il s'agit du produit, proposé depuis la V6, regroupant
il tourne en tant qu'application avec le serveur d'Administration, démarré par STRTCPSVR SERVER(*HTTP) HTTPSVR(*ADMIN)
Il utilise le port 2005, et toute requête vers la racine sur le port 2001 est redirigée vers :
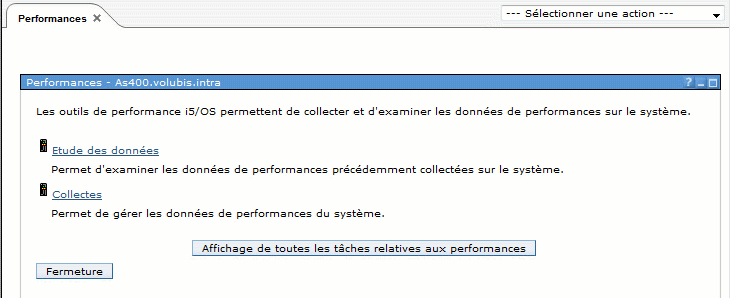
Il s'agit de collecter des données de performances afin d'offrir une vision d'ensemble de l'état de la machine.
cela était possible avant grâce aux commandes STRPFRMON/ENDPFRMON qui disparaissent en V5 au profit de cette nouvelle notion de collecte.
Les collectes écrivent dans un seul objet : *MGTCOL (avant il y avait jusqu'à 30 fichiers différents)
Vous pouvez choisir d'écrire dans des fichiers en fin de traitement ou en temps réel.
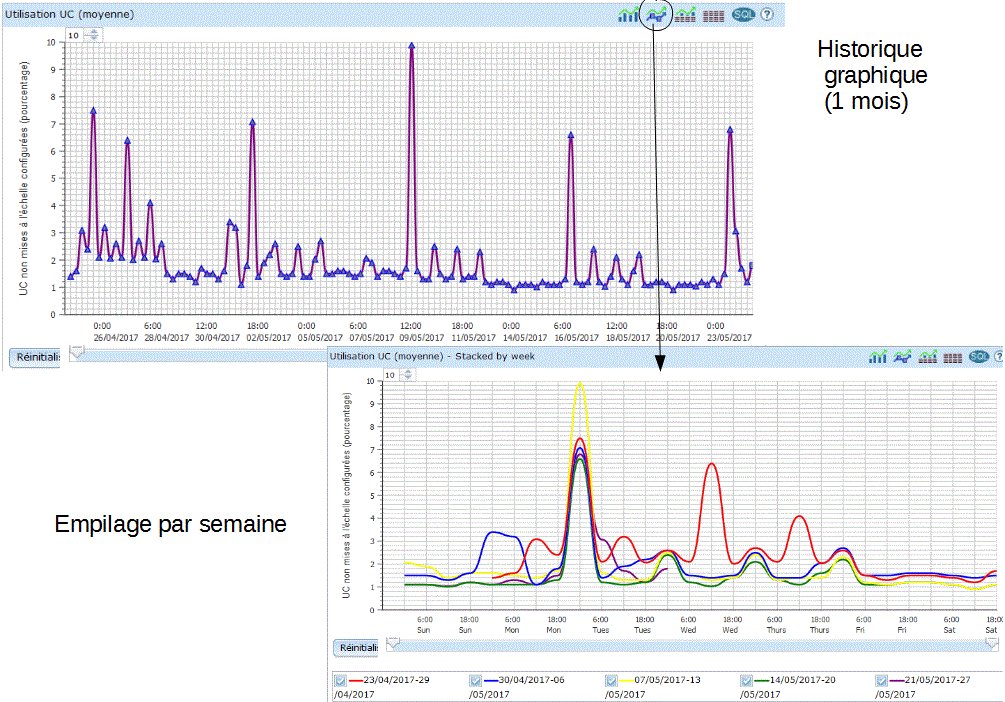
