Le principe est simple, il s'agit de balayer la totalité de la table
Ce balayage peut être réalisé en parallèle
1. Parallel pre-fetch
Le chargement du fichier est réalisé en parallèle
cette option est automatiquerment choisie par l'optimiseur si le temps prévu pour les I/O est supérieur au temps CPU prévu.Il faut autoriser cela par QQRYDEGREE et de préférence faire tourner le requête dans un pool avec expert cache actif (*CALC)
2. Parallel table scan
Idem au 1/ mais en plus le traitement de la table (une fois chargée en mémoire) est éclaté sur l'ensemble des processeurs.
Vous devez installer le dispositif facturable DB2/ SMP
3. Parallel table pre-load et parallel Index pre-load
Le chargement de la table et des index est réalisé en parallèle et en tache de fond, pendant le traitement de la requête (il faut beaucoup de mémoire, pour que cela soit efficace)
Utilisation d'un Index pour réaliser les tests contenus dans la requête.
Index B-arbre
ATTENTION, les Index EVI ne peuvent pas être utilisés pour les jointures.
Il vous faut donc encore quelques index b-tree sur les clefs primaires et étrangères, CE QUI EST FAIT en AUTOMATIQUE si vous mettez en place l'intégrité référentielle de DB2/400 (PRIMARY KEY et FOREIGN KEY)
JOINTURES et GROUPAGE
Le premier enregistrement de la table 1 est relié aux enregistrements de table2 suivant la valeur de clé (utilisation d'un index) , chaque enregistrement étant lui-même reliè à table3 etc…
Quand la jointure est complète, on passe à l'enregistrement suivant de table1 jusqu'à épuisement.
Cette technique est utilisée quand moins de 20 % des enregistrements sont retournés.
On fabrique une nouvelle table (en mémoire)) dans laquelle on place les enregistrements selon la méthode du hash-coding. Il s'agit d'établir une correspondance entre la valeur d'une clé et la position physique de l'enregistrement par le jeu d'une fonction (souvent basée sur un nombre premier).la localisation d'une ligne est alors particulièrement rapide.
La table de hachage peut être construire en
parallèle avec
SMP
Cette technique n'est possible que si le paramètre ALWCPYDTA
est
fixé à *OPTIMIZE et si la jointure est INTERNE
(pas de
LEFT OUTER JOIN).
Les deux tables sont triées suivant la valeur de la zone de jointure, puis l'on applique la jointure sur le résultat.
Un index n'est pas utile, cette technique est utilisée si plus de 20 % des lignes sont sélectées.
|
Ceci dit, pour des problèmes de transition et de temps, toutes les |
|
|
|
|
|
|
Faut-il utiliser la journalisation SUR DES BASES DECISIONELLES ?
Par contre pensez à enlever SMAPP (fonction de l'OS,
provoquant
une journalisation temporaire des index afin de proposer une reprise
plus rapide) par la commande CHGRCYAP SYSRCYTIME(*NONE).
L'optimiseur prend des décisions en fonction de la mémoire disponible pour chaque job (fair share)
CQE effectue un calcul simple : "taille du pool/ niveau d'activité" = mémoire maxi par job.
Si votre requête s'exécute seule dans un pool (ce
qui est
conseillé) , descendez le niveau d'activité
à 1.
En même temps, utilisez l'expert cache qui est toujours une
bonne
solution pour les accès base de données, dans des
pools
mémoire de plus de 100 Mo (on garde en mémoire
les tables
les plus utilisées).
Cela se paramètre par CHGSHRPOOL PAGING(*CALC)
SQE, lui divise la taille du pool par le nombre moyen de travaux (expert cache obligatoire, pour faire la moyenne)
Ce paramètre est renseignable sur les commandes STRSQL , RUNSQLSTM
- *NO la copie des données n'est pas admises (pour des
besoins
de temps réel)
- *YES la copie des données est admises, elle n'a lieu que quand il est impossible de faire autrement
- *OPTIMIZE la copie des
données est admises, elle aura lieu
à chaque fois que cela améliorera les temps de
réponses
(particulièrement le hachage pour les jointures)
c'est cette dernière valeur qu'il faut
privilégier (elle
est par défaut via ODBC./JDBC).
