, par défaut les champs XML sont en UNICODE) * récupération du XML dans une variable du langage *=================================================
D MON_XML S SQLTYPE(XML_DBCLOB:2500)
D pos S 5i 0
/free
exec sql
select info into :mon_xml from posample/customer
where cid = 1000;
eval pos = %scan(%ucs2('phone') :mon_xml_data); //pos = 260
*inlr = *on;
/end-free * récupération du XML dans un fichier de l'IFS *==============================================
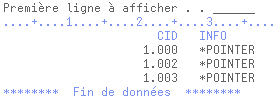
DMON_FICHIERXML S SQLTYPE(XML_DBCLOB_FILE) /free mon_fichierxml_name = '/temp/xml01.xml'; mon_fichierxml_nl = %len(%trim(mon_fichierxml_name)); mon_fichierxml_fo = SQFOVR;exec sql select info into :mon_fichierxml from posample/customer where cid = 1000;
*inlr = *on; /end-freele fichier xml01.xml est bien généré dans /temp (CCSID 1208) et contient :
Record : 1 of 3 by 18 Column : 1 132 by 131
Control :
....+....1....+....2....+....3....+....4....+....5....+....6....+....7....+....8....+....9....+....0....+....1....+....2....+....3.
************Beginning of data**************
<?xml version="1.0" encoding="UTF-8"?><customerinfo xmlns="http://posample.org" Cid="1000"><name>Kathy Smith</name><addr country="Ca
nada"><street>5 Rosewood</street><city>Toronto</city><prov-state>Ontario</prov-state><pcode-zip>M6W 1E6</pcode-zip></addr><phone typ
e="work">416-555-1358</phone></customerinfo>
************End of Data********************un ordre INSERT aurait lu le fichier XML de l'IFS et placé son contenu dans une colonne de la table SQL.
Les fonctions ligne à ligne (scalaires) permettant de produire du XML :
(tous les exemples sont lancés depuis iSeries navigator, sous 5250 il faudrait utiliser XMLSERIALIZE):
- XMLDOCUMENT : production d'un flux XML à partir d'une chaîne de caractère (validation comprise).
Cette action est implicite lors des ordres INSERT et UPDATE, comme vu plus haut.
- XMLPARSE : production après vérification, d'un flux XML, avec choix de conservation des espaces ou non
--STRIP WHITESPACE--- XMLPARSE(DOCUMENT '<xml> ... </xml>' | | -PRESERVE WHITESPACE-
- XMLVALIDATE : validation d'un flux XML à l'aide d'un schéma XSD enregistré dans XSROBJECTS (voir ci-dessous)
XMLVALIDATE(DOCUMENT '<xml> ... </xml>' ACCORDING TO XMLSCHEMA --> |---ID un-schéma-enregistré--| >---| |---- |--une URI valide------------|
- XMLTRANSFORM : transforme un flux XML à l'aide de XSLT
- XMLTEXT : production d'un texte compatible XML
select XMLTEXT('100 est > à 99 & à 98')
FROM SYSIBM.SYSDUMMY1 ;100 est > à 99 & à 98
- XMLELEMENT : production d'un élément XML
<region>Ahr </region>
<region>Alsace </region>
<region>Andalucía </region>
<region>Aragón </region>
Cette fonction peut être imbriquée
xmlelement(name "appellation" , appellation),
xmlelement(name "region" , region_code) )
from bdvin1.appellations ; <Appellations><appellation>Alella D.O. </appellation><region>21</region></Appellations>
<Appellations><appellation>Ampurdàn- costa brava D.O </appellation><region>21</region></Appellations>
<Appellations><appellation>Anoia </appellation><region>21</region></Appellations>
<Appellations><appellation>Bajo ebro-montsià </appellation><region>21</region></Appellations>
<Appellations><appellation>Conca de barberà D.O </appellation><region>21</region></Appellations>
<Appellations><appellation>Conca de tremp </appellation><region>21</region></Appellations>
<Appellations><appellation>Costers del segre D.O </appellation><region>21</region></Appellations>
- XMLATTRIBUTES : production d'un attribut, uniquement valide dans XMLELEMENT
select xmlelement(name "Appellations", XMLATTRIBUTES(pays_code as "pays"), appellation , region_code ) from bdvin1.appellations join bdvin1.regions using (region_code) ;
<Appellations pays="11">Alella D.O. 21</Appellations>
<Appellations pays="11">Ampurdàn- costa brava D.O 21</Appellations>
<Appellations pays="11">Anoia 21</Appellations>
<Appellations pays="11">Bajo ebro-montsià 21</Appellations> select xmlelement(name "Appellations", XMLATTRIBUTES(pays_code as "pays"),
xmlelement(name "appellation" , appellation),
xmlelement(name "region" , region_code) )
from bdvin1.appellations join bdvin1.regions using (region_code) ; <Appellations pays="11"><appellation>Alella D.O. </appellation><region>21</region></Appellations>
<Appellations pays="11"><appellation>Ampurdàn- costa brava D.O </appellation><region>21</region></Appellations>
<Appellations pays="11"><appellation>Anoia </appellation><region>21</region></Appellations>
<Appellations pays="11"><appellation>Bajo ebro-montsià </appellation><region>21</region></Appellations>
- XMLNAMESPACES , production d'un balise d'espace de nommage (namespace)
select xmlelement(name "vin:Appellations", XMLNAMESPACES('http://www.volubis.fr/vins/1.0' AS "vin") ,
appellation , region_code )
from bdvin1.appellations join bdvin1.regions using (region_code) ; <vin:Appellations xmlns:vin="http://www.volubis.fr/vins/1.0">
Alella D.O. 21
</vin:Appellations>
- XMLPI , production d'une balise processing instruction
FROM SYSIBM.SYSDUMMY1<?Instruction APPUYEZ SUR ENTREE?>
- XMLCOMMENT, production d'un commentaire XML
select XMLCOMMENT('A consommer avec modération')
FROM SYSIBM.SYSDUMMY1 ;<!--A consommer avec modération-->
- XMLCONCAT, production d'un flux XML à partir de la concaténation de deux.
