pause-café
destinée aux informaticiens sur plateforme IBM i.
Pause-café #61
Modernisation de la base de données, SQL vs DDS.
Les différentes facettes de la modernisation du système d'informations
Moderniser le matériel et le logiciel (Power 7)
Moderniser la base de données (ce que nous allons voir)
Moderniser les environnements de développement (RDP)
Moderniser le code existant (RPG4 en libre, Java/PHP)
Moderniser l'accès au code (Travail en équipe, Gestion de version)
Moderniser l'interface utilisateur (IHM)
Moderniser les compétences ;-)
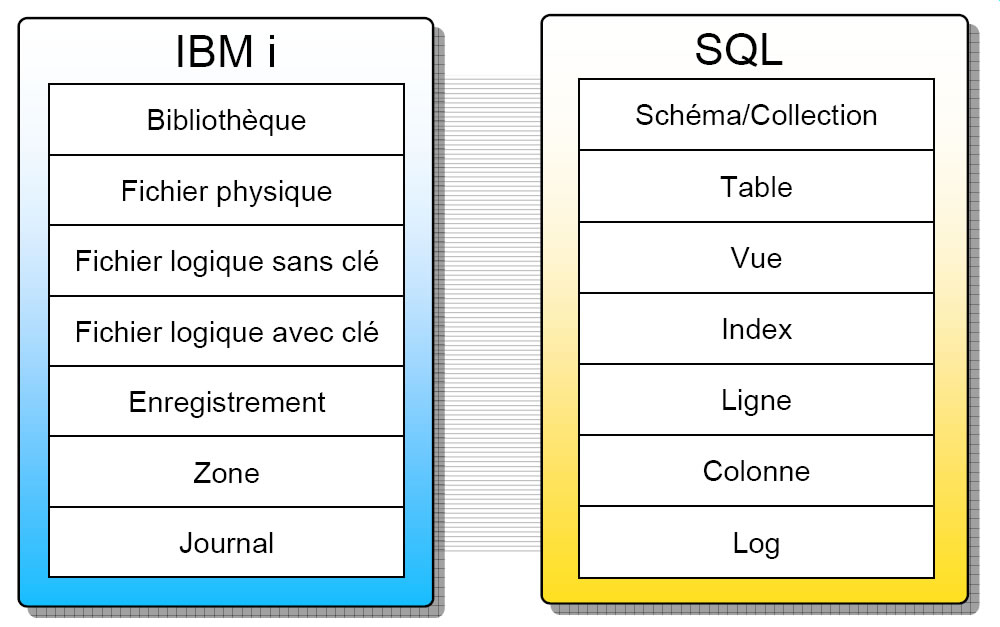
Le langage SQL est composé de sous ensembles
DDL
Data Definition Language (DDL) , instructions de création et de maintenance de la structure base de données
- CREATE - création d'objets
- ALTER - modification de structure
- DROP - suppression d'objets
- LABEL / COMMENT - documentation
- RENAME - renommage d'objet
DML
Data Manipulation Language (DML) instructions de manipulation de données:
- SELECT - lecture de données
- INSERT - insertion de données
- UPDATE - mise à jour de données
- DELETE - suppression de données
- MERGE - (insert or update)
- CALL - Appel d'une procédure cataloguée
DCL
Data Control Language (DCL) instructions de gestion des droits:
- GRANT - accord de droits
- REVOKE - retrait de droits
Autant l'utilisation de DML se démocratise chez les clients IBM i , autant DDL reste minoritaire...
Pourtant IBM préconise l'utilisation de SQL (DDL) pour concevoir la base de données.
- Les dernières modifications importantes de SDD datent de la V2R11 (1992 de mémoire...), sont mineures ensuite.
- variables dates/heures , valeur nulle (V2)
- support UNICODE (V5)
- PAGESIZE sur CRTLF (V5)
- Support disques SSD (V6)
- paramètre KEEPINMEM (V7)
- Toutes les autres avancées sont liées à SQL
- Nouveaux types
- Dates/Heures et valeur nulle sont intégrés au SQL de base
- BLOB /CLOB (champs images, PDF)
- OmniFind sait indexer de tels champs
- DATALINK
- champs de type URL avec possibilité de contrôle de l'existence du fichier dans l'IFS.
- NCHAR
- DECFLOAT
- ROWID
- zones auto-incrémentées (AS IDENTITY)
- SEQUENCES
- attribut HIDDEN
- cette colonne est cachée par défaut (SELECT * FROM ... ne la montre pas)
- attribut AS ROW CHANGE TIMESTAMP
- ce TIMESTAMP contient automatiquement date/heure de dernière modification.
- XML
- Intégrité référentielle directement définie avec la table (syntaxe SQL)
- Index EVI pour le BI
- FIELDPROC pour crypter les données
- TRIGGER à la colonne
Attention à la terminologie
Quels sont les avantages de SQL pour la création de tables
- plus de types de données disponibles, nous venons de le voir
- les contraintes sont définies dans le même source, le même langage
- noms plus longs
- 30 c. pour les noms de zone
- 128c pour les noms de table
- lectures plus rapides
En effet, pour des raisons historiques (fichiers décrits en internes) les fichiers créés par SDD ne controlent pas la données insérée.
(il est ainsi possible de stocker "ABC" dans une zone numérique, si vous utilisez des spécifs O en RPG).