Ce paramètre est renseignable par la valeur système QQRYDEGREE (pour tout le monde) ou via le paramètre DEGREE de la commande CHGQRYA (session en cours)
| In the Teraplex Center, we have found that *MAX is most useful during the warehouse creation and update processes. For warehouse environments with many users running complex queries, running with SMP turned off is often a beter choice because the system will automatically send each query to its own processor. |
En résumé, à utiliser pendant la phase de chargement de la base décisionnelle (traitement s'exécutant seul), à enlever si des utilisateurs travaillent pendant les mises à jour, l'OS/400 répartissant de lui-même les tâches sur l'ensemble des processeurs.
Par contre, si cela est
possible, lors des mises à jour lourdes, le
parallélisme améliorera grandement le temps de
maintenance des index (lors du chargement initial, le plus simple est
de construire les index après).
Vous pouvez influencer l'optimiseur de requêtes en indiquant le nombre de lignes à traiter en même temps :
Si vous indiquez une petite valeur, l'optimiseur cherche à
rendre un résultat le plus rapide possible, vous le forcer
à utiliser des index, même si le temps global doit
en
pâtir.
C'est une solution interactive (STRSQL considère, sans
indication de votre part, une optimisation pour 3% des lignes du
fichier)
Si vous indiquez une GRANDE
valeur (FOR ALL ROWS est admis depuis
V4R30) l'optimiseur privilégie le temps global de
traitement.
