|
|
|
|
|
|
|
Planning de péremption de profils utilisateur |
|
|
|
|
|
WATCH |
La version 7.1 de IBM i apporte à SQL l'intégration du langage XML.
Cette intégration a été normalisée sous le nom de SQLXML, elle propose :
commençons par la création d'une table avec le type de champs XML, tel que donné par la documentation
CREATE SCHEMA POSAMPLE; |
Les champs de type XML peuvent faire jusqu'à 2 Go, la totalité d'une ligne ne peut pas dépasser 3,5 Go.
Ils sont stockés dans le CCSID indiqué par SQL_XML_DATA_CCSID dans QAQQINI, UTF-8 (1208) par défaut.
Puis insertion de données, le parsing (la conversion CHAR -> XML) est automatique lors des insertions,
mais vous pouvez parser de manière explicite avec XMLPARSE() pour utiliser des options (voir cette fonction)
INSERT INTO Customer (Cid, Info) VALUES (1000, |
Mais aussi (voir la fonction GET_XML_FILE ici):
INSERT INTO POSAMPLE/CUSTOMER
VALUES( 1004 , GET_XML_FILE('/temp/client04.xml') ) |
le document doit être bien formé, sinon vous recevrez SQ20398
Complément d'informations sur message |
Voyons le résultat

Attention : Client Access V7 impératif !
Sous une session 5250, la sérialisation (conversion en une chaîne simple) n'est pas faite par défaut :

il faut utiliser XMLSERIALIZE(INFO as CHAR(2000) ) pour voir le contenu, le CCSID du job doit être renseigné (pas de 65535).

La zone INFO doit être manipulée dans sa totalité, il n'est pas possible de n'afficher ou de ne modifier que la ville du flux xml précédent.
par exemple
update customer set info = |
Comment manipuler du XML en programmation (RPG et COBOL particulièrement)
Il faut pour cela revoir la manipulation des BLOB et CLOB tel que vue en V4R40.
|
|
|
Exemple en COBOL |
LE XML se manipule de la même manière avec les types suivants
D MON_XML S SQLTYPE(XML_DBCLOB:2500)
Génère :
D MON_XML DS D MON_XML_LEN 10U D MON_XML_DATA C LEN(2500)
D MON_FICHIERXML S SQLTYPE(XML_CLOB_FILE)
Génère :
D MON_FICHIERXML DS D MON_FICHIERXML_NL 10U D MON_FICHIERXML_DL 10U D MON_FICHIERXML_FO 10U D MON_FICHIERXML_NAME 255A
exec sql
select info into :mon_fichierxml from posample/customer
where cid = 1000; |
le fichier xml01.xml est bien généré dans /temp (CCSID 1208) et contient :
Browse : /temp/xml01.xml |
un ordre INSERT aurait lu le fichier XML de l'IFS et placé son contenu dans une colonne de la table SQL.
--STRIP WHITESPACE---
XMLPARSE(DOCUMENT '<xml> ... </xml>' | |
-PRESERVE WHITESPACE- |
XMLVALIDATE(DOCUMENT '<xml> ... </xml>' ACCORDING TO XMLSCHEMA -->
|---ID un-schéma-enregistré--|
>---| |----
|--une URI valide------------| |
XMLTRANSFORM( flux-xml USING 'source-XSLT') |
select XMLTEXT('100 est > à 99 & à 98')
100 est > à 99 & à 98 |
select XMLELEMENT(name "region" , region) from bdvin1.regions; <region>Abruzzo </region> |
select xmlelement(name "Appellations", |
select xmlelement(name "Appellations", XMLATTRIBUTES(pays_code as "pays"),
appellation , region_code )
from bdvin1.appellations join bdvin1.regions using (region_code) ;
|
select xmlelement(name "vin:Appellations", XMLNAMESPACES('http://www.volubis.fr/vins/1.0' AS "vin") , |
SELECT XMLPI(NAME "Instruction", 'APPUYEZ SUR ENTREE') <?Instruction APPUYEZ SUR ENTREE?> |
select XMLCOMMENT('A consommer avec modération')
<!--A consommer avec modération--> |
select XMLCONCAT(XMLELEMENT(name "region" , region) ,
XMLELEMENT(name "pays" , pays_code)) from bdvin1.regions; ;
<region>Abruzzo </region><pays>18</pays> |