select XMLCONCAT(XMLELEMENT(name "region" , region) , XMLELEMENT(name "pays" , pays_code)) from bdvin1.regions; ;<region>Abruzzo </region><pays>18</pays>
<region>Ahr </region><pays>2</pays>
<region>Alsace </region><pays>12</pays>
<region>Andalucía </region><pays>11</pays>
- XMLFOREST, production d'une suite d'éléments XML à partir des colonnes d'une table
<REGION>Ahr </REGION><PAYS_CODE>2</PAYS_CODE>
<REGION>Alsace </REGION><PAYS_CODE>12</PAYS_CODE>
<REGION>Andalucía </REGION><PAYS_CODE>11</PAYS_CODE> select XMLFOREST(region AS "region" , pays_code as "pays") from bdvin1.regions; <region>Abruzzo </region><pays>18</pays>
<region>Ahr </region><pays>2</pays>
<region>Alsace </region><pays>12</pays>
<region>Andalucía </region><pays>11</pays>
- XMLROW, production d'une ligne XML à partir des colonnes d'une table
<row><APPELLATION>Ampurdàn- costa brava D.O </APPELLATION><REGION_CODE>21</REGION_CODE></row>
<row><APPELLATION>Anoia </APPELLATION><REGION_CODE>21</REGION_CODE></row>
<row><APPELLATION>Bajo ebro-montsià </APPELLATION><REGION_CODE>21</REGION_CODE></row>
<row><APPELLATION>Conca de barberà D.O </APPELLATION><REGION_CODE>21</REGION_CODE></row>
<row><APPELLATION>Conca de tremp </APPELLATION><REGION_CODE>21</REGION_CODE></row>
<row><APPELLATION>Costers del segre D.O </APPELLATION><REGION_CODE>21</REGION_CODE></row>
<row><APPELLATION>Penedés D.O </APPELLATION><REGION_CODE>21</REGION_CODE></row> select XMLROW(appellation, region_code OPTION ROW "une_appellation") from bdvin1.appellations; <une_appellation><APPELLATION>Alella D.O. </APPELLATION><REGION_CODE>21</REGION_CODE></une_appellation>
<une_appellation><APPELLATION>Ampurdàn- costa brava D.O </APPELLATION><REGION_CODE>21</REGION_CODE></une_appellation>
<une_appellation><APPELLATION>Anoia </APPELLATION><REGION_CODE>21</REGION_CODE></une_appellation>
<une_appellation><APPELLATION>Bajo ebro-montsià </APPELLATION><REGION_CODE>21</REGION_CODE></une_appellation>
<une_appellation><APPELLATION>Conca de barberà D.O </APPELLATION><REGION_CODE>21</REGION_CODE></une_appellation>
<une_appellation><APPELLATION>Conca de tremp </APPELLATION><REGION_CODE>21</REGION_CODE></une_appellation>
<une_appellation><APPELLATION>Costers del segre D.O </APPELLATION><REGION_CODE>21</REGION_CODE></une_appellation>
<une_appellation><APPELLATION>Penedés D.O </APPELLATION><REGION_CODE>21</REGION_CODE></une_appellation>
Fonctions de groupe (agrégat)
- XMLAGG, production d'une série d'élements XML par groupe de données
select pays_code, xmlagg(XMLELEMENT(name "region" , region)) from bdvin1.regions group by pays_code ;1 <region>Constantia </region><region>Durbanville </region> ...
2 <region>Ahr </region><region>Baden </region> ...
5 <region>Burgenland Neusiedlersee </region><region>Niederösterreich </region> ...
11 <region>Andalucía </region><region>Aragón </region> ...
12 <region>Alsace </region><region>Bordeaux </region> ...
15 <region>Tokaji </region>
18 <region>Abruzzo </region><region>Basilicata </region> ...
25 <region>Douro </region>
30 <region>Berne </region><region>Fribourg </region> ...
33 <region>Arizona </region><region>Arkansas </region> ...
- <region>Franschhoek </region><region>Hermanus-Walker Bay </region> ...