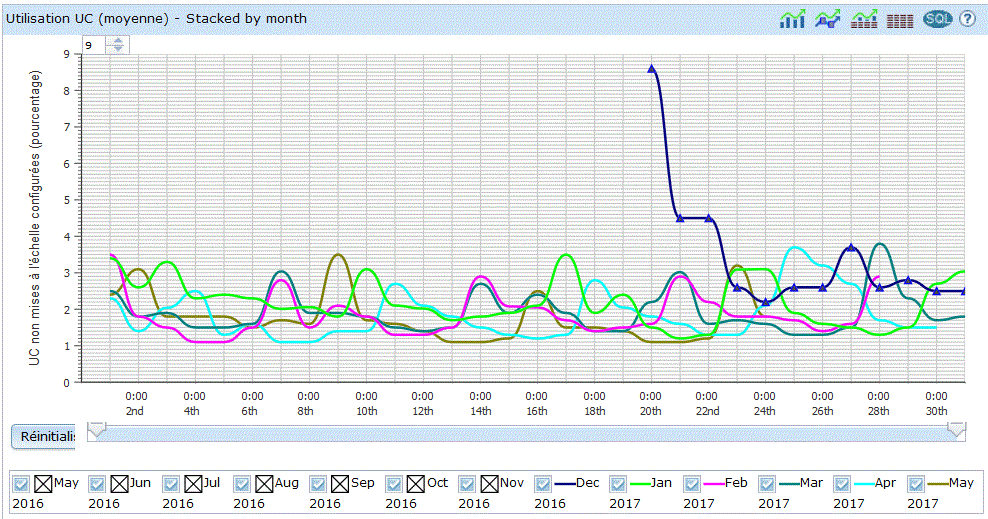
Les collectes sont plus précises, les points de collectes plus rapprochés (attention aux volumes !!! )
Pour lancer une collecte :
·Vous pouvez utiliser l'option 2 du menu PERFORM. Si une collecte est déjà active, on vous affiche l'écran suivant:
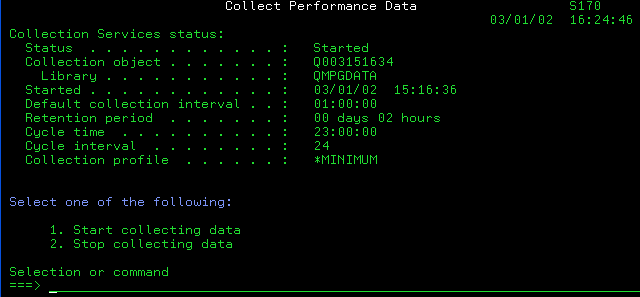
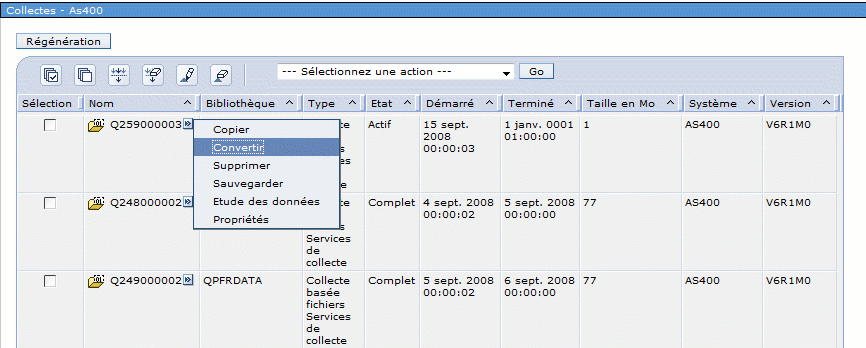
·Ou lancer les commandes STRPFRCOL / ENDPFRCOL
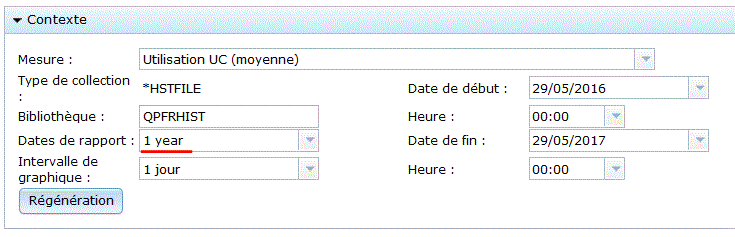
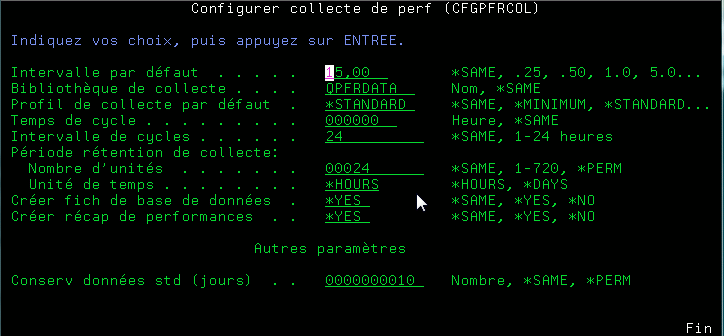
le paramétrage peux se faire grâce à CFGPFRCOL
les commandes suivantes sont fournies
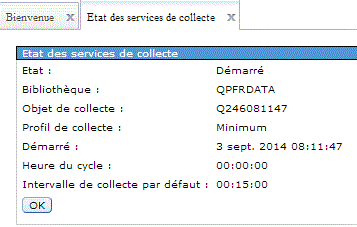
Il est important d'avoir des données récapitulative pour le bon fonctionnement de PDI
- CRTPFRSUM
- ou mieux CFGPFRCOL CRTPFRSUM(*YES) CRTDBF(*YES)