select XMLFOREST(region , pays_code) from bdvin1.regions; <REGION>Abruzzo </REGION><PAYS_CODE>18</PAYS_CODE> |
select XMLROW(appellation, region_code) from bdvin1.appellations; <row><APPELLATION>Alella D.O. </APPELLATION><REGION_CODE>21</REGION_CODE></row> |
Fonctions de groupe (agrégat)
select pays_code, xmlagg(XMLELEMENT(name "region" , region))
from bdvin1.regions
group by pays_code ;
1 <region>Constantia </region><region>Durbanville </region> ... |
select pays_code, XMLGROUP(XMLELEMENT(name "region" , region))
from bdvin1.regions
group by pays_code ;
11 <rowset><row><APPELLATION>Aljarafe </APPELLATION><REGION>Andalucía</REGION></row><row><APPELLATION>Bailen ... </rowset> |
Il faut commencer par enregistrer le schéma dans XSROBJECTS de QSYS2 par la procédure XSR_REGISTER
Enregistrons le schéma XML suivant (nous devons passer par une procédure, XSR_REGISTER attendant un paramètre de type BLOB)
CREATE PROCEDURE SAMPLE_REGISTER
LANGUAGE SQL
BEGIN
DECLARE CONTENT BLOB(1M);
VALUES BLOB('<?xml version="1.0"?>
<xs:schema targetNamespace="http://posample.org"
xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified">
<xs:element name="customerinfo">
<xs:complexType>
<xs:sequence>
<xs:element name="name" type="xs:string" minOccurs="1" />
<xs:element name="addr" minOccurs="1" maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="street" type="xs:string" minOccurs="1" />
<xs:element name="city" type="xs:string" minOccurs="1" />
<xs:element name="prov-state" type="xs:string" minOccurs="1" />
<xs:element name="pcode-zip" type="xs:string" minOccurs="1" />
</xs:sequence>
<xs:attribute name="country" type="xs:string" />
</xs:complexType>
</xs:element>
<xs:element name="phone" nillable="true" minOccurs="0" maxOccurs="unbounded">
<xs:complexType>
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="type" form="unqualified" type="xs:string" />
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:element>
<xs:element name="assistant" minOccurs="0" maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="name" type="xs:string" minOccurs="0" />
<xs:element name="phone" nillable="true" minOccurs="0" maxOccurs="unbounded">
<xs:complexType>
<xs:simpleContent >
<xs:extension base="xs:string">
<xs:attribute name="type" type="xs:string" />
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
<xs:attribute name="Cid" type="xs:integer" />
</xs:complexType>
</xs:element>
</xs:schema>')
INTO CONTENT;
CALL SYSPROC.XSR_REGISTER('POSAMPLE', 'CUSTOMER', 'http://posample.org', CONTENT, null);
END; |
Exécutez et validez par :
CALL POSAMPLE.SAMPLE_REGISTER; CALL SYSPROC.XSR_COMPLETE('POSAMPLE', 'CUSTOMER', null, 0); |
Vérifiez en affichant le contenu de XSROBJECTS
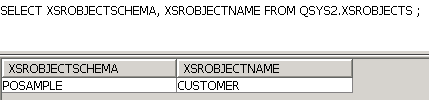
Essayons d'insérer une donnée ne respectant pas les règles.
-> ici nous ne fournissons pas d'élément <addr> alors que ce dernier est déclaré obligatoire (<xs:element name="addr" minOccurs="1")
INSERT INTO POSAMPLE.Customer(Cid, Info) VALUES (1004, |
par contre
|
C'est à dire "parser" le XML afin de le faire correspondre ("mapper") aux colonnes d'une table
Les éléments du mappage dans le schéma :
<xs:schema |
<xs:annotation> |
<xs:element name="name" type="xs:string" minOccurs="1" db2-xdb:rowSet="CUSTOMERD" db2-xdb:column="NOM" />
ou
<xs:attribute name="country" type="xs:string" db2-xdb:rowSet="CUSTOMERD" db2-xdb:column="PAYS" />
|
Remarque
tous les éléments n'ont pas à être associés à une colonne (on peut "perdre" des données)
