
V6R10
Nouveautés systčme de la version 6.1
IBM i est le nouveau nom qui remplace I5/OS.
Il est livré en version 6.1 et est disponible sur POWER5 et POWER6
Parmi les nouveautés matériel, citons :
-le processeur POWER6 donc,avec une puissance unitaire de 4300 CPW ou +
-la possibilité d'utiliser VIOS (Virtual IO Serveur), ce dernier
pouvant s'allouer toutes les ressources et les partageant par le biais
de ressources virtuelles.
ATTENTION, VIOS ne sait pas émuler un dérouleur de bande virtuel
-la possibilité de créer une partition IBMi "hostée", c.a.d utilisant
des disques virtuels offerts par une autre partition IBMi.
(comme les partitions Linux, sur versions précédentes)
-la possibilité d'intégrer une partition IBMi dans un Blade center
|
Cette nouvelle version de l'OS possède un jeu d'opérations codées
(niveau Microcode) différent .
Il faut donc recréer les programmes pour cette nouvelle version, à partir
des données de création contenues dans ce dernier.
(comme au passage CISC/RISC)
ces données de création sont automatiquement contenues dans les programmes
compilés en version 5.1 et suivantes
mais peuvent être absentes sur les versions précédentes, si vous avez
enlevé l'observabilité (RMVOBS).
(Depuis la V5.1, enlever l'observabilité conserve les données de création)
IBM fournit une commande ANZOBJCVN pour les versions 5.3 et 5.4 afin de
planifier le changement de version, voyez l'APAR II14306
|
Pourquoi ce nouveau format ?
* pour une meilleure intégrité des objets
* pour une meilleure utilisation de la mémoire , particulièrement du
Téraspace
* pour apporter de nouvelles options à ILE, particulièrement *DEFER sur
un programme de service lié, permettant son chargement mémoire
uniquement lors de l'utilisation réelle (si elle est occasionnelle)
* pour ACG (Adaptive Code Generation) qui génèra des programmes
utilisant au mieux et dynamiquement le jeu d'instructions du
processeur sur lequel ils s'exécutent !
|
CPYSRCF possède deux nouveaux paramètres
TOMBRID *GEN l'identificateur de niveau de membre est généré
*FROMMBR l'identifiant est le même que le membre copié
SRCCHGDATE *FROMMBR , par défaut la date de modification de source
est la même que le source copié pour les
membre créé ou copiés avec MBROPT(*REPLACE)
pour une copie MBROPT(*ADD) la date est
mise à la date du jour.
*NEW la date est mise à la date du jour.
La commande DSPAUTLOBJ qui liste les objets protégés par une AUTL
liste aussi maintenant les objets et les répertoires de l'IFS,
particulièrement dans le fichier de sortie.
|
la commande DSPPGMREF sur un Query (*QRYDFN) créé en V6R1 donne des
informations sur les fichiers manipulés
les Query non modifiés en V6R10 n'affichent aucune référence croisée
le paramètre OBJTYPE admet *QRYDFN et *ALL inclus les Query.
La commande STRDBMON admet en plus des paramètres :
FTRFILE : filtrer sur le nom de fichier
FTRUSER : filtrer sur le nom d'utilisateur
FTRINTNETA : filtrer par adresse Internet
les paramètres suivants, nouveaux en V6
FTRLCLPORT : filtrer suivant le port IP local
FTRQRYGOVR : filtrer suivant les limites de Query Governor
|
Vous pouviez déjà fixer une limite aux requêtes par CHGQRYA (en V5)
- QRYTIMLMT : limite de temps
- QRYSTGLMT : limite en mémoire temporaire
Un message CPA4259 (interrogation) sera envoyé à moins que vous ayez défini
un programme sur le point d'exit QIBM_QQQ_QUERY_GOVR
Si la réponse au message d'interrogation CPA4259 est 'Cancel'
ou la réponse retournée par le pgm d'exit annule la demande (2 ou 3),
ET que vous indiquez FTRQRYGOVR(*COND) alors la requête est écrite.
Si vous indiquez FTRRYGOVR(*ALL), alors la requête est toujours écrite.
Un nouveau point d'exit QIBM_QMH_HDL_INQEXT + la PTF SI29311 gèrent
l'appel à un programme chargé de répondre aux messages d'interrogation
envoyés à l'External (*EXT).
|
JDBC :
Plusieurs modification faites à l'interface java.sql.database.Metadata
dont le fait que "localhost", ne soit plus accepté en tant que catalogue.
Le driver JDBC natif possède une nouvelle propriété QueryCloseImplicit
qui permet un CLOSE implicite lors de la lecture de la dernière ligne
Cette nouvelle propriété est active par défaut et doit améliorer les
temps de réponse
|
DB2 et SQL
(nous ne voyons ici que les différences, pas les nouveautès)
les fonctions LEFT et RIGHT extraient des caractères et non des Octets,
vous devez donc fournir en 2eme argument un nbr de caractères à extraire
(important pour UNICODE et DBCS, transparent pour EBCDIC)
la valeur de IGNORE_DERIVED_INDEX dans QAQQINI est par défaut à *YES
permettant d'ignorer les index dérivés des tables qui en possèdent.
la fonction RRN est interdite sur les vues utilisant des tables UDTF
les paramètres de type caractère des fonctions SQL (UDF) avec le style de
paramètre GENERAL, sont cadrés à droite.
si vous déclarez un paramètres de 15 de long et que la fonction retourne 16
vous verrez les 15 derniers et non les 15 premiers.Si la fonction retourne
la bonne longueur vous ne verrez pas de différence.
|
les fonctions ADD_MONTHS et LAST_DAY retournent un horodatage si le
paramètre en entrée est un horodatage, sinon une date comme avant.
la fonction NEXT_DAY retourne une date si le paramètre est une date,
sinon un horodatage comme avant.
Enfin, l'utilisation de la clause USING lors d'une jointure change l'ordre
des colonnes retournées
Soit : Select * from T1 join T2 USING(z1)
cela retourne Z1, puis les zones de T1 sauf Z1 et celles de T2 sauf Z1
ET l'utilisation d'une correllation pour les zones USING est interdite.
Select A.Z1, A.Z2 from T1 A join T2 B USING(z1) retourne SQL0205
"La colonne Z1 ne se trouve pas dans la table T1 de *LIBL"
il faut écrire :
Select Z1, A.Z2 from T1 A join T2 B USING(z1)
|
Vous ne pouvez plus utiliser dans les critères de jointure réalisées par
JOIN, des variables qui viennent d'une jointure simple (dans le WHERE)
par exemple :
SELECT * FROM T1, T2 WHERE ... fonctionne
SELECT * FROM T1 JOIN T2 ON t1.cle = t2.cle aussi
SELECT * FROM T1, T2 JOIN T3 on t2.cle = t3.cle fonctionne toujours.
SELECT * FROM T1, T2 JOIN T3 ON t2.cle = t3.cle
AND t3.autrecle = t1.autrecle
==> ne fonctionne pas : SQL0338
il faut écrire :
SELECT * FROM T1 JOIN T2 on t1.cle = t2.cle
JOIN T3 ON t2.cle = t3.cle
AND t3.autrecle = t1.autrecle
|
SQL devient moins permissif sur les assignations de valeur de type
différent à la variable (CHAR dans du VARCHAR par exemple)
le nombre de mots-réservés augmente, voici les nouveaux mots-réservés :
DECFLOAT, SNAN, NAN, INFINITY
NCHAR, NVARCHAR, NCLOB, NATIONAL
VOLATILE
LOCKED
FINAL
GROUPING, SETS , CUBE, ROLLUP
RDI, ASCII, CHR
CLIENT_ACCTNG, CLIENT_USERID, CLIENT_APPLNAME, CLIENT_PROGRAMID, CLIENT_WRKSTNNAME
|
Nouvelle commande bien pratique ANZCMDPFR
Vous lancez cette commande avec le paramètre CMD() contenant UNE commande
ou le paramètre CMDFILE() faisant référence à un source contenant plusieurs
commandes
et vous obtenez (dans la JOBLOG) des informations de performance dans le
texte d'aide du message CPCC711 ANZCMDPFR command completed successfully
Cause . . . . . : The request to measure the performance of a single CL
command or a set of CL commands has completed.
Total Time Used . . . . . . . . . . . : 2,476
Total CPU time Used . . . . . . . . . : 1,383
Synchronous Database Reads . . . . . : 2
Synchronous Non Database Reads . . . : 106
Synchronous Database Writes . . . . . : 0
Synchronous Non Database Writes . . . : 129
Asynchronous Database Reads . . . . . : 40
Asynchronous Non Database Reads . . . : 1
... etc...
|
De nouvelles informations sont associés au profil utilisateur et affichées
par DSPUSRPRF
Profil utilisateur - Informations générales
Profil utilisateur . . . . . . . . . . . . : CM
Dernière ouverture de session . . . . . . : 02/09/08 18:21:15
Vérifications du mot de passe infructueuses: 0
Etat . . . . . . . . . . . . . . . . . . . : *ENABLED
Date dernière modif du mot de passe . . . : 24/06/08 08:47:08
> Le mot de passe est *NONE . . . . . . . . : *NO
Durée de validité du mot de passe . . . . : *SYSVAL
> Mot de passe arrivé à expiration par la
commande . . . . . . . . . . . . . . . . : *NO (CHGUSRPRF PWDEXP)
> Bloquer la modification du mot de passe . : *SYSVAL (cf ci-dessous)
Gestion locale du mot de passe . . . . . . : *YES
Classe d'utilisateur . . . . . . . . . . . : *PGMR
> Date/Heure de création . . . . . . . . . . : 24/08/99 18:12:40
> Date/Heure de modification . . . . . . . . : 02/09/08 18:07:44
> Date de la dernière utilisation . . . . . : 03/09/08
> Date/Heure de restauration . . . . . . . . : 18/06/08 17:47:43
A Suivre ...
|
C/ nouvelles valeurs système
QPWDCHGBLK temps mini (en jours) avant de pouvoir changer de mot de passe
QPWDEXPWRN temps (en jours) avant envoi d'un avertissement indiquant
que le mot de passe va arriver à expiration.