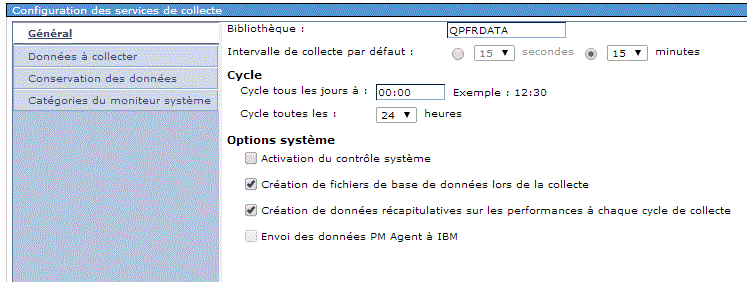
- ou cochez les cases suivantes :



 ->
-> 

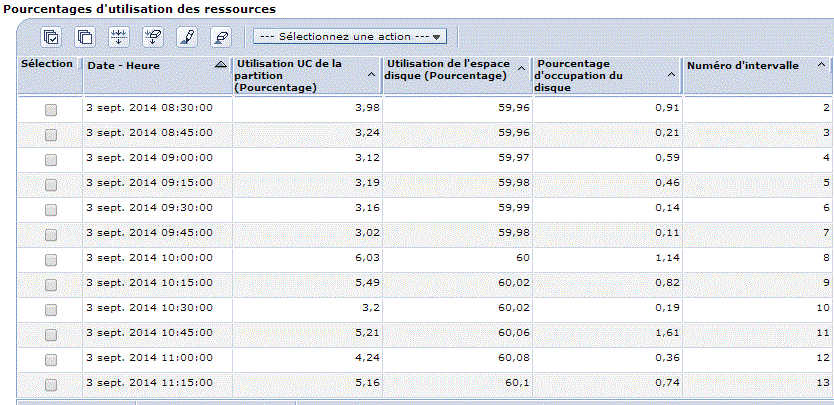

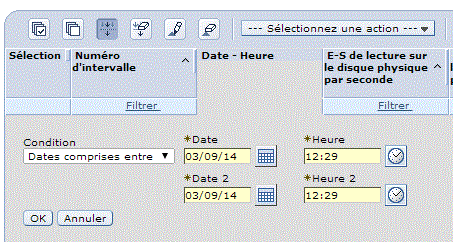
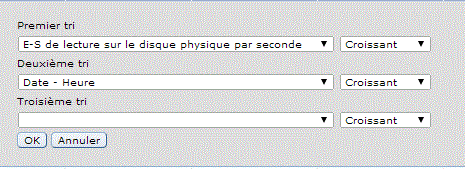
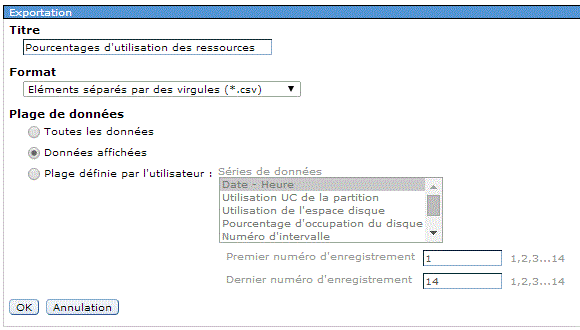
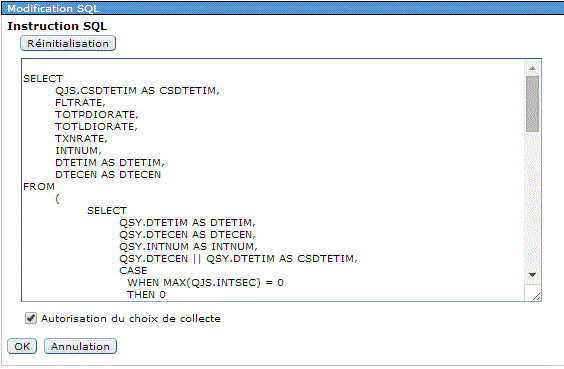
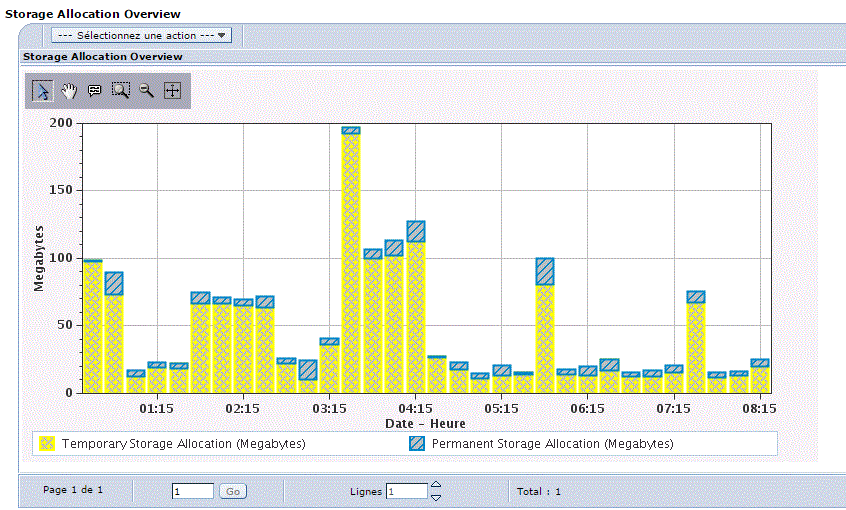
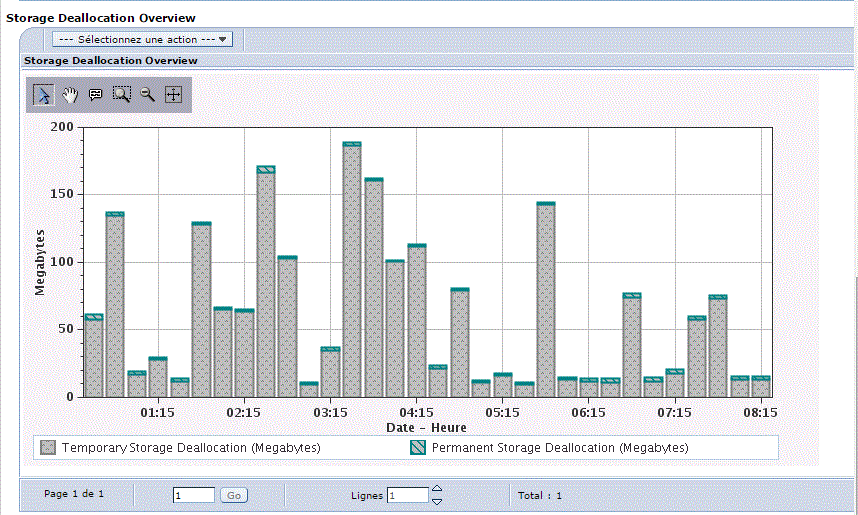
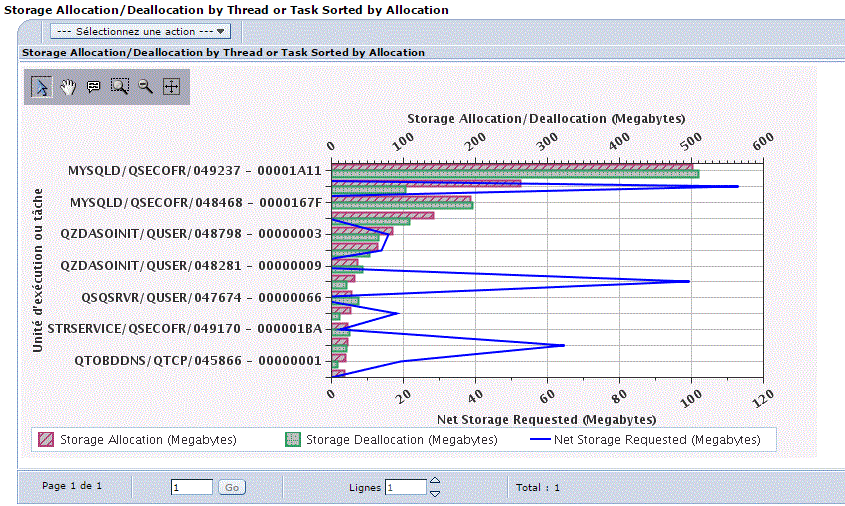
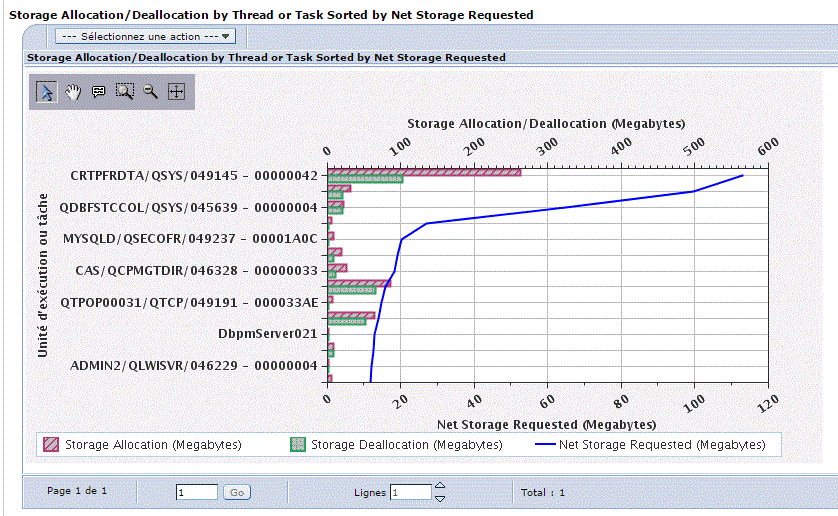
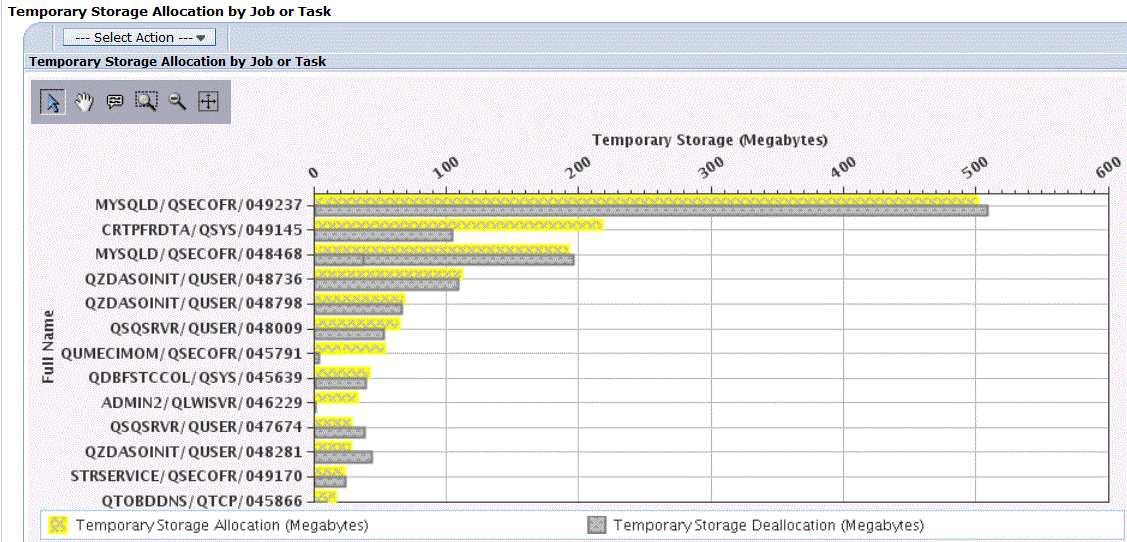


V7 : Vous pouvez aussi utiliser IBM Navigator pour accéder à la nouvelle perspective Base de données.
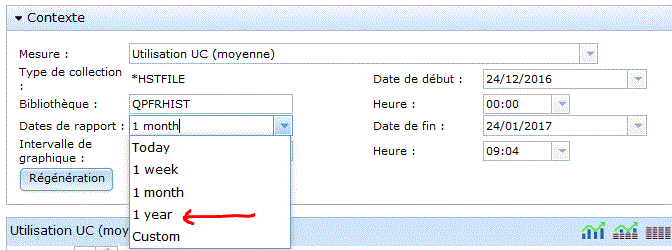
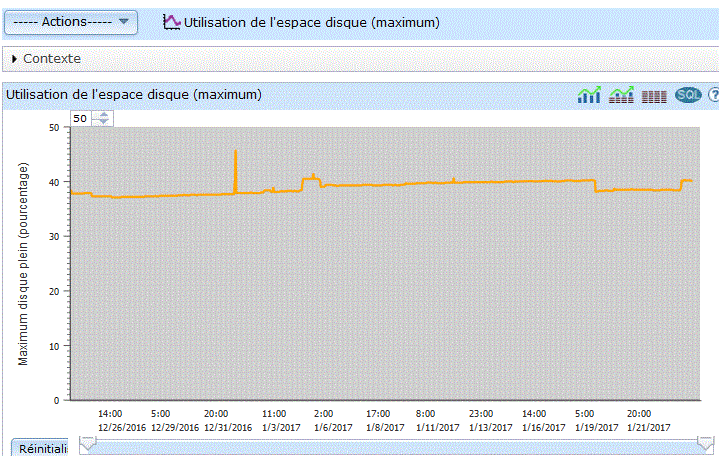
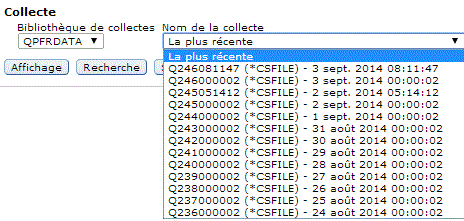
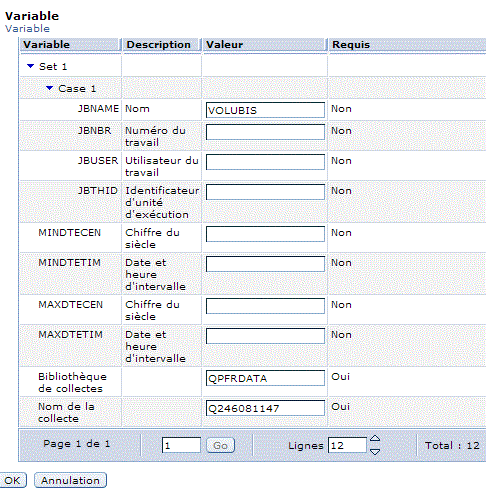