Vous favoriserez les copies temporaires, les tris, le hachage s'ils
sont plus efficaces)
C'est une solution purement orientée batch et gros volumes.
(INSERT into …SELECT … FORM …, est
toujours traité pour un
nombre maxi de lignes)
voyez aussi le fichier d'option QAQQINI|
|
1/ passez la commande STRDBG avant de lancer SQL en mode 5250 ,
vous verrez alors
après chaque requête des messages
CPI43xx ansi que SQL79xx dans l'historique indiquant les choix de
l'optimiseur.
ID message Texte du message SQL7910 Les curseurs SQL ont été fermés. |
2/ mettez le paramètre QRYTIMLMT à 0 par la commande CHGQRYA :
toutes vos requêtes seront alors refusées (CPA4259) , l'optimiseur vous indiquant le temps qu'il a prévu :
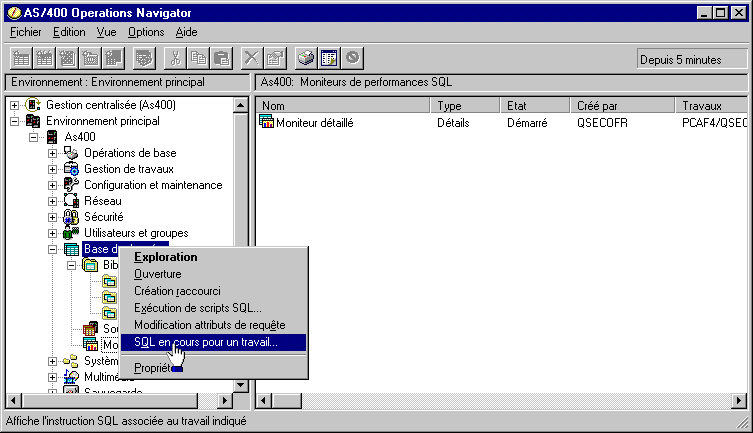
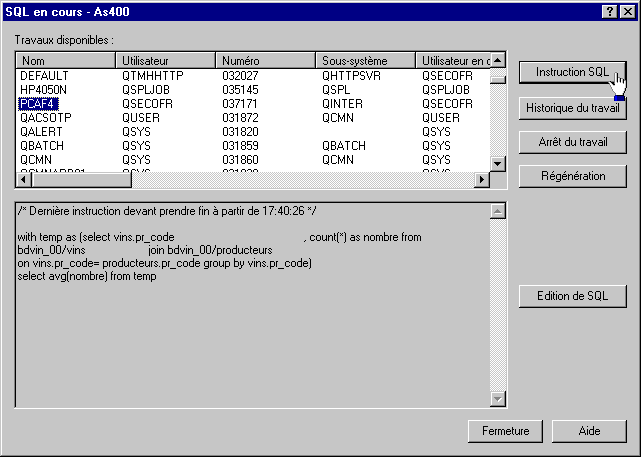
3/ Pour les Batch, utilisez le Moniteur base de données :
dans une session 5250, lancez la commande STRDBMON
via Operation navigator :
choisissez "base de données"/"moniteur de performances SQL"
Les outils graphiques
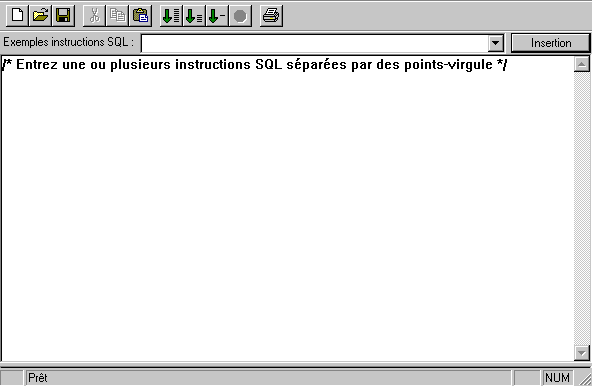
Vous pouvez :
sauvegarder
et relire un script SQL
lancer
tout ou partie du script
demander
l'inclusion des messages degug et voir l'historique du travail sur
l'AS/400
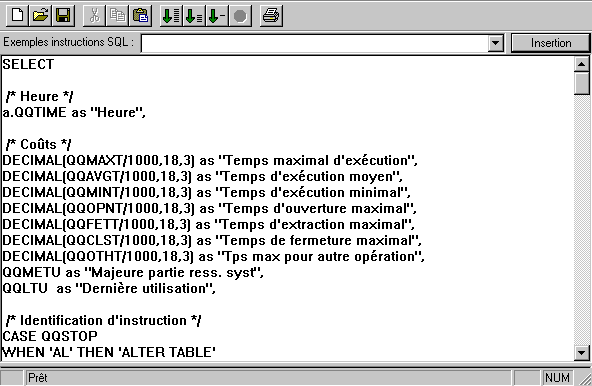
modifier vos attributs de requête. (fichier QAQQINI)
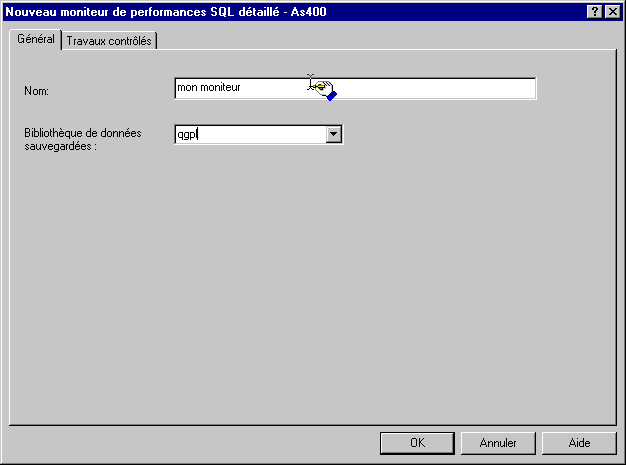
cliquez sur moniteur de Base de données / nouveau ...
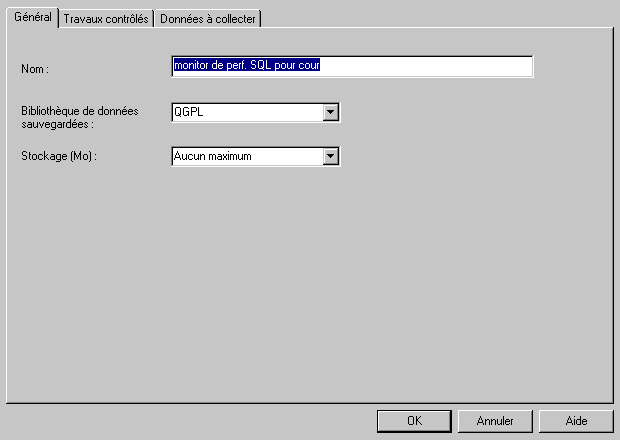
il s'agit en fait de la commande STRDBMON, il faut indiquer la bibliothèque où stocker les fichiers.