QPWDRULES règles pour les mots de passe
*PWDSYSVAL on utilise les valeurs système de la V5R40
*CHRLMTAJC deux caractères identiques adjacents sont interdits
*CHRLMTREP deux caractères identiques sont interdits
*DGTLMTAJC deux chiffres adjacents sont interdits
*DGTLMTFST le premier caractère ne peut pas être un chiffre
*DGTLMTLST le dernier caractère ne peut pas être un chiffre
*DGTMAXn le mot de passe ne peut pas contenir plus de n chiffres
(par exemple *DGTMAX3 : 3 chiffres maxi)
*DGTMINn le mot de passe doit contenir au moins n chiffres
*LMTSAMPOS caractère(s) identique(s) à la même position que
l'ancien mot de passe, interdit (comme QPWDPOSDIF)
|
*LMTPRFNAM le mot de passe ne peut pas contenir le profil
*LTRLMTAJC deux lettres identiques adjacentes sont interdites
*LTRLMTFST le premier caractère ne peut pas être une lettre
*LTRLMTLST le dernier caractère ne peut pas être une lettre
*LTRMAXn le mot de passe ne peut pas contenir plus de n lettres
*LTRMINn le mot de passe doit contenir au moins n lettres
*MAXLENnnn lg maxi (nnn) du mot de passe, comme QPWDMAXLEN avant.
*MINLENnnn lg mini (nnn) du mot de passe, comme QPWDMINLEN avant.
*MIXCASEn le mot de passe doit contenir au moins n minuscules
et n majuscules (valide avec QPWDLVL à 2 ou 3)
*REQANY3 le mot de passe doit contenir au moins trois des ces
quatre types : - une minuscule
- une majuscule
- un chiffre
- un caractère spécial
*SPCCHRLMTAJC le mot de passe ne peut pas contenir 2 caractères
spéciaux adjacents
*SPCCHRLMTFST le premier caractère ne peut pas être un caractère spécial
*SPCCHRLMTLST le dernier caractère ne peut pas être un caractère spécial
*SPCCHRMAXn le mot de passe ne peut pas contenir plus de n car.spéciaux
*SPCCHRMINn le mot de passe doit contenir au moins n car.spéciaux
|
D/ sauvegarde/restauration
Le paramètre DFRID permet de mieux restaurer les objets dépendants.
Par objets dépendant, comprendre LF ou MQT, dépendant d'un PF, par exemple
Vous restaurez la bibliothèque BIB1 avec DFRID(RST1), par exemple
si BIB1 contient des logiques, ils sont placés dans un cache
si BIB1 contient des MQT, elles sont restaurées, inutilisables
Puis vous restaurez BIB2 avec le même DFRID(RST1), BIB2 contenant les PF
les objets de BIB1 mis en différés sont automatiquement restaurés ou
validés, lors de la restauration de BIB2, si :
a/ ils sont restaurés dans leur bibliothèque d'origine
b/ les restauration utilisent le même DFRID [par défaut *DFT=QRSTLIB]
Si la restauration de la 2ème bibliothèque ne suffit pas, utiliser :
RSTDFROBj DFRID(RST1)
la commande RMVDFRID,élimine les informations du cache, sans RSTDFROBJ.
|
la nouvelle commande STRSAVSYNC permet de démarrer un point de contrôle
commun à plusieurs commandes de sauvegarde.
ceci concerne la fonctionnalité SAVACT et permet de marier dans un même
point de contrôle, par exemple, une commande SAVLIB et une commande SAV
à condition qu'elle utilisent le même SYNCID.
les deux commandes de sauvegarde doivent débuter dans le délai
indiquer par STRSAVWAIT (600 S. par défaut)
Exemple :
STRSAVSYNC SYNCID(MASYNCHRO) NUMSYNC(2) STRSAVWAIT(1800)
puis
SAVLIB LIB(CLIENTS) DEV(TAP01) SAVACT(*SYNCLIB) SYNCID(MASYNCHRO)
SAV DEV('/QSYS.LIB/TAP01.DEVD') OBJ('/clients/*')
SAVACT(*SYNC) SYNCID(MASYNCHRO)
|
La commande de sauvegarde peut maintenant sauvegarder les droits privés
de l'objet en même temps que l'objet lui même (paramètre PVTAUT à *YES)
les commandes de restauration RSTOBJ et RSTLIB possèdent un paramètre
FRCOBJCVN indiquant si la conversion au nouveau format microcode
doit avoir lieu :
FRCOBJCVN(*SYSVAL) ==> voir QFRCOBJCVN
FRCOBJCVN(*NO) la conversion aura lieu à la première utilisation
FRCOBJCVN(*YES *RQD) la conversion aura lieu si elle est obligatoire
FRCOBJCVN(*YES *ALL) la conversion aura lieu systématiquement
Cette notion est directement liée à la nouvelle fonctionnalité ACG
(Adaptive Code Generation), permettant à un programme d'utiliser
une nouvelle instruction microcode, sans tenir compte du fait que cette
instruction n'existe peut-être pas sur tous les modèles
pgm compilé sur un POWER6 et restauré sur POWER5 par ex.
Cette conversion peut donc avoir lieu sur un même niveau de version !
(machines de processeurs différents)
|
E/ nouveau produit 5761TS1 IBM Transform Services for i5/OS
et particulièrement l'option 1 : Transformation AFP/PDF
Ce produit est livré gratuitement (pour l'instant ?) et implique que vous
ayez installé 5761SS1/option3 et 33 (PASE)
il utilise deux nouvelles fonctions associées aux PRTF :
1/ le paramètre TOSTMF( ) demandant à ce que le PRTF génère non pas
un spool, mais un fichier stream dans l'IFS.
Vous pouvez préciser un répertoire et le nom de fichier est généré
automatiquement
Vous pouvez préciser un nom de fichier, il ne doit pas exister
quand le fichier stream est généré.
vous devez aussi indiquer DEVTYPE(*AFPDS)
|
2/ le paramètre WSCST (non obligatoire) proposant une transformation
par objet de personnalisation lors de l'écriture du fichier stream
il propose, particulièrement, la valeur *PDF, qui génère ....un PDF.
Ces deux paramètres sont accessibles sur les commandes CHGPRTF et OVRPRTF
Par exemple
-OVRPRTF QPDSPLIB DEVTYPE(*AFPDS) TOSTMF('/tmp/')
puis DSPLIB xxx *PRINT
génère un fichier QPDSPLIB@Dt013.afp
-OVRPRTF QPDSPLIB DEVTYPE(*AFPDS) TOSTMF('/tmp/') WSCST(*PDF)
génère un fichier QPDSPLIBk3w5pz.pdf
-OVRPRTF QPDSPLIB DEVTYPE(*AFPDS) TOSTMF('/tmp/test.pdf') WSCST(*PDF)
génère un fichier test.pdf
|
Nouveautés SQL de la version 6.1
V6R10 , cette version apporte de nombreuses nouveautés à SQL.
- DECFLOAT nouveau format numérique 16 ou 32 Chiffres (BigDecimal en java)
à la norme IEEE 754R permettant le stockage de :
valeurs décimales très grandes:
16: -9.999999999999999x10 p.384 à 9.999999999999999x10 p.384
32: -9.999999999999999999999999999999999x10 puissance 6144
à 9.999999999999999999999999999999999x10 puissance 6144
le zéro signé + et -
la valeur infinie (INFINITY) positive ou négative
la valeur "quiet NaN" (not a number=NAN)
résultat d'un calcul invalide ne provoquant pas d'erreur
la valeur "signal NaN"(SNAN)
résultat d'un calcul invalide provoquant une erreur
|
- NCHAR, NVARCHAR, NCLOB ou NATIONAL CHAR|VARCHAR|CLOB
nouveaux types de donnée en UNICODE (CCSID=1200)
- les zones FOR BIT DATA (CCSID=65535) sont compatibles avec le type BINARY
- l'attribut : IMPLICITLY HIDDEN , lors du CREATE TABLE
(NOT HIDDEN est le défaut)
les zones cachées n'apparaissent pas en retour d'un SELECT * FROM...
mais uniquement si vous les demandez dans la liste du SELECT
- les timestamp générés automatiquement (le type TIMESTAMP est facultatif)
FOR EACH ROW ON UPDATE AS ROW CHANGE TIMESTAMP
attribut ajouté à une zone TIMESTAMP NOT NULL, indique que cette
colonne est modifiée avec le timestamp en cours à chaque INSERT/UPDATE
Il ne peut y avoir qu'une seule colonne de ce type par table.
|
Quand vous créez une table par copie d'une autre:
CREATE TABLE T1 like (select ..)
Vous pouvez préciser :
EXCLUDING --
>--IMPLICITLY HIDDEN COLUMN ATTRIBUTES
INCLUDING --
et
EXCLUDING --
>--ROW CHANGE TIMESTAMP COLUMN ATTRIBUTES
INCLUDING --
Vous pouvez aussi indiquer sur CREATE TABLE
VOLATILE indiquant à l'optimiseur que le nombre de lignes peut varier
très rapidement (utilisation d'un index souhaitable)
ou
NOT VOLATILE
|
et
NOT LOGGED INITIALLY
indiquant que la table n'est pas journalisée automatiquement
sinon, la table est journalisé automatiquement dès la création.
La journalisation automatique pouvant être définie par :
1/ la présence d'un journal QSQJRN
2/ la présence d'une data area QDFTJRN indiquant le nom du journal
3/ le fait d'avoir utilisé la commande STRJRNLIB sur la bibliothèque
(ce dernier point est nouveau en V6R10)
CREATE INDEX
La création d'index subit de nombreux changements, les rendant proches
des fichiers logiques (LF)
|
A/ On admet les expressions en tant que clé
CREATE INDEX i1 on table T1 ( UPPER(NOM) as NOMMAJ )
la zone NOMMAJ est la clé de cet index.
toute requête utilisant WHERE UPPER(NOM) like '...%', utilisera
implicitement l'index en question.
l'expression ne peut pas contenir :
- des sous requêtes
- des fonctions agrégées (COUNT, AVG, SUM, etc ...)