- XMLGROUP , production d'un flux XML valide, par groupe de données
12 <rowset><row><APPELLATION>Alsace </APPELLATION><REGION>Alsace </REGION></row><row><APPELLATION>Alsace chasselas ... </rowset> 18 <rowset><row><APPELLATION>Montepulciano</APPELLATION><REGION>Abruzo </REGION></row><row><APPELLATION>Brunelo... </rowset> select pays_code, XMLGROUP(appellation, region ORDER BY region OPTION row "appellations" root "regions" ) from bdvin1.regions join bdvin1.appellations using(region_code) group by pays_code; 11 <regions><appellations><APPELLATION>Aljarafe </APPELLATION><REGION>Andalucía</REGION></appellations><appellations><APPELLATION>Bailen ... </regions> 12 <regions><appellations><APPELLATION>Alsace </APPELLATION><REGION>Alsace </REGION></appellations><appellations><APPELLATION>Alsace chasselas ... </regions> 18 <regions><appellations><APPELLATION>Montepulciano</APPELLATION><REGION>Abruzo </REGION></appellations><appellations><APPELLATION>Brunelo... </rregions>
XSD, validation par un schéma XML
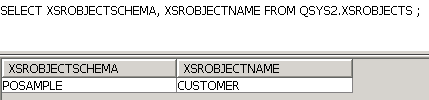
Il faut commencer par enregistrer le schéma dans XSROBJECTS de QSYS2 par la procédure XRS_REGISTER
Enregistrons le schéma XML suivant (nous devons passer par une procédure, XSR_REGISTER attendant un paramètre de type BLOB)
CREATE PROCEDURE SAMPLE_REGISTER LANGUAGE SQL BEGIN DECLARE CONTENT BLOB(1M); VALUES BLOB('<?xml version="1.0"?> <xs:schema targetNamespace="http://posample.org" xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified"> <xs:element name="customerinfo"> <xs:complexType> <xs:sequence> <xs:element name="name" type="xs:string" minOccurs="1" /> <xs:element name="addr" minOccurs="1" maxOccurs="unbounded"> <xs:complexType> <xs:sequence> <xs:element name="street" type="xs:string" minOccurs="1" /> <xs:element name="city" type="xs:string" minOccurs="1" /> <xs:element name="prov-state" type="xs:string" minOccurs="1" /> <xs:element name="pcode-zip" type="xs:string" minOccurs="1" /> </xs:sequence> <xs:attribute name="country" type="xs:string" /> </xs:complexType> </xs:element> <xs:element name="phone" nillable="true" minOccurs="0" maxOccurs="unbounded"> <xs:complexType> <xs:simpleContent> <xs:extension base="xs:string"> <xs:attribute name="type" form="unqualified" type="xs:string" /> </xs:extension> </xs:simpleContent> </xs:complexType> </xs:element> <xs:element name="assistant" minOccurs="0" maxOccurs="unbounded"> <xs:complexType> <xs:sequence> <xs:element name="name" type="xs:string" minOccurs="0" /> <xs:element name="phone" nillable="true" minOccurs="0" maxOccurs="unbounded"> <xs:complexType> <xs:simpleContent > <xs:extension base="xs:string"> <xs:attribute name="type" type="xs:string" /> </xs:extension> </xs:simpleContent> </xs:complexType> </xs:element> </xs:sequence> </xs:complexType> </xs:element> </xs:sequence> <xs:attribute name="Cid" type="xs:integer" /> </xs:complexType> </xs:element> </xs:schema>') INTO CONTENT; CALL SYSPROC.XSR_REGISTER('POSAMPLE', 'CUSTOMER', 'http://posample.org', CONTENT, null); END;Exécutez et validez par :
CALL SYSPROC.XSR_COMPLETE('POSAMPLE', 'CUSTOMER', null, 0);Vérifiez en affichant le contenu de XSROBJECTS
Essayons d'insérer une donnée ne respectant pas les règles.
-> ici nous ne fournissons pas d'élément <addr> alors que ce dernier est déclaré obligatoire (<xs:element name="addr" minOccurs="1")
XMLVALIDATE (XMLPARSE (DOCUMENT '<customerinfo xmlns="http://posample.org" Cid="1003"> <name>Robert Shoemaker</name> <phone type="work">905-555-7258</phone> <phone type="home">416-555-2937</phone> <phone type="cell">905-555-8743</phone> <phone type="cottage">613-555-3278</phone> </customerinfo>' PRESERVE WHITESPACE ) ACCORDING TO XMLSCHEMA ID posample.customer ));
--------------------------------------------------------------------------------------------------
Etat SQL : 2201R
Code fournisseur : -20399
Message : [SQ20399] Echec de l'analyse syntaxique ou de la validation XML. Cause . . . . . : L'analyse syntaxique XML a échoué pendant la validation.
Le décalage en octets dans la valeur XML en cours de traitement après conversion en UTF-8 est de 109.
La description de l'erreur de l'analyseur syntaxique XML est la suivante : cvc-complex-type.2.4.a:
Expecting element with local name "addr" but saw "phone". Que faire . . . : Corrigez l'incident lié au document de l'instance XML.
Relancez XMLVALIDATE ou XDBDECOMPXML.par contre
INSERT INTO posample.Customer(Cid, Info) VALUES (1004, XMLVALIDATE (XMLPARSE (DOCUMENT
'<customerinfo xmlns="http://posample.org" Cid="1003">
<name>Robert Shoemaker</name>
<addr country="Canada">
<street>1596 Baseline</street>
<city>Aurora</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N8X 7F8</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
<phone type="home">416-555-2937</phone>
<phone type="cell">905-555-8743</phone>
<phone type="cottage">613-555-3278</phone>
</customerinfo>' PRESERVE WHITESPACE )
ACCORDING TO XMLSCHEMA ID posample.customer )); --------------------------------------------------------------------------------------------------
1 ligne insérée.