la phase de transformation gère les éléments multiples, par exemple pour un client, un nom, une adresse et DES téléphones
il y aura autant de lignes générées qu'il y a des N° de téléphone, nom et adresse étant répétés (un peu comme une jointure)
Ce schéma doit être enregistré, (nous devons toujours passer par une procédure, XSR_REGISTER attendant un paramètre de type BLOB)
CREATE PROCEDURE POSAMPLE.SAMPLE_DECOMP ( )
LANGUAGE SQL
BEGIN
DECLARE CONTENT BLOB ( 1 M ) ;
VALUES BLOB('<?xml version="1.0"?>
<xs:schema targetNamespace="http://posample.org"
xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified"
xmlns:db2-xdb="http://www.ibm.com/xmlns/prod/db2/xdb1" >
<xs:annotation>
<xs:appinfo>
<db2-xdb:defaultSQLSchema>POSAMPLE</db2-xdb:defaultSQLSchema>
</xs:appinfo>
</xs:annotation>
<xs:element name="customerinfo">
<xs:complexType>
<xs:sequence>
<xs:element name="name" type="xs:string" minOccurs="1" db2-xdb:rowSet="CUSTOMERD" db2-xdb:column="NOM" />
<xs:element name="addr" minOccurs="1" maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="street" type="xs:string" minOccurs="1" db2-xdb:rowSet="CUSTOMERD" db2-xdb:column="RUE" />
<xs:element name="city" type="xs:string" minOccurs="1" db2-xdb:rowSet="CUSTOMERD" db2-xdb:column="VILLE" />
<xs:element name="prov-state" type="xs:string" minOccurs="1" db2-xdb:rowSet="CUSTOMERD" db2-xdb:column="ETAT" />
<xs:element name="pcode-zip" type="xs:string" minOccurs="1" />
</xs:sequence>
<xs:attribute name="country" type="xs:string" db2-xdb:rowSet="CUSTOMERD" db2-xdb:column="PAYS" />
</xs:complexType>
</xs:element>
<xs:element name="phone" nillable="true" minOccurs="0" maxOccurs="1"
db2-xdb:rowSet="CUSTOMERD" db2-xdb:column="TEL">
<xs:complexType>
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="type" form="unqualified" type="xs:string" />
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:element>
</xs:sequence>
<xs:attribute name="Cid" type="xs:integer" />
</xs:complexType>
</xs:element>
</xs:schema>')
INTO CONTENT;
CALL SYSPROC . XSR_REGISTER ( 'POSAMPLE' , 'CUSTOMERD' , 'http://posample.org' , CONTENT , NULL ) ; END ; CALL POSAMPLE.SAMPLE_DECOMP; CALL SYSPROC.XSR_COMPLETE('POSAMPLE', 'CUSTOMERD', null, 1); |
le dernier paramètre sur XSR_COMPLETE indique si le schéma servira à une décomposition (1) ou non (0)
Vous pouvez voir aussi les schémas par la nouvelle option de System I Navigator (Décomposition représente ce dernier paramètre)

Puis la décomposition se fait à l'aide de la procédure XDBDECOMPXML qui attend un BLOB contenant un flux XML à décomposer.
pour décomposer du XML stocké dans une table vous devez écrire une procédure qui balaye la table :
CREATE PROCEDURE POSAMPLE.DECOMP ( )
LANGUAGE SQL
SET OPTION DBGVIEW = *SOURCE
BEGIN
DECLARE CONTENT BLOB ( 2G ) ;
DECLARE WEOF INTEGER DEFAULT 0;
DECLARE not_found CONDITION FOR '02000';
DECLARE c1 CURSOR FOR
SELECT XMLSERIALIZE(info as BLOB(2G) ) FROM POSAMPLE.CUSTOMER;
DECLARE CONTINUE HANDLER FOR not_found SET wEOF = 1; OPEN c1; FETCH c1 INTO content; WHILE wEOF = 0 DO CALL XDBDECOMPXML ('POSAMPLE' , 'CUSTOMERD' , content, NULL);
FETCH c1 INTO content;
END WHILE;
CLOSE c1;
END ; |
et voici le résultat
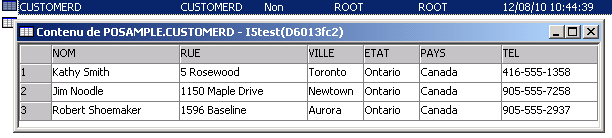
Les différentes annotations de l'espace de nommage db2-xdb :
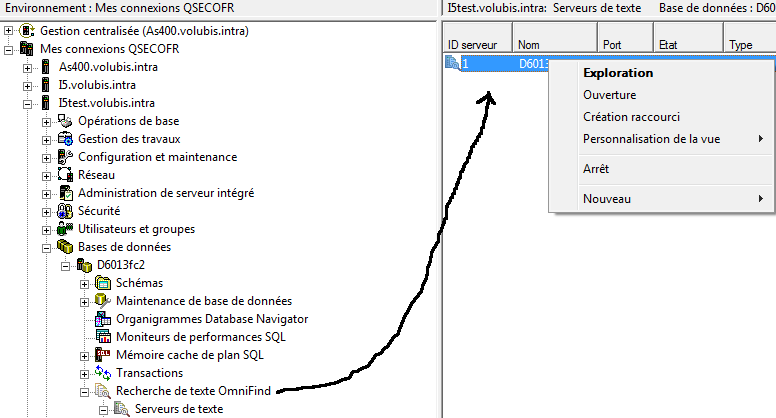
Le serveur OmniFind est fourni avec la version 7 de IBM i. Il permet une indexation des champs texte, texte enrichi (format .doc ou .pdf, par exemple) et enfin, avec cette nouvelle version 1.2, les champs de type XML.