- des fonctions NOT DETERMINISTIC (dont le résultat varie), comme
ATAN2,DECRYPT_DB,ENCRYPT_TDES,RAND, CURDATE, DIFFERENCE, REPEAT
GENERATE_UNIQUE, CURTIME, DLURLCOMPLETE, GETHINT, REPLACE, INSERT
DLURLxxx , DLURLPATHONLY, IDENTITY_VAL_LOCAL ROUND_TIMESTAMP, SOUNDEX
DAYNAME, MONTHNAME, MONTH_BETWEEN, TIMESTAMP_FORMAT, TIMESTAMPDIFF
- des UDF sauf celles liées à un nouveau type de données (UDT)
- la manipulation de SEQUENCE
- des variables , des marqueurs ("?")
|
B/ On admet la clause WHERE sur les index :
CREATE INDEX i1 on table T1 (NOM) WHERE NOM NOT LIKE 'VOL%'
la clause WHERE subit les mêmes règles que les expressions
C/ Vous pouvez préciser un format par la clause RCDFMT
(rappel: c'est possible sur les tables depuis la V5R40)
suivi de la phrase suivante :
ADD ALL COLUMNS : toutes les colonnes du PF appartiennent au format
ADD KEYS ONLY : seules les zones clés appartiennent au format
ADD col1, col2 : ces zones font suite aux zones clés dans le format
ATTENTION : la valeur par défaut est ADD KEYS ONLY
et le nom de format par défaut est le nom de l'INDEX
(avant l'index avait le même format que la table)
|
Exemple récapitulatif :
CREATE INDEX logi1 on HTTPLOG
( SUBSTR(virtualhost, 1 , 10) VHOST2 )
Where virtualhost IS NOT NULL
RCDFMT httpfmt2 ADD host, logtime -- en plus de VHOST2
L'ordre ALTER FUNCTION est nouveau et permet de modifier les attributs
d'une fonction (UDF)
l'ordre LABEL ON admet en plus, à cette version :
LABEL ON CONSTRAINT*
FUNCTION
PROCEDURE
TRIGGER
TYPE*
tous ces types d'objets sont aussi admis par COMMENT ON.
(ceux avec * sont nouveaux en V6R10)
|
SELECT
un select utilisant la clause USING pour faire sa jointure :
- retourne les zones de jointure, puis les autres dans l'ordre des tables
- les zones de jointure ne doivent PAS être qualifiées
une nouvelle option de jointure est disponible: FULL OUTER JOIN
affichant l'équivalent du SELECT suivant (soit toutes les combinaisons)
SELECT * FROM T1 LEFT OUTER JOIN T2 on ...
UNION
SELECT * FROM T1 RIGHT EXCEPTION JOIN T2 on ...
la clause SKIP LOCKED DATA est nouvelle et permet d'ignorer les lignes
verrouillées.
cette clause concerne toutes les tables lues
cette clause ne concerne que COMMIT(*ALL ou *RS)
==> ignorée avec COMMIT(*NONE|*CHG|*RR)
|
VALUES(val1, val2, ...) peut être utilisé à la place de SELECT
rendant possible : SELECT z1, z2, z3 FROM FICHIER WHERE ...
UNION VALUES(val1 , val2, val3)
VALUES peut être aussi utilisé simplement pour tester une fonction :
Sur la ligne de commande SQL, pour voir le résultat
Dans un TRIGGER pour voir si la fonction produit une erreur(interceptable)
On peut passer un ordre SELECT sur le résultat d'un INSERT permettant
ainsi, de retrouver facilement la valeur d'une zone IDENTITY ou d'un
TIMESTAMP, par exemple.
Exemple avec T1 possédant Z1 AS IDENTITY et Z3 de type TIMESTAMP
SELECT Z1, Z3 FROM FINAL TABLE
(INSERT INTO T1 (z2, z3) VALUES('test', now() )), affiche:
Z1 Z3
3 2008-08-07-09.04.17.455674
|
SI vous insérez plusieurs lignes, la clause ORDER BY admet maintenant
INPUT SEQUENCE, demandant à ce que les lignes soit triées dans
l'ordre ou elles ont été insérées
Exemple
SELECT Z1, Z3 FROM FINAL TABLE
(insert into qtemp.toto (z2, z3)
values ('test2' , now() ) ,
('test3' , now() )
)
ORDER BY INPUT SEQUENCE
Z1 Z3
4 2008-08-07-09.57.46.375829
5 2008-08-07-09.57.46.375829
la clause GROUP BY évolue beaucoup pour implémenter des fonctions OLAP
|
Soit un fichier CAVE et un select GROUP BY suivant :
SELECT year(entreele) , cav_format, sum(prxactuel)
FROM ma_cave join vins using(vin_code)
GROUP BY year(entreele) , cav_format
affichant
YEAR CAV_FORMAT SUM
2.006 CAISSE de 6 20,82
2.008 Bouteille 5,35
2.007 Bouteille 278,15
2.008 CAISSE de 6 15,76
2.006 Bouteille 278,78
2.007 CAISSE DE 6 28,96
Le montant des vins par année et format de stockage (un niveau de rupture)
Nous allons ajouter les nouvelles clauses : GROUPING SETS
ROLLUP
CUBE
|
SELECT year(entreele) , cav_format, sum(prxactuel)
FROM ma_cave join vins using(vin_code)
GROUP BY GROUPING SETS (year(entreele) , cav_format)
affiche le total par année, PUIS le total par format
YEAR CAV_FORMAT SUM
2.008 - 21,11
2.006 - 299,60
2.007 - 307,11
- CAISSE DE 6 28,96
- CAISSE de 6 36,58
- Bouteille 562,28
Cette clause admet la syntaxe suivante:
SELECT year(entreele), MONTH(entreele), cav_format, sum(prxactuel)
FROM ma_cave join vins using(vin_code)
GROUP BY GROUPING SETS ( (year(entreele) , cav_format) ,
(year(entreele) , month(entreele))
)
|
YEAR MONTH CAV_FORMAT SUM
2.006 - CAISSE de 6 20,82
2.008 - Bouteille 5,35
2.007 - Bouteille 278,15
2.008 - CAISSE de 6 15,76
2.006 - Bouteille 278,78
2.007 - CAISSE DE 6 28,96
2.007 8 - 15,59
2.006 7 - 14,40
2.008 3 - 15,76
2.007 3 - 20,82
2.007 9 - 155,48
2.007 2 - 12,19
2.007 1 - 28,96
2.006 11 - 35,00
2.006 4 - 20,82
2.007 6 - 74,07
2.006 9 - 229,38
2.008 5 - 5,35
|
SELECT year(entreele) , cav_format, sum(prxactuel)
FROM ma_cave join vins using(vin_code)
GROUP BY ROLLUP (year(entreele) , cav_format)
affiche le total par année/format, puis par année, puis le total général
YEAR CAV_FORMAT SUM
2.006 Bouteille 278,78
2.006 CAISSE de 6 20,82
2.006 - 299,60
2.007 Bouteille 278,15
2.007 CAISSE DE 6 28,96
2.007 - 307,11
2.008 Bouteille 5,35
2.008 CAISSE de 6 15,76
2.008 - 21,11
- - 627,82
Vous pourriez compléter le select par un ORDER BY
|
SELECT year(entreele) , cav_format, sum(prxactuel)
FROM ma_cave join vins using(vin_code)
GROUP BY CUBE (year(entreele) , cav_format)
affiche tous les totaux de toutes les combinaisons (un cube, donc !)
YEAR CAV_FORMAT SUM
2.006 Bouteille 278,78
2.006 CAISSE de 6 20,82
2.006 - 299,60
2.007 Bouteille 278,15
2.007 CAISSE DE 6 28,96
2.007 - 307,11
2.008 Bouteille 5,35
2.008 CAISSE de 6 15,76
2.008 - 21,11
- - 627,82
- CAISSE DE 6 28,96
- CAISSE de 6 36,58
- Bouteille 562,28
|
Enfin, vous pouvez utiliser la syntaxe suivante
SELECT year(entreele) , month(entreele), cav_format, sum(prxactuel)
FROM ma_cave join vins using(vin_code)
GROUP BY GROUPING SETS(
ROLLUP(year(cav_entreele) , cav_format) ,
ROLLUP(year(cav_entreele), month(cav_entreele))
)
affiche des totaux par année/format, contenant des sous totaux par année
et un total général(ROLLUP), puis la même chose pour le couple année/mois
YEAR MONTH CAV_FORMAT SUM
2.006 - Bouteille 278,78
2.006 - CAISSE de 6 20,82
2.006 - - 299,60
2.007 - Bouteille 278,15
2.007 - CAISSE DE 6 28,96
2.007 - - 307,11
2.008 - Bouteille 5,35
2.008 - CAISSE de 6 15,76
2.008 - - 21,11
- - - 627,82
|
2.006 4 - 20,82
2.006 7 - 14,40
2.006 9 - 229,38
2.006 11 - 35,00
2.006 - - 299,60
2.007 1 - 28,96
2.007 2 - 12,19
2.007 3 - 20,82
2.007 6 - 74,07
2.007 8 - 15,59
2.007 9 - 155,48
2.007 - - 307,11
2.008 3 - 15,76
2.008 5 - 5,35
2.008 - - 21,11
- - - 627,82
Liste des nouvelles fonctions
GROUPING(col) indique si la ligne en cours est une ligne de regroupement
concernant cette colonne (information utile en programmation)
|
Exemple
SELECT year(entreele) , cav_format, sum(prxactuel) ,
GROUPING(cav_format)
FROM ma_cave join vins using(vin_code)
GROUP BY CUBE (year(entreele) , cav_format)
YEAR CAV_FORMAT SUM GROUPING
2.006 Bouteille 278,78 0
2.006 CAISSE de 6 20,82 0
2.006 - 299,60 1
2.007 Bouteille 278,15 0
2.007 CAISSE DE 6 28,96 0
2.007 - 307,11 1
2.008 Bouteille 5,35 0
2.008 CAISSE de 6 15,76 0
2.008 - 21,11 1
- - 627,82 1
- CAISSE DE 6 28,96 0
- CAISSE de 6 36,58 0
- Bouteille 562,28 0
|
Autres fonctions
toutes les fonctions manipulant des DECFLOAT utilisent
SET CURRENT DECFLOAT ROUNDING MODE pour la gestion des arrondis
- ROUND_CEILING : arrondi à +1 si positif
- ROUND_DOWN : arrondi inférieur (troncature)
- ROUND_FLOOR : arrondi à -1 si négatif
- ROUND_HALF_DOWN : arrondi comptable (si >0,5)
- ROUND_HALF_EVEN : arrondi au chiffre pair supérieur
- ROUND_HALF_UP : arrondi comptable (si >=0,5)
- ROUND_DOWN : arrondi supérieur (+1)
DECFLOAT() convertit une données au nouveau format DECFLOAT
COMPARE_DECFLOAT() compare deux DECFLOAT (gestion des valeurs indéfinies)
QUANTIZE(D, E) produit un DECFLOAT avec D comme partie décimale et
E comme exposant (puissance de 10)
NORMALIZE_DECFLOAT affiche un DECFLOAT à sa forme la plus simple
ex : NORMALIZE_DECFLOAT(DECFLOAT(-120)) = -1.2E+2
|
TOTALORDER(a1 , a2) retourne -1 si a1<a2, 0 si a1=a2 , 1 si a1>a2
suivant le critère de tri qui suit:
-NAN<-SNAN<-INFINITY<-0.10<-0.100<-0<0<0.100<0.10<INFINITY<SNAN<NAN
DECFLOAT_SORTKEY() convertit un DECFLOAT en zone numérique pouvant
être un critère de tri (ORDER BY)
RID() retourne le N° de rang au format integer [ RRN = DEC(15,0) ]
ASCII() retourne la valeur ASCII d'un caractère [ ASCII('E') = 69 ]
CHR() retourne le caractère dont on fournit la valeur ASCII
MONTH_BETWEEN(d1, d2) retourne le nombre de mois (avec décimales sur 31j)
qui sépare les dates d1 et d2.