Choisissez la bibliothèque, pensez à indiquer celle du moniteur ou de l'image et non QPFRDATA puis le nom de l'objet (ou laissez "la plus récente")
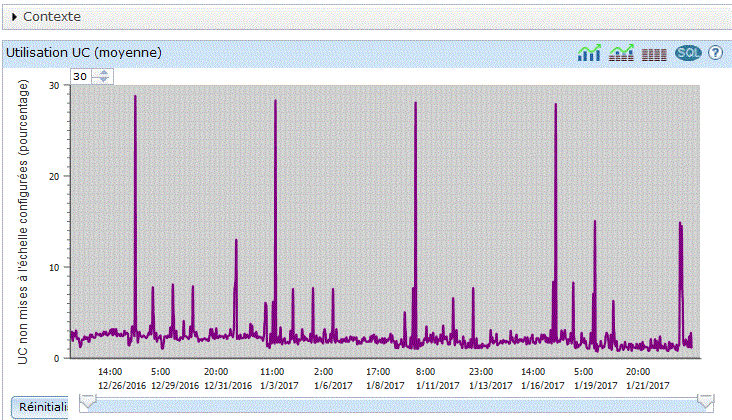
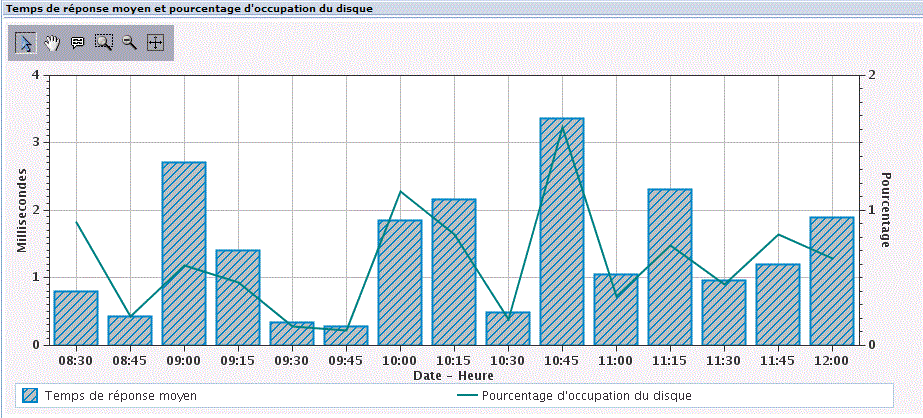
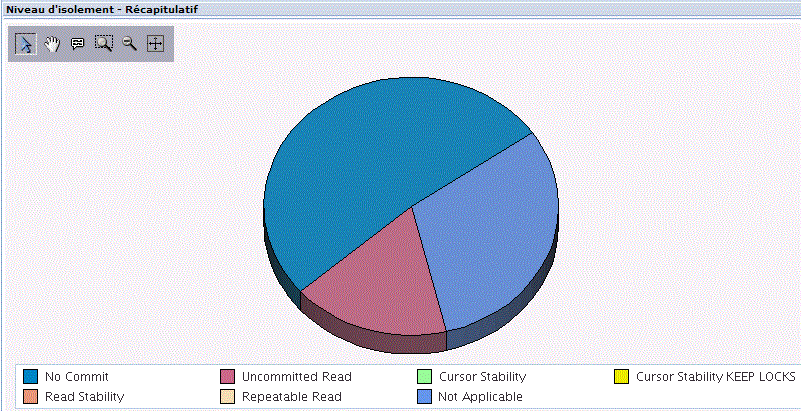
Nous avons (depuis SF99701, level 18) des statistiques d'Entrée/Sortie globales
Entrée/sortie base de donnée physiques, vue détaillée
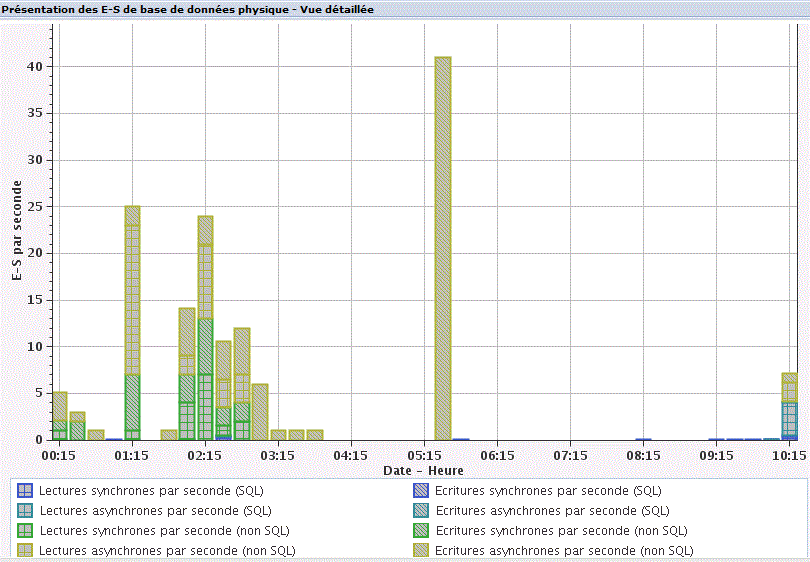
Par travail :
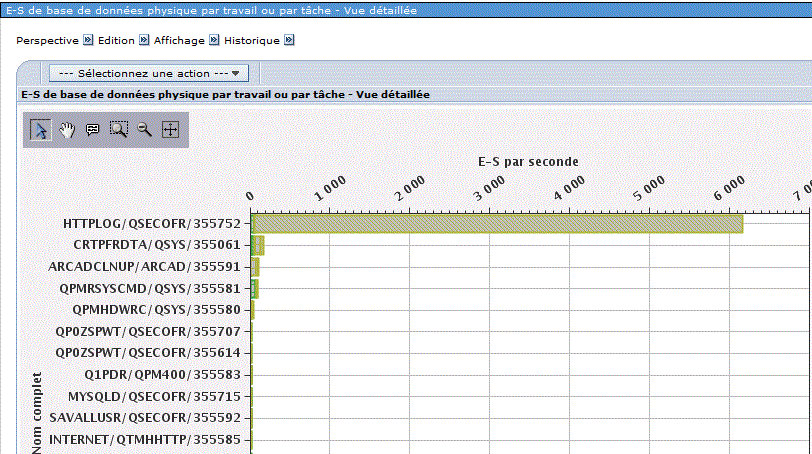
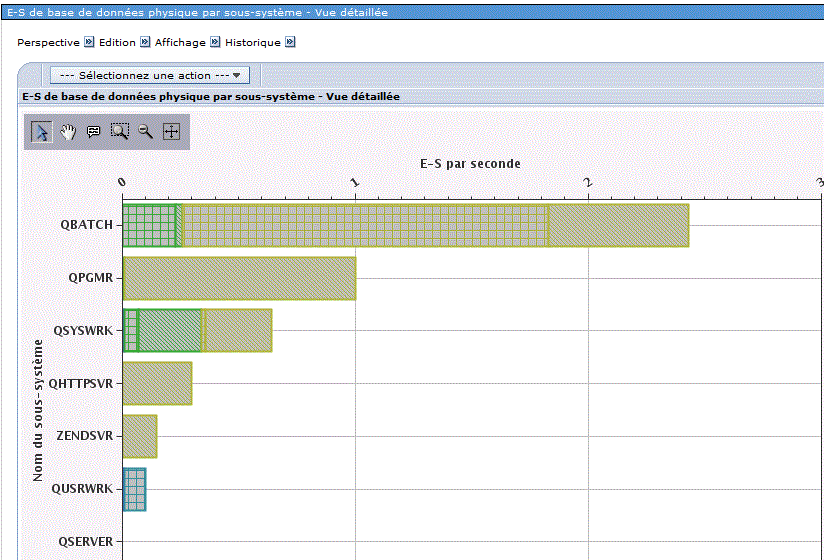
Par sous-système
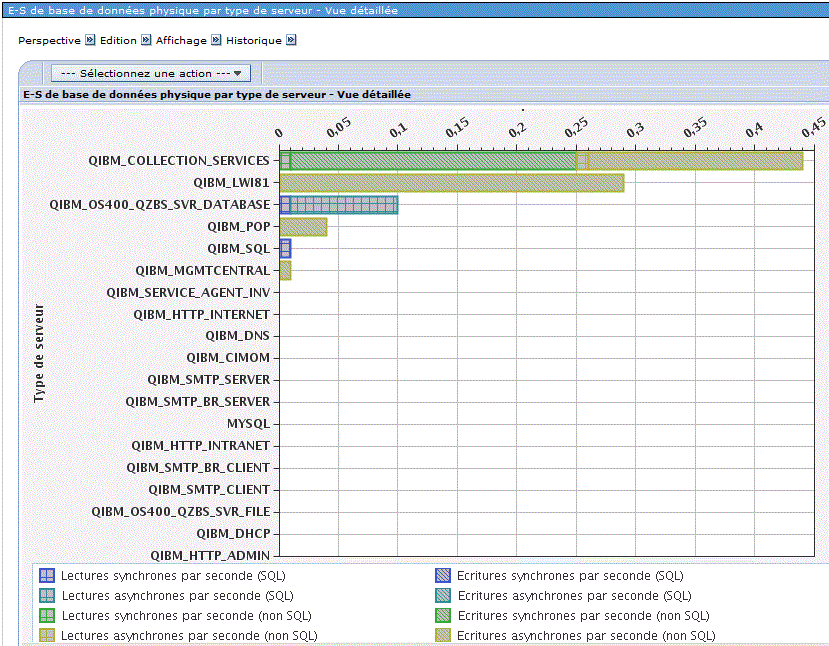
Par type de serveur
Ces options s'étoffent en 7.2 dans PDI :
permettant de gérer images du cache des plans SQL (option base de données)