On peut aussi, toujours à l'aide d'un schéma, faire de la décomposition XML-> DB2
C'est à dire "parser" le XML afin de le faire correspondre ("mapper") aux colonnes d'une table
Les éléments du mappage dans le schéma :
- Ajouter l'espace de nommage db2-xdb
xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified"
xmlns:db2-xdb="http://www.ibm.com/xmlns/prod/db2/xdb1" >
- Définir le schéma par défaut dans une annotation
<xs:appinfo>
<db2-xdb:defaultSQLSchema>POSAMPLE</db2-xdb:defaultSQLSchema>
</xs:appinfo>
</xs:annotation>
- Associer à un élément ou un attribut un nom de table et de zone
<xs:element name="name" type="xs:string" minOccurs="1" db2-xdb:rowSet="CUSTOMERD" db2-xdb:column="NOM" /> ou <xs:attribute name="country" type="xs:string" db2-xdb:rowSet="CUSTOMERD" db2-xdb:column="PAYS" />Remarque
tous les éléments n'ont pas à être associés à une colonne (on peut "perdre" des données)
la phase de transformation gère les éléments multiples, par exemple pour un client, un nom, une adresse et DES téléphones
il y aura autant de lignes générées qu'il y a des N° de téléphone, nom et adresse étant répétés (un peu comme une jointure)Ce schéma doit être enregistré, (nous devons toujours passer par une procédure, XSR_REGISTER attendant un paramètre de type BLOB)
CREATE PROCEDURE POSAMPLE.SAMPLE_DECOMP ( ) LANGUAGE SQL BEGIN DECLARE CONTENT BLOB ( 1 M ) ; VALUES BLOB('<?xml version="1.0"?> <xs:schema targetNamespace="http://posample.org" xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified" xmlns:db2-xdb="http://www.ibm.com/xmlns/prod/db2/xdb1" ><xs:annotation> <xs:appinfo> <db2-xdb:defaultSQLSchema>POSAMPLE</db2-xdb:defaultSQLSchema> </xs:appinfo> </xs:annotation> <xs:element name="customerinfo"> <xs:complexType> <xs:sequence> <xs:element name="name" type="xs:string" minOccurs="1" db2-xdb:rowSet="CUSTOMERD" db2-xdb:column="NOM" /> <xs:element name="addr" minOccurs="1" maxOccurs="unbounded"> <xs:complexType> <xs:sequence> <xs:element name="street" type="xs:string" minOccurs="1" db2-xdb:rowSet="CUSTOMERD" db2-xdb:column="RUE" /> <xs:element name="city" type="xs:string" minOccurs="1" db2-xdb:rowSet="CUSTOMERD" db2-xdb:column="VILLE" /> <xs:element name="prov-state" type="xs:string" minOccurs="1" db2-xdb:rowSet="CUSTOMERD" db2-xdb:column="ETAT" /> <xs:element name="pcode-zip" type="xs:string" minOccurs="1" /> </xs:sequence> <xs:attribute name="country" type="xs:string" db2-xdb:rowSet="CUSTOMERD" db2-xdb:column="PAYS" /> </xs:complexType> </xs:element> <xs:element name="phone" nillable="true" minOccurs="0" maxOccurs="1" db2-xdb:rowSet="CUSTOMERD" db2-xdb:column="TEL"> <xs:complexType> <xs:simpleContent> <xs:extension base="xs:string"> <xs:attribute name="type" form="unqualified" type="xs:string" /> </xs:extension> </xs:simpleContent> </xs:complexType> </xs:element> </xs:sequence> <xs:attribute name="Cid" type="xs:integer" /> </xs:complexType> </xs:element> </xs:schema>') INTO CONTENT;CALL SYSPROC . XSR_REGISTER ( 'POSAMPLE' , 'CUSTOMERD' , 'http://posample.org' , CONTENT , NULL ) ; END ;CALL POSAMPLE.SAMPLE_DECOMP;CALL SYSPROC.XSR_COMPLETE('POSAMPLE', 'CUSTOMERD', null, 1);
le dernier paramètre sur XSR_COMPLETE indique si le schéma servira à une décomposition (1) ou non (0)
Vous pouvez voir aussi les schémas par la nouvelle option de System I Navigator (Décomposition représente ce dernier paramètre)
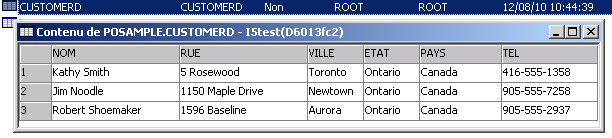
Puis la décomposition se fait à l'aide de la procédure XDBDECOMPXML qui attend un BLOB contenant un flux XML à décomposer.pour décomposer du XML stocké dans une table vous devez écrire une procédure qui balaye la table :
CREATE PROCEDURE POSAMPLE.DECOMP ( ) LANGUAGE SQL SET OPTION DBGVIEW = *SOURCE BEGIN DECLARE CONTENT BLOB ( 2G ) ; DECLARE WEOF INTEGER DEFAULT 0; DECLARE not_found CONDITION FOR '02000'; DECLARE c1 CURSOR FOR SELECT XMLSERIALIZE(info as BLOB(2G) ) FROM POSAMPLE.CUSTOMER;DECLARE CONTINUE HANDLER FOR not_found SET wEOF = 1;OPEN c1; FETCH c1 INTO content; WHILE wEOF = 0 DOCALL XDBDECOMPXML ('POSAMPLE' , 'CUSTOMERD' , content, NULL); FETCH c1 INTO content; END WHILE; CLOSE c1; END ;et voici le résultat
Les différentes annotations de l'espace de nommage db2-xdb :
- db2-xdb:defaultSQLSchema : bibliothèque par défaut
- db2-xdb:rowSet : nom de la table
- db2-xdb:column : nom de la zone
- db2-xdb:locationPath : chemin pour accéder à l'élément (s'il n'est pas racine)
- db2-xdb:expression : permet d'utiliser une expression SQL (pour CASTER, par ex) à la place de la valeur brute, à insérer
- db2-xdb:condition : permet d'utiliser une condition lors du mappage (pour choisir l'expression à utiliser, par exemple)
Autres nouveautés SQL de la version 7.1
|
Nouveautés liées à DB2 en 7.1
- Support des champs de type tableau, dans les procédures SQL uniquement.