VALUES(months_between('25/09/08' , '31/08/08'))=> 0,806451612903225
VALUES(months_between('30/09/08' , '31/08/08'))=> 1,000000000000000
|
TIMESTAMP_FORMAT('chaine' , 'format')
produit un Timestamp à partir de "chaîne" qui est un timestamp au
format caractère, suivant le format indiqué en deuxième argument.
Ex : TIMESTAMP_FORMAT('99/02/05' , 'RR/MM/DD')=1999-02-05-00.00.00.000000
Dans format vous pouvez utiliser les séparateurs suivants :
- . / , ' : ; et (espace)
et les code suivants (les zéros de gauche seront facultatifs)
DD les jours MM les mois YY l'années sur 2
YYYY l'année sur 4 RR l'année ajustée (00 à 49>2000, 50 à 99>1900)
HH24 l'heure (24h) SS les secondes NNNNNN les micro-secondes
Chaque code est facultatif, SQL assumant l'année en cours pour YYYY
le mois en cours pour MM, 01 pour DD, 0 pour le reste.
|
ROUND_TIMESTAMP(A,B) et TRUNC_TIMESTAMP(A,B) fournissent un nouveau
timestamp de A, arrondi ou tronqué au format indiqué par B.
voici les formats et la valeur retour à partir de 1999-06-28-12.48.37.543210
+------------+------+--------------------------+--------------------------+
+ Code + ? + ROUND_TIMESTAMP + TRUNC_TIMESTAMP +
+------------+------+--------------------------+--------------------------+
| CC ou SCC |siecle|2000-01-01.00.00.00.000000|1900-01-01.00.00.00.000000|
| | | | |
| YYYY/SYYYY | | | |
| YEAR/SYEAR |Année |1999-01-01.00.00.00.000000|1999-01-01.00.00.00.000000|
|YYY ouYY ouY| | (arrondi au 1 juillet) | |
| | | | |
| Q |trim. |1999-07-01.00.00.00.000000|1999-04-01.00.00..00.00000|
| | | (arrondi au 16 du mois | |
| | | du mi-trimestre) | |
| | | | |
| MONTH/MON |mois |1999-07-01.00.00.00;000000|1999-06-01.00.00.00;000000|
| MM ou RM | | (arrondi au 16 du mois) | |
+-------------------------------------------------------------------------+
|
0
retour à partir du Lundi 1999-06-28-12.48.37.54321 (01/01 = Vendredi) 0
+------------+------+--------------------------+--------------------------+
+ Code + ? + ROUND_TIMESTAMP + TRUNC_TIMESTAMP +
+------------+------+--------------------------+--------------------------+
| WW |semain|1999-07-02.00.00.00.000000|1999-06-25.00.00.00.000000|
| | | (nb de 7j + arrondi +- 4j| |
| | | depuis le 1er janvier) | |
| | | | |
| W |semain|1999-06-29.00.00.00.000000|1999-06-22.00.00.00.000000|
| | | (nb de 7j + arrondi +- 4j| |
| | | depuis le 1er du mois) | |
| | | | |
| DDD ou DD | jour |1999-06-29.00.00.00.000000|1999-06-28.00.00..00.00000|
| ou J | | (arrondi à 12 heures) | |
| | | | |
| | | | |
| DAY ou DY | jour |1999-06-27.00.00.00.000000|1999-06-27.00.00.00;000000|
| ou D | | (arrondi au dimanche) | |
+-------------------------------------------------------------------------+
|
0
retour à partir du Lundi 1999-06-28-12.48.37.54321 0
+------------+------+--------------------------+--------------------------+
+ Code + ? + ROUND_TIMESTAMP + TRUNC_TIMESTAMP +
+------------+------+--------------------------+--------------------------+
| HH ou HH12 | heure|1999-06-28.13.00.00.000000|1999-06-28.12.00.00.000000|
| ou HH24 | | (arrondi à 30 Mn) | |
| | | | |
| MI |minute|1999-06-28.12.49.00.000000|1999-06-28.12.48.00.000000|
| | | (arrondi à 30 S) | |
| | | | |
| SS |second|1999-06-28.12.48.37.000000|1999-06-28.12.48.38.000000|
| | | (arrondi à 0,5 seconde) | |
| | | | |
+-------------------------------------------------------------------------+
Les codes peuvent être saisis en minuscules.
ENCRYPT_AES() encrypte suivant le format AES (en plus de RC2 et TDES)
|
Les registres suivants sont nouveaux :
ROW CHANGE TIMESTAMP FOR nom : retourne le timestamp de la dernière
modification, uniquement pour les tables possédant une zone
"FOR EACH ROW ON UPDATE AS ROW CHANGE TIMESTAMP", uniquement
Exemple : Select * from clients
where ROW CHANGE TIMESTAMP FOR clients = current date - 1 day
ROW CHANGE TOKEN FOR nom : retourne un "token" des modifications
indiquant si une ligne a été modififée, ou 0 si elle n'a pas été
modifiée.
Exemple : update clients set nom = 'nouveau nom' where nocli = :nocli
and ROW CHANGE TOKEN FOR clients = :save_token
--permet de savoir si le client a été modifié depuis lecture
|
Les registres suivants sont nouveaux :
CURRENT DEBUG MODE : mode debug lors de la création de la routine
CURRENT DECFLOAT ROUNDING MODE : ( voir le type DECFLOAT )
ainsi que les registres "clients" suivants :
CURRENT CLIENT_ACCTNG : chaîne de connexion
CURRENT CLIENT_USERID : profil utilisateur client
CURRENT CLIENT_APPLNAME : nom de l'application cliente
CURRENT CLIENT_PROGRAMID : nom du programme de connexion
CURRENT CLIENT_WRKSTNNAME: nom du poste client
Ils sont à renseigner par l'application lors de la connexion
(sauf le PROGRAMMID, qui le sera souvent en automatique)
|
OleDB :
Set connect = New ADODB.Connection
connect.Open
"Provider=IBMDASQL; Data Source=MONAS; Application Name=pgm;"
Java :
Class.forName("com.ibm.as400.access.AS400JDBCDriver");
Connection connect=Drivermanager.getConnection("jdbc:as400//MONAS/BDVIN;"
,"profil","motdepasse");
connect.setClientInfo("ApplicationName" , "pgm");
connect.setClientInfo("ClientUser" , "moi");
Cli (php) :
Utilisez SQLSetConnectAttr
|
Autres :
appellez la procédure cataloguée WLM_SET_CLIENT_INFO, qui fonctionne dans
tous les cas, avec les paramètres suivants :
1/ CLIENT_USERID VARCHAR(255)
2/ CLIENT_WRKSTNNAME VARCHAR(255)
1/ CLIENT_APPLNAME VARCHAR(255)
1/ CLIENT_ACCTSTR VARCHAR(255)
1/ CLIENT_PROGRAMMID VARCHAR(255)
vous devez la retrouver dans SYSPROCS et la liste des paramètres
dans SYSPARMS
Programmation :
Les noms de Curseur et d'instructions (PREPARE) passent à 128 c.
|
Lors de l'appel à une procédure cataloguée vous pouvez transmettre
maintenant des variables avec la variable indicateur associée
C/EXEC SQL
+ CALL PROC1 (:P1:P1ind , :P2:P2ind)
C/EXEC SQL
P1ind et P2ind étant des variable binaires (en RPG "5i 0") contenant
0 si la variable est non nulle, -1 si elle l'est.
La procédure cataloguée doit recevoir (par ex. par "*ENTRY PLIST" en RPG)
1/ P1
2/ P2
3/ un tableau (ici à 2 postes) de variables binaires
les variables indicateurs peuvent être modifiées par la procédure
qui indique ainsi si elle retourne (-1) ou non (0) la valeur nulle.
|
Une Sous Sélection (SELECT imbriqué) admet maintenant :
ORDER BY et FETCH FIRST x ROWS ONLY , permettant de retrouver
plus facilement le premier ou le dernier d'un groupe
On pouvait le faire avant avec " where xxx = (SELECT MAX(xxx) from ...)
Il est possible de placer les sources SQL dans des fichiers stream,
à la compilation (CRTSQLRPGI), et au lancement d'un script (RUNSQLSTM)
avec le nouveau paramètre SRCSTMF()
pour les scripts vous pouvez aussi, si vous continuez à travailler
avec des membres source, en préciser la largeur
Exemples :
RUNSQLSTM SRCSTMF('/home/cm/monscript.txt')
RUNSQLSTM SRCFILE(QTXTSRC) SRCMBR(MONSCRIPT) MARGINS(120)
|
les schémas (bibliothèques) SYSTOOLS et SYSIBMADM sont nouveaux, vides (??)
et réservés à IBM !
les fichiers suivants du catalogues SQL sont nouveaux :
statistiques sur l'activité des tables
SYSCOLUMNSTAT SYSPACKAGESTAT
SYSINDEXSTAT SYSPROGRAMSTAT
SYSMQTSTAT SYSTABLEINDEXSTAT
SYSTABLESTAT
notion de partition, c'est à dire de membre
SYSPARTITIONSTAT SYSPARTITIONINDEXES
SYSPARTITIONMQT SYSPARTITIONINDEXSTAT
et enfin, ce dernier avec une ligne par bibliothèque
SYSSCHEMAS
|
Nouveautés du compilateur RPG-IV en V6R10
Nouveautés V6R10 du compilateur RPG-IV
-Support complet du multithreading avec THREAD(*CONCURRENT) en specif H
Chaque thread possède une copie des variables déclarées STATIC
certaines variables peuvent être partagées par STATIC(*ALLTHREAD)
le mot-clé SERIALIZE sur une procédure demande à ce que cette dernière
ne puisse être lancée que par un thread à la fois.
