pause-café
destinée aux informaticiens sur plateforme IBM i.
Pause-café #57
IBM i , V7.1 - fin
OmniFind
Le serveur OmniFind est fourni avec la version 7 de IBM i. Il permet une indexation des champs texte, texte enrichi (format .doc ou .pdf, par exemple) et enfin, avec cette nouvelle version 1.2, les champs de type XML.
OmniFind apporte :
- un certain nombre de procédures stockées d'administration (création d'index par exemple)
- deux fonctions SQL, CONTAINS et SCORE, de recherche dans un index OmniFind
Ce produit s'installe par RSTLICPGM 5733OMF, les options 30,33 et 39 de SS1 et java (JV1) sont des pré-requis.
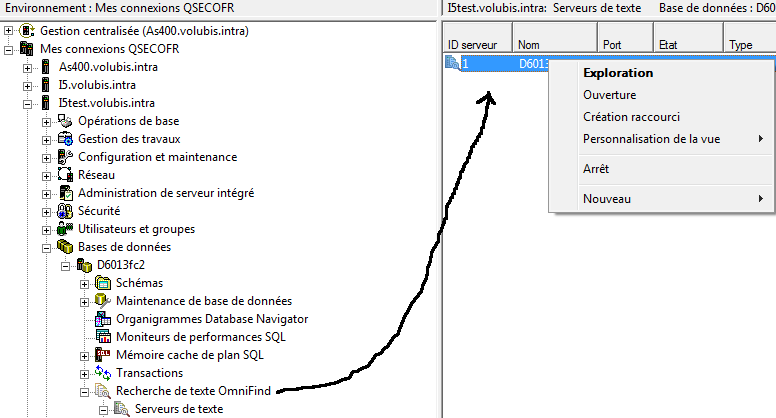
L'installation doit vous créer un serveur de texte avec l'ID n° 1 (cela créé un répertoire /QOpenSys/QIBM/ProdData/TextSearch/server1)
La requête suivante donne la liste des serveurs :
SELECT SERVERID,SERVERPORT,SERVERSTATUS,SERVERPATH FROM QSYS2.SYSTEXTSERVERS
(ServerStatus à 0 indique un serveur actif, 1 inactif)
Ainsi que System i navigator
le serveur se démarre avec cette même interface ou IBM Navigator Director
ou avec les procédures cataloguées suivantes
- CALL SYSPROC.SYSTS_START(n° ID de serveur)
- CALL SYSPROC.SYSTS_STOP(n° ID de serveur)
Si vous êtes en convention d'appellation système utilisez le / à la place du .
Enfin vous pouvez utiliser QSH :
- QSH CMD('cd /QOpenSys/QIBM/ProdData/TextSearch/server1/bin; startup.sh'), pour démarrer
- QSH CMD('cd /QOpenSys/QIBM/ProdData/TextSearch/server1/bin; shutdown.sh') pour arrêter
Indexation
Vous pouvez créer un index OmniFind sur les types de donnée suivants :
- CHAR , VARCHAR , CLOB , BLOB , DBCLOB , GRAPHIC, VARGRAPHIC , BINARY , VARBINARY , XML
les données peuvent être stockées en texte simple, HTML, XML, ou un format enrichi. Elles seront transformées en UNICODE 1208 avant d'être indexées, donc pas de job en CCSID(65535).Ce ne sont pas des index traditionnels DB2 (pas d'objet, donc pas de SAVOBJ) , ils ne sont pas maintenus temps réel et n'ont d'existence que dans le cadre du serveur OmniFind.
Les index sont enregistrés dans SYSTXTINDX de QSYS2, trois triggers sont ajoutés à la table indexée qui stockent les mises à jour dans une table temporaire, dite table de transfert, crée elle aussi à cette occasion (toujours dans QSYS2).
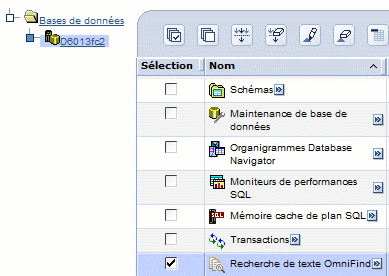
Création d'un Index
- par System i navigator
- Par procédure cataloguée
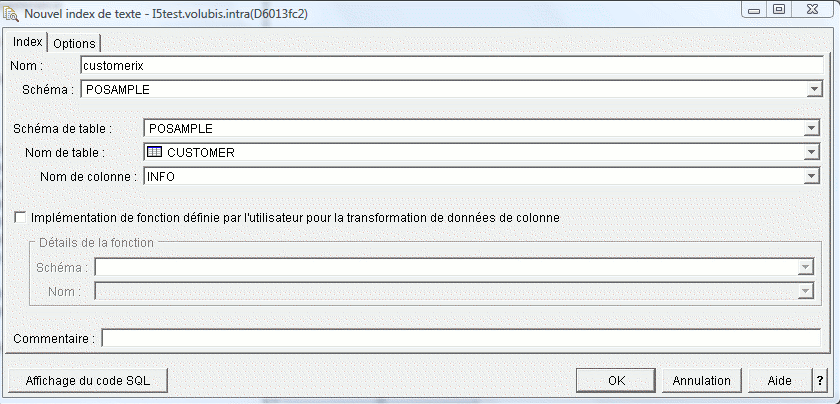
CALL SYPROCS.SYSTS_CREATE
Paramètres
- Nom de l'index VARCHAR(128)
- Schéma (bibliothèque) VARCHAR(128)
- Source, sous la forme
- schéma.table(colonne) référence une zone du fichier, à indexer.
- schéma.table(schéma.fonction(colonne) ) référence une fonction à lancer sur une des zones de la table dont il faut indexer le résultat
On pourrait ainsi imaginer une fonction qui lise un fichier dans l'IFS et en retourne le contenu afin d'utiliser OmniFind pour indexer des fichiers stream associés à des éléments base de donnée.
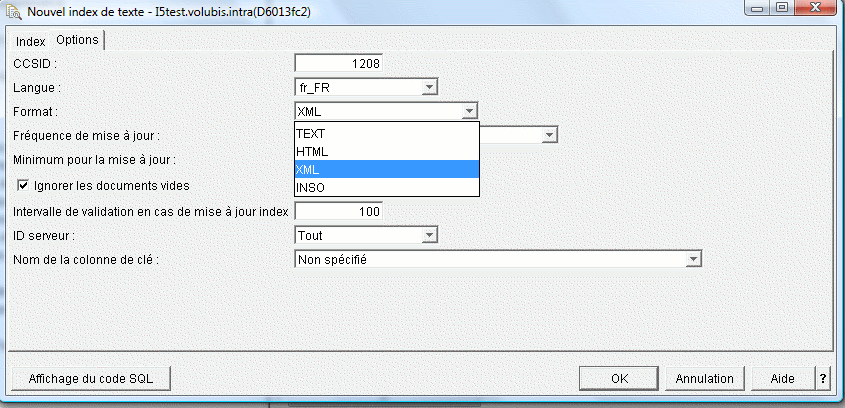
- Options
- CCSID un n° de CCSID
- LANGUAGE un code langage (fr_FR ou en_US)
- FORMAT
- TEXT
- HTML
- XML
- INSO qui permet une reconnaissance automatique des formats Lotus, Word, Excel, Pps, Html, PDF, OpenOffice et RTF.