CREATE TYPE tva AS dec(4.2) ARRAY[4]
- Nouvelles fonctions d'agrégation produisant des tableaux
SELECT ARRAY_AGG(taux) into :tva from factures (GROUP BY possible)
- nouvelle instruction MERGE
MERGE INTO archive ar USING (SELECT activity, description FROM activities) ac ON (ar.activity = ac.activity) WHEN MATCHED THEN UPDATE SET description = ac.description WHEN NOT MATCHED THEN INSERT (activity, description) VALUES(ac.activity, ac.description)
Exemple :
la table des PAYS contient deux champs pays_code integer, pays char(20)
créons AUTREPAYS
CREATE TABLE BDVIN1/AUTRESPAYS (PAYS_CODE INTEGER , PAYS CHAR (20) )
MERGE into bdvin1/autrespays ap USING( select pays_code, pays from bdvin1/pays) p on (ap.pays_code = p.pays_code) when matched then update set (pays_code, pays, flag) = (p.pays_code, p.pays, 0) when not matched then insert (pays_code, pays, flag) values(p.pays_code, p.pays, 1)
cet ordre SQL insert les enregistrements qui existent dans PAYS et pas dans AUTRESPAYS (sur le code pays) et met à jour ceux qui existent déjà.
mais on peut faire encore plus complexe :
MERGE into bdvin1/autrespays ap USING( select pays_code, pays from bdvin1/pays) p on (ap.pays_code = p.pays_code) when matched AND p.pays_code = 0 then DELETE when matched AND p.pays_code <=9 then UPDATE set (pays_code, pays, flag) = (p.pays_code, p.pays, 2) when matched AND p.pays_code > 9 then UPDATE set (pays_code, pays, flag) = (p.pays_code, p.pays, 3)
when not matched then INSERT (pays_code, pays, flag) values(p.pays_code, p.pays, 1) ELSE IGNORE
le table cible (AUTRESPAYS dans notre exemple) peut être une vue.
on peut derrière THEN signaler une erreur
SIGNAL SQLSTATE '70001' SET MESSAGE_TEXT = 'le pays ne peut pâs être modifié'
l'instruction peut être completée par
ATOMIC
si une opération delete, update ou insert signale une erreur la totalité des opérations est annulée (ROLLBACK)
NOT ATOMIC
on ne revient pas sur les lignes impactées
STOP ON SQL EXCEPTION l'instruction MERGE s'arrête à la première erreur
CONTINUE ON SQL EXCEPTION l'instruction MERGE se poursuit malgrès les erreurs rencontrées.
XMLDOCUMENT production d'un flux XML à partir d'une chaine de caractère XMLPARSE production après vérification, d'un flux XML XMLVALIDATE validation d'un flux XML à l'aide d'un schéma XSD XMLTRANSFORM transforme un flux XML à l'aide de XSLT XMTEXT production d'un texte compatible XML XMLELEMENT production d'un élément XML XMLATTRIBUTES production d'un attribut XML XMLNAMESPACES production d'un balise d'espace de nommage XMLPLI production d'une balise processing instruction XMLCOMMENT production d'un commentaire XML XMLCONCAT production d'un flux XML à partir de deux XMLFOREST production d'une suite d'élements XML à partir des colonnes d'une table XMLROW production d'une ligne XML à partir des colonnes d'une table
fonctions d'agrégation (récapitulatives) XMLAGG production d'une série d'élements XML XMLGROUP production d'un flux XML valide.
Variable globale
on peut maintenant créer des variables globales
elles sont stockées en fait dans des programmes de service (*SRVPGM) accessibles par toute personne ayant les droits sur l'objet. le contenu est propre à la session .
Exemple:
CREATE VARIABLE profil CHAR(10) DEFAULT 'QSECOFR'
la variable PROFIL sera créé pour tous les travaux du système et contiendra QSECOFR.
VALUES profil , permet de l'afficher.
VALUES 'CM' INTO PROFIL, change son contenu mais uniquement pour mon job.
la variable est initialisée en début de job, et seul le job peut la modifier.On dit que la "portée" est limité à la session.