-support plus souple d'UNICODE
une conversion implicite est réalisée lors des affectations(EVAL/EVALR)
et des tests (IF, DOW/DOU, ...) entre une variable EBCDIC et une
variable UNICODE, sans utilisation des fonctions %CHAR() et %UCS2()
cette conversion implicite était déjà réalisée par MOVE/MOVEL
|
-la taille maxi des constantes passe à 16380 (la moitié pour UNICODE)
-la taille maxi des variables caractères passe de 65535 à 16 Mo !!
le nombre d'occurences d'une DS ou d'un tableau n'est plus limité
qu'à la taille globale maxi de 16.773.104 octets ( 16 Mo )
le mot-clé LEN peut être utilisé à la place des colonnes 33/39 (lg)
sur la définition d'une zone ou d'une DS (spécif D)
le mot-clé VARYING admet un paramètre (2 ou 4) indiquant le nombre d'octets
utilisés pour stocker la lg.Sans paramètre, le compilateur calcul.
la fonction %ADDR() admet un deuxième argument *DATA quand elle s'applique
sur une zone VARYING, demandant à ce que l'adresse pointe sur la partie
significative de la variable (et non les octets binaires de début)
|
-La taille du module ou du programme objet peut être réduite par
OPTION(*NOUNREF) en spécif H ou sur la commande de compilation.
les variables non utilisées ne sont plus répercutées dans l'objet.
la valeur par défaut est *UNREF (même résultat qu'aujourd'hui)
-les informations concernant le pgm et ces paramètres pouvaient déja
être notées dans un fichier stream au format PCML par PGMINFO(*PCML)
ce fichier PCML était utile pour des apppels depuis JAVA, mais aussi
pour la création de services WEB.
la création de services web étant facilité en V6R10 (nouveau serveur
d'application intégré) ces informations peuvent maintenant être stockées
dans l'objet PGMINFO(*PCML:*MODULE) dans un fichier IFS
PGMINFO(*PCML : *STMF) ou dans les deux PGMINFO(*PCML : *ALL)
|
- la spécif F possède de nouveaux paramètres
sur les versions précédentes, il était possible d'indiquer un nom réel
de fichier à utiliser à l'exécution, par EXTFILE, évitant des OVRDBF
EXTDESC() permettant d'indiquer le nom du fichier à la compilation
-> cela permet de compiler avec un fichier qui n'est pas dans *LIBL
EXTDESC('BDVIN1/VINS')
-> cela permet de manipuler un fichier ayant le même nom de format
puisque que c'est le nom en spécif F qui est utilisé
le paramètre EXTFILE(), admet maintenant EXTFILE(*EXTDESC) demandant
à ce que le nom réel à l'exécution soit celui de EXTDESC
- les définitions de fichier (F) et de DS (D) admettent un nouveau mot-clé
TEMPLATE indiquant que cette déclaration n'est qu'un modèle.
- EXTNAME , mot-clé lié à une DS externe (spécif D), admet maintenant
un litéral, éventuellement qualifié
|
Les ordres d'entrée/sortie READ,CHAIN,UPDATE,etc, admettaient un nom
de DS résultat dans le cadre d'un fichier décrit en interne.
la DS résultat est maintenant admise aussi pour un fichier externe
et EXFMT possède aussi cette possibilité.
-un nom de format peut être qualifié par QUALIFIED en spécif F
le nom de format doit être manipulé sous la forme "fichier.format"
(dans notre exemple il s'agit d'une TABLE SQL, d'où le même nom)
il n'a plus à être unique : il n'y a plus de spécif I et O pour ce fichier
==> les I/O doivent utiliser une DS :
Fvins IF E DISK QUALIFIED
Din DS LIKEREC(vins.vins)
/free
read vins IN;
dsply IN.VIN_NOM;
return;
/end-free
|
le mot-clé MAIN en spécif H permet d'indiquer une sous procédure en tant
que procédure principale.Cette dernière ne peut être lancée que par CALL.
le source ne contient donc plus que des procédures, la procédure déclarée
MAIN doit contenir EXTPGM('le-nom-du-pgm') sur le proptotype
il n'y a plus de cycle GAP , il faut donc fermer explicitement par CLOSE
les fichiers (le compilateur signale une erreur RNF7534 de gravité 10)
source TESTMAIN
h MAIN(ENTREE)
D ENTREE PR EXTPGM('TESTMAIN')
D 5A
P ENTREE B
D PI
D parm1 5A
/free
dsply parm1;
/end-free
P ENTREE E
|
les spécif F sont admises maintenant locales (à l'intérieur des procédures)
entre la spécif P et les D.
les entrées/sorties doivent être réalisées à l'aide de DS.
les fichiers sont fermés automatiquement à la fin de la procédure, sauf à
utiliser STATIC, qui garde les fichier ouverts et les variables chargées.
|
P lecture B
Fvins IF E DISK QUALIFIED
D PI 50
D code 10I 0 CONST
Din DS LIKEREC(vins.vins)
/free
chain code vins IN;
return IN.VIN_NOM;
/end-free
P lecture E
Cela permet de mieux gérer les fonctions dans des programmes de service
retournant des valeurs basées sur des données venant de fichier lus.
LIKEFILE , définition d'un fichier comme un autre
1/ en spécif F, on récupère tous les attributs de la déclaration de
fichier d'origine, type d'ouverture, utilisation de la clé, etc...
Attention cela implique QUALIFIED (implicite), donc DS résultat.
Fvins IF E DISK
Fproducteur LIKEFILE(vins)
|
2/ le mot-clé LIKEFILE peut être indiqué en spécif D, sur un paramètre
de procédure, afin de passer un fichier en tant que paramètre
le paramètre transmis doit lui même être un fichier déclaré par EXTFILE
par un pgm appellant RPG ! (pas de COBOL, ni de C)
le fichier référencé peut être déclaré avec TEMPLATE, afin de n'être
qu'un modèle.il doit préciser le facteur de groupage par BLOCK()
en effet, le facteur de groupage est déterminé par le GAP en fonction
des ordres d'entrée/sortie réalisés par le programme.
ici le fichier n'étant q'un modèle, le GAP ne peux pas décider du
type de groupage, il faut préciser :
BLOCK(*YES) le groupage a lieu sauf pour READE/READP/READPE
BLOCK(*NO) les enregistrements sont lus un par un.
l'ouverture de fichier est passée par référence, elle est commune aux 2.
par exemple l'appelant peut lire et l'appelé mettre à jour.
|
IBMi, Integreted Web Application Serveur V7.1
Il s'agit du nouveau serveur d'application intégré à l'OS
pour distribuer les applications Java., remplaçant Tomcat, qui n'est
plus fourni avec la V6.
Ce serveur support JSF, JSP, servlets et services web, et implique
peu de ressources et d'administration, c'est le même que celui utilisé par
DB2 WebQUERY, il est basé sur OSGI .
et vous trouverez plus d'infos à http://www-03.ibm.com/systems/i/software/iws/
Lancez le serveur d'administration HTTP, si ce n'est déjà fait
par STRTCPSVR *HTTP HTTPSVR(*ADMIN)
Puis loggez vous sur http://<votreas400>:2001/HTTPAdmin/


Il permet d' installez WebAccess , pour cela
vous devez :
- Avoir installé le produit 5761XH2, bien sûr.
- Etre au niveau 1 du groupe PTF SF99115 (au niveau 13 de SF99114 si vous êtes
en V5R40)
- passez la commande suivante (sous QSH, c'est plus simple)
- CD /QIBM/ProdData/Access/web2/install
- cfgaccweb2 -appsvrtype *INTAPPSVR -instance INTAPPSVR
(ou le nom que vous lui avez donné)
Ce qui doit vous afficher :
Configuring System i Access for web
Preparing to perform the configuration changes
System i Access for web command has completed
- donc, installer l'application Webaccess (cela peut être
long)

Si la commande cfgaccweb2 affiche des erreurs, voyez
- /QIBM/UserData/Access/Web2/logs/cmds.log
- /QIBM/UserData/Access/Web2/logs/cmdstrace.log
- Sinon, essayez l'URL suivante http://<votreas400:10041>/webaccess/iWAHome
, qui doit vous afficher

C''est lui qui se cache derrière DB2 Web QUERY
Enfin, il permet d'exposer des programmes ILE existant, en tant que services
WEB.
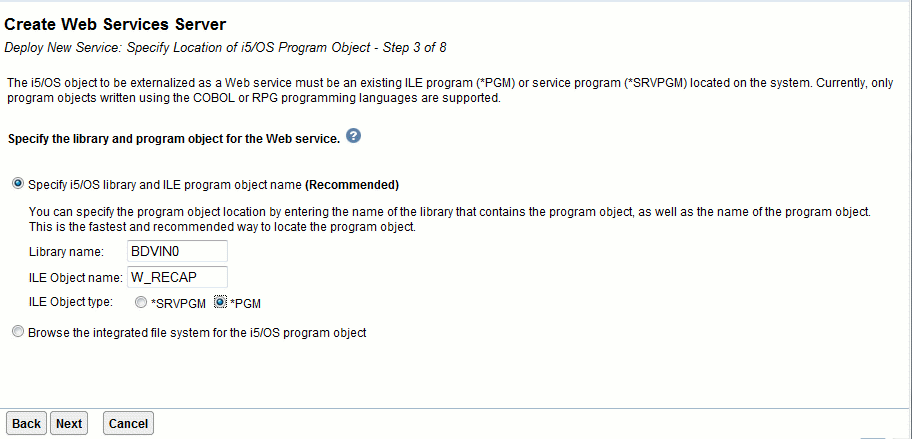
Ici un programme W_RECAP de BDVIN0, attendant une zone PR_CODE, et retournant
une DS nommée INFOCENTRE,
ce pgm a été compilé avec PGMINFO(*PCML
: *MODULE) , en V5R40 il faut SI27065 pour
activer cette option.
