L'optimiseur prend des décisions en fonction de la mémoire disponible, tout en essayant de laisser de la mémoire aux autres travaux (fair share)
CQE effectue un calcul simple : "taille du pool/ niveau d'activité" = mémoire maxi par job.
Si votre requête s'exécute seule dans un pool (ce
qui est
conseillé) , descendez le niveau d'activité
à 1.
»Pour travailler dans un Pool dédié :
» En même temps, utilisez l'expert
cache qui est toujours une bonne solution pour
les accès base de données, dans
des pools mémoire de plus de 100 Mo
(on garde en mémoire les tables les plus
utilisées).
SQE, lui
divise la taille du pool par le nombre moyen
de travaux
(expert cache obligatoire, pour faire la moyenne)
ATTENTION, Si vous faites des tests, le deuxième test ira toujours plus vite que le premier, du fait que les données sont (partiellement ?) restées en mémoire, ce qui peut fausser vos mesures.
Placez vous alors Obligatoirement
dans un pool ou vous êtes seul, et lancez entre deux
requêtes :
CLRPOOL POOL(*SHRPOOL1)
Ce paramètre est renseignable sur les commandes STRSQL , RUNSQLSTM
- *NO la copie des données n'est pas admises (pour des
besoins
de temps réel)
- *YES la copie des données est admises, elle n'a lieu que quand il est impossible de faire autrement
- *OPTIMIZE la copie des
données est admises, elle aura lieu
à chaque fois que cela améliorera les temps de
réponses
(particulièrement le hachage pour les jointures et les index
bitmap)
c'est cette dernière valeur qu'il faut
privilégier (elle
est par défaut via ODBC./JDBC).
Vous pouvez influencer l'optimiseur de requêtes en indiquant le nombre de lignes à traiter en même temps :
Si vous indiquez une petite valeur, l'optimiseur cherche à
rendre un résultat le plus rapide possible, vous le forcer
à utiliser des index, même si le temps global doit
en
pâtir.
C'est une solution interactive (STRSQL considère, sans
indication de votre part, une optimisation pour 3% des lignes du
fichier)
Si vous indiquez une GRANDE
valeur (FOR ALL ROWS est admis depuis
V4R30) l'optimiseur privilégie le temps global de
traitement.
Vous favoriserez les copies temporaires, les tris, le hachage s'ils
sont plus efficaces)
C'est une solution purement orientée batch et gros volumes.
(INSERT into …SELECT … FORM …, est
toujours traité pour un
nombre maxi de lignes)
D'abord un petit, "truc", mettez le paramètre QRYTIMLMT à 0 par la commande CHGQRYA :
toutes vos requêtes seront alors refusées (CPA4259) , l'optimiseur vous indiquant le temps qu'il a prévu.1/ En interactif, passez la commande STRDBG avant de lancer SQL en mode 5250 ,
vous verrez alors après chaque requête des messages CPI43xx ainsi que SQL79xx dans l'historique indiquant les choix de l'optimiseur lors de la création du plan d'accès
2/
pour un programme, vous pouvez voir le plan d'accès par la
commande PRTSQLINF
vous verrez alors, dans un
spool portant le nom du pgm, pour chaque requête des messages
SQL40xx
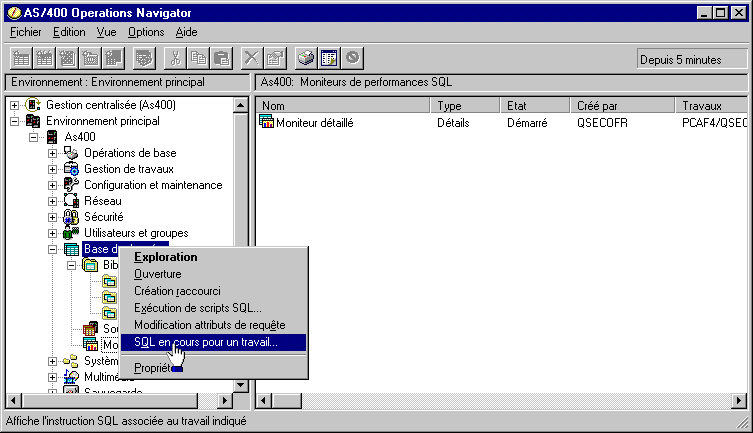
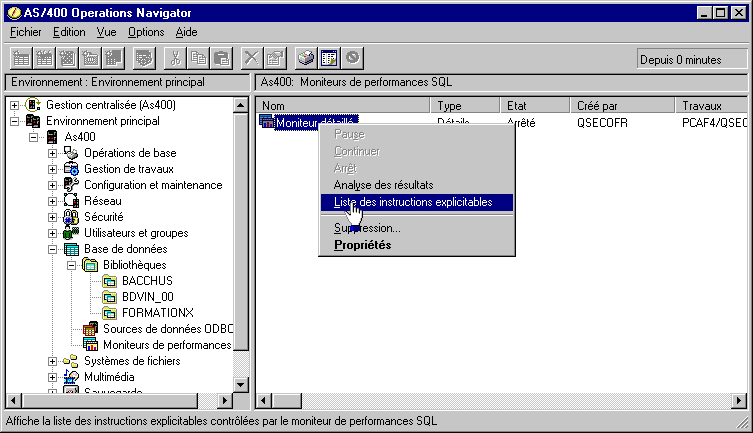
3/ Pour les Batch, utilisez le Moniteur base de données :
dans une session 5250, lancez la commande STRDBMON
ou, mieux,
via Operation navigator
:
choisissez "base de données"/"moniteur de performances SQL"
Les
outils graphiques
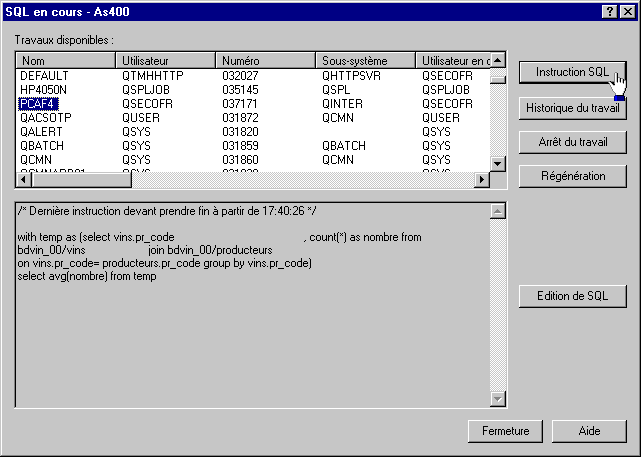
Vous pouvez :
sauvegarder
et relire un script SQL
lancer
tout ou partie du script
demander
l'inclusion des messages degug et voir l'historique du travail sur
l'AS/400
modifier vos attributs de requête. (fichier QAQQINI)
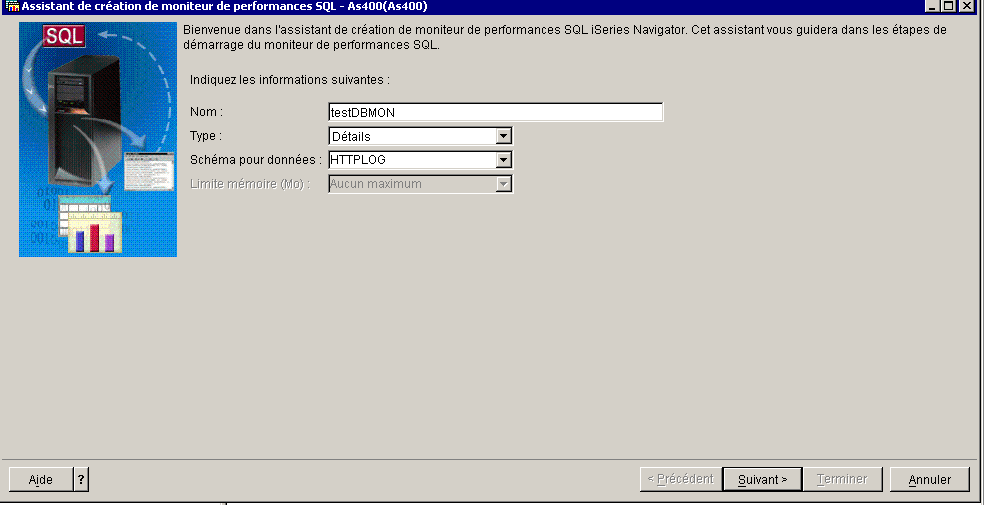
cliquez sur moniteur de Base de données / nouveau ...