- UPDATE FREQUENCY
- NONE
- D( )
- * tous les jours
- 0 à 6 : le N° du jour de la semaine de mise à jour
- H( )
- * toutes les heures
- 0 à 23 : heure de mise à jour
- M( )
- * toutes les 5 minutes
- 0 à 59 : minutes de mise à jour
par exemple UPDATE FREQUENCY D(*) H(*) M(0 , 30) demande une mise à jour toutes les demi-heures
- On peut aussi utiliser un format chronologique plus compliqué à manipuler
- UPDATE MINIMUM
- nombre de mise à jour avant UPDATE de l'index tel que planifié par UPDATE FREQUENCY
- INDEX CONFIGURATION( )
- IGNOREEMPTYDOCS
- 0 les documents vide (colonne nulle) sont répercutés dans l'index
- 1 les documents vides ne sont pas répercutés dans l'index
- KEYCOLUMN
- nom de la zone clé à utiliser lors des mise à jour d'index, si non précisé la zone ROWID ou la clé primaire sera utilisée
- UPDATEAUTOCOMMIT
- indiquez un nombre de ligne à mettre à jour lors de la mise à jour de l'index avant de commiter
- 0, le commit n'a lieu qu'une seule fois en fin de mise à jour de l'index
- COMMENT
- indiquez un commentaire de 512c. maxi
(les valeurs par défaut des options sont stockées dans SYSTEXTDEFAULTS)
Exemple :
CALL SYSPROC.SYSTS_CREATE('BDVIN1', 'PRODUCTEURS_IX', 'BDVIN1.PRODUCTEURS(PR_AVIS)', 'CCSID 1208 LANGUAGE fr_FR FORMAT TEXT UPDATE FREQUENCY NONE UPDATE MINIMUM 1 INDEX CONFIGURATION(IGNOREEMPTYDOCS 1 , UPDATEAUTOCOMMIT 100)');
Une ligne est ajoutée dans SYSTEXTINDEXES (Nom système : SYSTXTINDX)la table de transfert est créé dans QSYS2 (son nom est précisé dans STAGINGTABLENAME), les trois triggers sont ajoutés à la table indexée afin d'écrire dans la table de transfert
un répertoire est créé dans l'IFS (répertoire /QOpenSys/QIBM/ProdData/TextSearch/server1/config/collections)
son nom est indiqué par COLLECTIONNAME (par exemple 0_1_3_2010_09_28_17_10_36_131543, pour l'index 3 créé en septembre 2010)Une vue est créé portant le nom de l'index (PRODUCTEURS_IX) dans la bibliothèque indiquée. C'est le seul objet pouvant être sauvegardé par SAVOBJ.SAVLIB.
La restauration de la vue, recréé l'index de recherche OmniFind (sans les données) et relance l'indexation.
Ensuite, il vous lancer la procédure de mise à jour (l'index est créé vide par SYSTS_CREATE) :
CALL SYPROCS.SYSTS_UPDATE
- Schéma
- Nom de l'index
- Option (facultative)
- USING UPDATE MINIUM
- nombre de mise à jour minimum dans la table de transfert pour faire la mise à jour de l'index.
l'index est alors créé dans le répertoire de la collection (la création prend au moins 3 à 5 fois le temps de création d'un index "normal")
-> Pour détruire l'index
CALL SYPROCS.SYSTS_DROP
- Schéma
- Nom de l'index
-> Pour modifier les caractéristiques de l'index
CALL SYPROCS.SYSTS_ALTER
- Schéma
- Nom de l'index
- Options
- toutes les options de la procédure SYSTS_CREATE
- RENAME FUNCTION
- pour renommer la fonction, si ce n'est pas une colonne qui est indexée.
Recherche
Deux fonctions sont à votre disposition :
- CONTAINS(zone-clé, 'expression-de-recherche')
Retourne 0 (ne contient pas) ou 1 (contient) si l'expression est présente dans la zone indexée.
- SCORE(zone-clé, 'expression-de-recherche')
retourne une valeur comprise entre 0 et 1 représentant une note de pertinence indiquant à quel degré l'expression est vraie
Ces deux fonctions peuvent avoir un troisième argument options, construit comme suit :
- QUERYLANGUAGE= fr_FR ou en_US
- RESULTLIMIT=valeur, pour limiter la réponse aux n premières valeurs.
- SYNONYM = OFF ou ON, pour utiliser ou non les synonymes.
Exemple :
WHERE contains(pr_avis,'excellent') = 1
Que mettre dans une expression de type texte
- un-mot
- en minuscules ou en majuscules, l'indexation ne tient pas compte de la casse
- avec ou sans le s pluriel, ainsi contains(pr_avis , 'coopérative') trouve les avis contenant coopératives
- avec sous sans les accents ainsi contains(pr_avis , 'cooperative') trouve les avis contenant coopérative(s)
- - (tiret) un-mot
- ce mot est exclut (il ne doit pas être rencontré) contains(pr_avis , 'cave -cooperative'), recherche cave et PAS coopérative
- deux mots
- il sont implicitement reliés par AND
contains(pr_avis , 'cave cooperative') trouve cave(s) ET coopérative(s)- si vous les placez entre guillemets " , c'est la chaîne qui est recherchée
contains(pr_avis , ' "cave cooperative" ') trouve cave suivit de coopérative (les pluriels ne sont plus gérés, mais la casse et l'accentuation sont toujours ignorées)
- Opérateurs
- AND ou + , opérateur implicite 'cave coopérative' et cave AND coopérative' retourne les mêmes résultats
- NOT ou - , exclusion d'un mot
- OR relation OU entre deux expressions
Bien sur vous pouvez utiliser les parenthèses ouvrantes et fermantes
- *
- caractère générique permettant d'émettre une début de mot (coop* par exemple)
- \
- caractère d'échappement permettant de rechercher un + (\+) ou un - (\-) par exemple
Exemple :
contains(pr_avis, 'chateau AND (pomerol OR lafite)') = 1 ;
trouve les lignes contenant chateau ou château ou châteaux puis, soit pomerol, soit lafite.