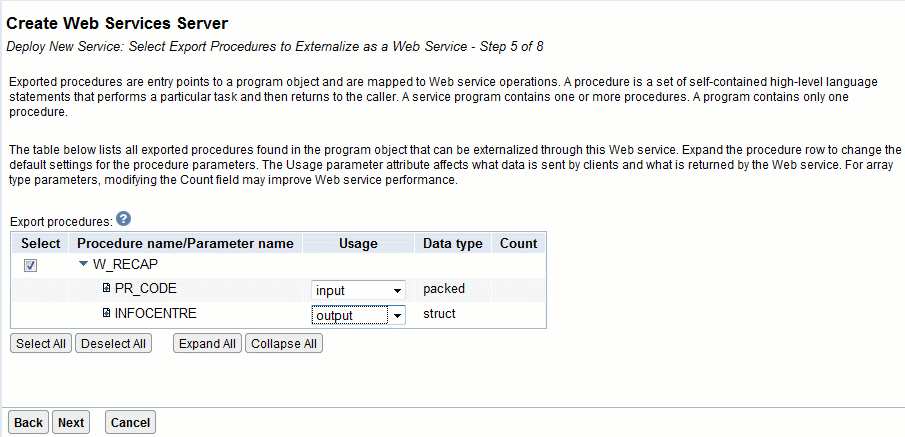
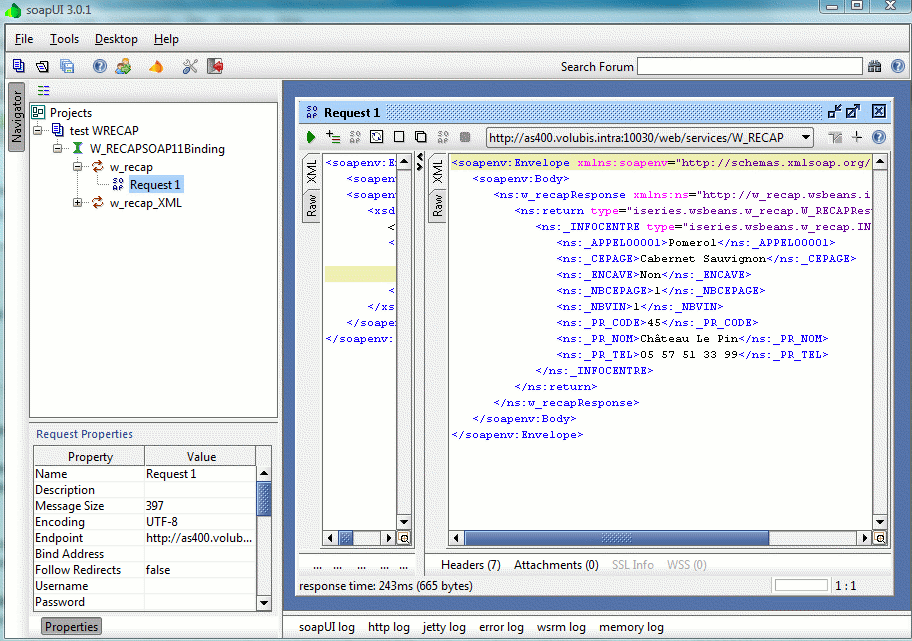
Résultat :
Dernier point, Iseries navigator
Commençons par celles liées à Client Access, mais concernant
aussi iSeries Navigator:
le produit est livré sous forme de fichier .MSI installable par
Windows Intaller
il est livré sous 3 versions:
- Windows 32 bits
- Windows 64 bits / processeur AMD
- Windows 64 bits / processeur Itanium
Appliquer SI28716 sur le système en V5R40 avant d'installer la V6
Appliquer le dernier service pack sur le serveur avant d'installer le client
V6
Venons en à iSeries Navigator lui-même.
il intègre certaines nouveautés liées à I5/OS
(ou IBMi) Version 6
- Nouvelles valeurs systèmes de gestion des mots de passe entre
autre.
- Nouvelles informations liées aux profils utilisateurs, dont le
paramètre PWDCHGBLK pour empêcher un utilisateur de modifier
son mot de passe
- Support des adresses IP V6
- Support de SSL par les serveurs SMTP et POP
- Support du serveur OSPF, nommé OMPROUTED
Il propose une gestion des unités de bandes virtuelles, dans configuration
et maintenance
- création d'une unité de bande virtuelle
- gestion des catalogues d'image
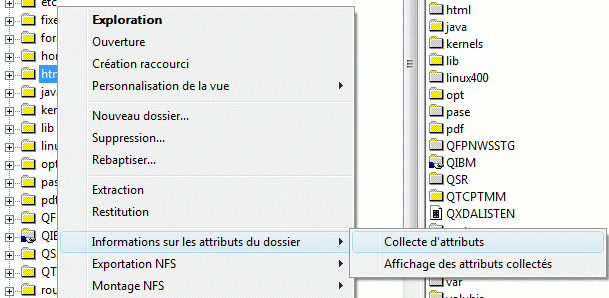
Enfin, la gestions des fichiers intégrés propose maintenant.
- le montage NFS client (voir l'image ci-dessous, Montage NFS)
- la récupération de données détaillées
concernant un répertoire (collecte d'attributs)
Mais le plus gros des nouveautés concerne la base de données,
particulièrement tout ce qui a trait à la surveillances des
performances SQL
Rappel de la V5R40
- Le centre de santé affiche des informations sur vos bases en % des
maximas DB2
- Les moniteurs SQL propose des sélections (bibliothèque, tables,
durée) au lancement et à l'affichage
- Consultation du cache des plans d'accès avec le même affichage
que les moniteurs
- -> ce dernier suggérant les index manquant en temps
réel
(assistant de gestion des index)
- La liste des index indique quand un index a été utilisé,
même implicitement, pour la dernière fois
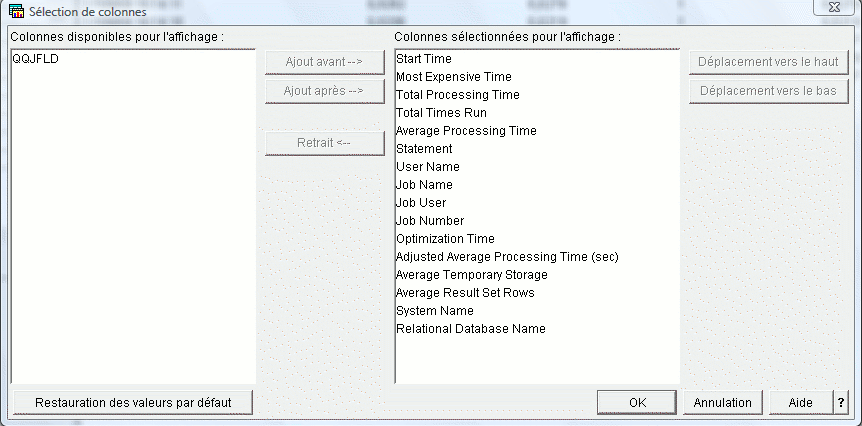
• Moniteurs
L'affichage d'un moniteur ou du cache des plans d'accès propose le
choix des colonnes
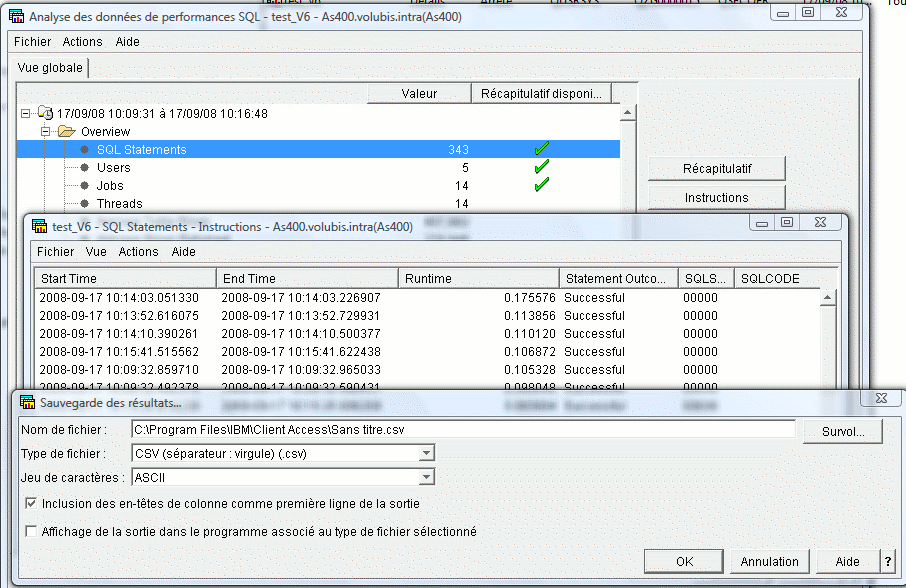
et, sur un affichage récapitulatif, à l'affichage des instructions
(Analyse, puis clic droit sur une ligne / instructions),
l'option fichier propose, maintenant, une sauvegarde
de la liste des instructions SQL
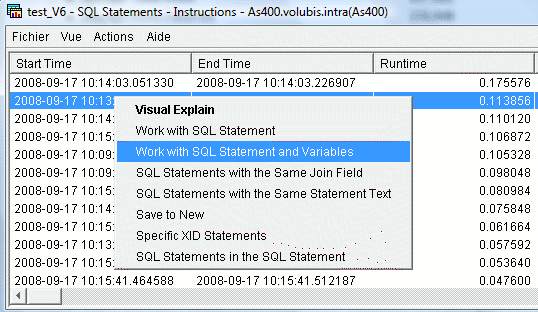
Sur le même affichage, vous pouvez maintenant, placer la
requête SQL dans le gestionnaire de script avec les valeurs des
variables, et non les marqueurs SQL (?)