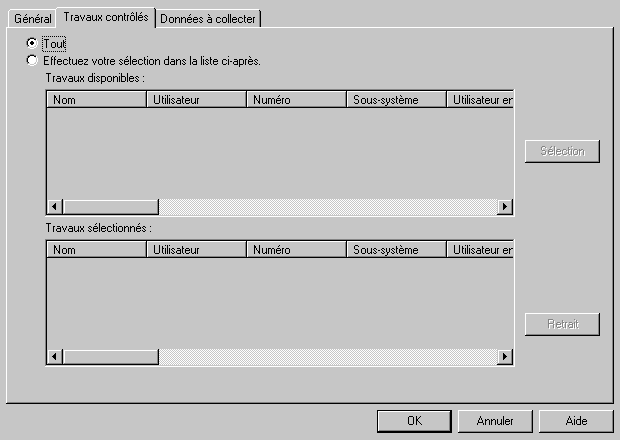
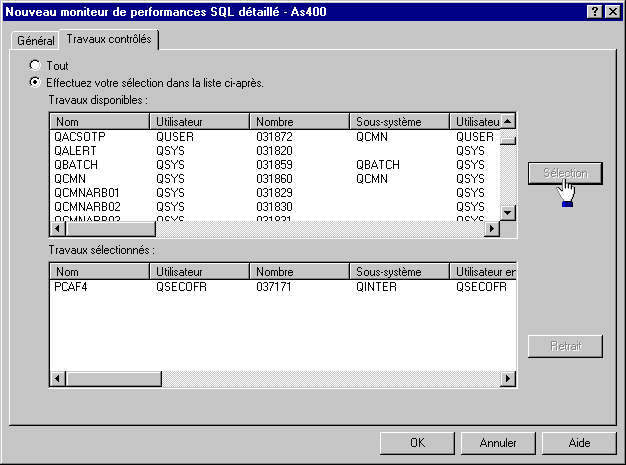
Puis indiquer les travaux à analyser (un , plusieurs , ou tous)
et les options à écrire dans le fichier trace
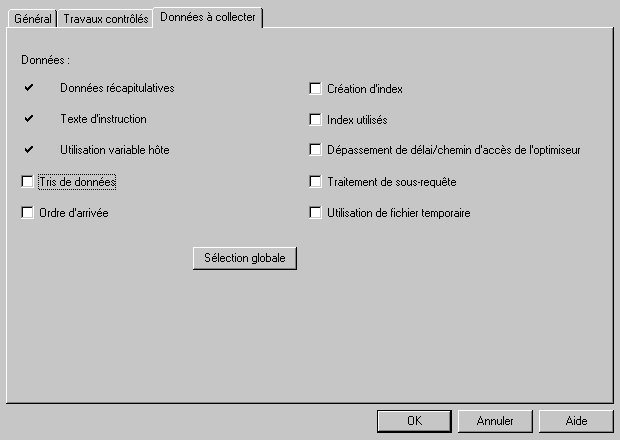
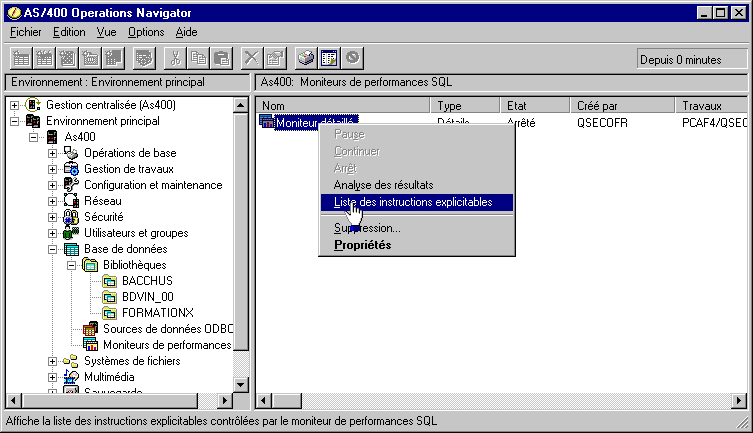
quand la trace est terminée (l'arrêt est à votre charge), choisissez une vue (les données à afficher)


il s'agit en fait d'un ordre SQL, lancé sur les fichiers stockés dans la bibliothèque choisie au début du paramétrage.