En contrepartie, lors de l'utilisation de ces fichiers sur un mode externe ou par SQL la donnée est controlée lors de la lecture,
d'où une perte de temps (nous réalisons en général plus d electures que d'écritures sur nos bases)
- Historiquement, journalisation automatique. Désormais nous pouvons utiliser STRJRNLIB
- Possibilité d'utiliser des outils de modélisation (IBM Infosphere Data Architect, Mega Database Builder ou XCASE vu plus loin, par exemple)
Quels sont les inconvénients de SQL pour la création de tables
- Ecritures plus lentes (contrôle de la donnée)
- pas de DDM (possibilité d'utiliser DRDA)
- gestion plus complexe des Multi-membres (ALIAS)
Quels sont les avantages de SQL pour la création d'index (vs LF)
- Choix du type (b-arbre ou EVI)
- Pages de 64 K
- Ces index à larges pages sont plus efficaces lors de manipulation de volumes
- les indexs créés par SDD ont des pages de 8k plus efficaces pour recherche une donnée unitaire (CHAIN en RPG)
- Depuis la V6, les index peuvent avoir
- une clé composée
- une sélection
where raisoc <> ' ' and nocli > 1 ;- un format particulier
RCDFMT clientf8 add raisoc ; -- en plus de la clé
Quels sont les avantages de SQL pour la création de vue (vs LF)
- Beaucoup plus de puissance
- une vue peut avoir une jointure interne et les autres externes gauche
- une vue peut retourner des données agrégées (GROUP BY, GROUP BY ROLLUP)
- une vue peut avoir une sélection utilisant toute la puissance du WHERE SQL (CASE par exemple)
- une vue peut utiliser une fonction "maison" c.a.d une UDF
(select nocli, raisoc, dispo(nocli)
from clients) ;- une vue peut utiliser une UDTF (fonction retournant une table à partir de données non BdeD)
(select * FROM TABLE (litrepertoire('/PDF') as PDF);
- Attention, les vues ne sont pas indexées
- C'est un problème pour remplacer un LF par une vue sur une spécif F RPG
(mais revoyez les nouvelles possibilités des index SQL)- Ce n'est pas un problème lors d'un accès SQL, c'est le moteur qui trouve tout seul le meilleur chemin
Nous savions déjà que SQL sait utiliser des objets créés par SDD, mais les programmes natifs peuvent aussi utiliser des objets SQL
- Bien sûr SQL sait utiliser des fichiers physiques créés par SDD
- Un INDEX SQL fait une bonne spécif F en RPG.
- Une vue SQL peut-être utiliser en progammation RPG (accès séquentiel uniquement)
- on peut :