OmniFind apporte :
Ce produit s'installe par RSTLICPGM 5733OMF, les options 30,33 et 39 de SS1 et java (JV1) sont des pré-requis.
L'installation doit vous créer un serveur de texte avec l'ID n° 1 (cela créé un répertoire /QOpenSys/QIBM/ProdData/TextSearch/server1)
La requête suivante donne la liste des serveurs :
SELECT SERVERID,SERVERPORT,SERVERSTATUS,SERVERPATH FROM QSYS2.SYSTEXTSERVERS
(ServerStatus à 0 indique un serveur actif, 1 inactif)
Ainsi que System i navigator
le serveur se démarre avec cette même interface ou IBM Navigator Director
ou avec les procédures cataloguées suivantes
Vous pouvez créer un index OmniFind sur les types de donnée suivants :
les données peuvent être stockées en texte simple, HTML, XML, ou un format enrichi. Elles seront transformées en UNICODE 1208 avant d'être indexées, donc pas de job en CCSID(65535).Ce ne sont pas des index traditionnels DB2 (pas d'objet, donc pas de SAVOBJ) , ils ne sont pas maintenus temps réel et n'ont d'existence que dans le cadre du serveur OmniFind.
Les index sont enregistrés dans SYSTXTINDX de QSYS2, trois triggers sont ajoutés à la table indexée qui stockent les mises à jour dans une table temporaire, dite table de transfert, crée elle aussi à cette occasion (toujours dans QSYS2).
Création d'un Index
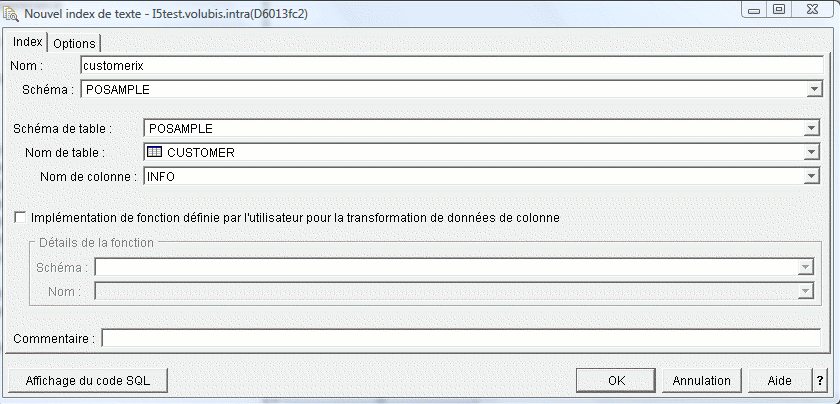
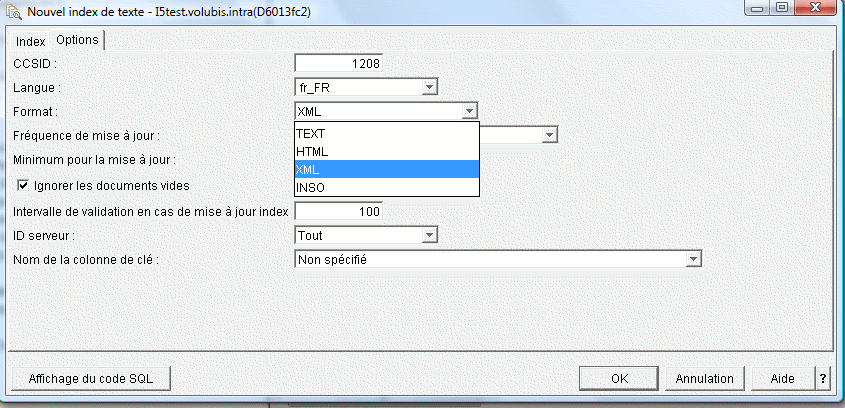
CALL SYPROCS.SYSTS_CREATE
Paramètres
(les valeurs par défaut des options sont stockées dans SYSTEXTDEFAULTS)
Exemple :
CALL SYSPROC.SYSTS_CREATE('BDVIN1', 'PRODUCTEURS_IX', 'BDVIN1.PRODUCTEURS(PR_AVIS)', 'CCSID 1208 LANGUAGE fr_FR FORMAT TEXT
UPDATE FREQUENCY NONE UPDATE MINIMUM 1 INDEX
CONFIGURATION(IGNOREEMPTYDOCS 1 , UPDATEAUTOCOMMIT 100)');
Une ligne est ajoutée dans SYSTEXTINDEXES (Nom système : SYSTXTINDX)la table de transfert est créé dans QSYS2 (son nom est précisé dans STAGINGTABLENAME), les trois triggers sont ajoutés à la table indexée afin d'écrire dans la table de transfert
un répertoire est créé dans l'IFS (répertoire /QOpenSys/QIBM/ProdData/TextSearch/server1/config/collections)
son nom est indiqué par COLLECTIONNAME (par exemple 0_1_3_2010_09_28_17_10_36_131543, pour l'index 3 créé en septembre 2010)Une vue est créé portant le nom de l'index (PRODUCTEURS_IX) dans la bibliothèque indiquée. C'est le seul objet pouvant être sauvegardé par SAVOBJ.SAVLIB.
La restauration de la vue, recréé l'index de recherche OmniFind (sans les données) et relance l'indexation.
Ensuite, il vous lancer la procédure de mise à jour (l'index est créé vide par SYSTS_CREATE) :
CALL SYPROCS.SYSTS_UPDATE