Vous pouvez modifier cet ordre ....... avec le gestionnaire de scripts :
3/
Visual Explain
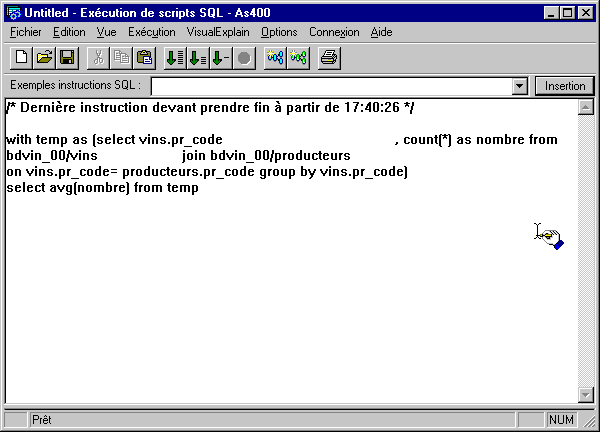
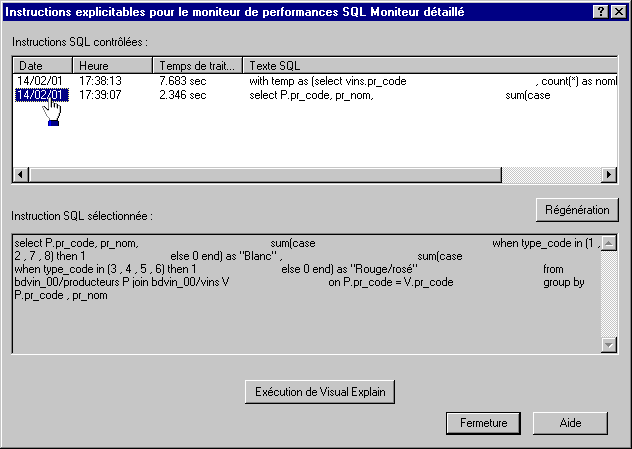
Vous pouvez maintenant obtenir une Explication graphique du détail d'une requête SQL avec Visual Explain :
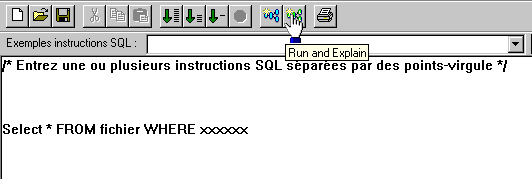
Le bouton EDITION SQL, place cette requête dans la fenêtre d'exécution de scripts SQL
| Le
bouton que voici lance la requête avec
QRYTIMLMT à 0 (la requête ne sera pas vraiment exécutée, mais l'optimiseur aura fait son travail) ce qui permet une analyse |
 |
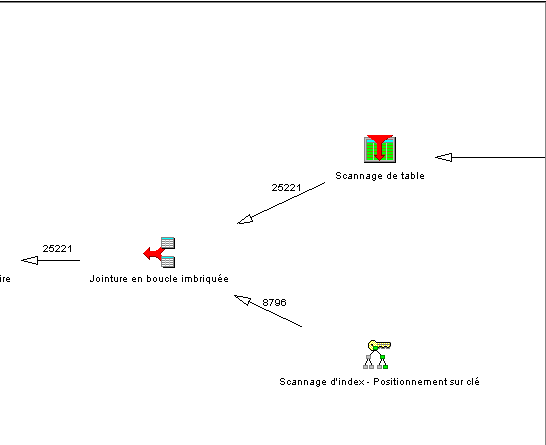
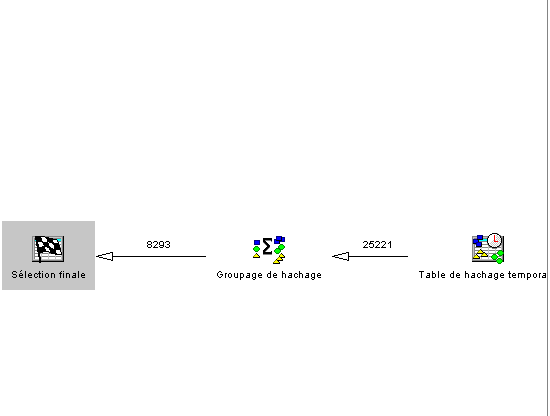
Visual Explain vous affiche alors le détail des différentes phases de la requête :
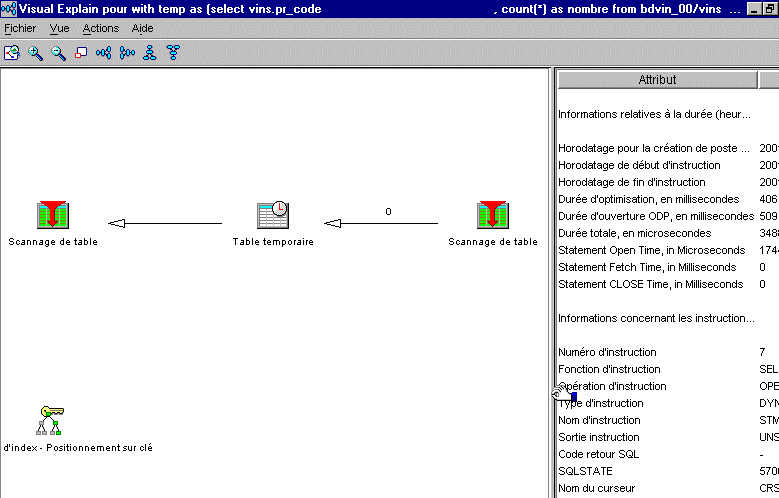
ICI, la phase de jointure
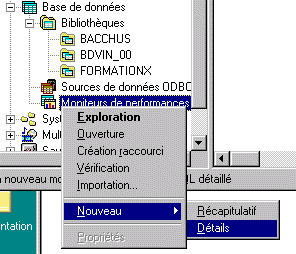
Vous pouvez aussi lancer Visual Explain sur le résultat d'un
moniteur de performance base de données.