remarquez :
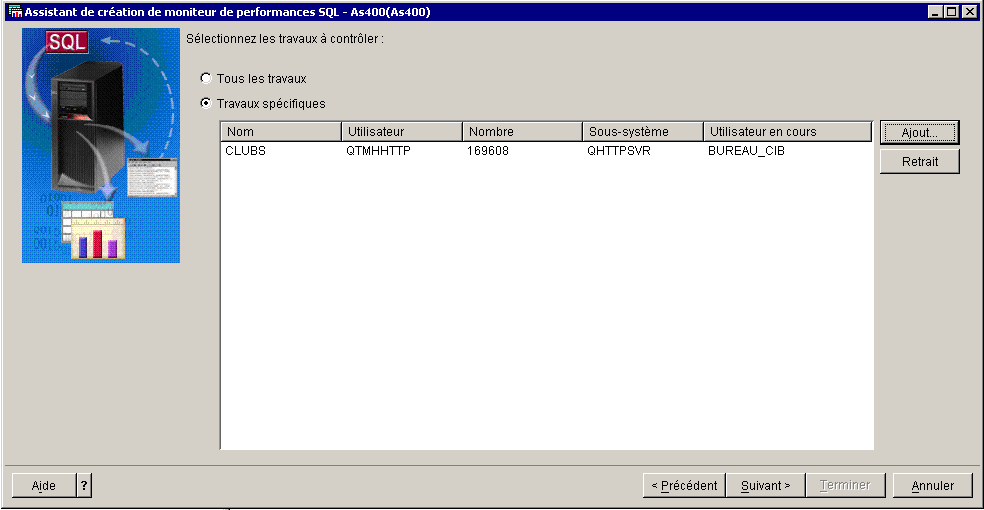
Choix des travaux (comme en V5R30)
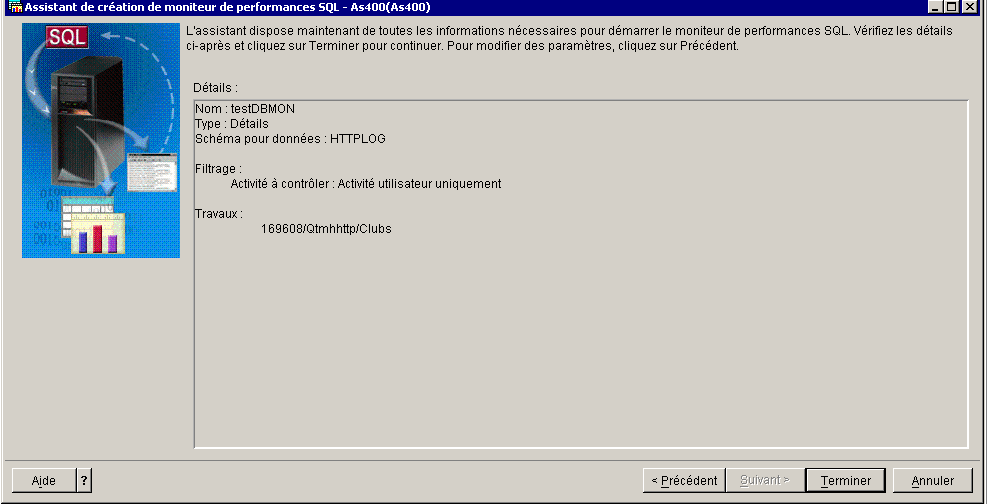
et récapitulatif final.