- Schéma
- Nom de l'index
- Option (facultative)
- USING UPDATE MINIUM
- nombre de mise à jour minimum dans la table de transfert pour faire la mise à jour de l'index.
l'index est alors créé dans le répertoire de la collection (la création prend au moins 3 à 5 fois le temps de création d'un index "normal")
-> Pour détruire l'index
CALL SYPROCS.SYSTS_DROP
- Schéma
- Nom de l'index
-> Pour modifier les caractéristiques de l'index
CALL SYPROCS.SYSTS_ALTER
- Schéma
- Nom de l'index
- Options
- toutes les options de la procédure SYSTS_CREATE
- RENAME FUNCTION
- pour renommer la fonction, si ce n'est pas une colonne qui est indexée.
Recherche
Deux fonctions sont à votre disposition :
Exemple :
WHERE contains(pr_avis,'excellent') = 1
Que mettre dans une expression de type texte
- un-mot
- en minuscules ou en majuscules, l'indexation ne tient pas compte de la casse
- avec ou sans le s pluriel, ainsi contains(pr_avis , 'coopérative') trouve les avis contenant coopératives
- avec sous sans les accents ainsi contains(pr_avis , 'cooperative') trouve les avis contenant coopérative(s)
- - (tiret) un-mot
- ce mot est exclut (il ne doit pas être rencontré) contains(pr_avis , 'cave -cooperative'), recherche cave et PAS coopérative
- deux mots
- il sont implicitement reliés par AND
contains(pr_avis , 'cave cooperative') trouve cave(s) ET coopérative(s)- si vous les placez entre guillemets " , c'est la chaîne qui est recherchée
contains(pr_avis , ' "cave cooperative" ') trouve cave suivit de coopérative (les pluriels ne sont plus gérés, mais la casse et l'accentuation sont toujours ignorées)
Exemple :
contains(pr_avis, 'chateau AND (pomerol OR lafite)') = 1 ;
trouve les lignes contenant chateau ou château ou châteaux puis, soit pomerol, soit lafite.
On peut même créer un dictionnaire de synonymes personnel en créant un fichier XML
Exemple :
<synonymgroups version="1.0">
<synonymgroup>
<synonym>vin</synonym>
<synonym>pinard</synonym>
<synonym>picrate</synonym>
<synonym>nectar</synonym>
</synonymgroup>
<synonymgroup>
<synonym>syrah</synonym>
<synonym>schiraz</synonym>
</synonymgroup>
</synonymgroups>
puis en passant la commande (sous QSH)
-synonymFile <chemin du fichier XML>
-collectionName <nom de la collection>
-replace <[true|false]>
-configPath <chemin absolu du dossier de config.>
Exemple > synonymTool.sh importSynonym
-synonymFile /temp/vin_synonyme.xml
-collectionName 0_1_3_2010_09_28_17_10_36_131543 -replace false
-configPath /QopenSys/QIBM/ProdData/TextSearch/server1/config
IQQD0084I The request was successfully executed.