- créer des index ou des vues SQL sur des physiques SDD
- créer des logiques SDD sur des tables SQL, ce que nous allons voir
Tout cela en attendant d'être FULL SQL ;-)
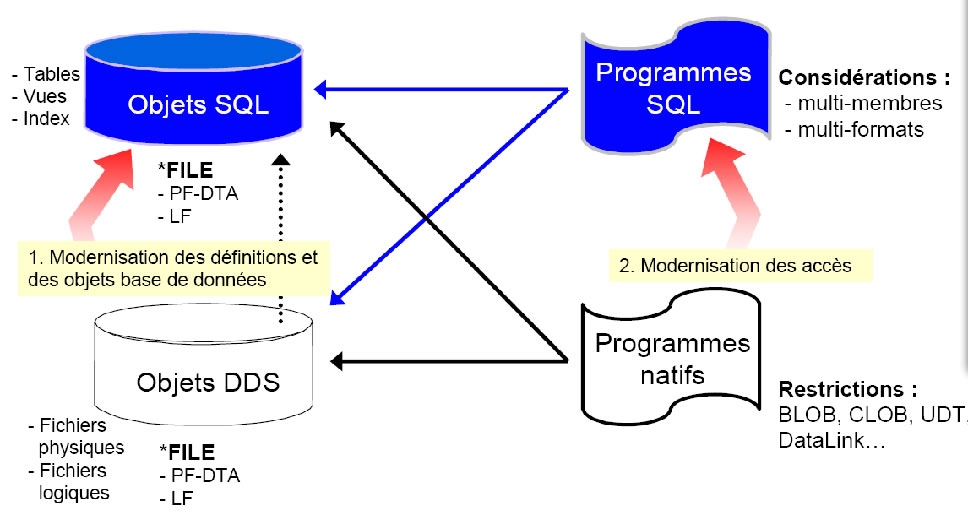
Voici la vision d'IBM concernant la phase de transition de modernisation de la base de données
Modernisation, phase 1
la phase 2 consiste à faire des modules d'accès à la base (*SRVPGM par exemple)la phase 3 à reporter sur la base de données un maximum de logique métier
- Intégrité référentielle
- contraintes
- Cryptage de données
- Auto-Incrémentation
enfin, la phase 4 propose d'externaliser l'accès aux données
- User Defined Fonction (UDF et UDTF)
- Procédures cataloguées
- etc....
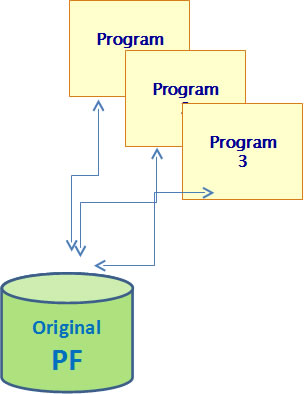
Revenons à l'étape 1, le principe est le suivant :
- Conversion des fichiers physiques en tables SQL
- Création d'un logique SDD ayant le même format que l'ancien physique
- Recréation des différents logiques
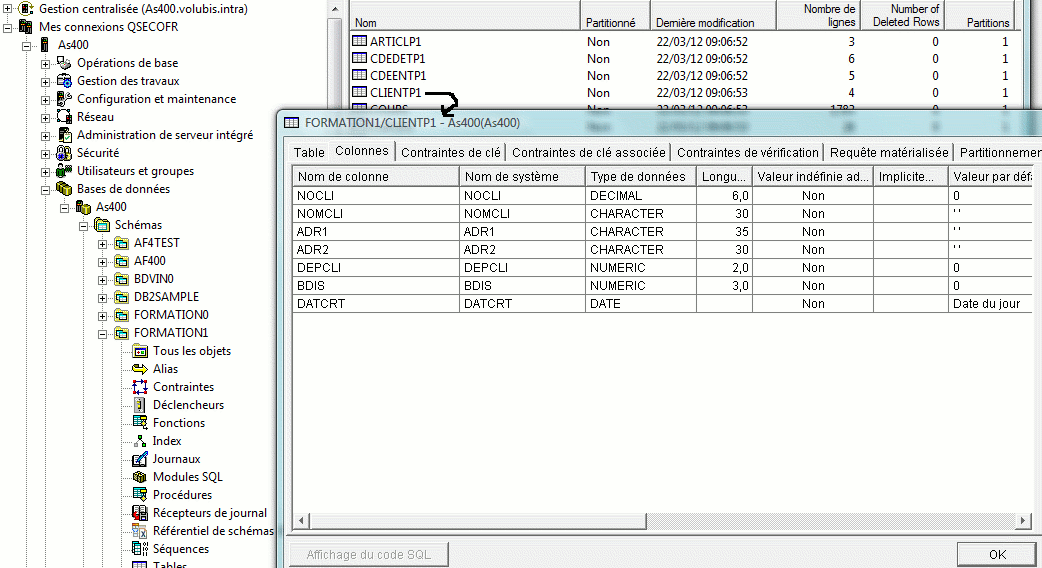
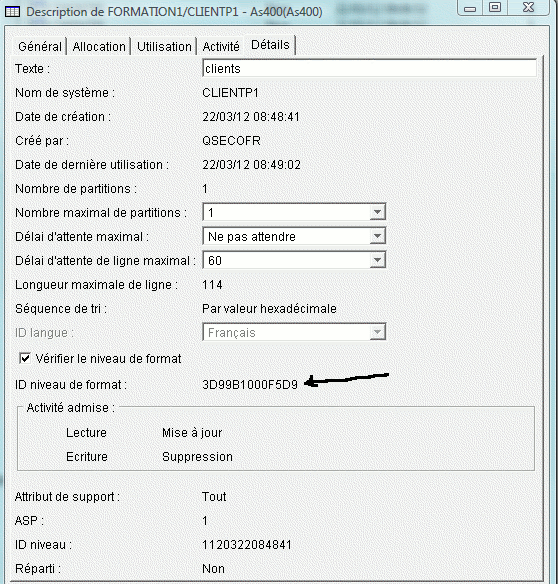
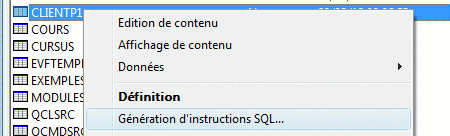
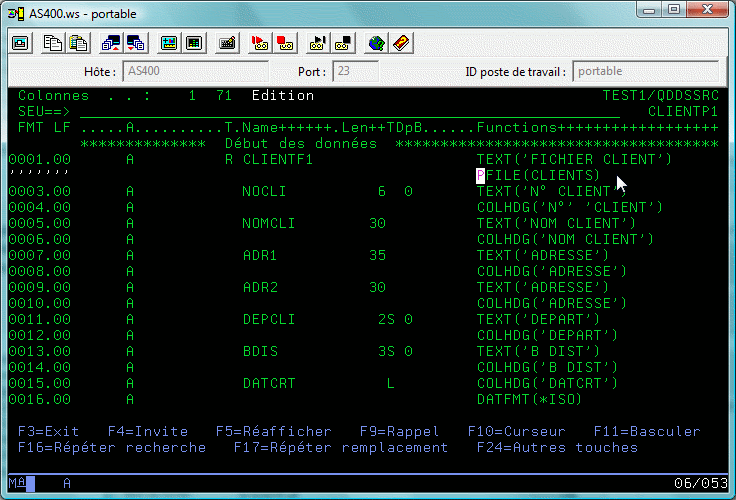
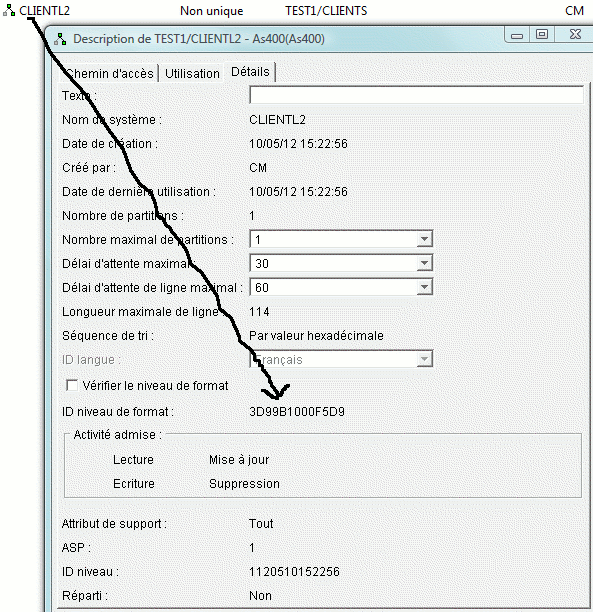
Partons donc d'un fichier physique existant (bibliothèque FORMATION1) que nous souhaitons "moderniser" dans le Schéma TEST1
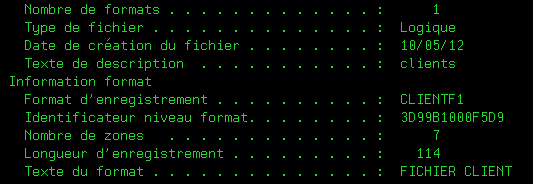
dont voici l'identifiant de format (3D99B1000F5D9)
La fonction génération d'instructions SQL permet de retrouver le source SQL
y compris des fichiers créés par SDD
Les fonctions non supportées sont notées en commentaire
- SQL1509 nom de format ignoré (inutile depuis que SQL admet la clause RCDFMT)
- SQL150B attribut de la table ignoré, REUSEDLT(*NO) par exemple
- SQL150D attribut de la colonne ignoré, EDTCDE par exemple
Que nous transformons en :
Nous aurions aussi pu ajouter une zone AS ROW CHANGE TIMESTAMP, par exemple.
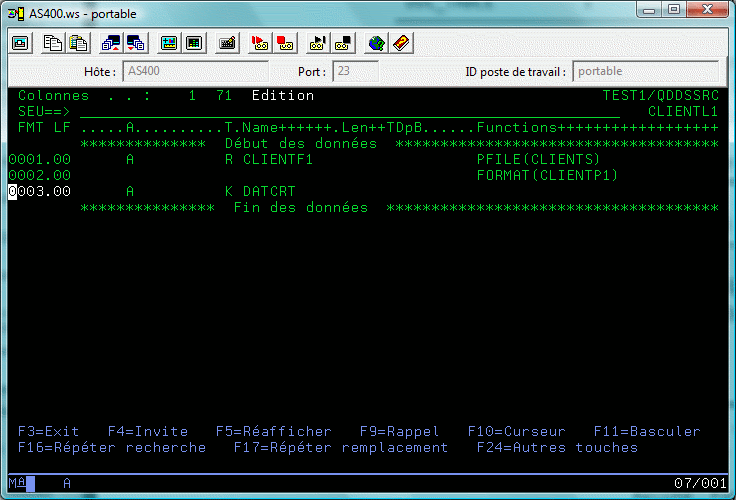
Créons ensuite le logique portant le même nom que l'ancien physique SDD
Vérifions
les autres fichiers logiques doivent juste utiliser le format du précédent
Mais depuis la V6, nous aurions pu aussi en faire de vrais index SQL
ayant toujours le même format :
Attention, aux cas ou le fichier physique (qui est maintenant un logique) est utilisé dans certaines commandes comme CLRPFM !!!!
Pour illustrer cela, nous allons regarder un Produit XCASE, dont la méthodologie nous a semblé intéressante .