et offrant à PDI, une meilleure vision des images du cache et des moniteurs de performances
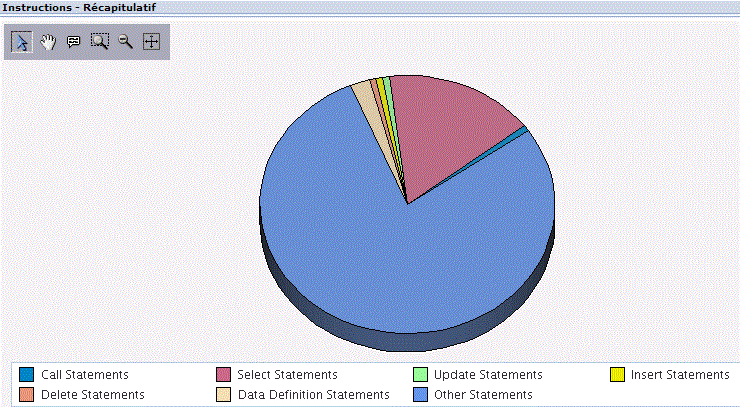
Présentation SQL, fournit des informations générales (récapitulatives)
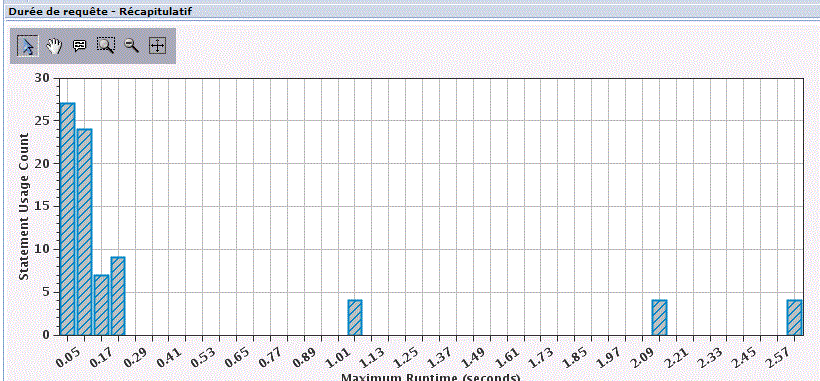
Ici sur un moniteur SQL
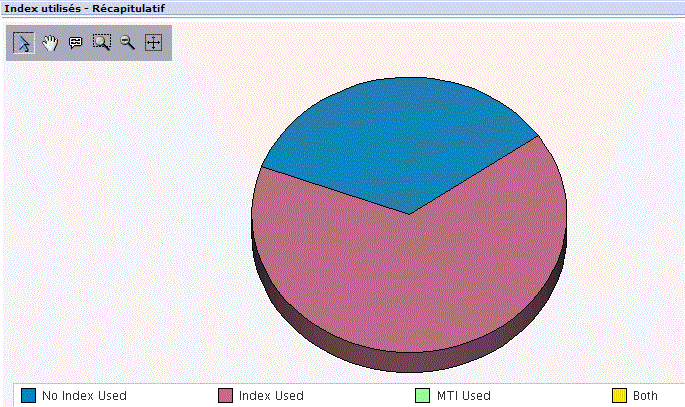
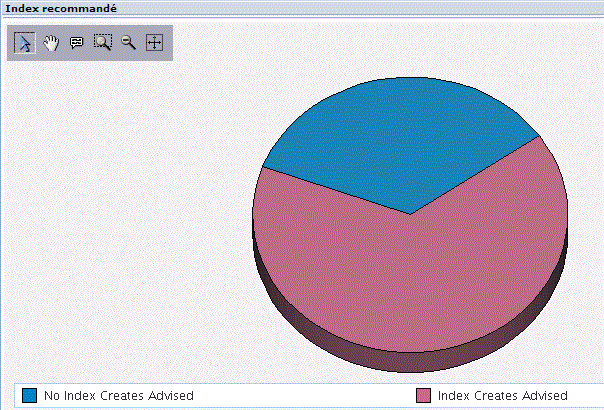
Combinaison d'attributs SQL, offrant une vision des attributs (propriétés) des différentes instructions SQL
Vous pouvez aussi accéder à des informations globales sur le système Power
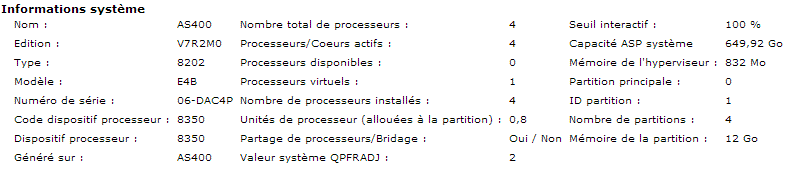
Sur l'option propriétés d'une partition
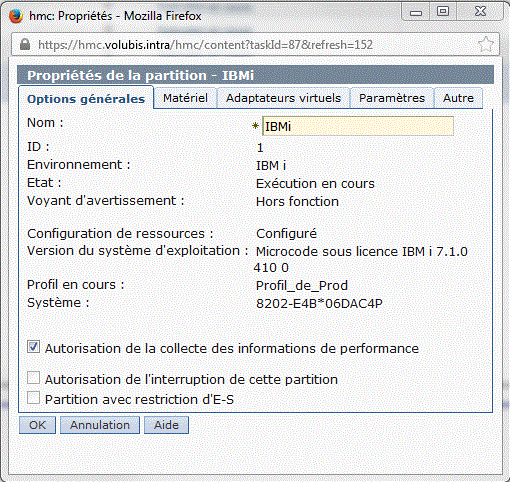
Cochez "Autorisation de la collecte des informations de performance", qui permet une analyse de l'activité matériel
à travers IBM Navigator for i.
