Tables matérialisées (ou MQT)
Cela permet de définir une table en lui associant une requête initiale
-la table peut être réactualisée avec le résultat de la requête
à tout moment.
- En cours de version V5R30 (DataBase group niveau 4) et avec les PTF
suivantes : SI17164, SI17609, SI17610, SI17611, SI17637
et MF34848, I5/OS est capable d'utiliser une MQT
(Materialized Query Table) dans un but d'optimisation
syntaxe :
CREATE SUMMARY TABLE -(nom)---AS (Select SQL complet [ORDER BY admis])->
!--DATA INITIALLY IMMEDIATE---!
>---! !--REFRESH DEFERRED-->
!--DATA INITIALLY DEFERRED ---!
!---ENABLED QUERY OPTIMIZATION--!
>--- MAINTAINED BY USER--! !---.
!---DISABLE QUERY OPTIMIZATION--!
Attention, seul SQE sait utiliser les tables matérialisées, il ne faut donc
pas que votre requête utilise des options traitées uniquement par CQE
(comme LIKE en V5R30 , l'utilisation d'index dérivés, etc ...)
il faut une requête - portant sur un seule table ou avec INNER JOIN
- sans UNION
- sans User Defined Function (UDF) ni UDT
- sans sous sélection
- sans certaines fonctions du langage comme
SOUNDEX, DIFFERENCE, DECRYPT_xx, INSERT, REPEAT,
REPLACE, DAYNAME, MONTHNAME.
L'utilisation des tables matérialisée est une option, ce n'est pas le
standard, il faut le demander en plaçant dans QAQQINI :
MATERIALIZED_QUERY_TABLE_USAGE = *ALL
MATERIALIZED_QUERY_TABLE_REFRESH_AGE = *ANY
(ou une durée sous la forme d'un timestamp AAAAMMJJHHMMSS)
il faut d'autre part que la TABLE a été crée avec ENABLED QUERY OPTIMIZATION
et que le paramètre ALWCPYDTA soit à *OPTIMIZE (par défaut sous ODBC/JDBC)
Le rafraîchissement de la table matérialisée est à votre charge (ordre REFRESH)
Quelques restrictions
- Si vous demandez dans votre requête, une colonne ne se trouvant pas dans
la
MQT, cette dernière ne peut pas être utilisée.
- une seule table MQT par requête
!
- C'est a vous de faire le rapport en entre les avantages
- gain de temps lors de la requête, optimisation transparente.
- et les inconvénients
- temps de rafraîchissement des données (la MQT n'est PAS maintenue par le système)
- affichage de données obsolètes, suivant le dernier REFRESH.
(sauf à utiliser MATERIALIZED_QUERY_TABLE_REFRESH_AGE)
|




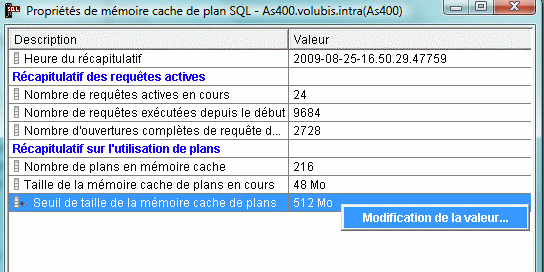
 et dans le fichier de sortie de STRDBMON avec le code QQRID=3006
- QQRCOD contient B2 et QQC21 =2 pour un Cold I/O to Warm I/O
- QQRCOD contient B2 et QQC21 =3 pour un First I/O to ALL I/O
et dans le fichier de sortie de STRDBMON avec le code QQRID=3006
- QQRCOD contient B2 et QQC21 =2 pour un Cold I/O to Warm I/O
- QQRCOD contient B2 et QQC21 =3 pour un First I/O to ALL I/O