L'offre Xcase
- Relate-DB
- Découverte automatique des Relations avant validation
Implementation modulable selon le contexte et les souhaits
- Modernize-DB
- Passage de DDS a SQL
- Evolve-DB
- Modélisation et maintenance de bases de données SQL
Création et maintenance de Vues SQL à partir de tableaux SQL ou DDS- Viewer-DB
- Documentation et visualisation de bases de données SQL ou DDS
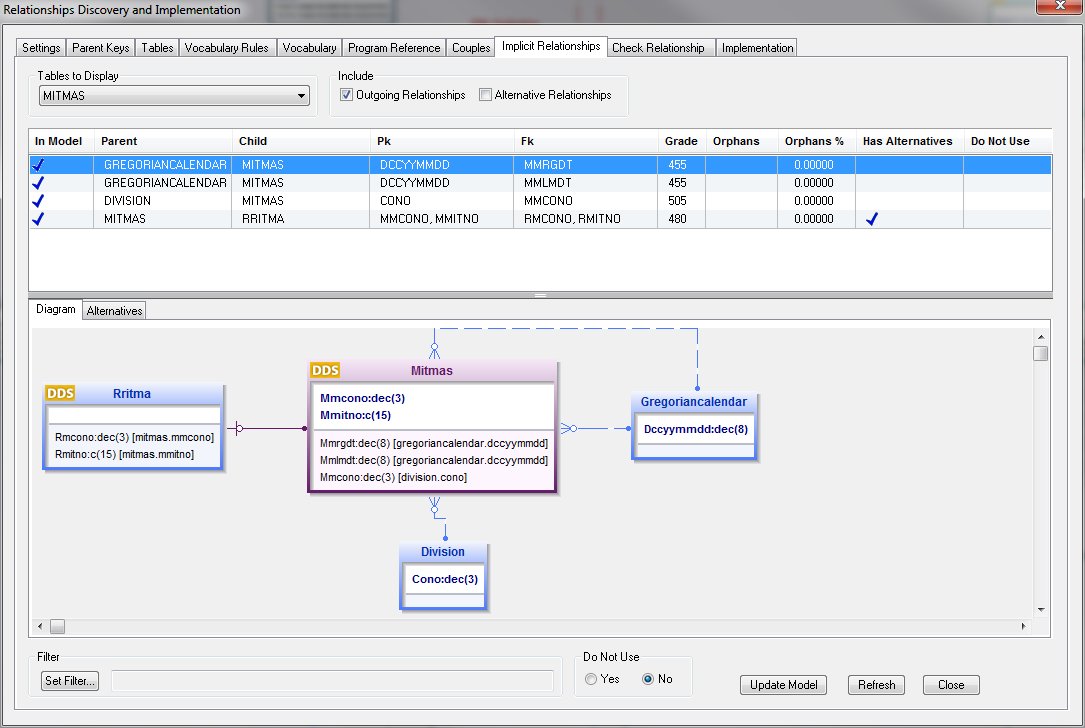
Relate-DB, Le processus de découverte
L'algorithme
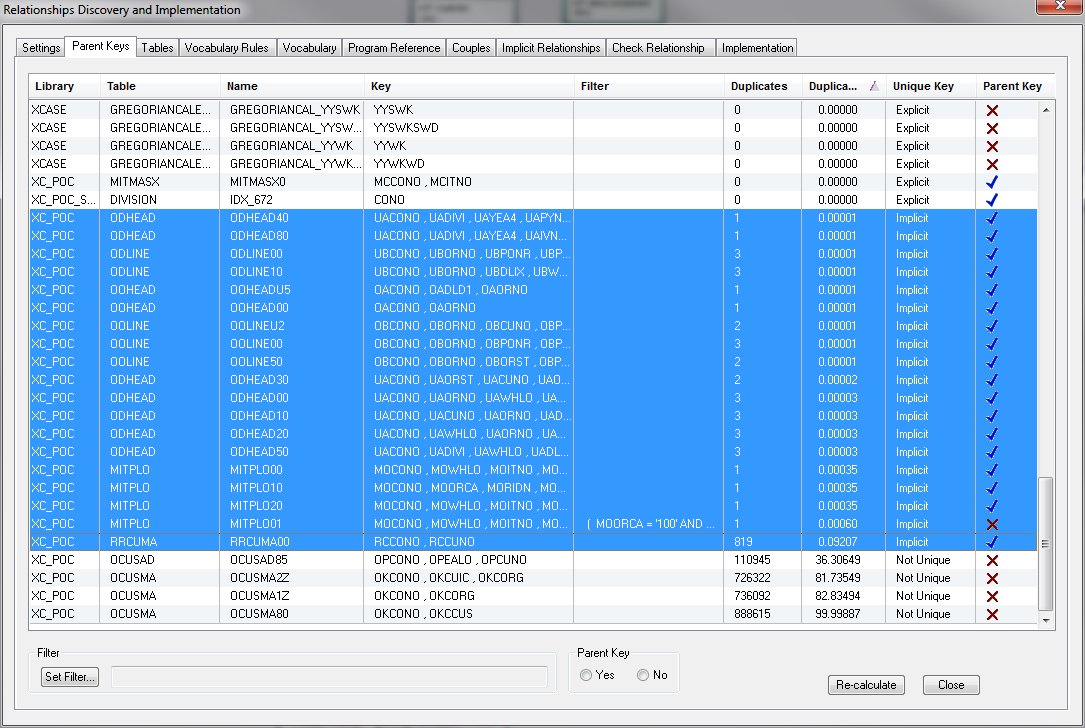
- Trouver les clés des parents (Parent Key)
Cette phase cherche les clés uniques (déclarées ou bien rencontrées réellement sur l'ensemble des valeurs)
- Trouver les tables enfants associées
Cette partie cherche les relations (jointures, fichiers souvent utilisés ensembles dans les programmes, etc...)
- Trouver les Candidats FK (Foreign Key)
Plusieurs méthodes sont utilisés
- recherches des zones compatibles (même type, même longueur)
- recherche sur le nom de zone (même partiel), sur le titre, etc ..
- Vérifier les données physiques
Phase de vérification
- Il y a-t-il des doublons ?
- il y a-t-il des orphelins, si oui est-ce un pourcentage acceptable (paramétrable)
- Sélectionner le meilleur candidat
Choix final de la relation par l'utilisateur
Une fois les relations définies
Vous avez une documentation à jour
- Principe: Modifier un modèle, et générer automatiquement du DDL par synchronisation de la base avec le model.
