Trois éléments peuvent intervenir dans la gestion des performances
pour mesurer ces éléments vous avez à votre
disposition quelques outils :
-> commandes natives d'analyse de
l'activité:
-> Des outils graphiques intégrés à Operation Navigator :
• DSPLOG, récupération du temps consommé :
DSPLOG (F4 vous offre le choix de la date) , puis aide sur le message de fin de travail (CPF1164)
Complément d'informations sur message |
• ENFIN, Nouveauté bien pratique en V6 : ANZCMDPFR
Vous lancez cette commande avec le paramètre CMD() contenant UNE commande
ou le paramètre CMDFILE() faisant référence à un source contenant plusieurs commandes
et vous obtenez (dans la JOBLOG) des informations de performance dans le texte d'aide
du message CPCC711 ANZCMDPFR command completed successfully
Cause . . . . . : The request to measure the performance of a single CL
command or a set of CL commands has completed.
Total Time Used . . . . . . . . . . . : 2,476
Total CPU time Used . . . . . . . . . : 1,383
Synchronous Database Reads . . . . . : 2
Synchronous Non Database Reads . . . : 106
Synchronous Database Writes . . . . . : 0
Synchronous Non Database Writes . . . : 129
Asynchronous Database Reads . . . . . : 40
Asynchronous Non Database Reads . . . : 1
etc...
Attention,
si vous soumettez plusieurs fois le même traitement, particulièrement réalisant des actions base de données, à partir du deuxième, les temps seront forcement meilleurs par le fait que le système va faire du cache sur les derniers fichiers traités. Il faut soumettre dans un pool mémoire particulier (voir la définition ci-dessous) et passer la commande CLRPOOL
WRKSYSSTS (gestion de la mémoire)
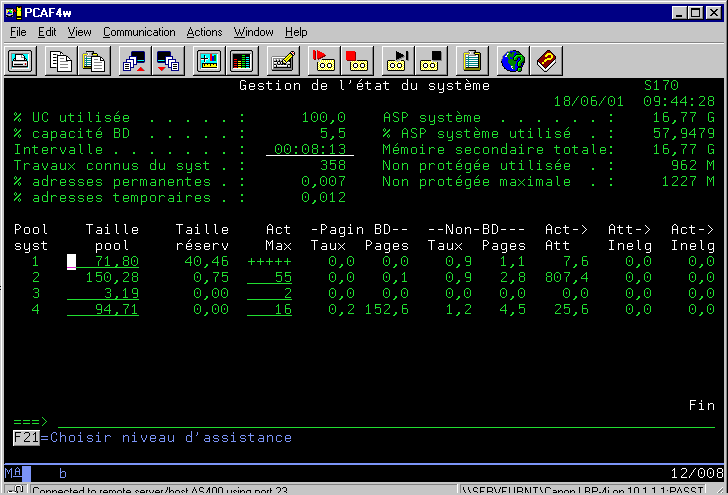
ATTENTION, tous ces écrans vous offrent des moyennes, il faut
visualiser des données qui ont au moins 2 minutes .
pour lire le WRKSYSSTS, vous devez comprendre la notion de pool
mémoire,
il s'agit d'un découpage logique de la mémoire qui sera
dédié a un ensemble cohérent de travaux. Cela est
réalisé par le jeu des sous systèmes.
Chaque sous système renvoi à un pool mémoire
spécifique , la plupart des pools acceptant plusieurs sous
systèmes.
(la commande WRKSBS vous montre cela).
un sous système représente donc un moyen de regrouper
entre eux des travaux cohérents :
Sauf à faire des choix particuliers, vous verrez (au moins) les pools suivants :
- La taille des pools se gère par WRKSHRPOOL (ou par
modification du sous système)
par exemple, on peut créer un sous système AGENCE,
réservé aux
travaux venant des agences distantes.
CRTSBSD AGENCE POOLS( (1 *BASE) (2 *INTERACT) ) TEXT('gestion des agences')
|
Ici, le sous système est découpé en deux
parties (nommées aussi pool de sous système),
- la première redirigeant vers *BASE (2) , probablement
destinée aux petit traitement batch
(liste utilisateur, query, ...)