On peut même créer un dictionnaire de synonymes personnel en créant un fichier XML
Exemple :
<synonymgroups version="1.0">
<synonymgroup>
<synonym>vin</synonym>
<synonym>pinard</synonym>
<synonym>picrate</synonym>
<synonym>nectar</synonym>
</synonymgroup>
<synonymgroup>
<synonym>syrah</synonym>
<synonym>schiraz</synonym>
</synonymgroup>
</synonymgroups>puis en passant la commande (sous QSH)
-synonymFile <chemin du fichier XML>
-collectionName <nom de la collection>
-replace <[true|false]>
-configPath <chemin absolu du dossier de config.>
Exemple > synonymTool.sh importSynonym
-synonymFile /temp/vin_synonyme.xml
-collectionName 0_1_3_2010_09_28_17_10_36_131543 -replace false
-configPath /QopenSys/QIBM/ProdData/TextSearch/server1/config
IQQD0084I The request was successfully executed.
$
contains(pr_avis, 'pinard')= 1 Donne 1 (pinard est le nom d'un producteur de Cognac) select count(*) FROM bdvin1/producteurs WHERE
contains(pr_avis, 'pinard', 'SYNONYM=ON')= 1 Donne 606
Recherche XML
La syntaxe des recherches XML utilise un sous-ensemble du langage W3 XPath
sous la forme CONTAINS(nom_colonne, '@xmlxp: ' 'expression_requête_Xpath' ' ')
le deuxième paramètre de la fonction CONTAINS est une chaîne donc entre quote ('), l'expression XPath étant elle même entre quotes il faut doubler ces dernières
vous devez indiquer un chemin dans l'arborescence XML :
Expression XPath Signifie / sélectionne le nœud, dit root element, qui englobe tout le document sauf <?xml version="1.0"?> // sélectionne tous les noeuds . sélectionne le nœud en cours /customerinfo sélectionne le nœud "customerinfo" //city sélectionne tous les éléments "city" du document où qu'ils soient /customerinfo/name sélectionne l'unique élément "name" fils de "customerinfo" puis, éventuellement, un Predicat (un test) devant être vrai, toujours entre crochets [ et ]
Prédicat Signifie //phone[. = "xxx"] sélectionne tous les éléments "phone" du document (où qu'ils soient), ayant une valeur égale à xxx //phone[@type = "work"] sélectionne tous les éléments "phone" du document, ayant un attribut "type" dont la valeur est "work" Pour les valeurs :
- Numerique, saisissez tel que '//quantite[. > 12000]'
- Alpha, saisissez entre guillemets '//phone[. = "02.40.30.00.70"]'
- Date, xs:date ou xs:DateTime, par exemple utilisez '/Article[@DateCrt > xs:date("2010-10-05")]'
- la requête XPath peut elle même contenir une recherche textuelle avec contains ou exclude, comme
'/Article[libart contains("piece AND rechange")]'Exemples :
'<customerinfo xmlns="http://posample.org" Cid="1000">
<name>Kathy Smith</name>
<addr country="Canada">
<street>5 Rosewood</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
<pcode-zip>M6W 1E6</pcode-zip>
</addr>
<phone type="work">416-555-1358</phone>
</customerinfo>') INSERT INTO Customer (Cid, Info) VALUES (1002,
'<customerinfo xmlns="http://posample.org" Cid="1002">
<name>Jim Noodle</name>
<addr country="Canada">
<street>25 EastCreek</street>
<city>Markham</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N9C 3T6</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
</customerinfo>') INSERT INTO Customer (Cid, Info) VALUES (1003,
'<customerinfo xmlns="http://posample.org" Cid="1003">
<name>Robert Shoemaker</name>
<addr country="Canada">
<street>1596 Baseline</street>
<city>Aurora</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N8X 7F8</pcode-zip>
</addr>
<phone type="work">905-555-2937</phone>
</customerinfo>')
SELECT * from posample/customer
where contains(info, '@xmlxp:''//name'' ') = 1 ....1....+.
CID
1.000 1.002 1.003
SELECT * from posample/customer
where contains(info, '@xmlxp:''//phone[. = "416-555-1358"]'' ')=1
....1....+.
CID
1.000
SELECT * from posample/customer
where contains(info,'@xmlxp:''//phone[. contains("905") ]'' ') = 1 ....1....+.
CID
1.002
1.003
SELECT * from posample/customer
where contains(info,'@xmlxp:''/customerinfo[phone = "416-555-1358"]'' ')=1
....1....+.
CID
1.000
QZDASOINIT
QZDASOINIT est un job de type serveur, démarré par STRHOSTSVR *DATABASE et répondant aux requêtes SQL entrantes (ODBC/JDBC))
Voyez la liste des travaux de type serveur ici http://publib.boulder.ibm.com/infocenter/iseries/v7r1m0/topic/rzaku/rzakuservertable.htm
Le job est-il lancé en avance ? se termine-t-il tout seul ? le nombre d'activation est-il limité ? bref comment fonctionnent les travaux à démarrage anticipé ?
Ce sont des questions que vous nous posez souvent lors des démarrages de projets client/serveur ou N-tiers, et nous avons essayé de faire le point.
» Fonctionnement d'un travail à démarrage anticipé :
|
Sous-Systèmes TRAVAUX A DEMARRAGE ANTICIPE. (ADDPJE) -------------
-Fonctionnent avec les entrées Télécom. (ADDCMNE ou services IP)
Permettent d'initialiser un travail sur le système cible (IBM i) avant l'activation du programme demandé par le système source (le client ou le serveur d'applications).
Ce travail doit se trouver DANS LE MEME SOUS-SYSTEME que l'entrée télécom pour l'unité APPC concernée, quand ADDCMNE sous SNA.
-Quand le système reçoit une demande de connexion réseau, il regarde s'il existe une entrée anticipée pour un pgm de MEME NOM que celui demandé
1/ si oui il utilise ce job
2/ si non un nouveau job est initialisé de manière traditionnelle.
-L'intérêt est que ce travail peut préparer un maximum de choses avant la demande d'activation (ouverture de fichiers B de D, initialisations, ...)
Ce travail va s'exécuter sous un profil donné jusqu'à la connexion.
A partir de cette demande, le profil de référence va devenir celui de la liaison télécom (voir dans la JOBLOG, le profil en cours), par défaut celui de l'entrée ADDCMNE si SNA.
Cas de QZDASOINIT (serveur Database)
Complément d'informations sur message
ID message . . . . . . : CPIAD02 Date d'envoi . . . . . : 23/05/08 Heure d'envoi . . . . : 06:20:00
Message . . . . : User FORMATION1 from client 10.3.1.1 connected to server. Cause . . . . . : User profile FORMATION1 from client 10.3.1.1 is currently connected to this server job. The client name is either a TCP/IP remote system name, a dotted decimal IP address, or the local host name
Indiquez vos choix, puis appuyez sur ENTREE.