On peut saisir des expressions en tant que paramètres
CALL PROC01 (SUBSTR(VARIABLE, 1, 10))
CALL PROC02 (autrevariable/2)
On peut récupérer le résultat (result sets) retourné par une procédure
avec le scénario suivant(si le procédure ne retourne qu'un seul result set)
CALL PROC03
si SQLCODE = +446 // il y a un jeu de résultat retourné
ASSOCIATE LOCATORS (:RS1) WITH PROCEDURE PROC03
// :RS1 doit être déclaré SQLTYPE(RESULT_SET_LOCATOR)
ALLOCATE C1 CURSOR FOR RESULT SET :RS1
Exemple :
D nom_du_jour s 10 D date_du_jour s 10 D RS1 S SQLTYPE(RESULT_SET_LOCATOR) /free exec sql CALL FREE03; if SQLCODE = +466; exec sql ASSOCIATE LOCATORS (:RS1) WITH PROCEDURE FREE03; exec sql ALLOCATE C1 CURSOR FOR RESULT SET :RS1; exec sql fetch c1 into :nom_du_jour , :date_du_jour; dow sqlcode = 0; // traitement des variables lues... exec sql fetch c1 into :nom_du_jour , :date_du_jour; ENDDO; exec sql close C1; ENDIF;
*inlr = *on; /end-free
La version 6 avait apporté à l'ordre SELECT l'option SKIP LOCKED DATA
cela permettait lors d'une lecture avec verrouillage d'enregistrement, c.a.d COMMIT à CS(*CS) ou RS(*ALL), d'ignorer les lignes verrouillées
Cette option a été étendue aux instructions UPDATE et DELETE
vous avez, en plus, le choix entre trois comportements :
WAIT FOR OUTCOME Attendre que les lignes soient libérées (COMMIT par exemple) cela n'a pas d'effet sur les niveaux de COMMIT inférieurs à CS
USE CURRENTLY COMMITTED Utiliser les valeurs déjà validées cela ne peut s'appliquer qu'aux COMMIT niveau CS (sans KEEP LOCKS)
SKIP LOCKED DATA les lignes verrouillées sont ignorées. Comme cette clause est maintenant valide avec UPDATE/DELETE, elle peut être utilisée avec tous les niveaux de COMMIT, sauf RR (repeatable read)
Vous pouvez en plus préciser cette option :
1/ en fin des ordres, SELECT, UPDATE, DELETE, PREPARE
2/ sur le nouveau paramètre CONACC des commandes de compilation (CRTSQLRPGI par ex.) et RUNSQLSTM (pas STRSQL)
3/ sur l'ordre CREATE PROCEDURE|CREATE FUNCTION (ou ALTER)
4/ avec SET OPTION CONACC=*CURCMT | *WAIT | *DFT dans la procédure SQL
5/ dans QAQQINI avec l'option SQL_CONCURRENT_ACCESS_RESOLUTION
les ordres CREATE ALIAS, CREATE FUNCTION, CREATE PROCEDURE, CREATE VIEW CREATE SEQUENCE, CREATE VIEW
possédent une clause CREATE OR REPLACE
pas les ordres CREATE TABLE, CREATE INDEX (dommage !)
Nouvelles fonctions
BITAND, BITANDNOT, BITOR, BITXOR et BITNOT
(identiques aux fonctions de même nom en RPG)
les indexs EVI peuvent maintenant contenir le résultat d'une fonction agrégée (ou de groupe), comme AVG, COUNT, SUM, MIN, MAX...
CREATE ENCODED VECTOR INDEX vinevi01 ON VINS (PR_CODE) INCLUDE (COUNT(*))
un index evi réalisant des stats par producteur (premier, dernier, etc.) il contiendra en plus directement le nombre de vins par producteurs
la procédure CANCEL_SQL de QSYS2 permet d'annuler une requête
CALL QSYS2.CANCEL_SQL('123456/QUSER/QZDASOINIT');
la PTF SI363919 implémente aussi cette procédure en V6R10

- FREE03 (SQLRPGLE) TP ILE retournant un RESULT SET
- FREE04 (SQLRPGLE) TP appelant FREE03 et récupérant le résultat
FIELDPROC
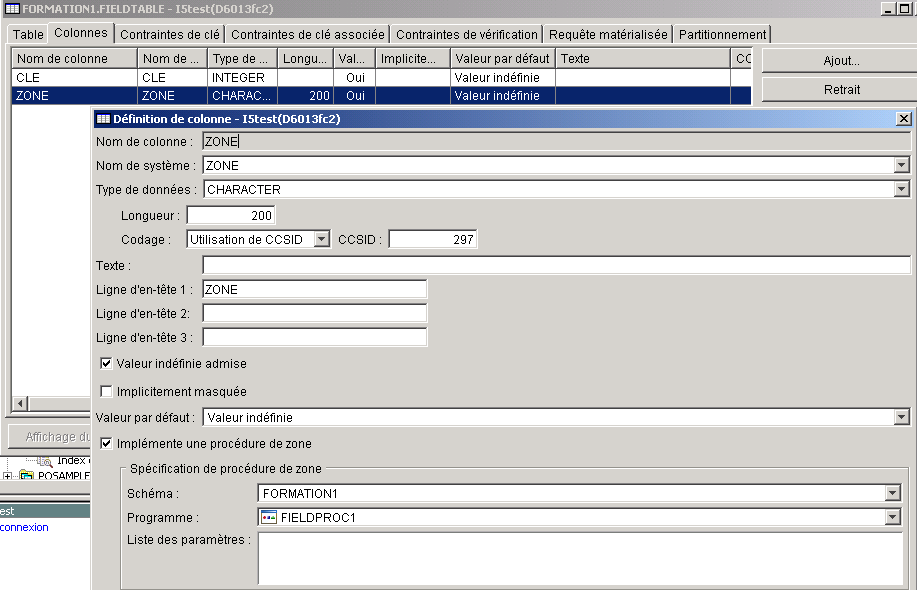
La version 7 propose aussi une nouvelle fonctionnalité permettant de crypter le contenu d'une colonne par le nouveau mot-clé FIELDPROC ajouté aux ordres SQL CREATE TABLE et ALTER TABLE
(cle integer ,
zone char(200) FIELDPROC fieldproc1)sous System i navigator :
La zone cryptée ne peut pas être :
- une zone de type ROWID
- une zone numérique avec l'attribut AS IDENTITY
- une zone de type TIMESTAMP avec AS ROW CHANGE TIMESTAMP
- un DATALINK
- une zone avec comme valeur par défaut CURRENT DATE/TIME/TIMESTAMP, USER



Programmation :
- la procédure doit être de type PGM/ILE (pas de GAPIII, de java, de programme de service)
- l'algorithme doit être réversible
(si la chaîne 'ABCDEF' est transformée en '123456', '123456' doit produire 'ABCDEF') - on peut définir des paramètres à envoyer à la procédure, ils sont transmis à chaque appel
- la procédure est appelée lors de la création, pour :
- valider le type de zone (elle peut refuser de travailler avec des zones numériques, par ex.)