Quand la trace est terminée (l'arrêt est à votre charge), choisissez une vue (les données à afficher)
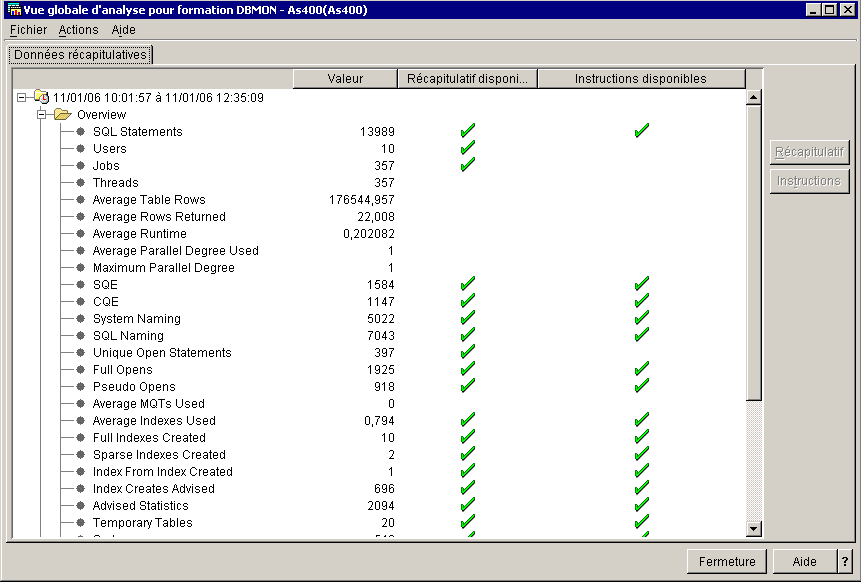
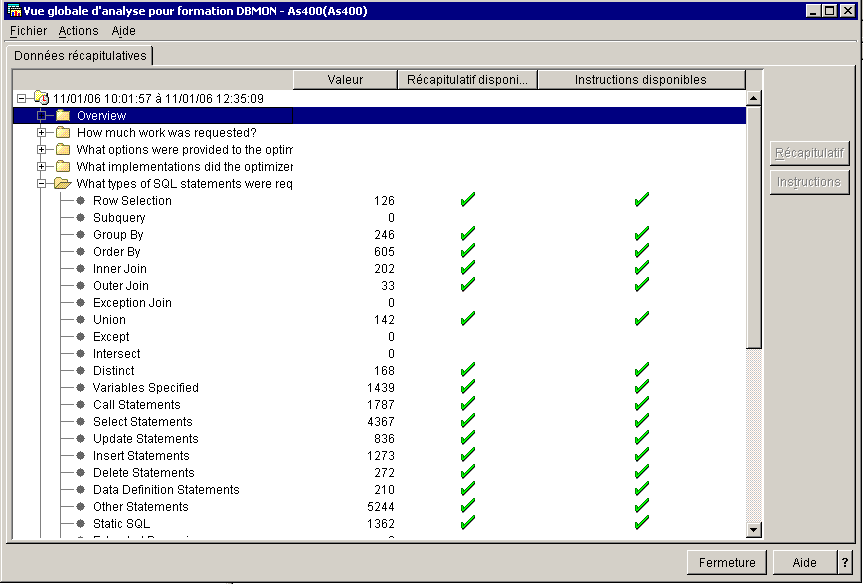
le menu Fichier/préférences, propose l'affichage des boutons de modification
de la requête
qui vous affichera (pour modification) la requête correspondant à la ligne
active
Vous pouvez modifier cet ordre ....... avec le gestionnaire de scripts :
IBM fournit des requêtes
d'exemple afin d'obtenir des statistiques globales à l'adresse http://www-03.ibm.com/servers/eserver/iseries/db2/dbmonqrys.htm
 , ci-dessous par
utilisateur :
, ci-dessous par
utilisateur :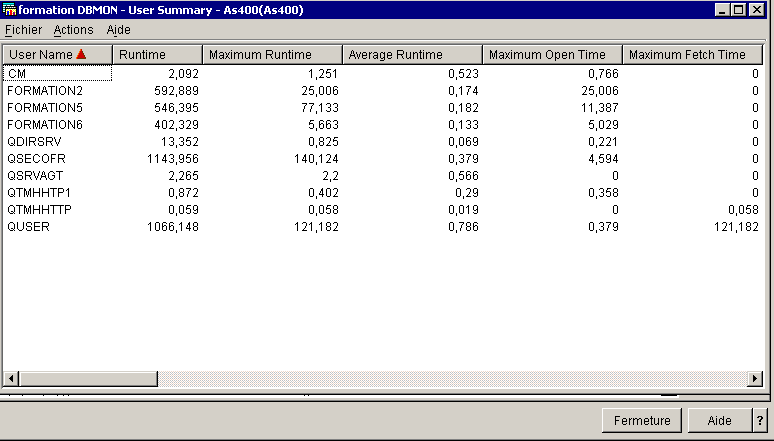
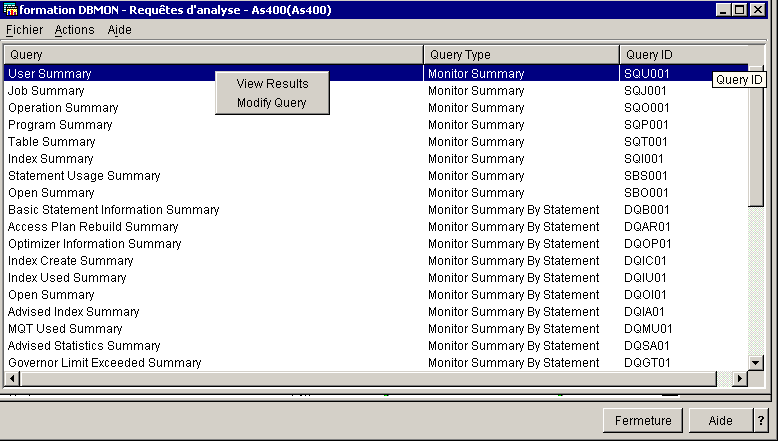
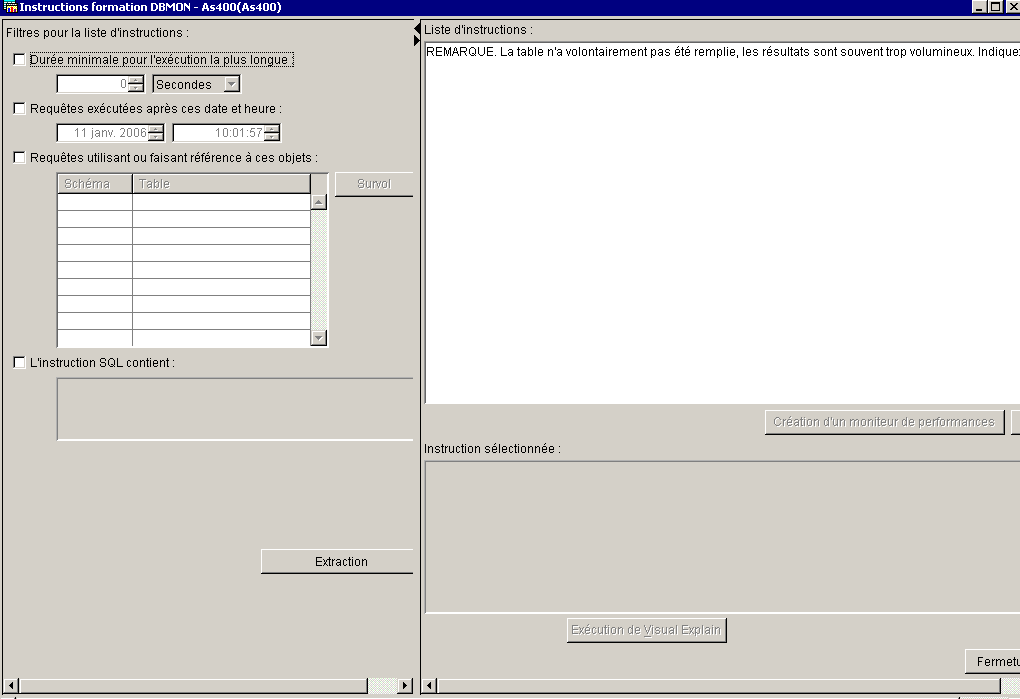
3/
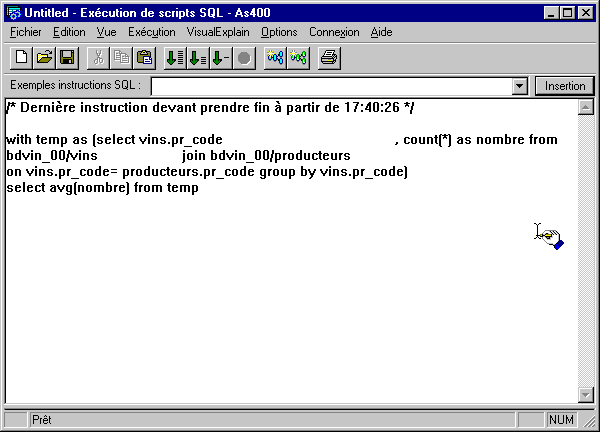
Visual Explain
Vous pouvez maintenant obtenir une Explication graphique du détail d'une requête SQL avec Visual Explain :