Description de sous-système . . SBSD ########## Bibliothèque . . . . . . . . . *LIBL Programme . . . . . . . . . . . PGM ########## Bibliothèque . . . . . . . . . *LIBL Profil utilisateur . . . . . . . USER QUSER Démarrer les travaux . . . . . . STRJOBS *YES (1) Nombre initial de travaux . . . INLJOBS 3 (2) Seuil . . . . . . . . . . . . . THRESHOLD 2 (3) Nombre additionnel de travaux . ADLJOBS 2 (4) Nombre maximal de travaux . . . MAXJOBS *NOMAX (5)
F10 Travail . . . . . . . . . . . . JOB *PGM Description de travail . . . . . JOBD *USRPRF Nombre maximal d'utilisations . MAXUSE 200 (6) Attente de travail . . . . . . . WAIT *YES (7) Identificateur du pool . . . . . POOLID 1 Classe: CLS
1/ les travaux doivent-ils démarrer en même temps que le sous-système ?
Il est possible de démarrer un travail à tout moment avec la commande STRPJ et de forcer l'arrêt par ENDPJ.
Arrêter travaux anticipés (ENDPJ)
Indiquez vos choix, puis appuyez sur ENTREE.
Sous-système . . . . . . . . . . SBS QUSRWRK Programme . . . . . . . . . . . PGM QZDASOINIT Biblio . . . . . . . . . . . . *LIBL Type d'arrêt . . . . . . . . . . OPTION *CNTRLD
2/ si oui en (1), nombre de travaux à démarrer initialement
3/ seuil mini, qui va enclencher le démarrage de (4)
4/ nombre de travaux à démarrer à l'avance, quand le seuil est atteint.
5/ nombre maximum de travaux actifs en même temps.
6/ un travail anticipé en attente d'un besoin passe à l'état PSRW (vous ne les verrez sur le WRKACTJOB que si vous faites F14)
lors d'une demande entrante il devient actif, la connexion est notée dans la LOG (CPIAD02, comme vu plus haut)
lors de la demande de déconnexion :
-soit le job repasse à l'état PSRW (il est complément ré-initialisé, la JOBLOG est mise à blanc)
-soit le nombre de fois où il a été "recyclé" est atteint et il s'arrête (c'est ce paramètre qui fixe le nombre de ré-utilisation possibles)
7/ si le nombre de jobs pouvant être actifs est atteint (MAXJOBS en 5/) que se passe-t-il pour les demandes entrantes
*YES elles attendent qu'un job se libère *NO la demande est rejetée
Vous pouvez avoir des statistiques d'utilisation par DSPACTPJ
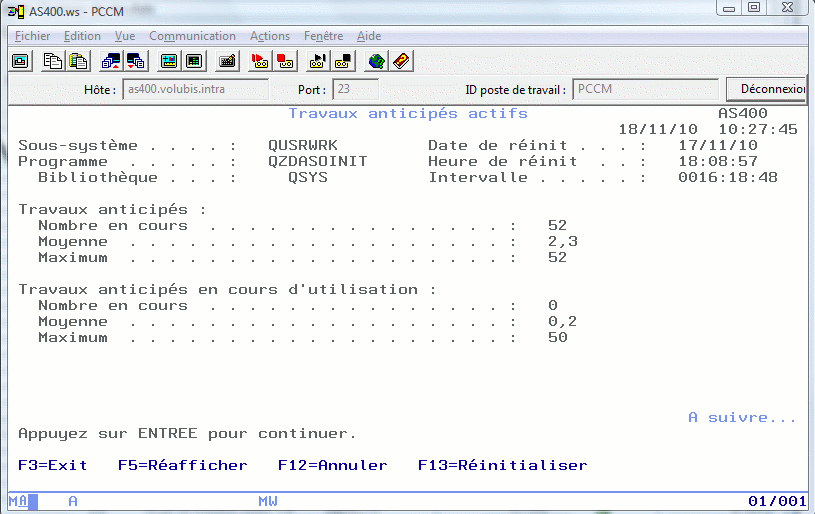
---------------------------------------------------------------------------- Travaux anticipés actifs AS400
Sous-système . . . . : QUSRWRK Date de réinit . . . : 17/11/10 Programme . . . . . : QZDASOINIT Heure de réinit . . : 16:29:24 Bibliothèque . . . : QSYS Intervalle . . . . . : 0001:19:57
Travaux anticipés : Nombre en cours . . . . . . . . . . . . . . . : 3 Moyenne . . . . . . . . . . . . . . . . . . . : 21,7 Maximum . . . . . . . . . . . . . . . . . . . : 52
Travaux anticipés en cours d'utilisation : Nombre en cours . . . . . . . . . . . . . . . : 1 Moyenne . . . . . . . . . . . . . . . . . . . : 1,6 Maximum . . . . . . . . . . . . . . . . . . . : 50 A suivre...
F3=Exit F5=Réafficher F12=Annuler F13=Réinitialiser
Vous pouvez réinitialiser les stats par F13 (un peu comme WRKACTJOB)
---------------------------------------------------------------------------- (écran suivant) Travaux anticipés actifs AS400
Sous-système . . . . : QUSRWRK Date de réinit . . . : 17/11/10 Programme . . . . . : QZDASOINIT Heure de réinit . . : 16:29:24 Bibliothèque . . . : QSYS Intervalle . . . . . : 0001:19:57
Demandes de démarrage de programmes : Nombre en cours d'attente . . . . . . . . . . : 0 Moyenne en attente . . . . . . . . . . . . . . : 0,0 Maximum en attente . . . . . . . . . . . . . . : 0 Temps d'attente moyen . . . . . . . . . . . . : 00:00:00,0 Nombre accepté . . . . . . . . . . . . . . . . : 5 Nombre refusé . . . . . . . . . . . . . . . . : 0
ici, vous avez des infos sur les éventuelles attentes et refus en fonction des paramètre MAXJOBS et WAIT.
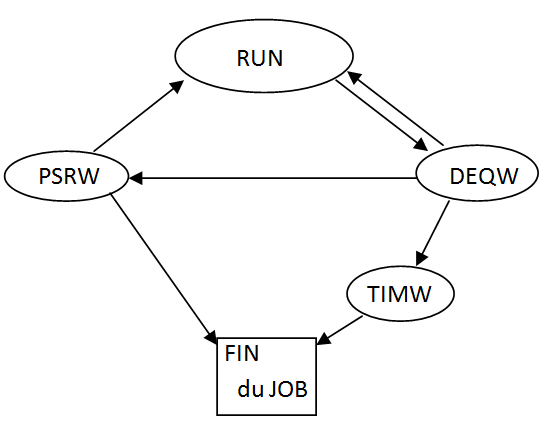
Cycle de vie d'un job QZDASOINIT
- Lors d'un démarrage anticipé le job doit passer à l'état PWSR (on ne les voit qu'avec F14 sur le WRKACTJOB)
- à la connexion il passe à l'état RUN, puis exécute la première requête
- entre deux requêtes, il est à l'état DEQW, puis repasse RUN à la requête suivante, etc...