$
contains(pr_avis, 'pinard')= 1 Donne 1 (pinard est le nom d'un producteur de Cognac) select count(*) FROM bdvin1/producteurs WHERE
contains(pr_avis, 'pinard', 'SYNONYM=ON')= 1 Donne 606
Recherche XML
La syntaxe des recherches XML utilise un sous-ensemble du langage W3 XPath
sous la forme CONTAINS(nom_colonne, '@xmlxp: ' 'expression_requête_Xpath' ' ')
le deuxième paramètre de la fonction CONTAINS est une chaîne donc entre quote ('), l'expression XPath étant elle même entre quotes il faut doubler ces dernières
vous devez indiquer un chemin dans l'arborescence XML :
Expression XPath Signifie / sélectionne le nœud, dit root element, qui englobe tout le document sauf <?xml version="1.0"?> // sélectionne tous les noeuds . sélectionne le nœud en cours /customerinfo sélectionne le nœud "customerinfo" //city sélectionne tous les éléments "city" du document où qu'ils soient /customerinfo/name sélectionne l'unique élément "name" fils de "customerinfo"
puis, éventuellement, un Predicat (un test) devant être vrai, toujours entre crochets [ et ]
Prédicat Signifie //phone[. = "xxx"] sélectionne tous les éléments "phone" du document (où qu'ils soient), ayant une valeur égale à xxx //phone[@type = "work"] sélectionne tous les éléments "phone" du document, ayant un attribut "type" dont la valeur est "work"
Pour les valeurs :
- Numerique, saisissez tel que '//quantite[. > 12000]'
- Alpha, saisissez entre guillemets '//phone[. = "02.40.30.00.70"]'
- Date, xs:date ou xs:DateTime, par exemple utilisez '/Article[@DateCrt > xs:date("2010-10-05")]'
- la requête XPath peut elle même contenir une recherche textuelle avec contains ou exclude, comme
'/Article[libart contains("piece AND rechange")]'Exemples :
SELECT * from posample/customer
where contains(info, '@xmlxp:''//name'' ') = 1 ....1....+.
CID
1.000 1.002 1.003
SELECT * from posample/customer
where contains(info, '@xmlxp:''//phone[. = "416-555-1358"]'' ')=1
....1....+.
CID
1.000
SELECT * from posample/customer
where contains(info,'@xmlxp:''//phone[. contains("905") ]'' ') = 1 ....1....+.
CID
1.002
1.003
SELECT * from posample/customer
where contains(info,'@xmlxp:''/customerinfo[phone = "416-555-1358"]'' ')=1
....1....+.
CID
1.000
La PTF SI40272 ainsi que le dernier niveau de GROUP PTF pour DB2 (level 9) apporte à Omnifind, deux fonctions supplémentaires
Vous devez d'abord créer une collection pour stocker ces informations, cela va créer une bibliothèque, contenant
vous pouvez fournir des options d'indexation , comme CALL SYSPROC.SYSTS_CRTCOL(‘OMNI_COL’,‘UPDATE FREQUENCEY D(*) H(0) M(0)’)
ou CALL SYSPROC.SYSTS_CRTCOL(‘OMNI_COL’,‘FORMAT INSO’) -- si les fichiers IFS sont de type Word, PDF, etc...