Enfin, vous pouvez comparer deux moniteurs 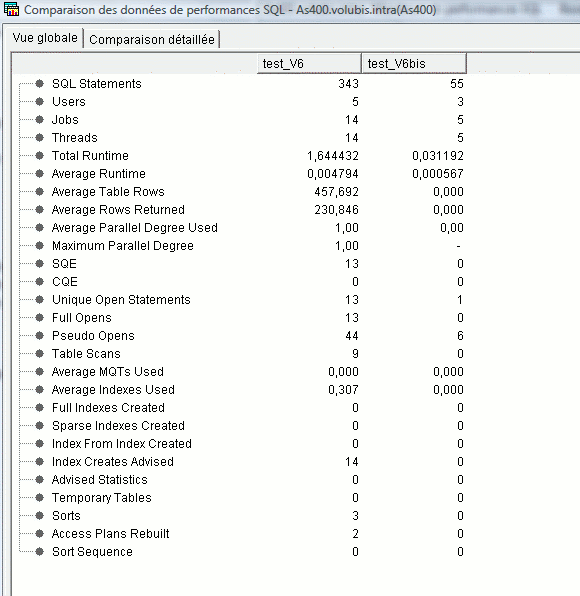
• Cache des plans d'accès
- la taille peut être ajustée par CALL QQQOOOCACH PARM('R:1024')
[tapez CALL QQQOOOCACH
pour avoir une liste des paramètres.]
ou par iSeries Navigator V6 (Mémoire cache de plan SQL/propriétés)
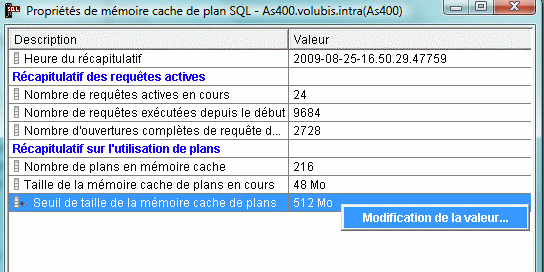
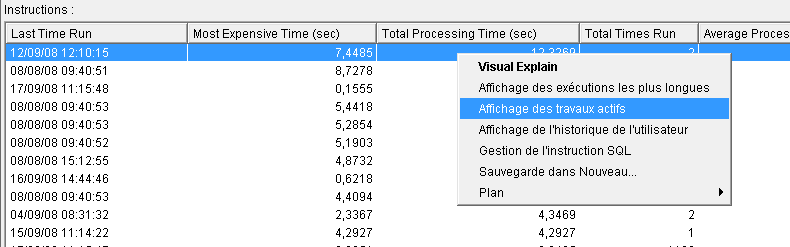
Les possibilités d'affichage sur une instruction ont été étendues
:
- l'affichage des instructions les plus longues est limité aux 500
premières
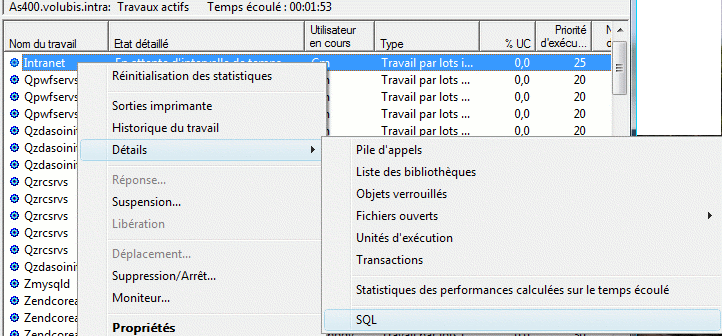
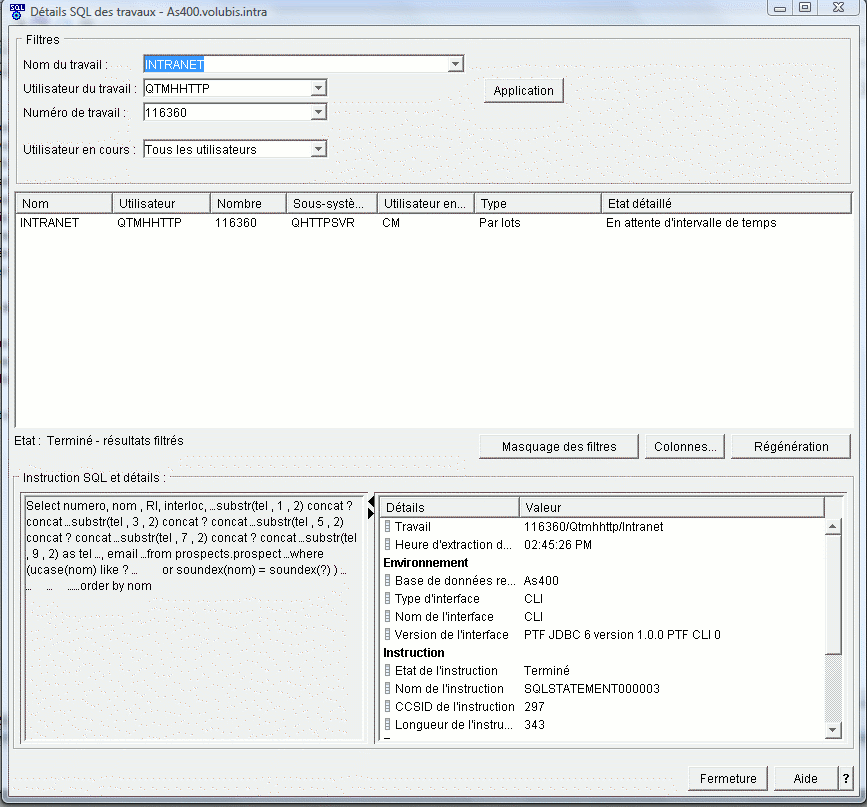
- vous pouvez demandez la liste des travaux utilisant actuellement cette
instruction
- et la liste des utilisateurs ayant utilisé cette instruction
(historique de l'utilisateur)
Vous pouviez déjà en V5R40 sauvegarder le cache sous forme d'images
instantanées :
par l'interface graphique sous Images instantanées de mémoire
cache de plan SQL
par la procédure cataloguée DUMP_PLAN_CACHE , qui en V6 est automatiquement enregistrée
au même endroit.
Quand le cache est plein il est automatiquement épuré, en
V6 il est possible de placer un moniteur sur cet événement
afin de le sauvegarder en fichier avant
• Gestion des index
Vous pouvez demander la liste des index pour un bibliothèque entière
(et non table par table) en cliquant sur Tables
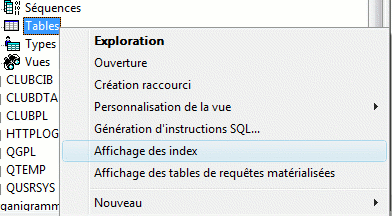
Vous remarquerez aussi l'affichage des MQT, la génération d'instruction
SQL (toujours pour toute la bibliothèque)
cette liste des index affiche les informations nouvelles en V6
-> clé basée sur une expression 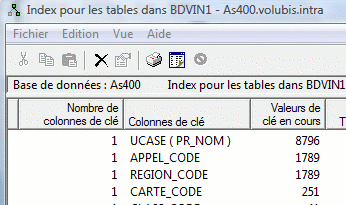
-> clause WHERE de sélection de lignes 
Bien sur, la fenêtre de création d'index a été modifiée
dans ce sens

et 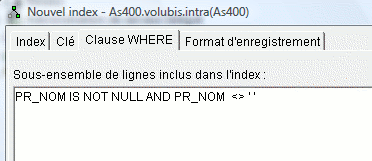
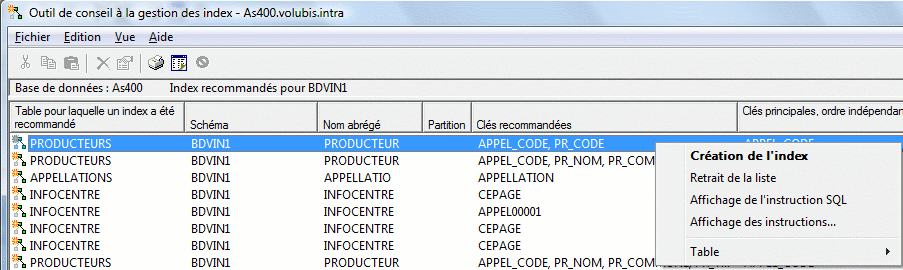
l'assistant de gestion d'index (qui affiche les index suggérés,
globalement, pour une bibliothèque ou pour une table) a été amélioré :