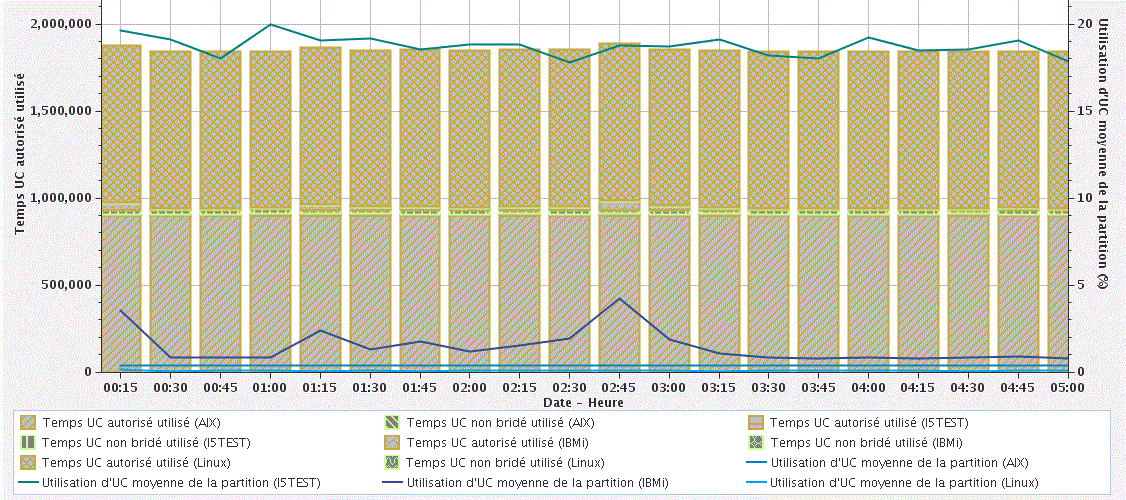
(Performances/Études de données/ Service de collecte/Système physique)

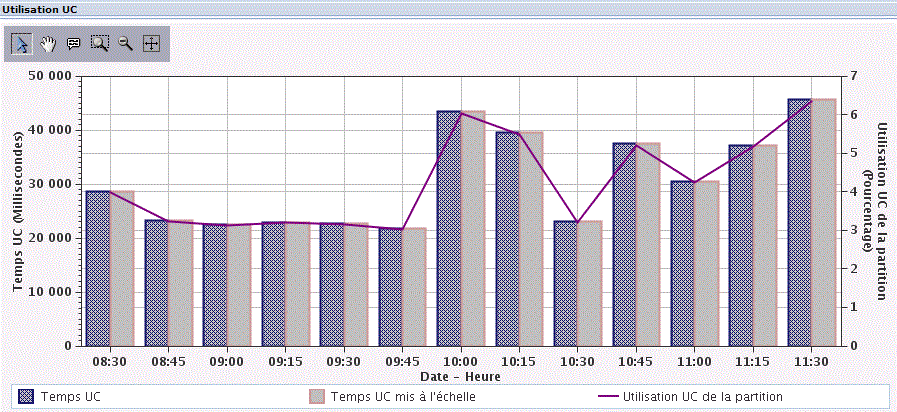
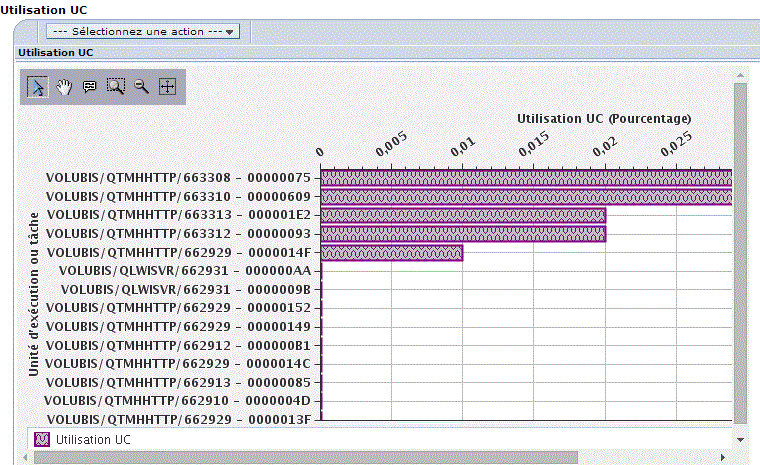
Ici, la consommation UC (bridé/non bridé) par LPAR
En 7.2, deux moniteurs, déjà présents dans Gestion centralisée de la version Windows, sont ajoutés :
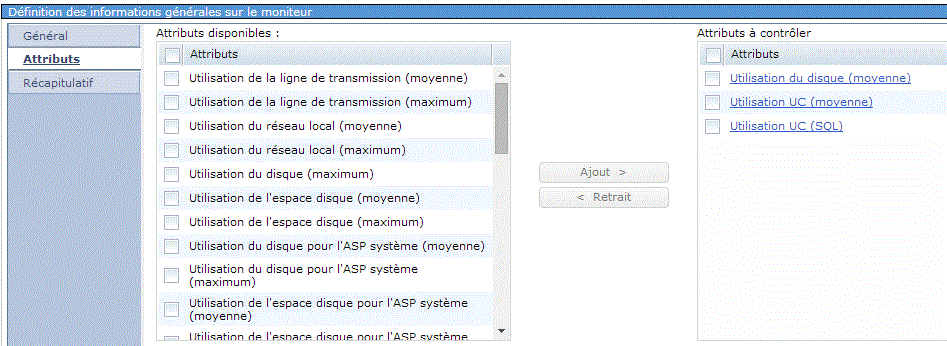
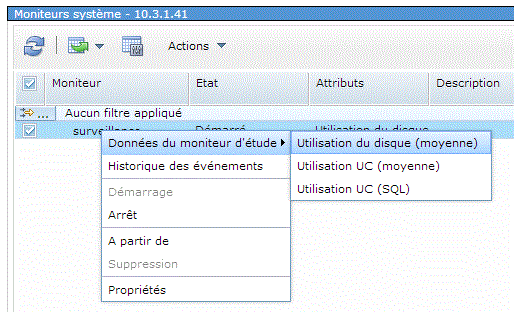
Moniteur système , permet de surveiller les performances
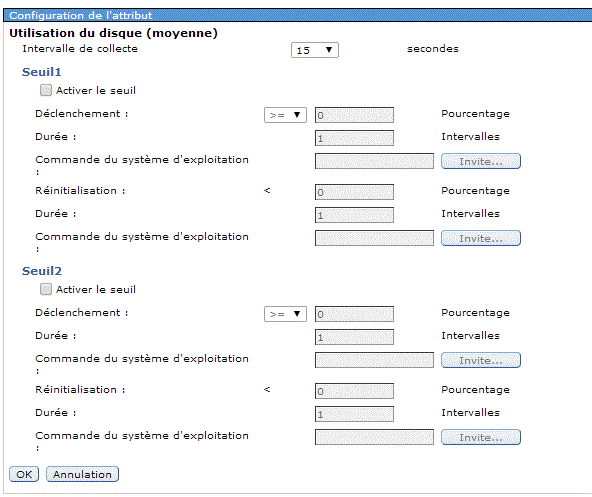
Le moniteur a été créé

On peut le visualiser dans PDI
Ou, plus simple, par un clic droit après avoir coché la ligne
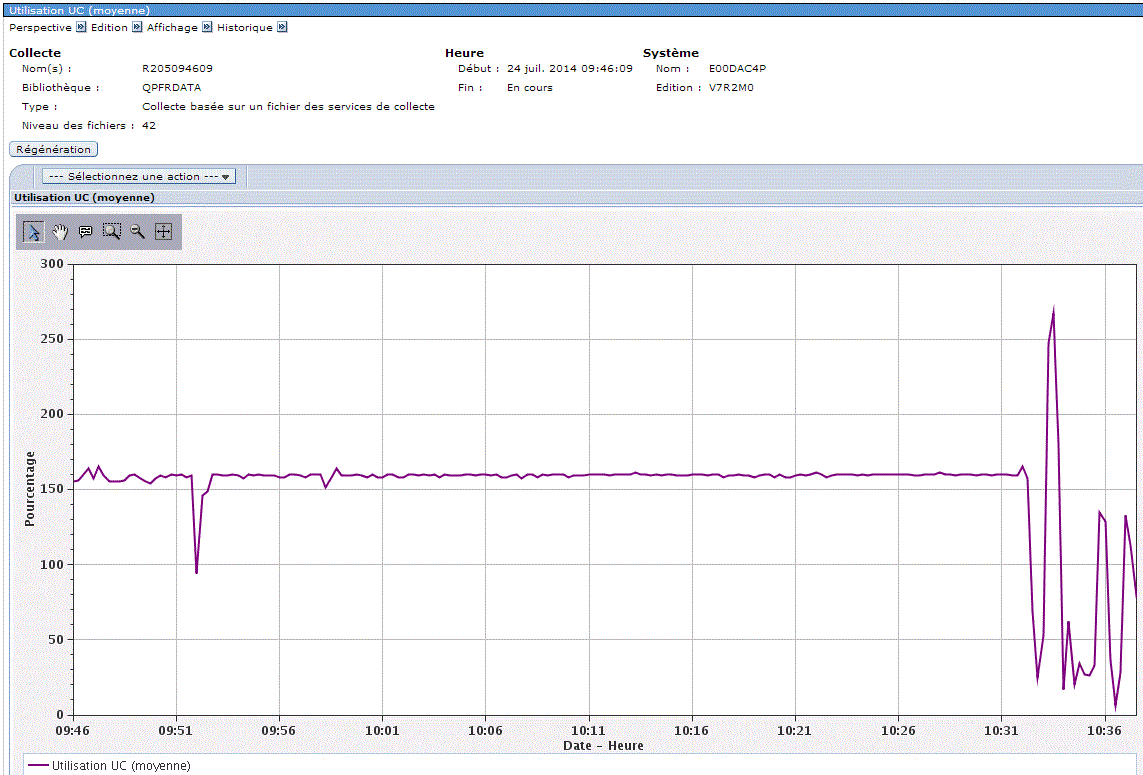
(cliquez pour agrandir)
Enfin cette nouvelle version 7.2 propose aussi un modélisation des données pour étude,
permettant de répondre aux questions :
ET si mon volume de données à traiter double ?
et si j'ajoute un processeur ?
et si j'ajoute deux disques, ai-je un véritable gain ?