- la deuxième vers *INTERACT (4) pour les sessions 5250.
CRTSBSD AGENCE POOLS( (1 *BASE) (2 1000 2) ) TEXT('gestion des agences')
|
Ici, le sous système est découpé en deux
parties , la première redirigeant toujours vers *BASE , mais la
deuxième implémentant un découpage de la
mémoire dédié (on parle de pool privé), qui sera
numéroté automatiquement lors du démarrage,
probablement le pool n° 5.
Ce pool mémoire a un niveau d'activité
de 2 : nombre de job ayant le droit de demander de
l'UC (prétention à la CPU)
revenons à la commande WRKSYSSTS
le taux de pagination global (BD + NON BD) sur le pool machine doit être < à 10 !
Si vous êtes en ajustement automatique, passez la commande WHRSHRPOOL
et faites F11
Gestion des pools partagés Système: AS400 Taille de la mémoire principale (Mo) . . . : 3054,28 Indiquez vos modifications (si admises), puis appuyez sur ENTREE. |
Pour les autres pools, historiquement, il devait être < à 20-25 (maxi).
Pour une machine récente, calculez plutôt la pagination maximale comme suit :
| Interactif | 5 + (T x 0,5) |
| Batch | 10 + (T x 2,0) |
la documentation V5R40 indique comme base de calcul rapide, par pool :
c*p, ou c est le pourcentage de CPU utilisé
p est le nombre de processeurs
de la partitionpar exemple
1 processeur à 36 % = 36 de taux de pagination maxi
1,8 processeur (LPAR) utilisé à 80% = 144
fixer à *CALC, les options de pagination (par F11) si vous avez au moins 100 Mo
( sur les pools BATCH, au moins)
- la colonne activité maxi, indique elle , le nombre de job chargés
en mémoire en même temps.
(un job ayant besoin de traitement, mais qui doit attendre car ce nombre est
atteint, est dit inéligible)
le nombre de job Attente/inéligible doit représenter 10 % maximum du nombre Actif/attente (ne demandant rien => attente écran ou I/O disque)
la colonne Actif/inéligible représente les jobs que le système a rendu inéligible de manière forcée (tranche de temps maxi consommée)
WRKACTJOB (travaux consommateur et temps de réponse)
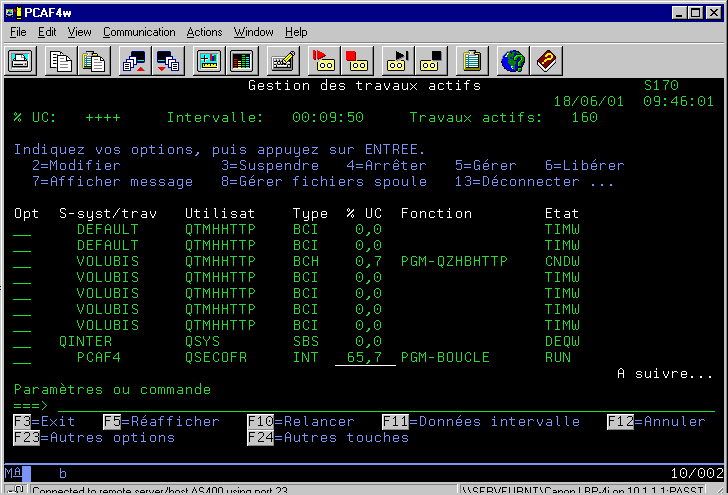
Remarquons :
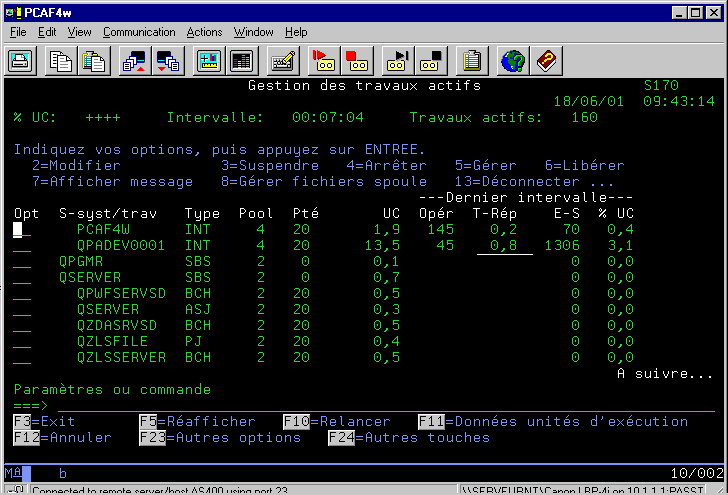
ces écrans permettent de retrouver les travaux les plus consommateurs ou les plus mauvais temps de réponse.