Ensuite vous devez accorder des droits à la procédure cataloguée SEARCH qui vient d'être créé
SET CURRENT SCHEMA OMNI_COL
GRANT EXECUTE ON PROCEDURE SEARCH(VARCHAR) TO QPGMR
comment ajouter des objets à l'index, toujours par procédure cataloguée
IL faut toujours commencer par définir la collection dans le chemin de recherche des procédures cataloguées
SET CURRENT PATH OMNI_COL
CALL ADD_SPLF_OBJECT_SET(‘QGPL’, ‘QPRINT’) -- par OUTQ
ou bien CALL ADD_SPLF_OBJECT_SET(‘’, ‘’ , 'QPGMR') -- par propriétaire
version complète (un paramètre à blanc n'est pas un critère)
CALL ADD_SPLF_OBJECT_SET(‘ ’ -- bibliothèque OUTQ
‘ ’ -- OUTQ ‘ ’ -- Propriétaire ‘ ’ -- nom du JOB ‘ ’ -- profil du JOB ‘ ' -- N° du JOB ‘ ’) -- USRDTA ‘2011-06-01T00:00:00’ -- date/heure de début '2011-06-30T23:59:59' -- date/heure de fin )
CALL ADD_IFS_STMF_OBJECT_SET(‘/home/mesfichiers’)
Remarques : -> le paramètre doit être un nom de répertoire -> ne peut pas contenir de caractères génériques (*) -> les liens symboliques ne sont pas traités -> les sous-répertoires ne sont pas traités
Ensuite vous devez rafraîchir l'index OmniFInd pour indexer réellement
CALL UPDATE
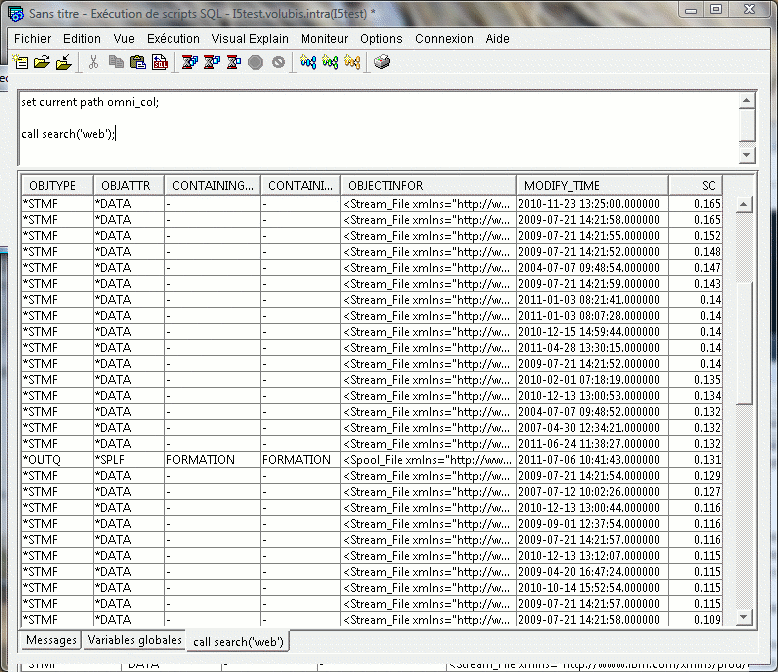
enfin vous pouvez faire des recherches, par CALL SEARCH('mot-recherché')
cela retourne un "result set" structuré comme suit :
Exemple
structure de la zone OBJECTINFOR
Autres procédures
QUERY_OBJECT_SET
Retourne la liste des objets indexés
GET_OBJECT_STATUS
retourne le status d'un objet
GET_OBJECTS_NOT_INDEXED
retourne la liste des objets non indexés
SYSTS_DRPCOL
détruit une collection
|
|
|
|
|
EXEMPLES : -------- |
|
|
|
|
|
La version 7 propose aussi une nouvelle fonctionnalité permettant de crypter le contenu d'une colonne par le nouveau mot-clé FIELDPROC ajouté aux ordres SQL CREATE TABLE et ALTER TABLE
Create table fieldtable |
sous System i navigator :
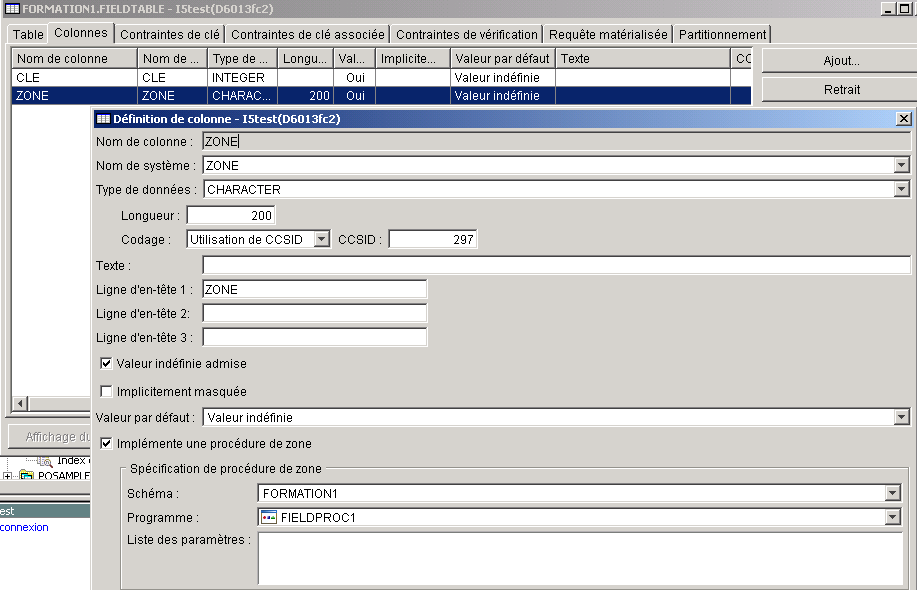
La zone cryptée ne peut pas être :
Programmation :
Exemple avec un pgm qui inverse les bits (fonction RPG %BITNOT) sur une zone CHAR
et ne décrypte que si c'est QSECOFR qui lit.