Donc, ne nécessitant pas la connaissance de SQL
- Permettant
Une génération et une maintenance automatique des jointures dans des vues SQL (par sélection graphique d'un chemin constituée de relations découvertes)
- Ces vues peuvent être utilisées directement par les développeurs dits "nouvelles technos" (java, php, .net)
- Ces vues peuvent se transformer, de manière simple, en Synonymes pour Web Query
Xcase vous propose ensuite, 5 options d'implémentation :
- None
- Declarative Referential Integrity
- Disabled
- Check
- Surrogate
None
- Prérequis
Aucun
- Avantages
La base de données ou les applications n'ont pas besoin d'être modifiées
Les relations peuvent être consultées à des fins de documentation dans un modèle XCase
Les relations peuvent être utilisées dans un modèle XCase pour créer des vues
Les relations peuvent être utilisées dans un modèle relationnel XCase pour parcourir les données physiques
- Inconvénients
Les relations ne sont pas exposées à la base de données
L'intégrité référentielle n'est pas appliquée par la base de données
- Mise en œuvre technique
Aucune
Déclarative R.I
- Prérequis
La clé primaire ne peut pas être une zone de sélection/omission (par un LF) à cause du partage implicite de chemin d'accès
Des enregistrements orphelins ne peuvent pas exister chez l'enfant lors de la création de la contrainte
- Mise en œuvre technique
Créer une contrainte Unique sur la table parent (clé alternative – PK surrogate, voir ci-dessous)
Créer une contrainte de Foreign Key sur la table enfant
Créer des déclencheurs pour mettre en œuvre les actions qui, dans certains cas, ne sont pas supportées par la base de données (AS ROW CHANGE TIMESTAMP, par ex.)
- Avantages
Les relations sont exposées à la base de données
L'intégrité référentielle est appliquée par le moteur de la base de données
Le moteur de recherche de base de données utilise les contraintes pour optimiser les performances
Les relations peuvent être utilisées dans Xcase (documentation, création de vues, parcours des données)
- Inconvénients
Les applications violant l'Intégrité Référentielle doivent être modifiées !
R.I Disabled
- Prérequis
La clé primaire ne peut pas être une zone de sélection/omission (par un LF) à cause du partage implicite de chemin d'accès
- Mise en œuvre technique
Créer une contrainte Unique sur la table parent (clé alternative)
Créer une contrainte de Foreign Key sur la table enfant en utilisant la commande ADDPFCST
Désactiver les contraintes
- Avantages
Les relations sont exposées à la base de données
Les relations peuvent être utilisées dans Xcase (documentation, création de vuex, parcours des données)
- Inconvénients
L'intégrité référentielle n'est pas appliquée par le moteur de base de données
Le moteur de recherche de base de données n'utilise pas les contraintes désactivées pour optimiser les performances
Check
- Prérequis
Les relations peuvent être déclarées dans la base de données
- Mise en œuvre technique
Créer un contrainte d'unicité sur la table parent (clé alternative)
Créer une contrainte de Foreign Key sur la table enfant en utilisant la commande ADDPFCST
Désactiver les contraintes
Créer des déclencheurs (trigger) pour tracer des violations dans une Message Queue
- Avantages
Les relations peuvent être utilisées dans Xcase (documentation, création de vuex, parcours des données)
- Inconvénients
L'intégrité référentielle n'est pas appliquée par le moteur de base de données
Le moteur de recherche de base de données n'utilise pas les contraintes désactivées pour optimiser les performances
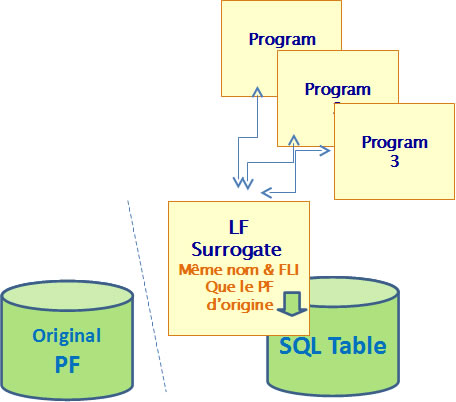
Surrogate
- Prérequis
La table Parent possède une clé primaire basée sur le champ d'identité ou la date (champ ajouté par Xcase)
La table des enfants est définie par DDL (SQL)
Les tables parent et enfant doivent être maintenues, dans certains cas, dans le même journal
- Mise en œuvre technique
Création d'un champ Foreign Key de substitution dans la table enfant
-> Initialisation d'un champ Foreign Key de substitution dans la table enfant
Création d'une contrainte sur le Foreign Key dans la table enfant
Création de déclencheurs pour maintenir le champ de substitution dans la table enfant
Si le Parent Key de la table Parent dans la relation découverte est conditionné, création d'une vue avec une clause Where identique à la condition
- Avantages
La contrainte est basée sur une clé primaire unique dans la table parent
Les relations sont toujours exposées à la base de données
Vous avez le choix d'appliquer l'intégrité référentielle ou non
Les contraintes CASCADE, SET NULL et SET DEFAULT sont prisent en charge lors de la mise à jour du Parent
Le moteur de recherche de base de données utilise la contrainte pour optimiser les performances
Plus les autres avantages "Xcase"
- Inconvénients
Les applications violant l'intégrité référentielle doivent être modifiées à moins que " No RI " n'ai été sélectionné dans le produit
Modernize-DB, Modernisation de la base
- Modernisation de base de données
- Fondation pour la réussite de la modernisation d'applications
- Cependant, il est souhaitable de rester compatible avec l'existant
- Ceci peut être atteint en utilisant la méthodologie développée par IBM et vue plus haut
- Modernize-DB est la mise en œuvre de cette méthodologie
- Automation
- Contrôle
La méthode choisie est celle que nous venons de voir de "Surrogate Key"
Avant
Après
*FLI = Format Level Identifier (Identifiant de niveau de format testé par LVLCHK)
- Préservation de la compatibilité
- Remplacement du PF par
- Une Table SQL
- Un Surrogate LF
- Transformation du LF existant
- Transformation des Views ou MQT existant
- Si le FLI est identique, vous pouvez également ajouter de nouvelles colonnes, sans qu'il soit modifié
Problèmes possibles
- "Vrai" Multi-membre
- Fichiers de travail
- PF Déjà utilisé dans une commande CRTDUPOBJ ou CLRPFM
- FLI du surrogate et du PF diffèrent (assez rare)
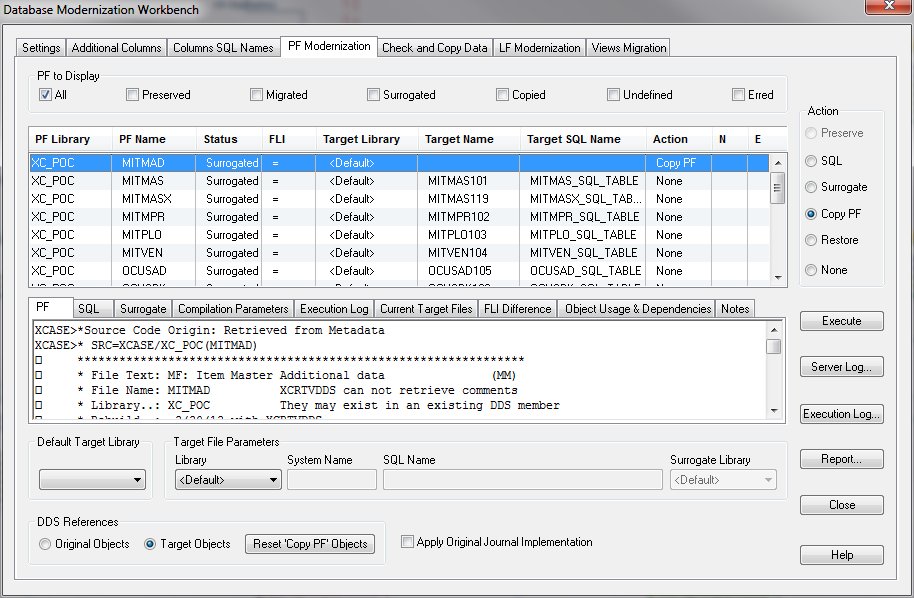
Le produit propose à travers un paramétrage très complet des options de transformation, la transformation elle même de manière automatisée avec des logs assez détaillées.