- Lors d'une demande de déconnexion :
- si le nombre d'utilisations (200 par défaut pour QZDASOINIT) est atteint il se termine
- sinon, il repasse à l'état PSRW (on ne le voit plus sur WRKACTJOB), en attente d'un prochain besoin.
- En cas d'inactivité longue du client (fin du pgm sans demande de déconnexion, par exemple)
le serveur envoi une demande réponse et démarre un "timer" ( TIMW )
Cette situation n'est pas normale, sans doute une déconnexion oubliée par le développeur ou un bug du connecteur
(.NET de client access 5.3 avait un tel bug).
s'il ne reçoit pas de réponse au bout du temps prévu par le timer (dépend du paramètre TCP/IP TCPKEEPALV, + 3 minutes), il se termine.facultatif, allouez de la mémoire à un Pool partageable : CHGSHRPOOL *SHRPOOLn SIZE(xxx)
» Pour travailler dans un Pool mémoire ou un sous-système dédié :
créez un sous système utilisant ce pool ou *BASE:
CRTSBSD MONSBS POOLS((1 *SHRPOOLn)) TEXT('Sous système dédié')
puis
ADDRTGE MONSBS SEQNBR(10) CMPVAL(*ANY) PGM(QCMD) CLS(QBATCH)
- créez et ajoutez un JOBQ (ADDJOBQE) , si vous faites des tests en BATCH
- ajoutez une entrée WorkStation (ADDWSE), si vous pensez travaillez en 5250
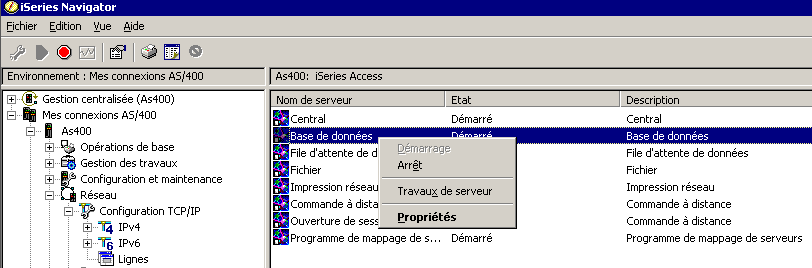
- Pour ODBC/JDBC (dont Iseries navigator), suivez la procédure suivante :
- Ajoutez un travail à démarrage anticipé à votre sous système, par :
ADDPJE SBSD(MONSBS) PGM(QSYS/QZDASOINIT) INLJOBS(?) JOBD(Qgpl/QDFTSVR) CLS(QSYS/QPWFSERVER)
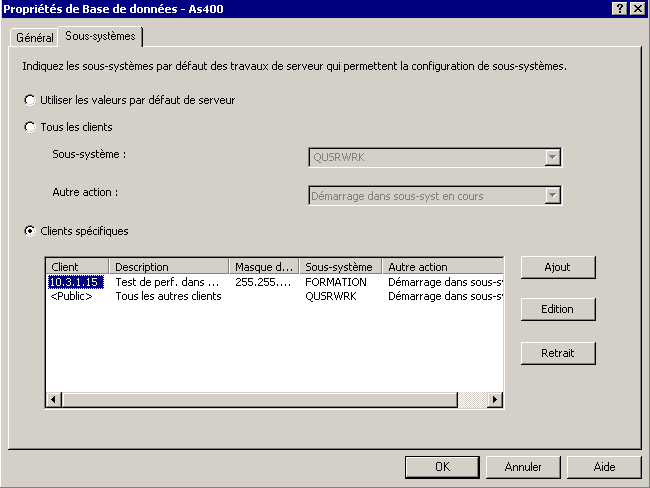
- modifiez les propriétés du serveur Database via Iseries Navigator
- allez sur l'onglet sous système
- Le bouton Ajout, permet d'indiquer votre sous système pour un ou plusieurs clients (adresse IP)
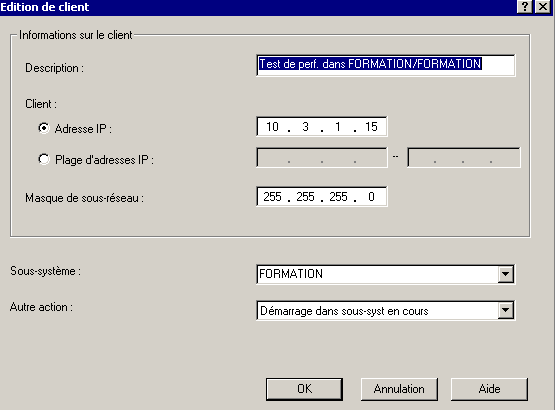
» Pour tester :
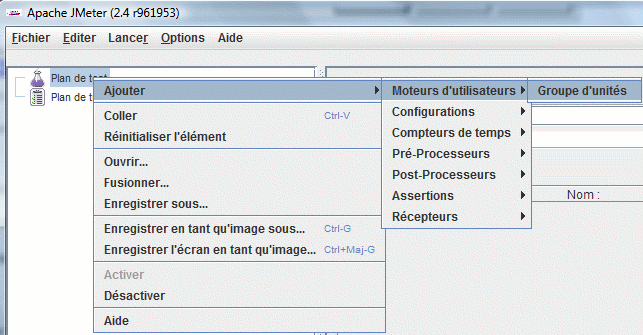
Enfin, pour tester tout cela (et faire des tests de montée en charge), voyez le projet Apache Jmeter
Dézippez et lancez jmeter.bat
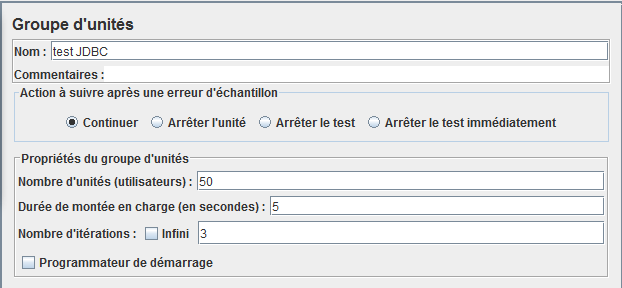
Ajoutez un groupe d'unité (de thread)
Indiquez un nombre d'utilisateurs, un objectif de durée (peut ne pas être respecté suivant la puissance votre poste) et un nombre de boucles
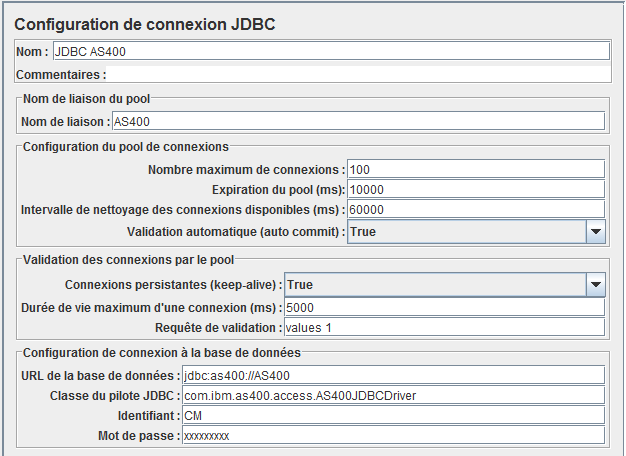
Ensuite, ajoutez dans Configurations une Configuration de connexion JDBC
indiquez :
- un nom de liaison à utiliser lors des requêtes
- une requête SQL de la validation de la connexion (values 1, retourne 1 bêtement, et est très rapide d'exécution)
- L'url d'accès : jdbc:as400://VOTRE-AS400
- les coordonnées de la classe JDBC : com.ibm.as400.access.AS400JDBCDriver
- un identifiant et mot de passe de connexion
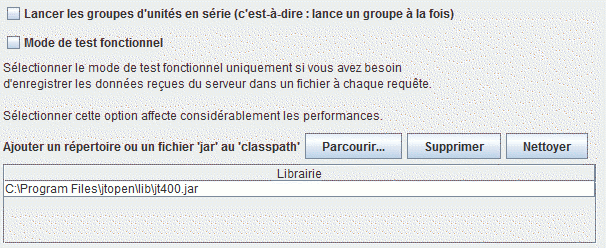
Il faut ensuite retourner sur le plan de test et ajouter le chemin de jt400.jar au CLASSPATH de Jmeter.