de nouvelles zones ont étés ajoutées
pour Visual
Explain
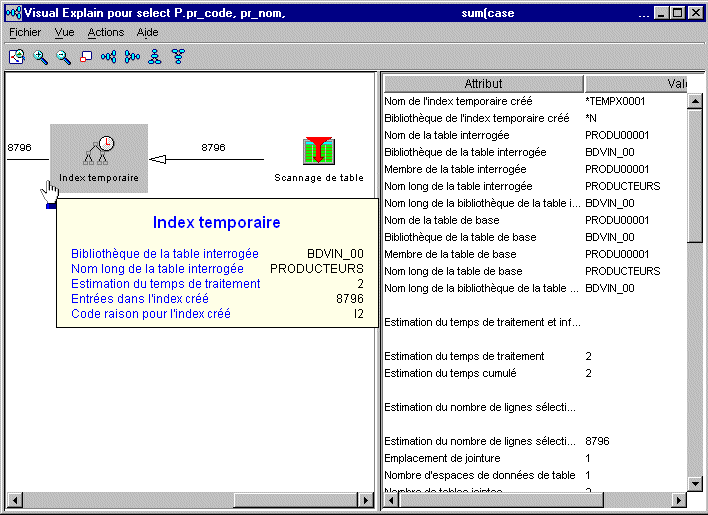
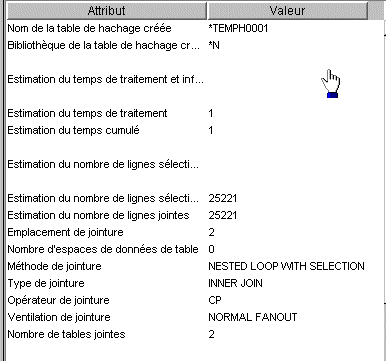
3/ V5R20 & Collectes de statistiques
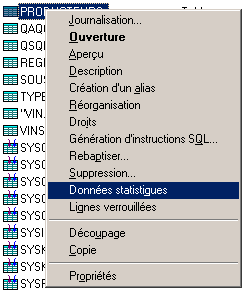
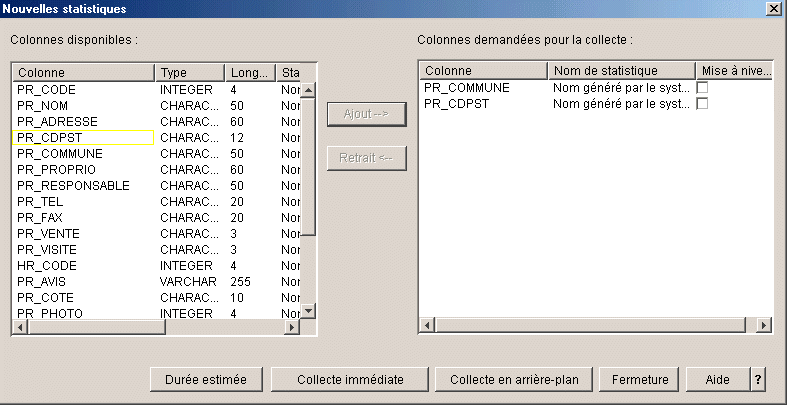
Pour définir ou voir les statistiques, utilisez
le click droit sur une table

Le bouton nouveau, permet de
définir une nouvelle collecte
Une message vous est
affiché (la première fois au
moins)

puis
:
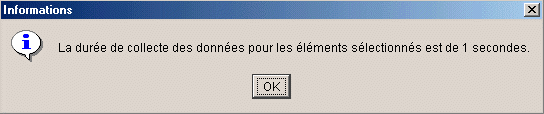
si vous demandez la durée estimée, on vous
affiche (ici sur une table de 500.000 lignes)
puis
cliquez sur
Collecte immédiate, les statistiques sont collectées immédiatement (vous attendez)
On vous rappelle alors vos
choix concernant la valeur système
QDBSTCCOL

et
les collectes sont soumises.