Touches de fonctions :
si le nombre de travaux actifs est élevé, vérifiez que la taille de la table des travaux est cohérente. En effet, si elle est sous-dimensionnée (QTOTJOB) elle est incrémenté (QADLTOTJ) au besoin pour vérifier tout cela DSPJOBTBL (F1 pour retrouver les valeurs systèmes concernées)
|
Tables de travaux AS400 |
WRKDSKSTS (gestion des disques)
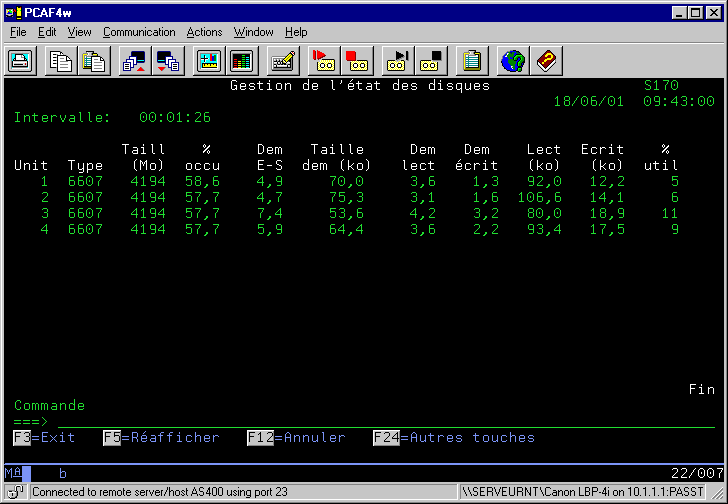
cet écran montre le taux d'occupation des disques
(l'idéal est un taux de 75 % au maximum)
ainsi que l'activité des bras (% util).Une activité au
delà de 50% indique des disques très occupés.
si la répartition n'est pas linéaire (achat de nouveaux