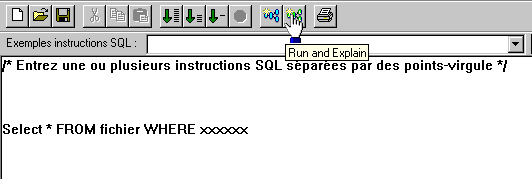
Le bouton EDITION SQL, place cette requête dans la fenêtre d'exécution de scripts SQL
| Le bouton que voici lance la requête avec QRYTIMLMT à 0 (la requête ne sera pas vraiment exécutée, mais l'optimiseur aura fait son travail) , ce qui permet une analyse basée sur une estimation | 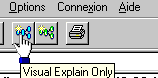 |
Visual
Explain vous affiche alors le détail des
différentes phases de la requête :
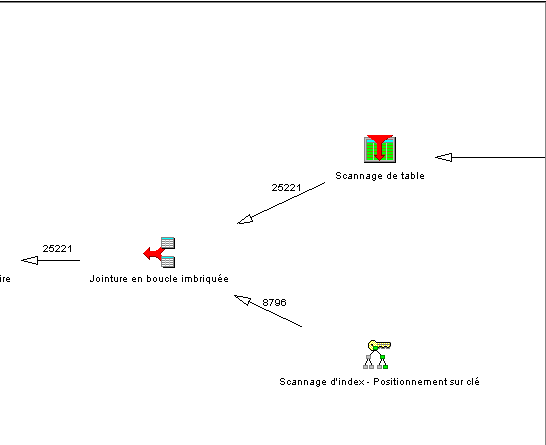
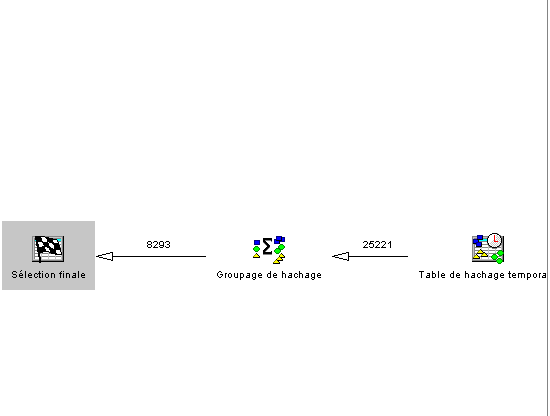
•Scanage de table et/ou utilisation d'un index
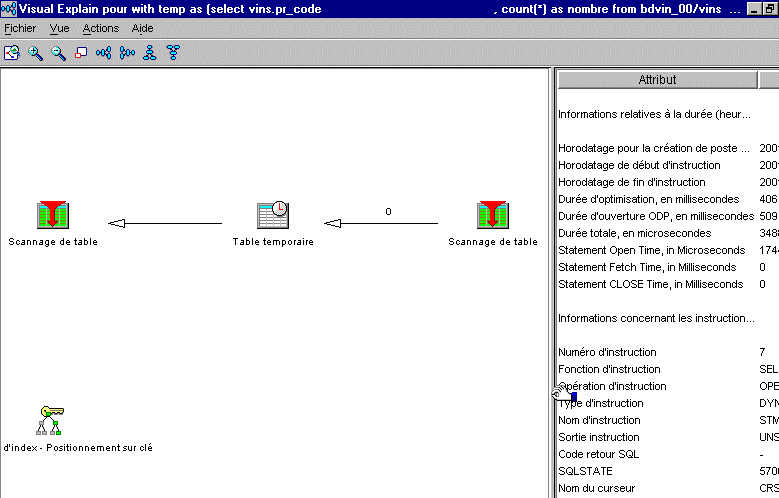
• phase de jointure
Vous pouvez aussi lancer Visual Explain sur le résultat détaillé d'un moniteur de performance base de données.
de nouvelles zones ont étés ajoutées
pour Visual
Explain
La V5R40 propose de commencer par établir
des critères de collecte :
remarquez :
Choix des travaux (comme en V5R30)
et récapitulatif final.