Pour voir les collectes en
attente, cliquez droit sur l'option
Base de données
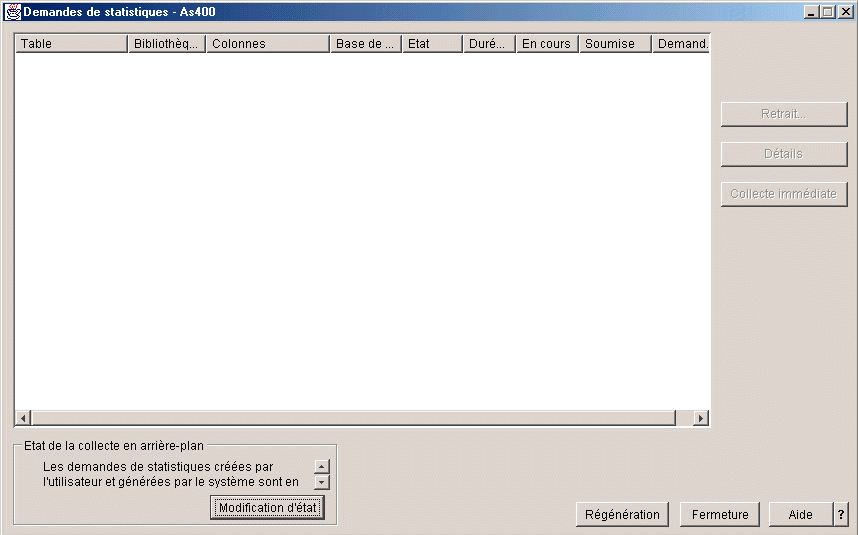
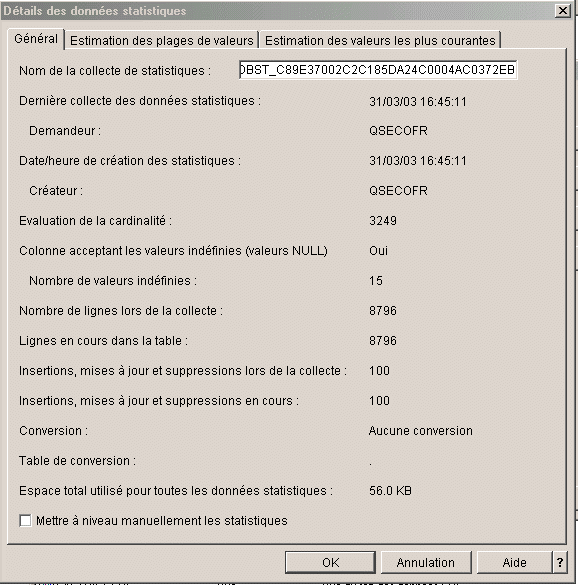
la fenêtre permettant de créer une nouvelle collecte, donne aussi un accès aux informations concernant une collecte existante :
Informations
générales
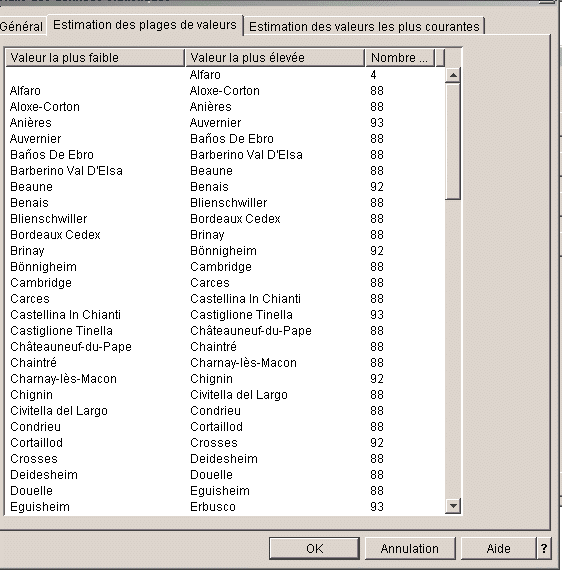
Plages de valeurs (ou
tranches)
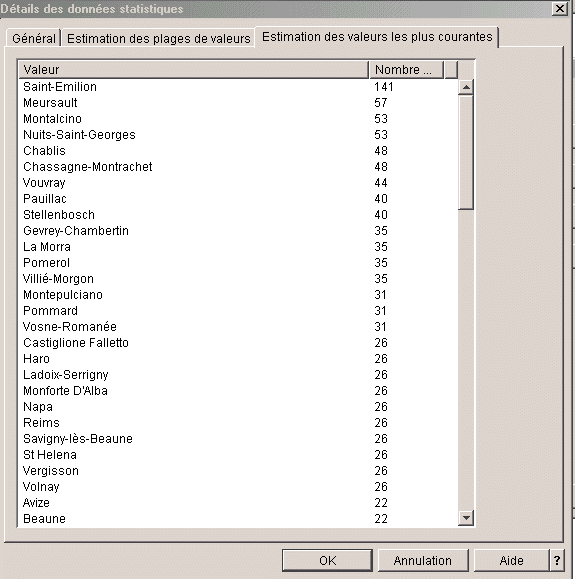
Valeurs les plus
utilisées
Visual Explain sait pleinement tirer profit de ces nouveautés :
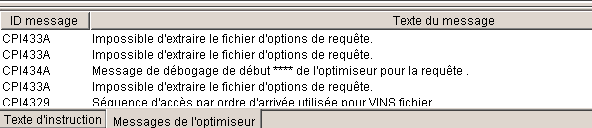