Pour cela vous devez créer un modèle de traitement par lot (batch) , depuis une collecte :
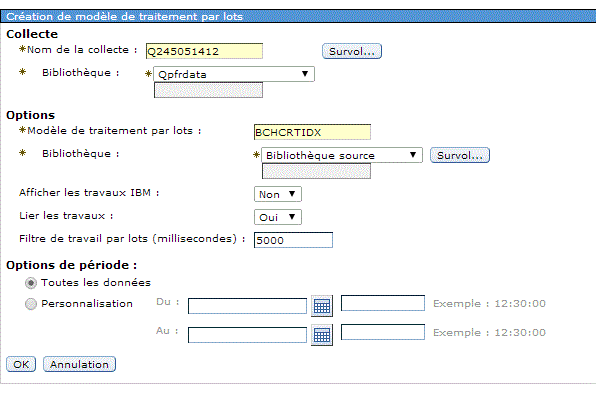
Vérifiez que les données correspondent à ce que vous voulez analyser
Regardez ensuite dans Modèle de traitement par lot, le détail des données collectées
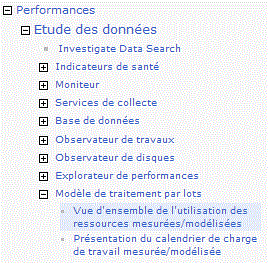
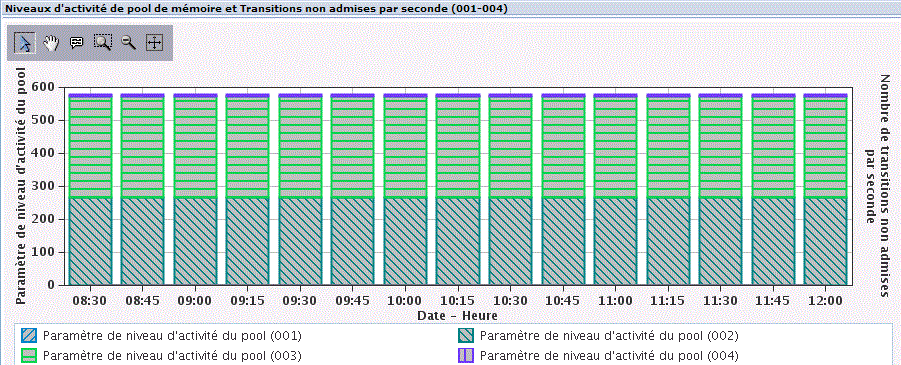
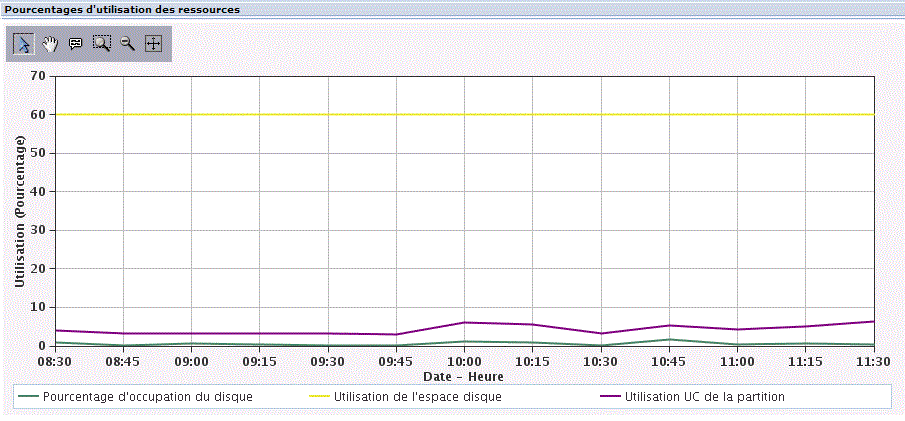
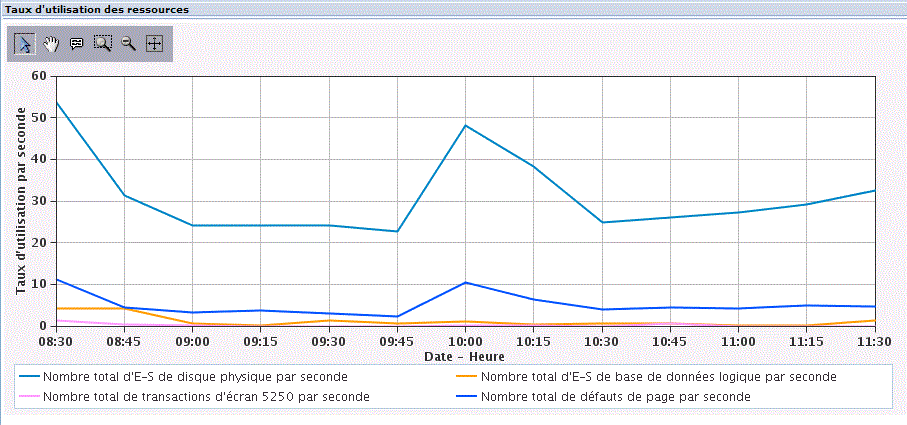
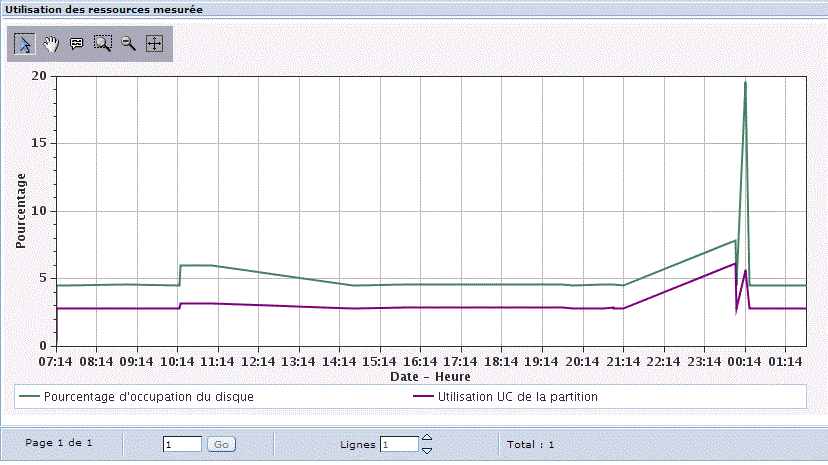
Utilisation des ressources mesurées, que vous allez modéliser
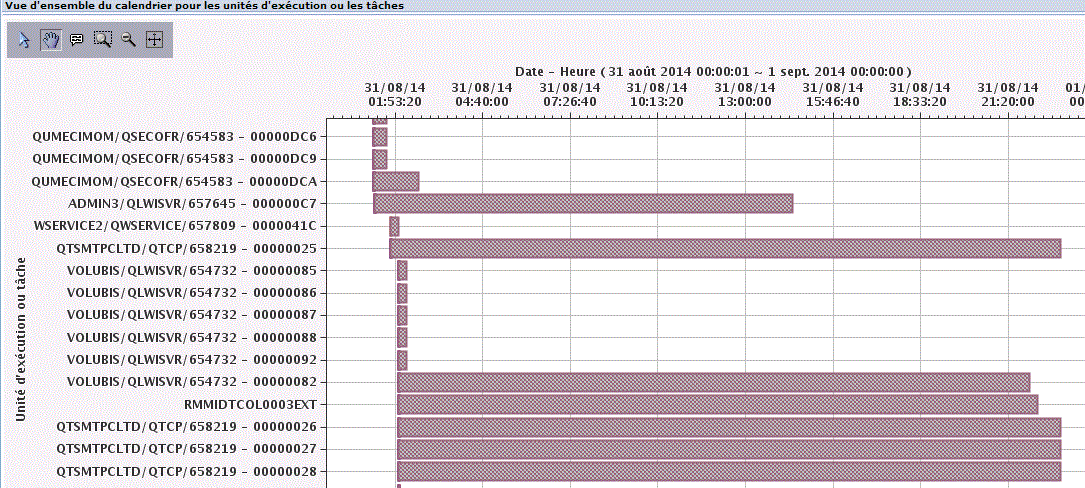
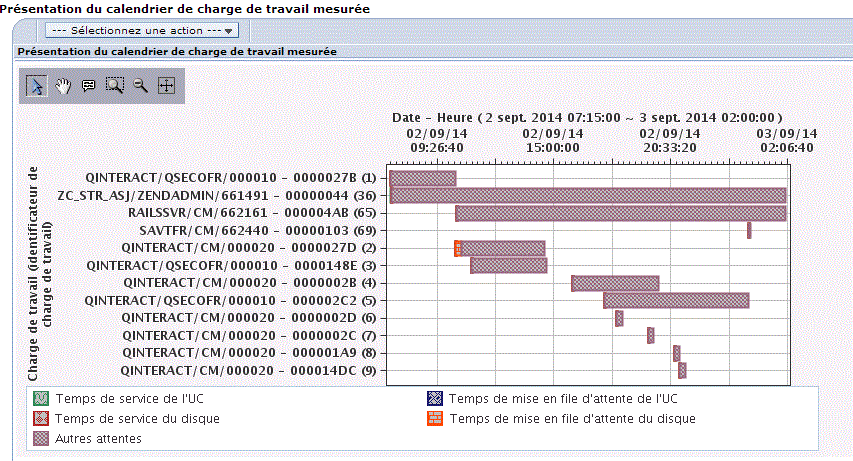
Et la répartition de la CPU dans le temps (calendrier de la charge mesurée)
Puis,
Utilisez l'option  qui permet de voir la liste des modèles
qui permet de voir la liste des modèles
et cliquez droit sur le modèle que vous venez de créer
Dans un premier temps vous devez calibrer ce modèle, soit :