- indiquer le type de zone à stocker :
- l'utilisateur saisi du caractère, on stocke du binaire
- lors de la lecture le binaire est transformé à nouveau en caractère
- la procédure est appelée ensuite lors des affectations afin de crypter la donnée, lors des lectures afin de la décrypter
(Ordres SQL ou Entrées/sorties natives) - Elle peut décrypter la donnée suivant des conditions, et c'est là que c'est intéressant.(l'utilisateur appartient à la DRH ou pas, par ex.)
- Paramètres :
- une zone fonction indiquant le contexte
8 = appel lors de la création
0 = appel pour crypter
4 = appel pour décrypter - une structure décrivant les paramètres
- une structure décrivant la valeur en clair
- valeur à utiliser pour le cryptage si fonction=0
- valeur à produire si fonction=4
- la valeur en clair
- une structure décrivant la valeur cryptée
- valeur à produire si fonction=0
- valeur à utiliser si fonction=4
- la valeur cryptée
- SQLCODE (doit commencer par 38, si erreur, 00000 dans le cas contraire)
- message complémentaire si SQLCODE <> '00000'
Exemple avec un pgm qui inverse les bits (fonction RPG %BITNOT) sur une zone CHAR
et ne décrypte que si c'est QSECOFR qui lit.
/free |
puis
Insert into fieldtable values |
SELECT * FROM FIELDTABLE, sous QSECOFR

Sous un autre profil 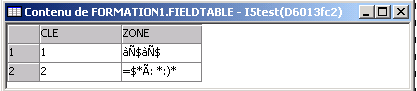 (ici, avec System i navigator)
(ici, avec System i navigator)
Quelques remarques
- La documentation vous déconseille de crypter le caractère espace
en effet quand vous comparez à la zone, une constante plus courte, le système complète l'information la plus petite par des espaces.
si les espaces de la zone sont cryptés, du coup la donnée sera considérée comme différente de la constante alors qu'en réalité ce n'est pas le cas.
- les tris peuvent être perturbés sur une zone cryptée :
ex SELECT *FROM FIELDTABEL ORDER BY ZONE
-> sous QSECOFR 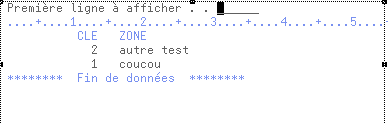 (la zone est décryptée)
(la zone est décryptée)
-> sous un autre profil  (la zone reste cryptée)
(la zone reste cryptée)
- lors d'un CPYF la procédure sera appelée (même sur DSPPFM), ainsi que lors d'un CREATE TABLE AS (SELECT ...)
- une option de QAQQINI destinée à l'optimiseur, indique si la zone doit être décryptée systématiquement :
FIELDPROC_ENCODED_COMPARISON :
- *ALLOW_EQUAL (dft)
on crypte les constantes comparées plutôt que de décrypter la valeur du fichier, pour les comparaisons, GROUP BY et DISTINCT.
la fonction doit être déterministe (retourner toujours le même résultat pour la même valeur) et les valeur retournées peuvent ne pas être triées
- ALLOW_RANGE
on crypte les constantes comparées plutôt que de décrypter la valeur du fichier, comme ALLOW_EQUAL, mais aussi pour MIN, MAX et ORDER BY
la fonction doit être déterministe et les valeur retournées doivent être triées (significatives pour un tri)
- *ALL
la procédure est appelée le moins souvent possible (on crypte les constantes comme ALLOW_RANGE) pour toutes les opérations y compris LIKE
- *NONE
la procédure de cryptage est appelée systématiquement et on travaille avec les valeurs en clair.
CQE travaille toujours de cette manière, quelque soit la valeur dans QAQQINI.
-
Rational Open Access , RPG Edition
Rational Open Access, RPG edition (5733OAR) est un produit apparu
en 7.1 et disponible aussi pour la V6R1(avec PTF).
Il permet de passer la main à un "driver" externe lors des ordres d'entrée sortie RPG, plutôt que d'appeler les routines historiques d'IBM.
Par exemple:
-
Vous avez actuellement un programme RPG écrivant dans un fichier physique.
-
Vous écrivez ou achetez un Handler qui reçoit les données et qui les écrit au format CSV ou XML dans l'IFS à la place de l'écriture dans le fichier physique.
-
Vous ajoutez le mot-clé HANDLER sur la déclaration du fichier en sortie de votre programme initial et le tour est joué, ce dernier écrit dans l'IFS.
- Ajout au pgm applicatif de HANDLER('le-nom' : info)
- le nom peut être noté
- ma_variable : un nom de variable
- 'PGM' : le nom du programme
- 'BIB/PGM' : le nom qualifié du programme
- 'SRVPGM(nom)' le nom d'une procédure dans un pgm de service
- 'BIB/SRVPGM(nom)' le nom d'une procédure dans un pgm de service qualifié
- info, paramètre facultatif permettant de passer des informations au Handler
(coordonnées dans l'IFS par exemple)
le fichier auquel vous avez ajouté HANLDER doit être présent à la
compilation ET à l'exécution (malgré que vous ne vous
en serviez pas vraiment, il fournit le format)
le produit 5733OAR (facturable) doit être présent à la
compilation ET à l'exécution.