Comparaison de l'approche « manuelle » de la modernisation par rapport à l’automatisation propose par Xcase
- System i Navigator ne produit pas les indexes SQL à définir (basées sur les clefs du PF et des LF dependants), Xcase le fait.
- Xcase ajoute automatiquement des colonnes supplémentaires à la table SQL (Identité, TimeStamp , Utilisateur renseigné par trigger)
- Noms longs des colonnes et tables
- Vérification et copie efficace des donnes lors de la migration
- Lors de la fabrication manuelle des LF (Surrogate) il faut récupérer tous les Keywords non explicites puisqu'ils ne sont plus hérités depuis le PF
- Xcase transforme les Vues et MQT existantes pour les faire pointer vers les tables SQL
Le but pour nous n'étant pas de faire la promotion de ce produit (très bien fait par ailleurs) mais de vous présenter une stratégie possible.
Quelques références :
- DDS and SQL - The winning Combination for DB2 for i
-> Comparatif DDS / SQL par Kent Milligan
- Modernizing IBM Eserver iSeries Application Data Access - A Roadmap Cornerstone
-> LE redbook qui explique probablement la stratégie utilisée par XCASE
- Modernize a DB2 for I application
-> Modernisation d'un application, exemple pas à pas, par Gene Cobb
- Enfin, Application Modernization: DB2 for i5/OS style
-> Présentation très complète de Mike Cain et Gene Cobb (qui d'ailleurs parle de Xcase).
Enfin quelques nouveautés qui nous ont semblé intéressantes
- C'est officiel, EXIT la console SDMC !
- Ce RedPaper explique comment migrer vers la dernière version de la HMC V7R7.4
- Nous avons installé HMC V7R7.4.0.2 sur notre 7042-CR6 à la place du soft SDMC
- tout c'est bien passé
- Le serveur et les partitions (enregistrées sur le FSP) ont été bien reconnus
- bref, transition sans problème (heureusement que nous n'avions pas choisi l'option "software appliance" pour la SDMC)
- ce wiki documente les améliorations apportées au serveur d'applications intégré.
Après la PTF SI43471 qui apporte de nouveaux paramètres à la commande CPYSPLF permettant la transformation d'un spool existant
CPYSPLF QPDSPAJB TOFILE(*TOSTMF) TOSTMF(/temp/wrkactjob.txt)
CPYSPLF QPDSPAJB TOFILE(*TOSTMF) TOSTMF(/temp/wrkactjob.tif)
WSCST(QSYS/QWPTIFFG4)
CPYSPLF QPDSPAJB TOFILE(*TOSTMF) TOSTMF(/temp/wrkactjob.pdf)
WSCST(*PDF)
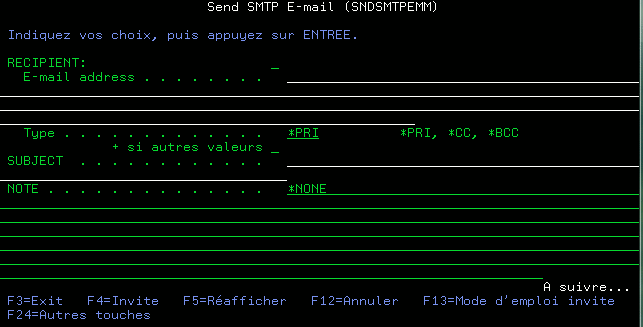
La commande SNDSMTPEMM vient d'arriver avec la PTF (V7) SI44334, voyez l'invite :
Quelques particularités :
- pas d'aide associée à la commande, pas de documentation disponible à ce jour.