Tout d'abord nous pouvons maintenant afficher l'historique du travail (contenant les messages DEBUG)
 ,
ce qui s'affiche en bas
,
ce qui s'affiche en bas
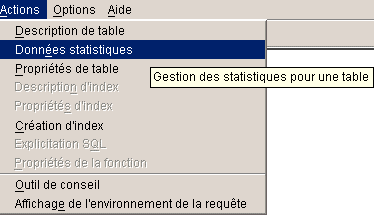
le Menu Option propose
Un
accès direct à la
gestion des statistiques
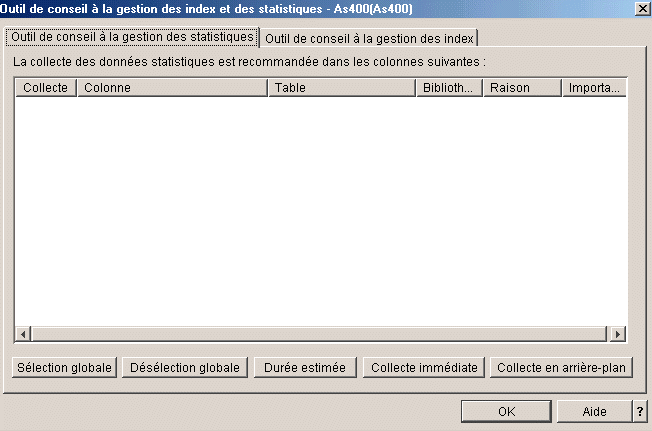
Un
outils de conseil,
suggérant certaines collectes
ou
la création d'index
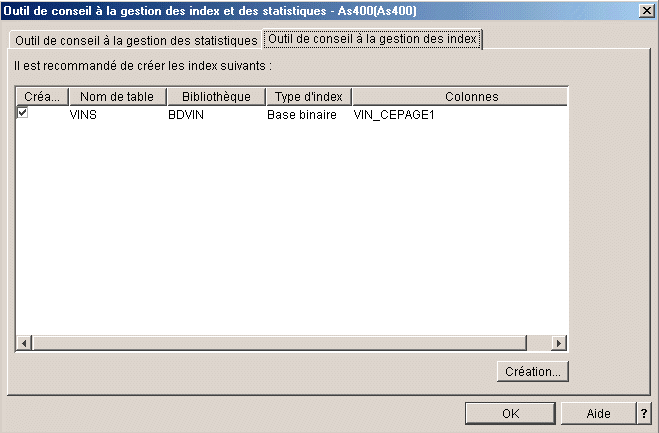
Le menu VUE, peut mettre en évidence
les
index recommandés

ce qui s'affiche :
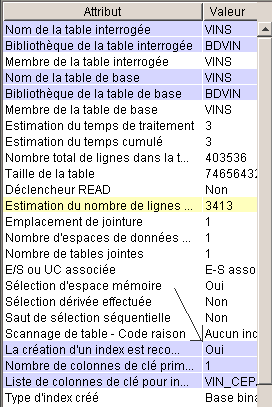
les étapes
les plus coûteuses en nombre de
lignes
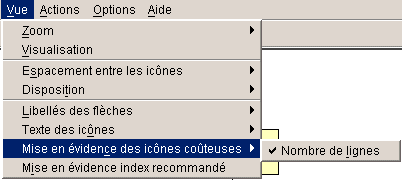
Ce qui s'affiche :
![]()