- Ecriture du Handler
- le Handler est appelé à chaque opération (open, close,
read, etc...) et reçoit une DS d'information structurée (QrnOpenAccess_T,
voir QRNOPENACC )
décrivant l'Entrée/sortie et permettant aussi un retour d'informations
auprès
des couches système.
// Exemple // Standard IBM supplied Open Access definitions /copy QOAR/QRPGLESRC,QRNOPENACC // paramètre recu par le pgm // de type QrnOpenAccess_T D CVS_HDLR PI D info likeds(QrnOpenAccess_T)
zones de QrnOpenAccess_T remarquables :
- structLen : lg totale de cette structure
- parameterFormat : toujours 'ROAC0100'
- userArea : pointeur vers l'espace mémoire fourni en 2ème paramètre du mot-clé Handler par le pgm (libre)
- stateInfo : pointeur vers un espace mémoire permettant au Handler de mémoriser quelque chose entre deux appels (libre)
- RecordName : nom du format
- rpgOperation : Opération en cours, voir les constantes QrnOperation_xxx dans QRNOPENACC
- rpgStatus : s'il est appelé pour une opération qu'il ne sait pas gérer, il doit signaler une erreur (QrnOpenAccess_T.rpgStatus <> 0).
- Eof : à mettre à *ON pour signaler une fin de fichier
- Found : à mettre à *ON pour signaler une opération d'accès directe réussie
- Equal : à mettre à *ON pour signaler une opération de positionnement par égalité réussie
- inputBuffer (pointeur vers un buffer mémoire si useNamesValues=*OFF)
- NamesValue (pointeur vers un espace mémoire structuré de type QrnNamesValues_T, si useNamesValues=*ON)
lors de l'OPEN le Handler doit signaler comment il veut recevoir les données (QrnOpenAccess_T.useNamesValues)
- *OFF ('0') les données sont fournies dans un buffer identique à celui reçu par les routines systèmes (suite d'octets)
- *ON ('1') les données sont fournies dans une structure contenant la description de la zone et les données en clair (en caractère, même pour le numérique)
QrnNamesvalues_T (si useNamesvalues est à *ON) :
- nombre de zones (binaire sur 4 octets)
- tableau de n occurrences (suivant zone précédente) de type QrnNameValue_T
//Exemple // déclaration de la structure basée sur Qrnnamesvalues_T //D QrnNamesValues_T... //D DS QUALIFIED TEMPLATE ALIGN //D num 10I 0 //D field LIKEDS(QrnNameValue_T) //D DIM(32767)
D nvInput ds likeds(QrnNamesValues_T) D based(pNvInput) /free // utilisation du pointeur lu dans info (QrnOpenAccess_T) if info.rpgOperation = QrnOperation_WRITE; pNvInput = info.namesValues; // contenant elle même QrnNameValue_T autant de fois // qu'il y a de zones, qq infos et des pointeurs //D QrnNameValue_T... //D DS QUALIFIED TEMPLATE //D externalName... //D 10A //D dataType... //D 3U 0 //D numericDefinedLen... //D 3U 0 //D decimals... //D 3U 0 //D dtzFormat... //D 3U 0 //D dtSeparator... //D 1A //D input... //D N //D output... //D N //D isNullCapable... //D N //D hasNullValue... //D N //D reserved1... //D 13A //D valueLenBytes... //D 10U 0 //D valueMaxLenBytes... //D 10U 0 //D valueCcsid... //D 10I 0 //D reserved2... //D 10U 0 //D value... //D * //D reserved3... //D *
QrnNamevalue_T (description d'une zone) , les lg sont données en nombre d'octets :
- Nom, CHAR(10)
- Type de données, Integer(1), voir les constante dans QRNOPENACC
- Longueur définie (numérique uniquement) , Integer(1)
- Décimales, Integer(1)
- Format (date/heure), Integer(1)
- Séparateur (date/heure), CHAR(1)
- Input ? (*ON/*OFF), CHAR(1)
- Output ? (*ON/*OFF), CHAR(1)
- NULL possible ? (*ON/*OFF), CHAR(1)
- Contient NULL ? (*ON/*OFF), CHAR(1)
- Lg de la valeur (peut être renseignée par RPG), Integer(4)
- Lg maxi de la valeur (fixée par le système), Integer(4)
- CCSID de la valeur, Integer(4)
- Valeur, pointeur vers cette dernière, qui elle est en clair (résultat
de %CHAR si numérique, de %DATE si c'est une date, etc ...).
//Exemple, suite // boucle autours du nbr de variables // pour récupérer les valeurs et les traiter D pvaleur s * D valeur s 32470a Based(pvaleur)
/free For i = 1 to nvInput.num;
pvaleur = nvInput.field(i).value; // accès aux données If ( nvInput.field(i).dataType = QrnDatatype_Alpha ); ... manipulation de "valeur" ... EndIf; EndFor;
Ces exemples sont d'abord inspirés de celui fourni par Partner400 , puis de la documentation
- TEST1 Pgm initial d'écriture dans un fichier Physique
- TEST2 Pgm initial
modifié pour utiliser le Handler qui suit (CSV_HDLR)
- CSV_HDLR Handler
pour générer un fichier CSV dans l'IFS
- TEST3 Pgm initial modifié pour utiliser le Handler qui suit (XML_HDLR)
- XML_HDLR Handler
pour générer un fichier XML dans l'IFS
- TEST4 Pgm initial de lecture d'un fichier Physique avec impression
- TEST5 TEST4 modifié pour utiliser le Handler CSV_HDLRI en lecture
- CSV_HDLRI Handler pour lire le contenu d'un fichier CSV dans l'IFS
Copyright © 1995,2010 VOLUBIS