/free |
puis
Insert into fieldtable values |
SELECT * FROM FIELDTABLE, sous QSECOFR
Sous un autre profil 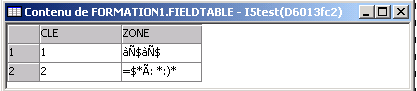 (ici, avec System i navigator)
(ici, avec System i navigator)
Quelques remarques
- La documentation vous déconseille de crypter le caractère espace
en effet quand vous comparez à la zone, une constante plus courte, le système complète l'information la plus petite par des espaces.
si les espaces de la zone sont cryptés, du coup la donnée sera considérée comme différente de la constante alors qu'en réalité ce n'est pas le cas.
- les tris peuvent être perturbés sur une zone cryptée :
ex SELECT *FROM FIELDTABLE ORDER BY ZONE
-> sous QSECOFR 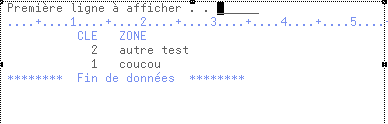 (la zone est décryptée)
(la zone est décryptée)
-> sous un autre profil  (la zone reste cryptée)
(la zone reste cryptée)
- lors d'un CPYF la procédure sera appelée (même sur DSPPFM), ainsi que lors d'un CREATE TABLE AS (SELECT ...)
- une option de QAQQINI destinée à l'optimiseur, indique si la zone doit être décryptée systématiquement :
FIELDPROC_ENCODED_COMPARISON :
RPG
Rational Open Access, RPG edition (5733OAR) est un produit apparu
en 7.1 et disponible aussi pour la V6R1(avec PTF).
Il permet de passer la main à un "driver" externe lors des ordres d'entrée/sortie RPG, plutôt que d'appeler les routines historiques d'IBM.
Par exemple:
- Ajout au pgm applicatif de HANDLER('le-nom' : info)
le fichier auquel vous avez ajouté HANLDER doit être présent à la
compilation ET à l'exécution (malgré que vous ne vous
en serviez pas vraiment, il fournit le format)
le produit 5733OAR (facturable) doit être présent à la
compilation ET à l'exécution.
- Ecriture du Handler
// Exemple // Standard IBM supplied Open Access definitions /copy QOAR/QRPGLESRC,QRNOPENACC // paramètre recu par le pgm // de type QrnOpenAccess_T D CVS_HDLR PI D info likeds(QrnOpenAccess_T) |
zones de QrnOpenAccess_T remarquables :
lors de l'OPEN le Handler doit signaler comment il veut recevoir les données (QrnOpenAccess_T.useNamesValues)
QrnNamesvalues_T (si useNamesvalues est à *ON) :
//Exemple
// déclaration de la structure basée sur Qrnnamesvalues_T
//D QrnNamesValues_T...
//D DS QUALIFIED TEMPLATE ALIGN
//D num 10I 0
//D field LIKEDS(QrnNameValue_T)
//D DIM(32767) |
QrnNamevalue_T (description d'une zone) , les lg sont données en nombre d'octets :
//Exemple, suite
// boucle autours du nbr de variables
// pour récupérer les valeurs et les traiter
D pvaleur s *
D valeur s 32470a Based(pvaleur)
|
Autre fonctionnalités
La PTF SI43471 apporte de nouveaux paramètres à la commande CPYSPLF permettant une transformation d'un spool existant .
CPYSPLF QPDSPAJB TOFILE(*TOSTMF) TOSTMF(/temp/wrkactjob.txt)
CPYSPLF QPDSPAJB TOFILE(*TOSTMF) TOSTMF(/temp/wrkactjob.tif) WSCST(QSYS/QWPTIFFG4)
CPYSPLF QPDSPAJB TOFILE(*TOSTMF) TOSTMF(/temp/wrkactjob.pdf) WSCST(*PDF)