- Affichage de l'instruction SQL est nouveau en V6
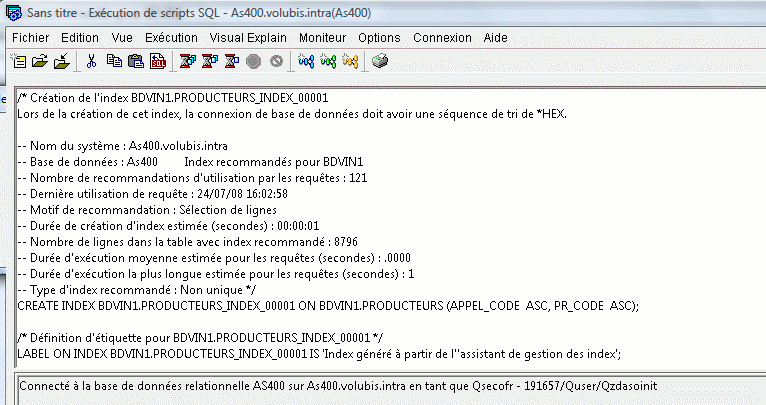
- ainsi que l'accès direct aux instructions qui ont provoqué cette
suggestion (dans le cache)
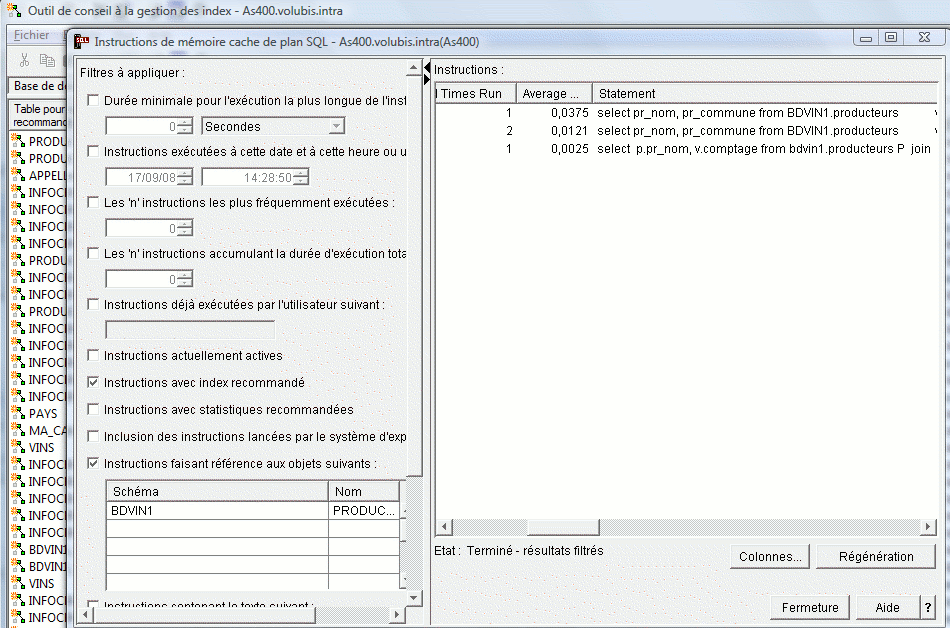
- l'assistant affiche aussi le nombre de fois ou un index a été suggéré et,
s'il a été créé automatiquement (MTI), le nombre
de fois ou il a été utilisé
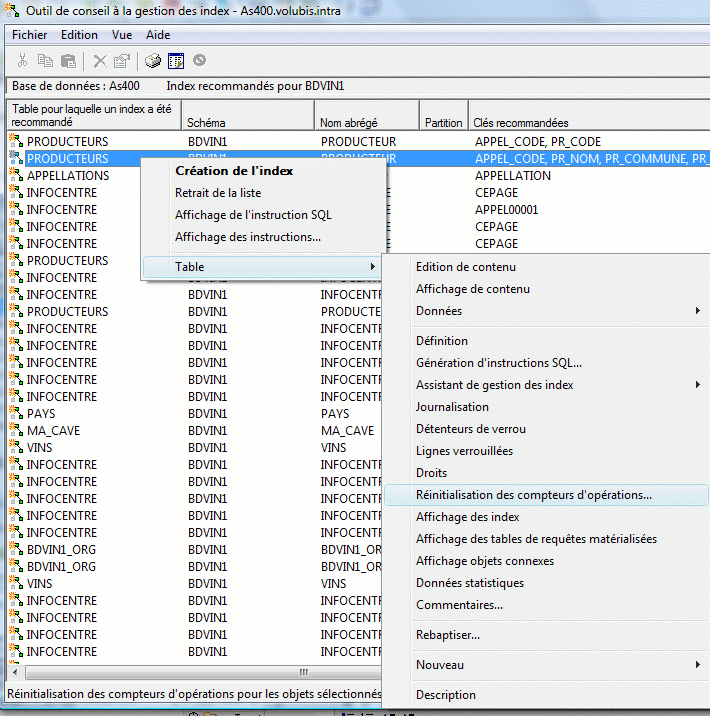
Ce compteur peut-être réinitialisé pour la table, par
le menu contextuel suivant :
L'affichage de l'instruction SQL pour un travail a été revue
:
Pour terminer le gestionnaire de scripts subit aussi des changements
1/ une option ALLOW SAVE RESULT, permet la sauvegarde des enregistrements extraits:
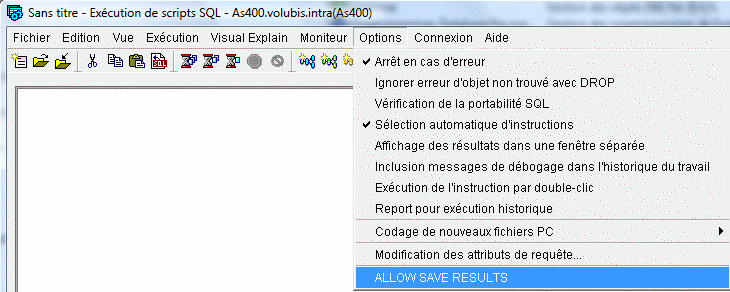
ensuite, avec un clic droit sur les lignes affichées :
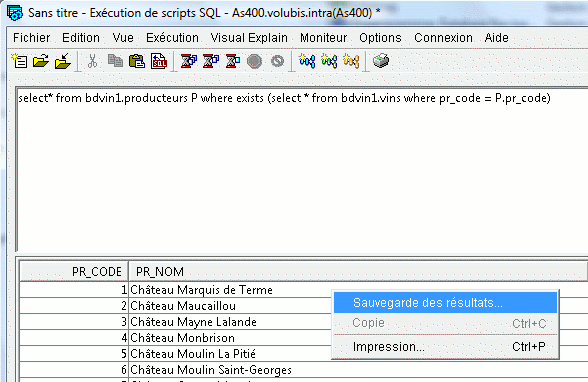
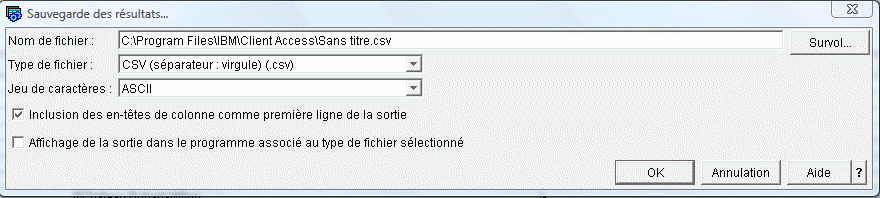
Les formats admis, sont :
- txt
- csv
- Lotus 123
- tableur Excel
Les paramètres de connexion (JDBC) peuvent être modifiés
temporairement ou définitivement

et proposent maintenant l'affichage des COLHDG plutôt que les noms de
zone en entête de colonne

La(les) requêtes(s) peuvent être sauvegardée(s) sur le serveur
(fichier physique ou IFS)
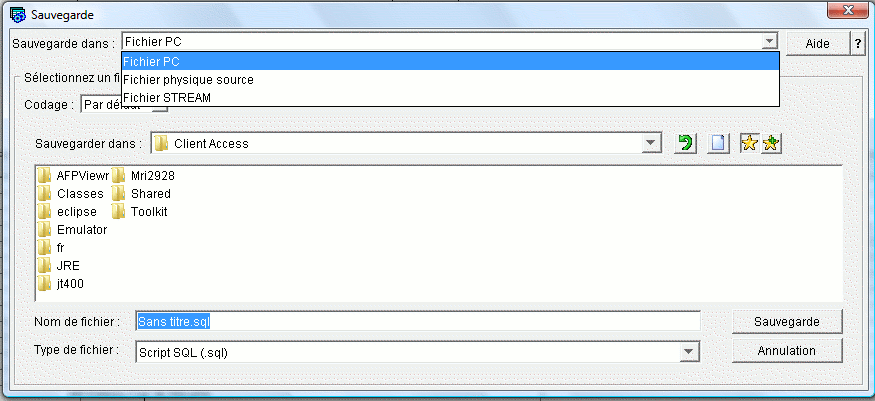
Ce qui accompagne très bien le nouveau paramètre SRCSTMF de
la commande RUNSQLSTM
Enfin, Visual Explain  peut être
lancé et réactualisé, pendant l'exécution, les
informations ayant bougé sont surlignées.
peut être
lancé et réactualisé, pendant l'exécution, les
informations ayant bougé sont surlignées.
Enfin, le probable successeur "IBM navigator Director", pointe le bout de
son nez...
il tourne en tant qu'application avec le serveur d'Administration, démarré par
STRTCPSVR
SERVER(*HTTP) HTTPSVR(*ADMIN)
Il utilise le port 2005, et toute requête vers la racine sur le port
2001 est redirigée vers :
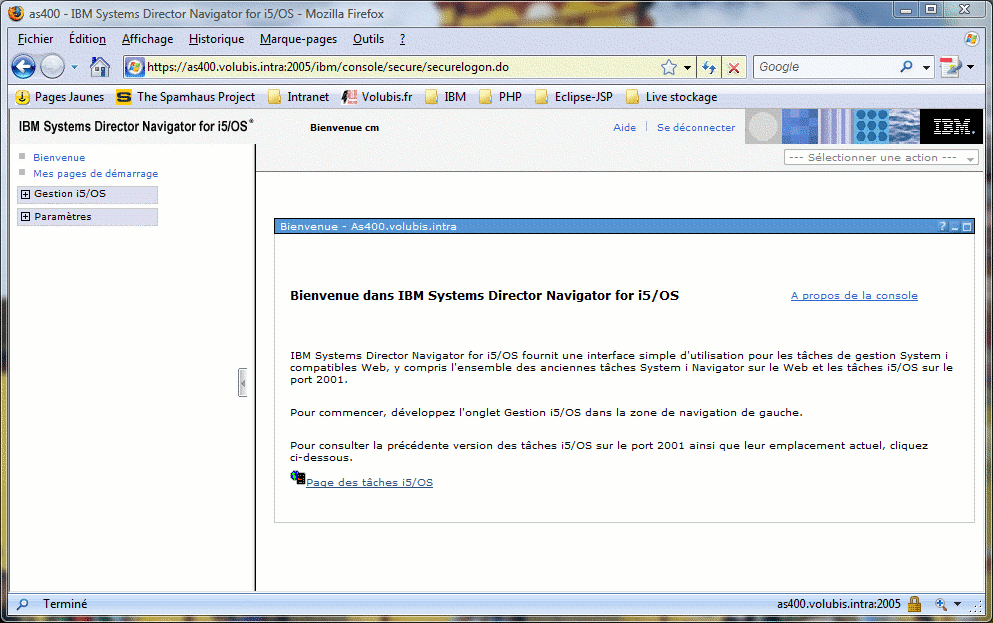
ET propose les options suivantes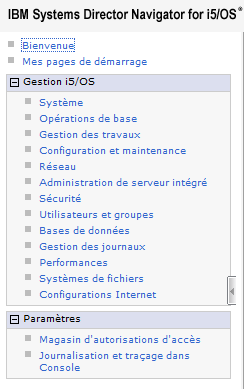
©AF400