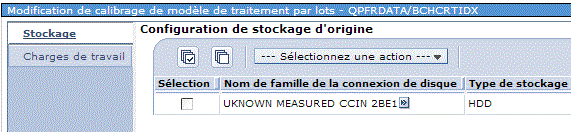
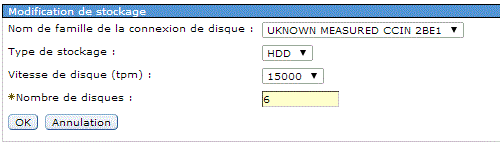
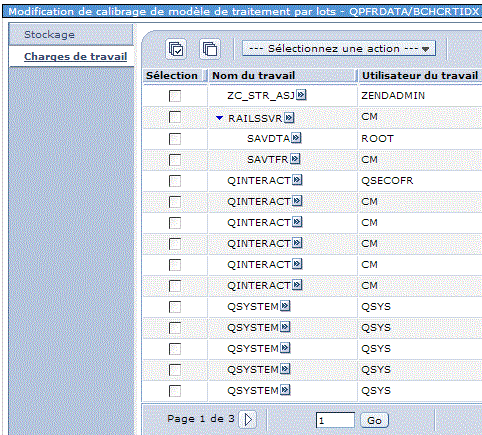
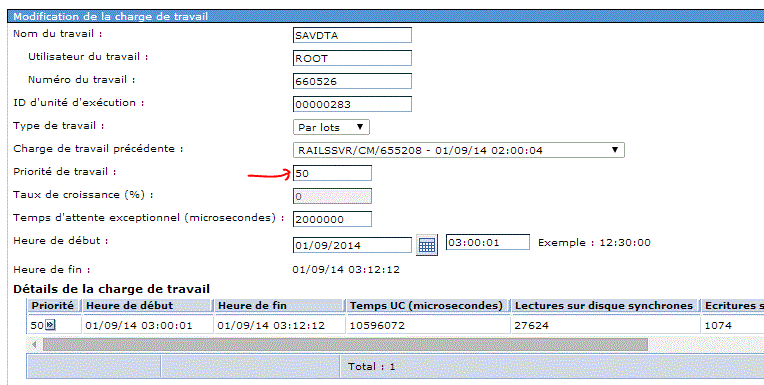
Attendez ensuite que l'état passe à Complet
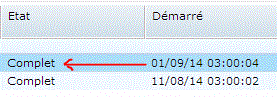
Vous pouvez alors
demander à Modifier le modèle
•taux de croissance prévu : (et si ma volumétrie double ?)

•processeur (et si j'en ajoute 1 ?)
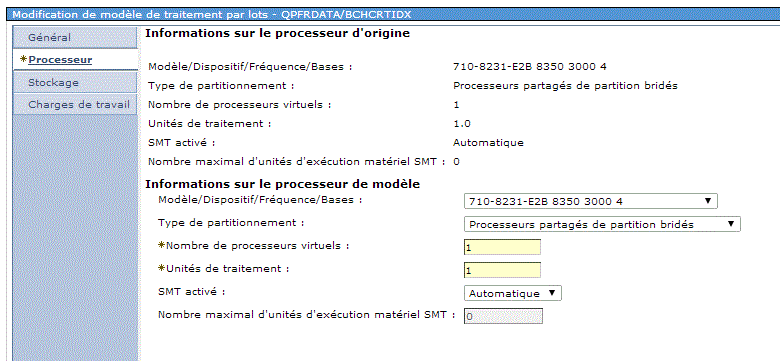
•disque (et si j'en achète deux ?)
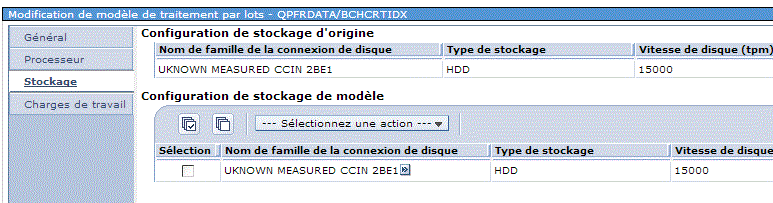
•charge de travail (et si je baisse la priorité des travaux concurrents ?)
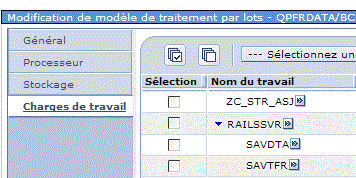
Confirmez

L'état passe à Analyse, puis repasse à Complet
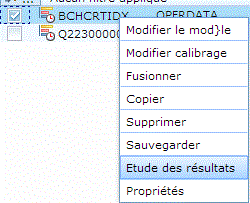
demandez l'étude des résultats :
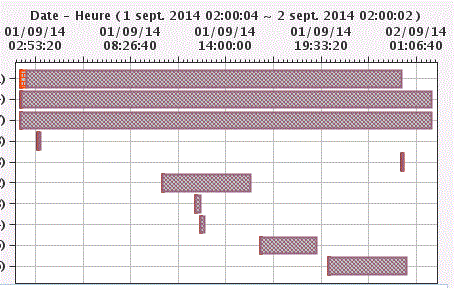
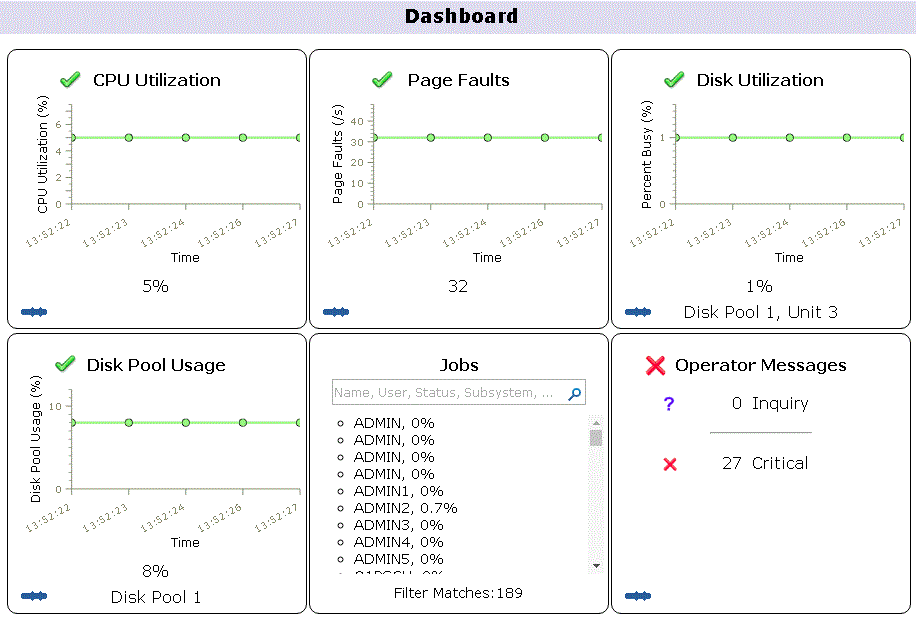
Enfin en version 7.3 , la page d'acceuil de Navigator for i affiche un tableau de bord contenant des informations de performances