une fois le moniteur arrêté (ou importé):
En V5R30, on vous affiche toutes les instructions, en V5R40 vous pouvez au préalable, choisir vos critères d'affichage :
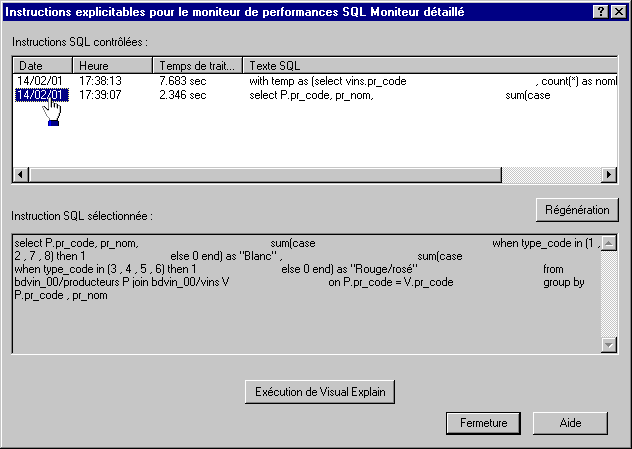
· les informations affichées par Visual Explain
Chaque icône représente
une action :
| Icône | STRDBG | PRTSQLINF | Commentaires |
 Table Scan |
CPI4329 | SQL4010 | Utilisé pour retourner un grand nombre de lignes |
 Table Probe |
Accès
direct à une ligne par son n° de rang (la connaissance du n° de rang peut venir d'une lecture d'index) |
||
 Index Scan |
CPI4328 | SQL4008 |
utilisé pour retourner un petit
nombre de lignes, si l'index correspond au critère de tri ET à une sélection,
par exemple. |
 Index Probe |
CPI4338 | SQL4032 |
utilisé pour retourner un petit
nombre de lignes, l'index permettant de réaliser la
sélection la plus importante (primary key, par exemple) |
 EVI Probe |
CPI4328 | SQL4008 SQL4011 |
utilisé éventuellement avec
d'autres pour créer un bitmap, entraîne ensuite un
accès direct sur la table (table
probe) |
 table
de hachage
table
de hachage  liste
triée
liste
triée  liste
simple
liste
simple liste
numérotée (basée sur les n° de
rang)
liste
numérotée (basée sur les n° de
rang) index
bitmap
index
bitmap index
temporaire
index
temporaire buffer
buffer| Icône | STRDBG | PRTSQLINF | Commentaires |
 Hash Scan |
CPI4329 | SQL4010 SQL4029 |
Utilisé principalement pour la gestion du GROUP
BY |
 HASH Probe |
CPI4327 | SQL4007 SQL4011 |
Utilisé principalement pour la jointure |
 Liste triée (Scan) |
CPI4328 CPI4325 |
SQL4008 SQL4002 |
Utilisé pour Order BY et l'option DISTINCT |
 Liste triée (Probe) |
CPI4327 | SQL4007 SQL4010 |
Utilisé pour une jointure avec un autre critère
que l'égalité |
 Liste simple (Scan) |
CPI4325 CPI4327 |
SQL4007 SQL4010 |
Utilisé pour préparer une utilisation
parallèle (SMP) |
 Liste numérotée (Scan) |
Utilisé avec des index multiples pour favoriser
ensuite le groupage des I/O disque. (récupération physique des
lignes par paquet) |
||
 Liste numérotée (Accès direct) |
CPI4338 | SQL4032 | technique bitmap pour combiner plusieurs index et limiter
ensuite l'accès direct aux lignes de la table |
 Bitmap Scan |
CPI4338 | SQL4010 SQL4032 |
technique pour combiner plusieurs index en un index bitmap. Un index bitmap est un nuage de point ou chaque position représente l'adresse, un liste numérotée contient les adresses (N° de rang) |
 Accès direct Bitmap |
CPI4338 | SQL4011 SQL4032 |
technique bitmap pour combiner plusieurs index et limiter
ensuite l'accès direct aux lignes de la table |
 Index Scan |
CPI4321 | SQL4009 |
création d'un index temporaire
pour tri ou groupage (de plus en plus rare) |
 Index Probe |
CPI4321 | SQL4009 |
création d'un index temporaire probablement pour jointure |
|
CPI4330 | SQL4030 | Objet temporaire utilisé lors des opérations de parallélisme (SMP) |
 vous
donnera des informations globales (temps,
nombre de lignes résultat , ...)
vous
donnera des informations globales (temps,
nombre de lignes résultat , ...)EVi table Scan, preload |
CPI4328 | SQL4008 |
utiliser pour retrouver les entrées à partir uniquement de la table des symboles d'un index EVI |
 QUEUE/DEQUEUE |
(pas de message) | (pas de message) | QUEUE, Objet temporaire pour mémoriser des données durant une requête récursive |
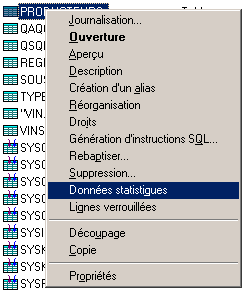
· Collectes de statistiques (depuis la V5R20)
Pour définir ou voir les statistiques, utilisez
le clic droit sur une table

Le bouton nouveau, permet de
définir une nouvelle collecte
Une message vous est
affiché (la première fois au
moins)

puis
:
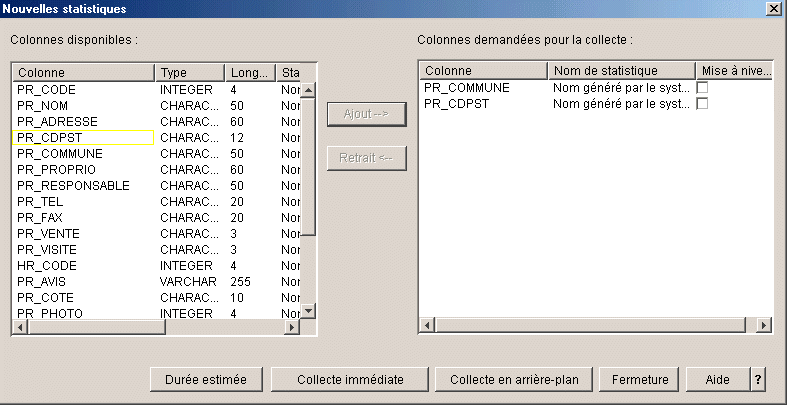
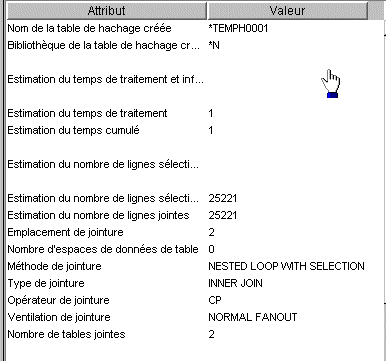
si vous demandez la durée estimée, on vous
affiche (ici sur une table de 500.000 lignes)
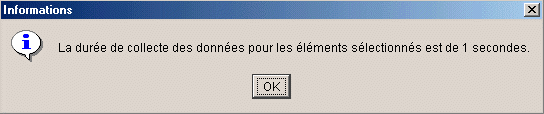
puis
cliquez sur
Collecte immédiate, les statistiques sont collectées immédiatement (vous attendez)
On vous rappelle alors vos
choix concernant la valeur système
QDBFSTCCOL

et
les collectes sont soumises.