disques, par exemple), passez la commande STRASPBAL
TYPE(*CAPACITY)
SI certains disques sont plus utilisés que d'autres (achat de disque suivi de l'installation de logiciel)
TRCASPBAL *ON
(analyse de l'activité base de données sur une plage horaire significative)
TRCASPBAL *OFF
Puis
STRASPBAL *USAGE
Le système réparti sur l'ensemble de l'ASP un « panachage » de fichiers très utilisés et de fichiers peu utilisés
WRKSYSACT (Commande de Performance Tools, intégrée à l'OS en V6.1)
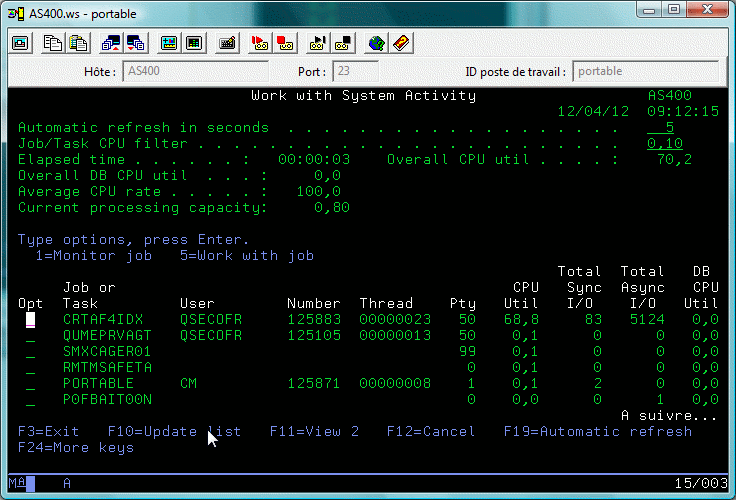
Cette commande possède deux particularités :
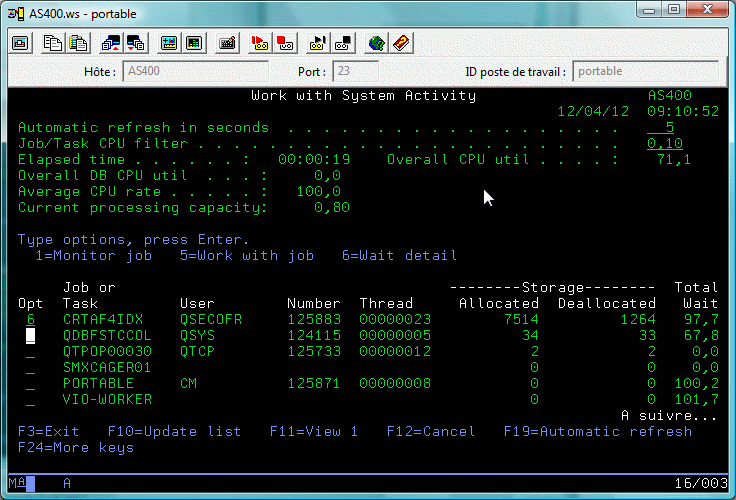
En effet les temps de traitement sont répartis de la manière suivante :