Téléchargez le, s'il faut depuis http://jt400.sourceforge.net/
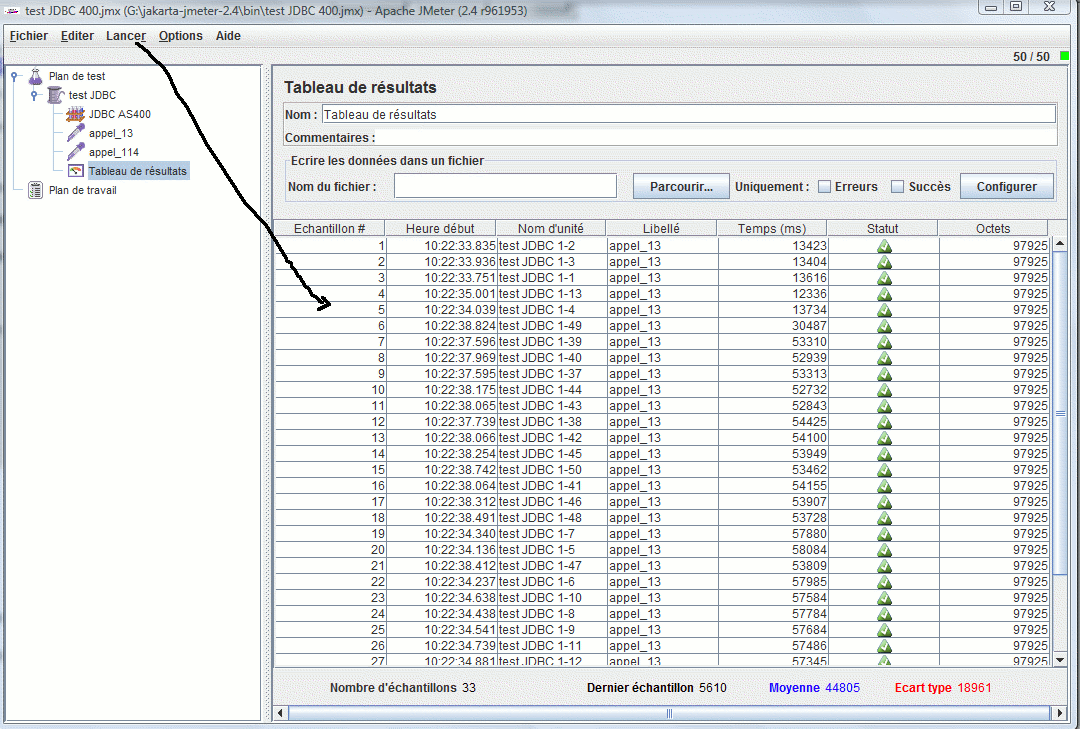
Ajoutez ensuite une ou plusieurs requêtes SQL (Ajouter/Échantillons/requête JDBC)
Remarquez le nom de liaison, correspondant à l'ID donné lors de la configuration de la connexion JDBC
Ajoutez enfin un récepteur pour voir les résultats de type Graphique de résultat ou Tableau de résultats (c'est le cas ci-dessous) puis lancez (Ctrl + R)
Les requêtes s'exécutent, voyons le résultat du coté IBM i, par DSPACTPJ QUSRWRK QZDASOINIT :
Pour plus de détails sur le réglage, voyez : http://publib.boulder.ibm.com/infocenter/iseries/v7r1m0/topic/experience_web/tuneprestart.pdf
Zend Server
Zend Server : des nouvelles du produit de Zend, la version 5.0.4 vient de sortir et remplace ZendCore.