Pour voir les collectes en
attente, cliquez droit sur l'option
Base de données
la fenêtre permettant de créer une nouvelle collecte, donne aussi un accès aux informations concernant une collecte existante :
Informations
générales
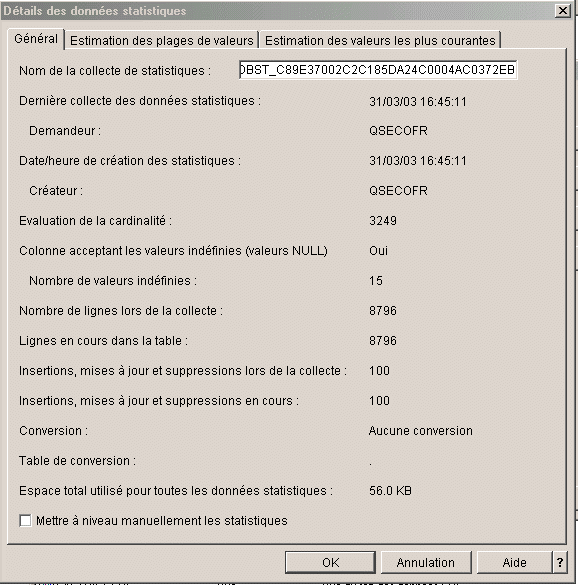
Plages de valeurs (ou
tranches)
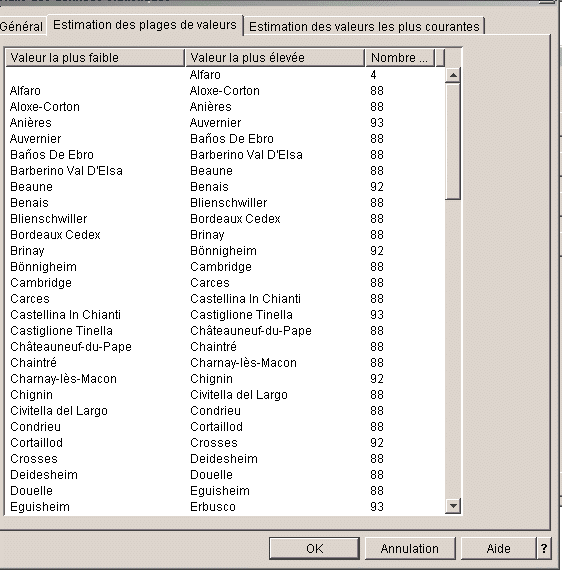
Valeurs les plus
utilisées
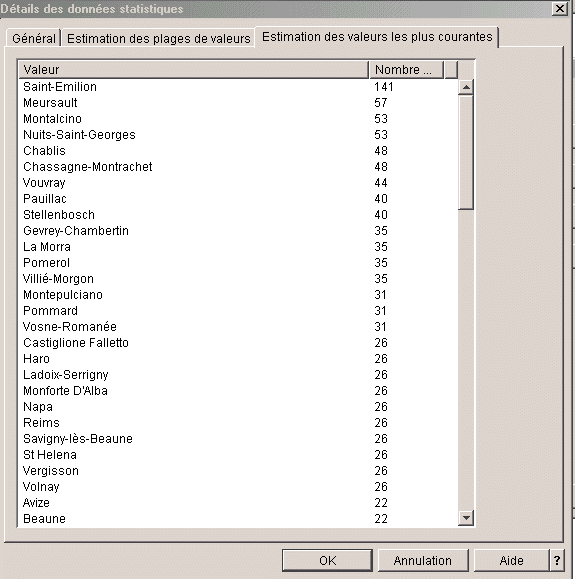
Visual Explain sait pleinement tirer profit de ces nouveautés :
Tout d'abord nous pouvons maintenant afficher l'historique du travail (contenant les messages DEBUG)
 ,
ce qui s'affiche en bas
,
ce qui s'affiche en bas
le Menu Option propose
Un
accès direct à la
gestion des statistiques
Un
outils de conseil,
suggérant certaines collectes
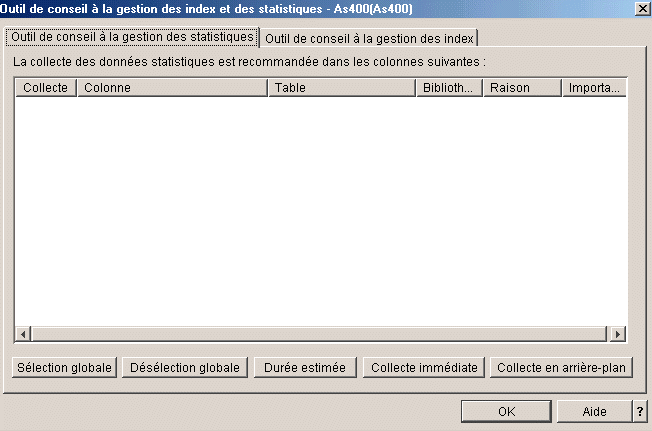
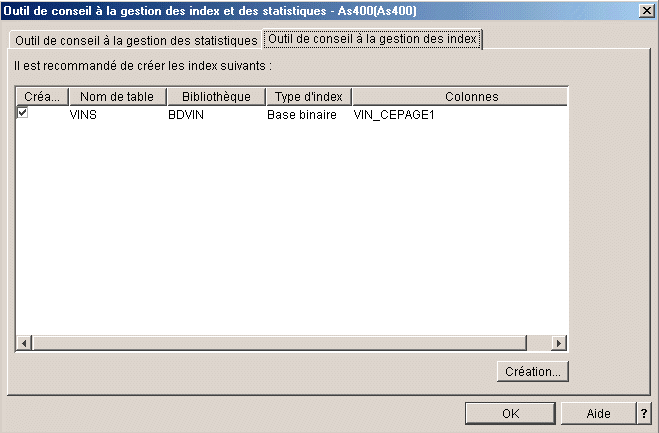
ou
la création d'index
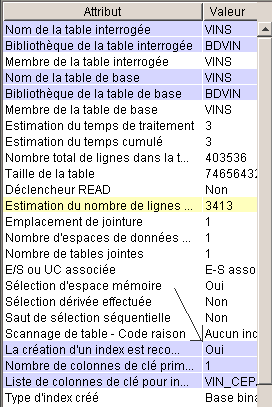
Le menu VUE, peut mettre en évidence
les
index recommandés

ce qui s'affiche :
les étapes
les plus coûteuses en nombre de
lignes
Ce qui s'affiche :
![]()
Visual Explain et tables matérialisées
|
·
Statistiques d'utilisation des
index (V5R30, plus correctifs)
iSeries Navigator, montre les
index liés à une table
(clic droit sur la table)
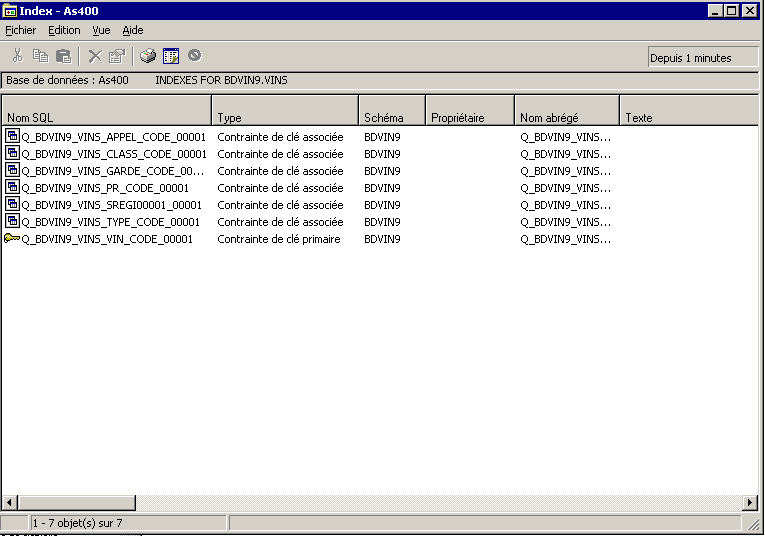
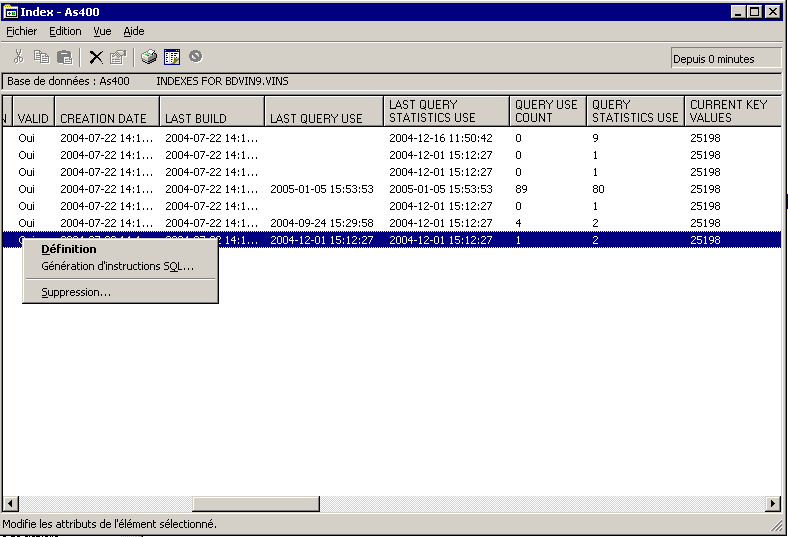
Cette dernière option vous affiche des informations nouvelles
en V5R30 concernant l'utilisation
des index
En effet, la date de dernière utilisation de l'objet fichier
logique, n'est pas significative dans le cas d'une requête
SQL,
où c'est l'optimiseur qui décide de l'utilisation
ou non
de l'index (utilisation non explicite).