| Traitement CPU | Attente CPU |
Longue attente | Attente bloquante |
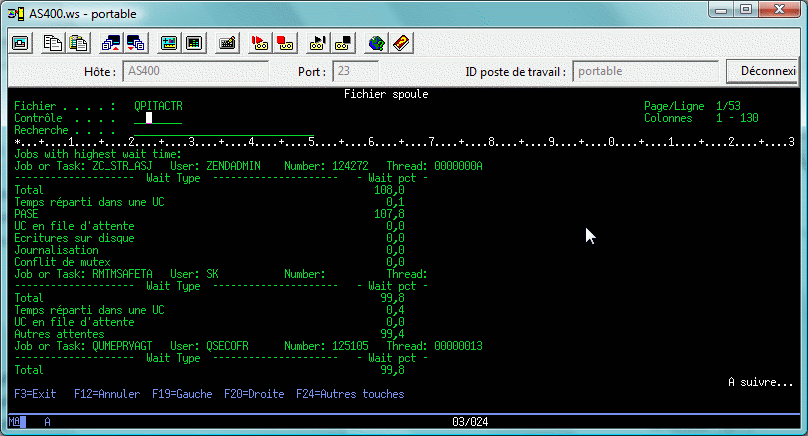
Les différents types d'attente :
| Lecture disque | Écriture disque | Verrouillage | fonction journal |
Il peut alors être intéressant de détailler ces mécanismes d'attente
(l'OS en interne en distingue 268, qui ont ici été regroupés en 32 groupes)
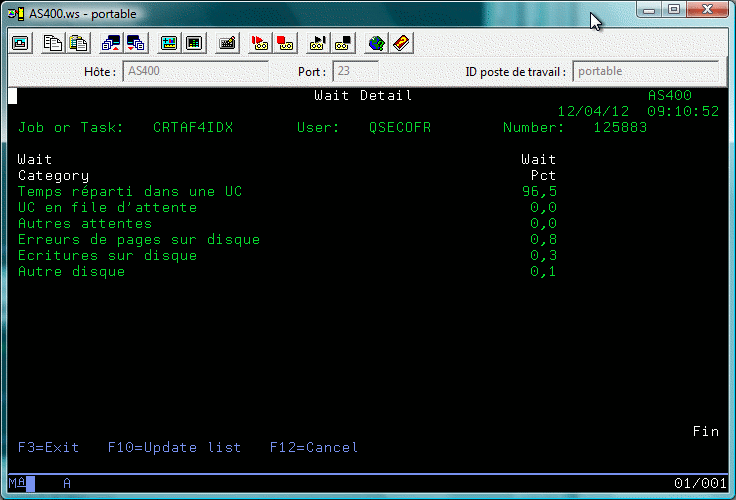
Détail de l'option 6 sur un travail ou une tâche
Enfin la commande WRKSYSACT possède un paramètre OUTPUT() qui renseigné à *FILE ou *BOTH provoque une écriture dans QAITMON
la commande PRTCATRPT (de 57xxPT1) imprime des statistiques basées sur ce fichier