Ce produit utilise la norme fastCGI, qui est disponible sur IBM i nativement sur une version 7 et via PTF sur une 6.1 ou 5.4
Avec cette technique le serveur Apache de IBM i peut lancer des scripts sous PASE, supprimant l'obligation d'avoir un deuxième serveur Apache tournant sous PASE
Important, Zend Server peut être installé, à coté de Zendcore, sans perturber le moins du monde ce dernier. Les 2 produits cohabitent parfaitement.Pré-requis :
1/ vérifiez que vous avez les logiciels sous licence suivants :
Code (option) Produit 5722SS1 (33) PASE 5722SS1 (30) Qshell 5722SS1 (13) System Openness Includes 5722SS1 (34) Digital Certificate Manager 5733SC1(*base) IBM Portable Utilities For I5/OS 5733SC1 (1) OpenSSH ,OpenSST,Zlib Le répertoire /usr/local doit exister (créez le, s'il le faut, par MKDIR) et ne doit pas être un lien symbolique
2/ vérifiez que vous avez les PTF suivantes
- V5R40
SI36004 (SS1 ) et SI36026 (DG1)
- V6R10
SI36005 (SS1 ) et SI36027 (DG1)
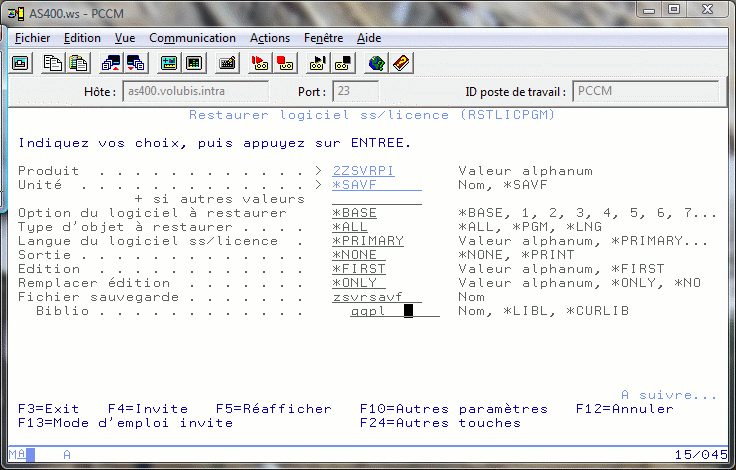
3/ Téléchargez le fichier zippé sur le site de ZEND, dézippez et transférez (en binaire) via FTP le SAVF ZSVRSAVF dans QGPL
4/ Passez ensuite la commande RSTLICPGM LICPGM(2ZSRVPI) DEV(*SAVF) SAVF(QGPL/ZSVRsavf)
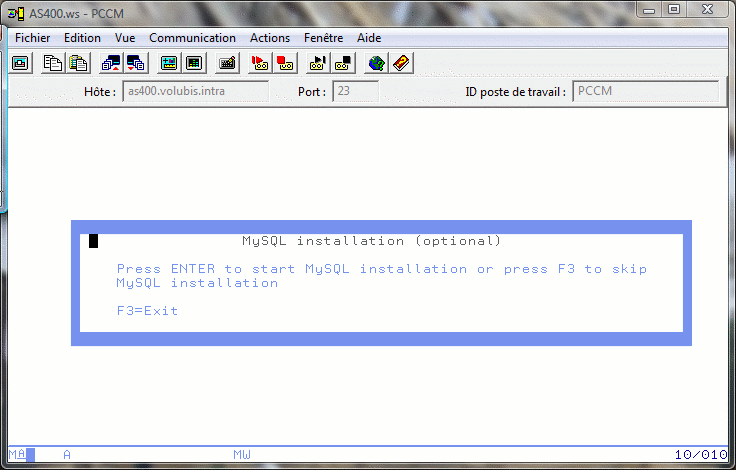
cela doit vous afficher l'écran de licence suivant :
Choisissez si vous souhaitez installer MYSQL ou non (cela n'est pas possible, s'il existe déjà un répertoire /usr/local/MYSQL)
Dernière minute, Oracle annonce la fin de distributions binaires de MYSQL pour IBM i ,AIX et Linux sur Power, ainsi qu'un support limité tout en continuant à proposer le téléchargement du code source (Open source oblige !).
Le support officiel de MYSQL sur IBM iet du DB2 Engine, pourraitêtre repris par ZEND.
Et voilà !
Le sous système ZENDSVR est lancé automatiquement grâce à un travail à démarrage automatique ZS_STR_SBS ajouté à QSYSWRK.
Le serveur Apache ZendSvr, aussi. Vous pouvez modifier cette instance, si vous n'avez pas actuellement de serveur.
--> pour modifier la configuration (/www/zendsvr/conf/httpd.conf), directive listen *:10088 et remplacer par le port 80
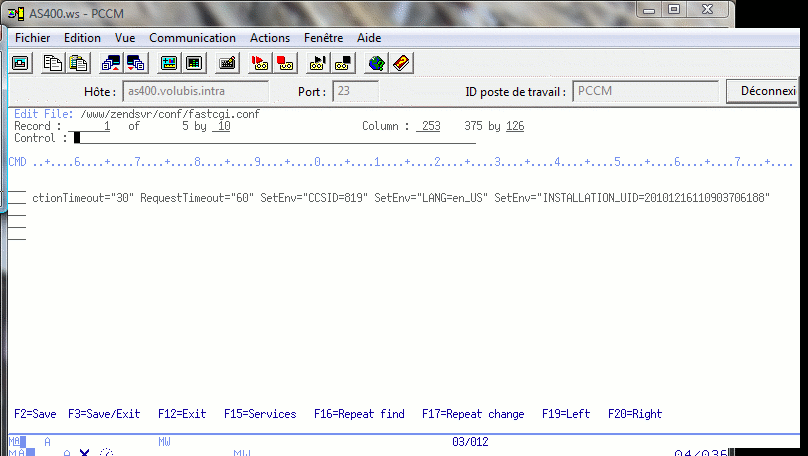
Modifiez aussi la langue du fichier fastcgi.conf qui contient à tort une config pour un OS en langue 2924 (US) , comme montré ci-dessous
ou bien ajouter à votre serveur apache existant :
LoadModule zend_enabler_module /QSYS.LIB/QHTTPSVR.LIB/QZFAST.SRVPGM
puis
AddType application/x-httpd-php .php
AddHandler fastcgi-script .php
Dans le même temps vous devez créer un fichier fastcgi.conf dans le même répertoire que le fichier httpd.conf
contenant
- sur une seule ligne
- Server type="application/x-httpd-php"
- CommandLine="/usr/local/ZendSvr/bin/php-cgi.bin"