Les PTF suivantes : SI12938, SI15255, SI13432, SI13245 ET SI16620
(en France) apportent 4 nouvelles colonnes
la version 5.40 nous amène une
consultation du cache des plans d'accès SQL
(ce concept date de la V5R20, mais n'était pas consultable,
c'est lui aujourd'hui qui suggère les index)
Un plan d'accès est le " plan, de bataille "
du moteur SQL face une requête :
"comment faire pour réaliser une requête mieux
?" , pendant cette phase le système examine les index
disponibles et en tire des conclusions.
ces "conclusions" sont mise en cache par SQE (depuis la version
5.20)
Attention, le cache des plans d'accès n'est fait que
par SQE, vous ne verrez donc pas de suggestion concernant les
requêtes encore effectuées par CQE
(ancien moteur utilisé par Query ou OPNQRYF, par exemple)
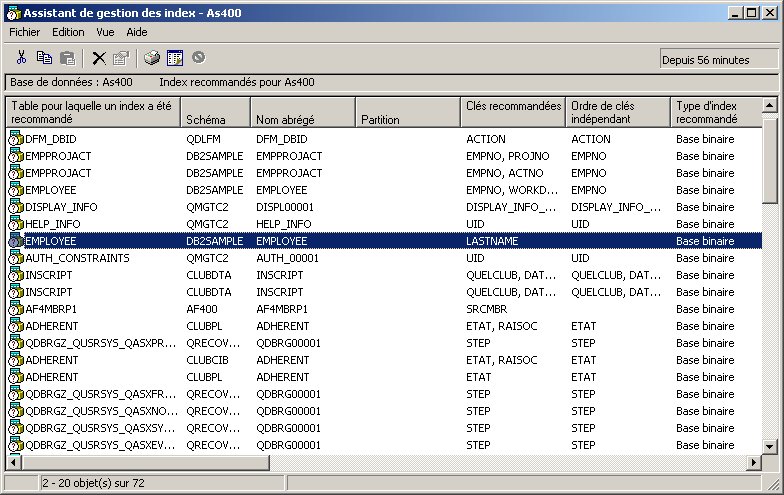
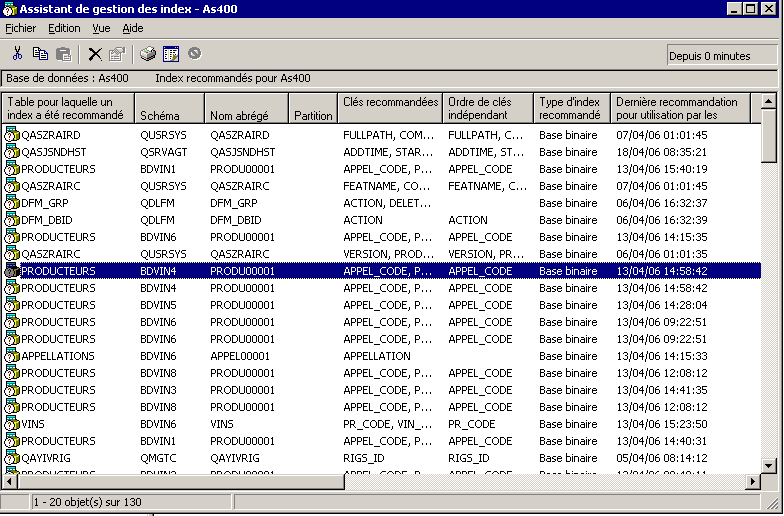
Avec la V5R40, au passage le système note les index qui
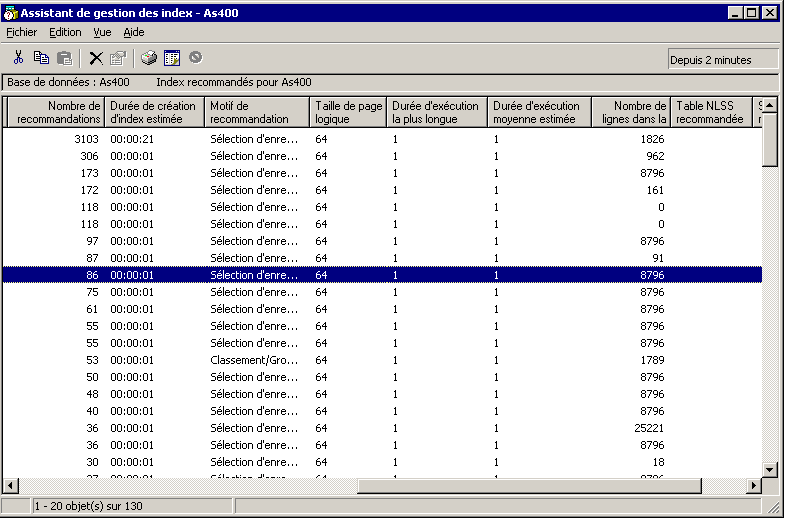
lui paraissent manquant dans QSYS2/SYSIXADV.