- on ne peut pas choisir l'émetteur, l'adresse est automatiquement extraite de la directory système (WRKDIRE + F19 ou WRKNAMSMTP)
- si l'utilisateur n'a pas d'adresse, à aujourd'hui, l'adresse est "composée" à partir du libellé de la directory système, ce qui pose parfois des problèmes avec les espaces (QSECOFR par exemple)
Dans la liste des nouveautés récentes, arrivées via PTF :
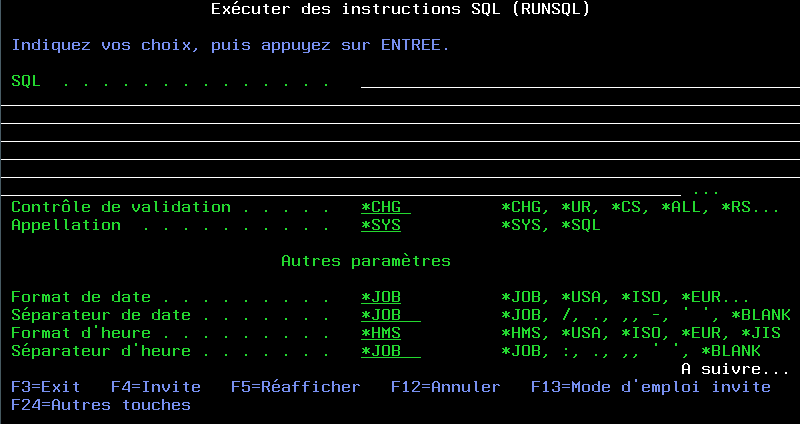
• la SI46477 (V6) ou SI46556 (V7) proposent la commande RUNSQL
Comme avec SNDSMTPEMM, il n'y a pas d'aide associé (à ce jour)
Comme avec RUNSQLSTM, la plupart des ordres SQL peuvent être utilisés, sauf SELECT
Contrairement à RUNSQLSTM, il n'y a pas :
- de commit automatique , mais vous pouvez utiliser la commande CL COMMIT
- de génération de spool d'erreur, vous recevez le code erreur dans le programme
Exemples d'utilisation donnés par la documentationRUNSQL SQL('INSERT INTO prodLib/worktable VALUES(1, CURRENT TIMESTAMP)')RUNSQL SQL('CREATE TABLE qtemp.worktable AS (SELECT * FROM qsys2.systables WHERE table_schema = ''MYSCHEMA'') WITH DATA') COMMIT(*NONE) NAMING(*SQL)Vous pouvez ensuite lire WORKTABLE par RCVF
Enfin la commande SQL peut être une variable :
DCL &LIB TYPE(*CHAR) LEN(10) DCL &SQLSTMT TYPE(*CHAR) LEN(1000) CHGVAR VAR(&SQLSTMT) VALUE('DELETE FROM qtemp.worktable + WHERE table_schema = ''' *cat &LIB *cat ''') RUNSQL SQL(&SQLSTMT) COMMIT(*NONE) NAMING(*SQL)• la SI46394 et SI46321 apportent plus de fonctionnalités d'audit à STRDBMON
SI46394 place; en cas de "embeded SQL", dans :
- QQC103 le nom du programme ou programme de service contenant l'ordre SQL
- QQC104 le nom de la bibliothèque du programme
Rappel, nous avons la possibilité de filtrer sur :
- La table ou fichier physique (FTRFILE)
- L'utilisateur (FTRUSR)
- L'adresse IP d'origine (FTRINTNETA)
Déjà (SF99601 level 21, SF99701 level 11) apportaient de nouveaux paramètres orientés AUDIT :
- Profil de groupe admis sur le paramètre FTRUSER
- FTRSQLCODE permet de filtrer sur le code SQL avec les valeurs suivantes :
- *NONE - pas de filtre sur SQLCODE
- *NONZERO - tout code SQL autre que 0
- *ERROR - tout code SQL d'erreur (< à 0)
- *WARN - tout code SQL de Warning (> à 0)
- <un n° de SQLCODE>
- Les registres clients peuvent être des filtres sur la commande STRDBMON en V7
- FTRCLTPGM pour PROGRAMID
(rappelez vous, STRSQL et RUNSQLSTM renseignent maintenant ce registre)- FTRCLTAPP pour APPLNAME
- FTRCLTUSR pour USERID
- FTRCLTWS pour WRKSTNNAME
- FTRCLTACG pour ACCTNG
dans le paramètre COMMENT en V6, par exemple COMMENT('FTRCLTPGM(STRSQL)')
Je peux donc demander la liste des utilisateurs du groupe « COMPTA » utilisant STRSQL
- ces informations seront placées dans le résultat du STRDBMON quand QQRID = 1000
- QVC3006 pour PROGRAMID
- QVC3001 pour APPLNAME
- QVC3002 pour USERID
- QVC3003 pour WRKSTNNAME
- QVC3005 pour ACCTNG
- SI46321 permet un support de QUERY/400
Les registres clients sont maintenant renseignés :
- CLIENT PROGRAMID = 'RUNQRY'
- CLIENT APPLNAME = 'RUN QUERY'
Comme STRSQL et RUNSQLSTM- CLIENT USERID = le profil en cours
- CLIENT WRKSTNNAME = le nom rdb en cours
- CLIENT ACCTNG = le code accouting en cours
et le paramètre FTRCLTPGM de STRDBMON admet le filtre RUNQRY
• SI46631 implémente une nouvelle fonction XMLTABLE produisant un contenu SQL à partir d'un flux XML
Exemple, Soit la table CUSTOMER
SET CURRENT SCHEMA POSAMPLE;
CREATE TABLE CUSTOMER ( CID BIGINT NOT NULL PRIMARY KEY , INFO XML ) ;Avec les données suivantes
'<customerinfo Cid="1000">
<name>Kathy Smith</name>
<addr country="Canada">
<street>5 Rosewood</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
<pcode-zip>M6W 1E6</pcode-zip>
</addr>
<phone type="work">416-555-1358</phone>
</customerinfo>') INSERT INTO Customer (Cid, Info) VALUES (1002,
'<customerinfo Cid="1002">
<name>Jim Noodle</name>
<addr country="Canada">
<street>25 EastCreek</street>
<city>Markham</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N9C 3T6</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
</customerinfo>') INSERT INTO Customer (Cid, Info) VALUES (1003,
'<customerinfo Cid="1003">
<name>Robert Shoemaker</name>
<addr country="Canada">
<street>1596 Baseline</street>
<city>Aurora</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N8X 7F8</pcode-zip>
</addr>
<phone type="work">905-555-2937</phone>
</customerinfo>')SELECT X.NOM, X.RUE, X.VILLE FROM Customer, XMLTABLE ('$c/customerinfo' passing INFO as "c" COLUMNS NOM CHAR(30) PATH 'name', RUE VARCHAR(25) PATH 'addr/street', VILLE VARCHAR(25) PATH 'addr/city' ) AS X Affiche ....+....1....+....2....+....3....+....4....+....5....+....6....+....7
NOM RUE VILLE
Kathy Smith 5 Rosewood Toronto
Jim Noodle 1150 Maple Drive Newtown
Robert Shoemaker 1596 Baseline Aurora
******** Fin de données ********
Si nous avions inséré les données de la manière suivante
'<customerinfo xmlns="http://posample.org" Cid="1000">
<name>Kathy Smith</name>
<addr country="Canada">