- StartProcesses="1"
- SetEnv="LIBPATH=/usr/local/ZendSvr/lib"
- SetEnv="PHPRC=/usr/local/ZendSvr/etc/"
- SetEnv="PHP_FCGI_CHILDREN=5
- SetEnv="PHP_FCGI_MAX_REQUESTS=0"
- ConnectionTimeout="30"
- RequestTimeout="60"
- SetEnv="CCSID=819"
- SetEnv="LANG=fr_FR"
- SetEnv="INSTALLATION_UID=20101216110903706188"
Quelques commentaires
Server type="application/x-httpd-php" la chaîne doit être la même que pour la directive AddType du fichier httpd.conf CommandLine="/usr/local/ZendSvr/bin/php-cgi.bin Coordonnées du PGM PASE à lancer StartProcesses="1" Démarrer le pgm PASE à l'avance (1 = oui) SetEnv="PHP_FCGI_CHILDREN=5 Nombre de travaux à démarrer SetEnv="CCSID=819" CCSID des fichiers .php SetEnv="LANG=fr_FR" Doit être le code langage de la langue primaire (2928 en France) SetEnv="INSTALLATION_UID=20101216110903706188" recopiez la valeur de fastcgi.conf du répertoire /www/zendsvr/conf
- sur une nouvelle ligne
- IpcDir /www/<votre-instance>/logs
indique l'endroit ou stocker le fichier error_zfcgi
- FastCGi dialogue avec PASE à l'aide de sockets IP.Si vous changez de profil avec une directive d'authentification, le nouvel utilisateur risque de manquer de droits sur le socket
Pour palier à cela, vous pouvez utiliser l'une des trois directives suivantes, sur une nouvelle ligne :
- IpcPublic *RWX pour donner tous les droits à *PUBLIC
- IpcGroup un-profil *RWX pour donner les droits du groupe
- IpcOwner un-profil *RWX pour donner tous les droits du propriétaire
Attention, il faut SI41688 (V5R4) ou SI41704 (6.1) ou SI41706 (7.1)
Relancez le serveur Apache, puis accédez à l'URL (par défaut http://<votre-as400>:10088/ZendServer)
Acceptez la licence
Fixez un mot de passe d'accès aux pages d'administration
Enfin, entrez votre clé, si vous en avez une, sinon le produit tournera en mode Community Edition (CE)
RD Power 8
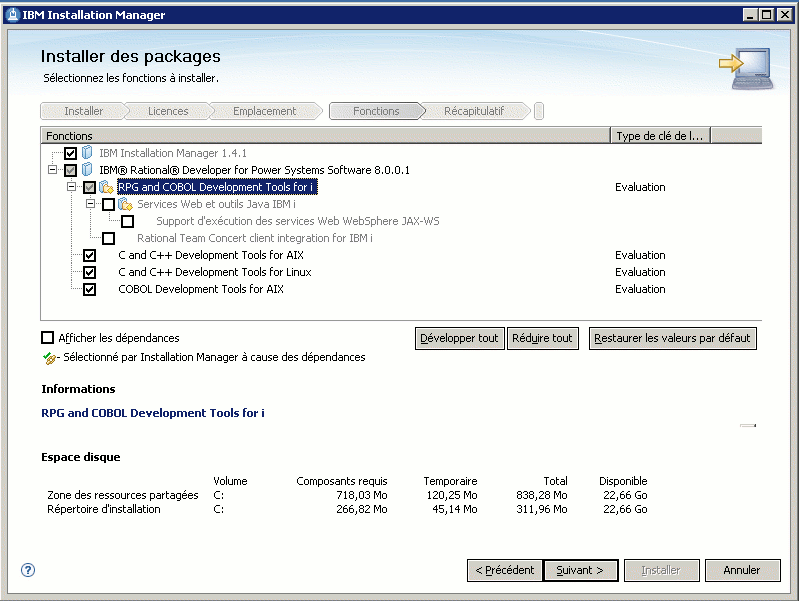
- Rational Developer for Power est le successeur de RDI, c'est un produit de convergence entre les outils pour IBM i et les outils pour AIX
1/ Installation
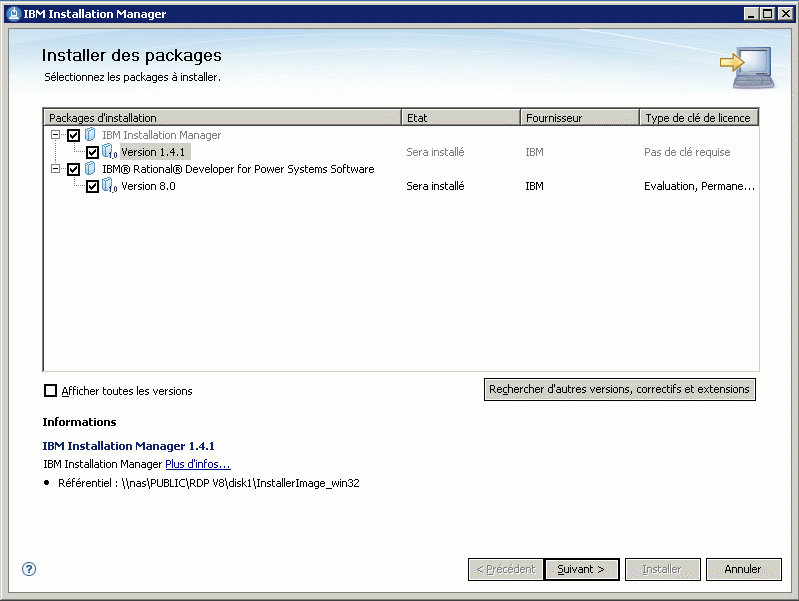
La procédure d'installation est très proche de RDI 7.5, si ce n'est que vous utiliser maintenant, Installation Manager 1.4.1
Il permet d'installer les outils pour IBM i et pour Unix (AIX ou Linux sur Power)
2/ Nouveautés
- Divers
- Support de la version 7 de IBM i et des nouvelles syntaxes (RPG particulièrement)
- Quelques bug corrigés
- Support des distributions SUSE et REDHAT comme clients Linux
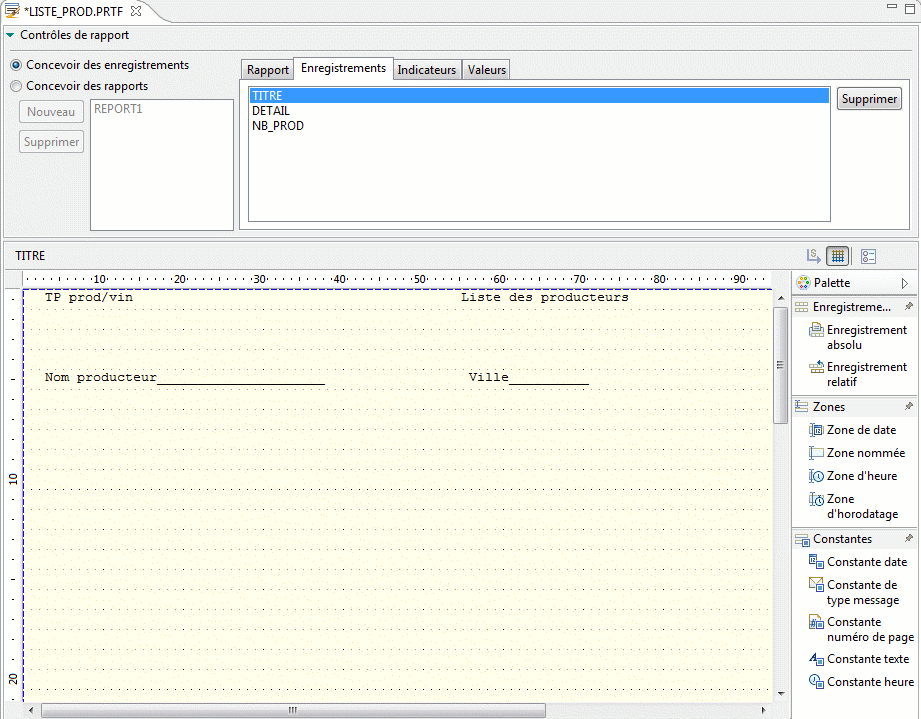
- Nouvel outil, Report Designer, pour concevoir des états (PRTF)
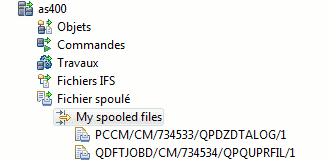
- Et la possibilité d'afficher les Spools
Copyright © 1995,2011 VOLUBIS