Le contenu de ce fichier est affiché par cette option
"Assistant de gestion des index"
d'iSeries Navigator
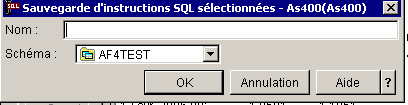
Le jeu d'instructions actuellement en cache pouvant être
sauvegardé sous forme d'image.
(sinon, il y a mise à
blanc à l'IPL)
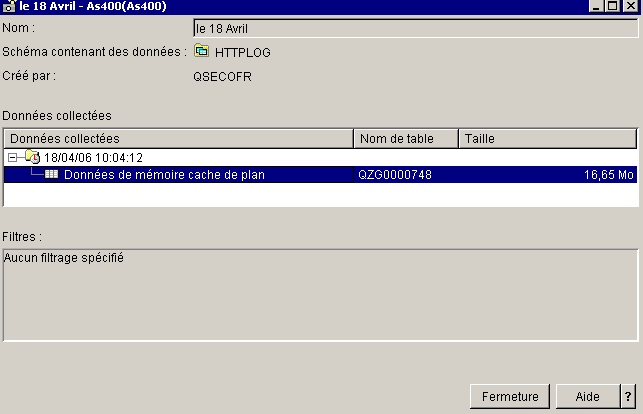
•Par iSeries Navigator, en cliquant, lors de l'affichage sur "création d'une image instantanée"
•Par appel à la procédure cataloguée QSYS2/DUMP_PLAN_CACHE(bibliothèque, nom_de_sauvegarde)
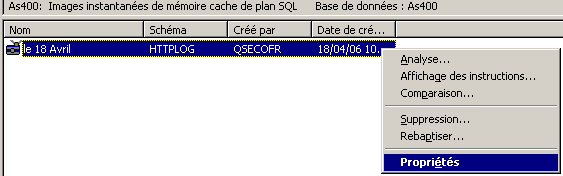
dans ce dernier cas, il faut importer ce cache pour le voir apparaître dans iSeries navigator :
pour cela, faites un clic droit sur "images instantanées de mémoire cache de plan SQL"
Cette sauvegarde peut ensuite, être réutilisé pour
une comparaison :
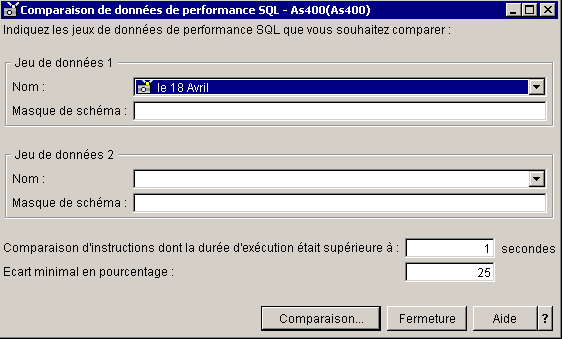
il n'est pas possible de comparer un jeu d'instructions venant
du cache et un moniteur
(ils n'ont pas le même type, voyez ci-dessous)
Enfin, depuis l'été 2006 avec la V5R40 et la
SI24893 du coté client et la SF99540 (Groupe database,)
niveau 4, le système créé lui même
sous forme d'index temporaires,
les index qu'il juge nécessaires . (fonction MTI
soit Maintained Temporary Indexes),
ces index disparaissent à l'IPL.
vous pourrez le constater en demandant l'assistant de gestion d'index (sur la machine ou sur un nom de schéma).
la nouveauté se trouve tout à droite de cette fenêtre
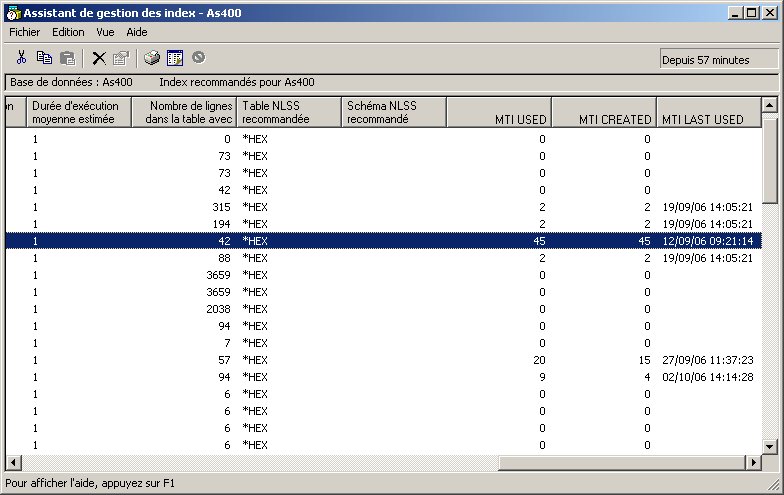
voici donc, maintenant la structure de la table SYSIXADV
nom de la colonne (zone) nom système Type de donnée Description TABLE_NAME TBNAME VARCHAR(258) Table sur laquelle l'index est suggéré TABLE_SCHEMA DBNAME CHAR(10) Bibliothèque de la table SYSTEM_TABLE_NAME SYS_TNAME CHAR(10) nom système (court) de la table PARTITION_NAME TBMEMBER CHAR(10) Partition KEY_COLUMNS_ADVISED KEYSADV VARCHAR(16000) nom des clé suggérées LEADING_COLUMN_KEYS LEADKEYS VARCHAR(16000) clé principale, dont le critère de tri (croissant/décroissant) n'importe pas. INDEX_TYPE INDEX_TYPE CHAR(14) type d'index (normal ou EVI) LAST_ADVISED LASTADV TIMESTAMP date/heure de suggestion TIMES_ADVISED TIMESADV BIGINT nombre de fois la suggestion a été faite ESTIMATED_CREATION_TIME ESTTIME INT nombre de secondes(estimées) pour la création REASON_ADVISED REASON CHAR(2) Code raison (Sélection / tri ou groupage / les deux) LOGICAL_PAGE_SIZE PAGESIZE INT taille des pages recommandée MOST_EXPENSIVE_QUERY QUERYCOST INT temps d'exécution le plus long AVERAGE_QUERY_ESTIMATE QUERYEST INT temps d'exécution moyen TABLE_SIZE TABLE_SIZE BIGINT nombre de lignes dans la table (lors de la suggestion) NLSS_TABLE_NAME NLSSNAME CHAR(10) Séquence de tri à utiliser NLSS_TABLE_SCHEMA NLSSDBNAME CHAR(10) Bibliothèque de la séquence de tri MTI_USED MTIUSED BIGINT Nombre de fois ou cet MTI a été utilisé
(le système n'utilise plus un MTI, dès qu'un index permanent existe)MTI_CREATED MTICREATED INT Nombre de fois ou cet MTI a été créé
(rappel un index MTI disparaît à l'IPL)LAST_MTI_USED LASTMTIUSE TIMESTAMP Date/heure de dernière utilisation de cet index MTI.