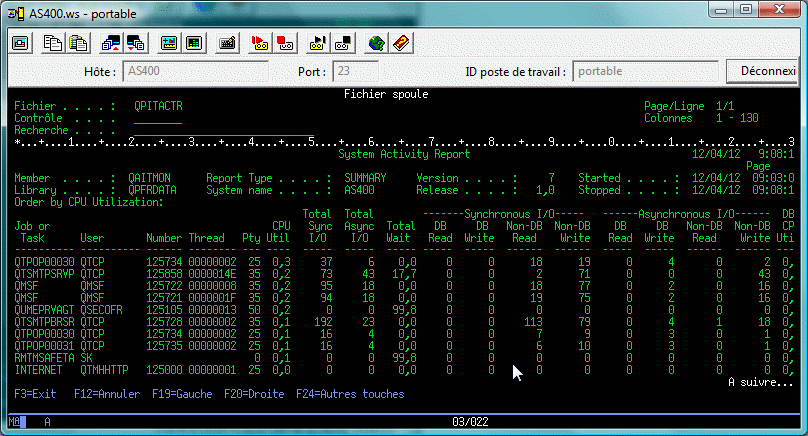
ou nous retrouvons les différents types d'attente pour les travaux en ayant le plus.
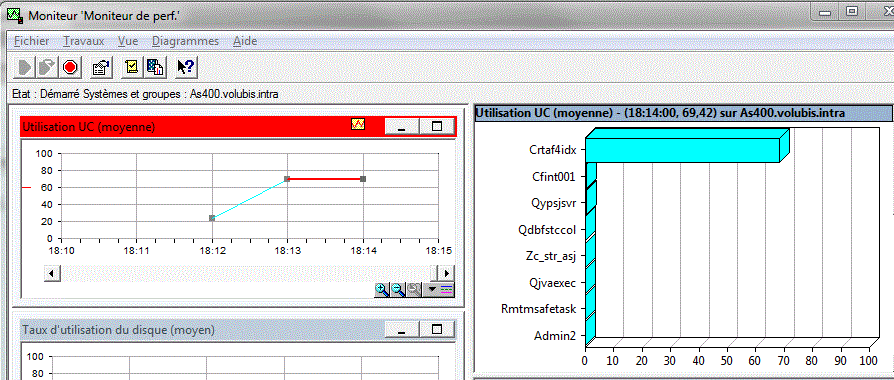
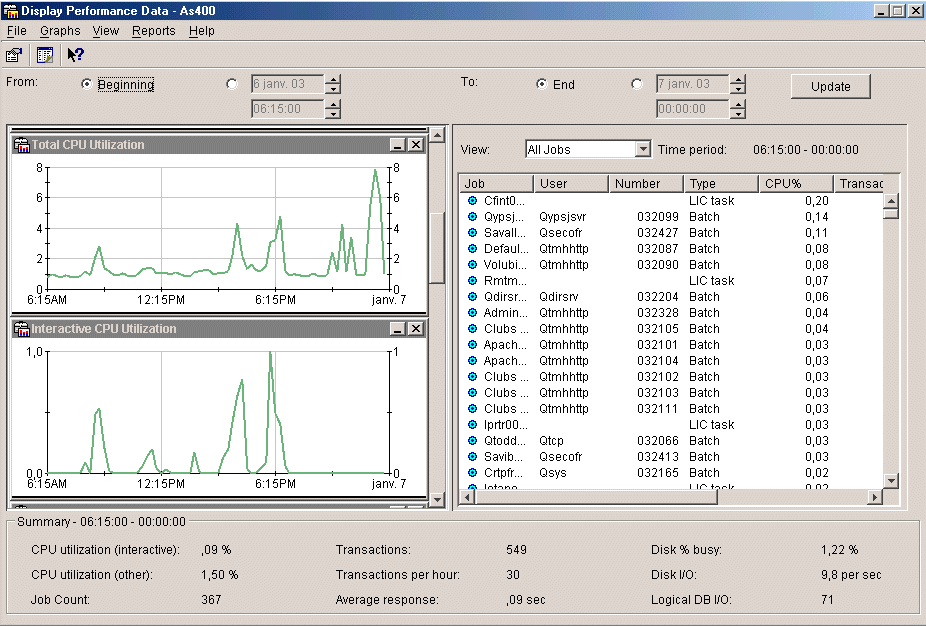
Un moniteur est une analyse graphique et temps réel des
performances:
Indiquez : - la liste des événement à analyser
vous remarquerez :
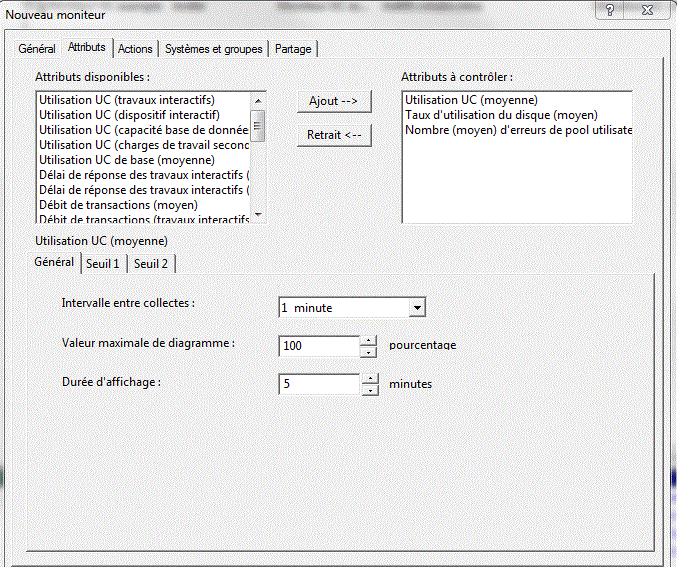
vous pouvez préciser :
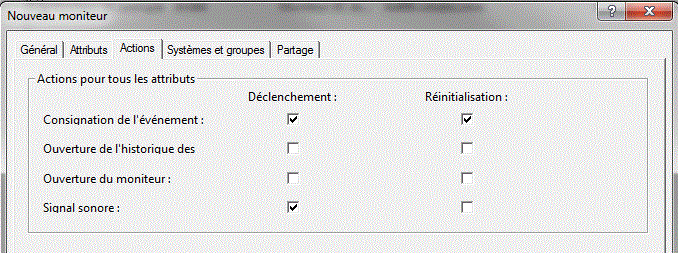
pour gérer les moniteurs, revenez à la fenêtre précédente :
le bouton vert (représentant une flèche) permet de lancer l'analyse.
le bouton rouge(représentant un panneau) permet de l'arrêter.