<street>5 Rosewood</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
<pcode-zip>M6W 1E6</pcode-zip>
</addr>
<phone type="work">416-555-1358</phone>
</customerinfo>') INSERT INTO Customer (Cid, Info) VALUES (1002,
'<customerinfo xmlns="http://posample.org" Cid="1002">
<name>Jim Noodle</name>
<addr country="Canada">
<street>25 EastCreek</street>
<city>Markham</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N9C 3T6</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
</customerinfo>') INSERT INTO Customer (Cid, Info) VALUES (1003,
'<customerinfo xmlns="http://posample.org" Cid="1003">
<name>Robert Shoemaker</name>
<addr country="Canada">
<street>1596 Baseline</street>
<city>Aurora</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N8X 7F8</pcode-zip>
</addr>
<phone type="work">905-555-2937</phone>
</customerinfo>')les éléments XML sont alors réputés comme appartenant à un espace de nommage (namespace)
le choix d'un élément se fait en indiquant l'espace de nommage ou * (tous) suivit de ":"
Il faut alors écrire :
SELECT X.NOM, X.RUE, X.VILLE FROM Customer, XMLTABLE ('$c/*:customerinfo' passing INFO as "c" COLUMNS NOM CHAR(30) PATH '*:name', RUE VARCHAR(25) PATH '*:addr/*:street', VILLE VARCHAR(25) PATH '*:addr/*:city' ) AS XOu bien définir l'espace de nommage
SELECT X.nom ,x.rue, x.ville, x.pays FROM posample/Customer, XMLTABLE ( XMLNAMESPACES('http://posample.org' as "cli"), '$c/cli:customerinfo' passing INFO as "c" COLUMNS NOM CHAR(30) PATH 'cli:name', RUE VARCHAR(25) PATH 'cli:addr/cli:street', VILLE VARCHAR(25) PATH 'cli:addr/cli:city', PAYS char(30) PATH 'cli:addr/@country' ) AS XVous remarquerez le choix d'un attribut "@country"
Ou bien encore, définir un espace de nommage par défaut
SELECT X.nom ,x.rue, x.ville, x.pays FROM posample/Customer, XMLTABLE ( XMLNAMESPACES(DEFAULT 'http://posample.org'), '$c/customerinfo' passing INFO as "c" COLUMNS NOM CHAR(30) PATH 'name', RUE VARCHAR(25) PATH 'addr/street', VILLE VARCHAR(25) PATH 'addr/city', PAYS char(30) PATH 'addr/@country' ) AS X
S'il existe plusieurs numéros de téléphone vous pouvez écrireSELECT X.nom ,x.rue, x.ville, x.TEL
FROM posample/Customer,
XMLTABLE (
XMLNAMESPACES(DEFAULT 'http://posample.org'),
'$c/customerinfo' passing INFO as "c"
COLUMNS
NOM CHAR(30) PATH 'name',
RUE VARCHAR(25) PATH 'addr/street',
VILLE VARCHAR(25) PATH 'addr/city',
TEL char(10) PATH 'phone[1]'
) AS X
Sans choix d'un téléphone (ici le premier), nous n'aurions pas eu les lignes où le téléphone est en double
Nous aurions pu aussi retourner la totalité des téléphones sous forme XML
SELECT X.nom ,x.rue, x.ville, x.TEL
FROM posample/Customer,
XMLTABLE (
XMLNAMESPACES(DEFAULT 'http://posample.org'),
'$c/customerinfo' passing INFO as "c"
COLUMNS
NOM CHAR(30) PATH 'name',
RUE VARCHAR(25) PATH 'addr/street',
VILLE VARCHAR(25) PATH 'addr/city',
TEL XML PATH 'phone'
) AS X
Enfin il est possible de faire des sélections sur les éléments XML
SELECT X.nom ,x.rue, x.ville
FROM posample/Customer,
XMLTABLE (
XMLNAMESPACES(DEFAULT 'http://posample.org'),
'$c/customerinfo[[addr/@country = "Canada"]' passing INFO as "c"
COLUMNS
NOM CHAR(30) PATH 'name',
RUE VARCHAR(25) PATH 'addr/street',
VILLE VARCHAR(25) PATH 'addr/city'
) AS X
Vous remarquerez la syntaxe XPATH déjà utilisée avec OmniFind et maintenant documentée sur Information Center
• SI46876 permet d'insérer des données venant d'une base de données remote
Il est possible depuis la V7 d'utiliser une base "remote" de manière implicite plutôt que d'écrire connect to AUTREAS select * from mabib.matable Ecrivez select * from AUTREAS.mabib.matable la connexion doit être avec authentification automatique, c'est à dire qu'il faut avoir enregistré les paramètres d'authentification à l'avance par : ADDSVRAUTE USPRF(*CURRENT) SERVER(AUTREAS) USERID(profil-distant) PASSWORD(motdepasse-distant) Vous pourrez maintenant écrire (par exemple) INSERT INTO GESCOM.VENTES (SELECT * FROM AUTREAS.GESCOM.VENTES WHERE DATEHA = CURRENT DATE - 1 DAY)
Toutes ces nouveautés étant, comme d'habitude maintenant, documentées sur le wiki Technology Updates
Enfin sur les machines récentes, les unités DVD sont en fait des graveurs (type 6331).
Comment s'en servir ?
Vous Devez passer par une unité optique virtuelle
CRTDEVOPT DEVD(OPTVRT01) RSRCNAME(*VRT)pensez à mettre l'unité VARY ON par wrkcfgsts *dev optvrt01
Ensuite, créez un catalogue d'images
CRTIMGCLG IMGCLG(OPTVIR) DIR('/optvir') CRTDIR(*YES) ADDIMGCLGE IMGCLG(OPTVIR) FROMFILE(*NEW) TOFILE(nom-de-fichier) IMGSIZ(*DVD4700) LODIMGCLG IMGCLG(OPTVIR) DEV(OPTVRT01) VFYIMGCLG IMGCLG(OPTVIR) TYPE(*OTHER) SORT(*NO)Sauvegardez sur ce catalogue
INZOPT NEWVOL(VOLUMENAME) DEV(OPTVRT01) TEXT('volume pour xxx') SAV DEV('/qsys.lib/optvrt01.devd') OBJ(('/xxx/*' *INCLUDE)) /* par exemple */Enfin, dupliquez vers le volume physique (c'est la seule action possible)
DUPOPT FROMVOL(*MOUNTED) TOVOL(*MOUNTED) NEWVOL(*FROMVOL) FROMDEV(OPTVRT01) TODEV(OPT01) TOENDOPT(*UNLOAD)
Copyright © 1995,2012 VOLUBIS