Quand vous démarrez le moniteur, le système vous demande les systèmes
ou groupes de systèmes, devant participer à cette analyse
| Le démarrage effectué, doucle-cliquez sur la ligne pour voir l'analyse. l'affichage est alors découpé comme suit : ######################################################################### # # si vous pointez une mesure, # # .................................... # vous verrez ici le détail # # : : # sous forme d'histogramme # # : vos différents graphes : # # # : (autant que d'événements : # # # : à analyser) : # # # :..................................: ################################ # # # # .................................... # en cliquant sur une ligne # # : : # de l'histogramme ci-dessus # # : sur chaque graphe, un point : # vous verrez le détail du # # : représente une prise de mesure : # job dans cette fenêtre. # # : : # # # :..................................: # # # # # ######################################################################### |

| 3/ Définition de seuils. --------------------- il s'agit de définir des actions à entreprendre automatiquement lorsque certaines valeurs sont rencontrées vous pouvez définir deux seuils : 1/ seuil critique 2/ seuil inacceptable ou tout autre organisation à votre choix. un seuil atteint est montré graphiquement par une ligne rouge il vous faut définir, quand considérer un retour à la normale. par exemple : seuil critique = CPU utilisée à plus de 90 % (réinitialisé à moins de 70) seuil dangereux = CPU utilisée à plus de 97 % (réinitialisé à moins de 91) on peut associer des commandes IBM i à un seuil atteint. et vous pouvez utiliser des variables de substitution :
|
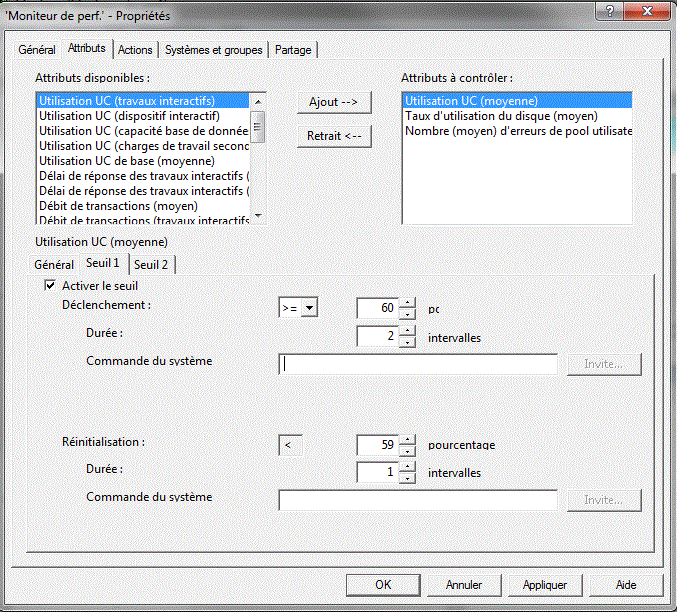
Vous voyez ici, l'influence des seuils (sur une machine très "confortable")
les moniteurs de performance changent en V5R10:

V5R10 , Collectes de
performances
Il s'agit de collecter des données de
performances afin d'offrir une vision d'ensemble de l'état de la
machine.
cela était possible avant grâce aux commandes
STRPFRMON/ENDPFRMON qui disparaissent en V5 au profit de cette nouvelle
notion de collecte.
Les collectes écrivent dans un seul objet :
*MGTCOL (avant il y avait jusqu'à 30 fichiers différents)
Vous pouvez choisir d'écrire dans des fichiers en fin de
traitement ou en temps réel.
Les collectes sont plus précises, les points de collectes plus
rapprochés (attention aux volumes !!! )
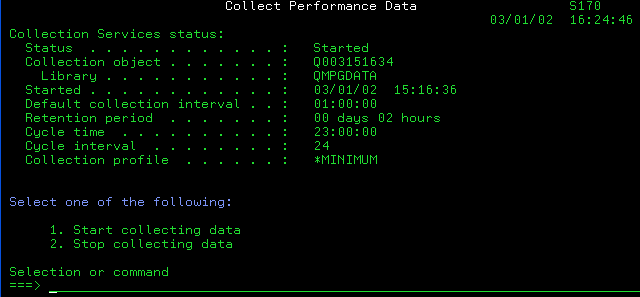
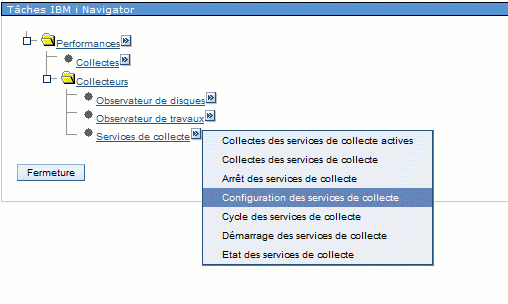
Pour lancer une collecte :
·Vous pouvez utiliser l'option 2 du menu PERFORM. Si une collecte est déja active, on vous affiche l'écran suivant:
·Ou lancer les commandes STRPFRCOL / ENDPFRCOL
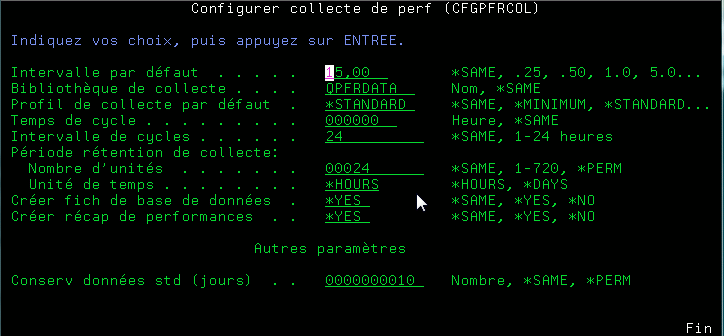
le paramétrage peux se faire grâce à CFGPFRCOL
les commandes suivantes sont fournies
· utilisez Operation navigator qui permet de consulter les
données sous forme de graphiques sans écrire dans aucun
fichier.
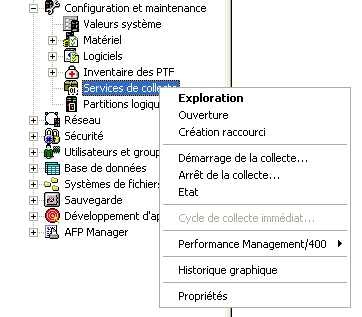 (depuis Op.navigator)
(depuis Op.navigator)
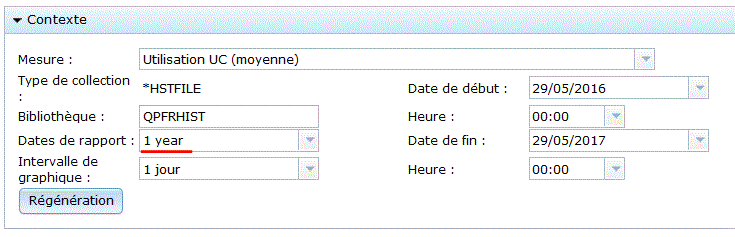
il vous faudra indiquer ensuite:
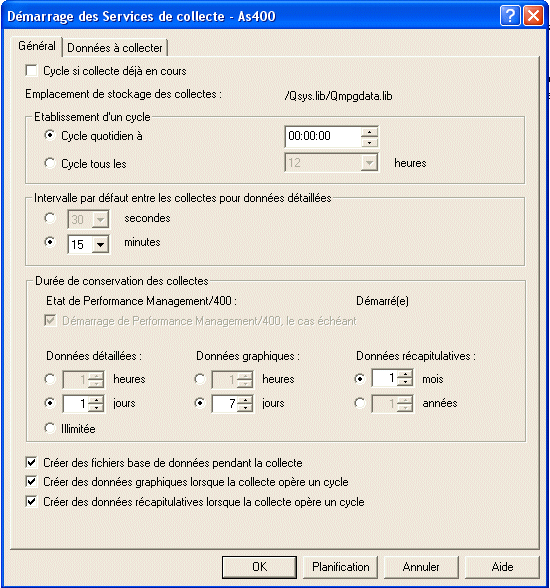
Si vous souhaitez établir un nouveau cycle au cas ou une collecte serait déja en cours de traitement.
rappel: les informations sont stockées dans
un seul objet : *MGTCOL (et non plus dans des fichiers ),
établir un cycle, c'est changer d'objet .
|
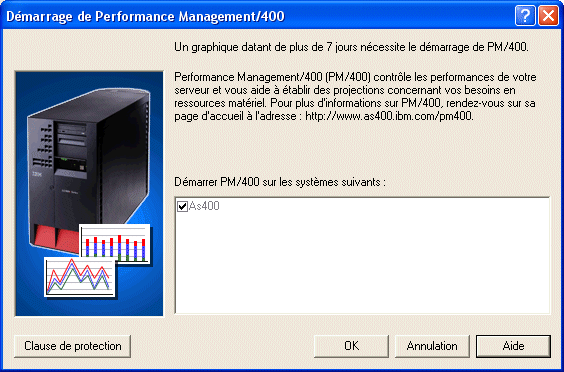
Puis indiquez les données à collecter, ou utilisez un
profil (modèle des données à collecter et des
intervalles associés).
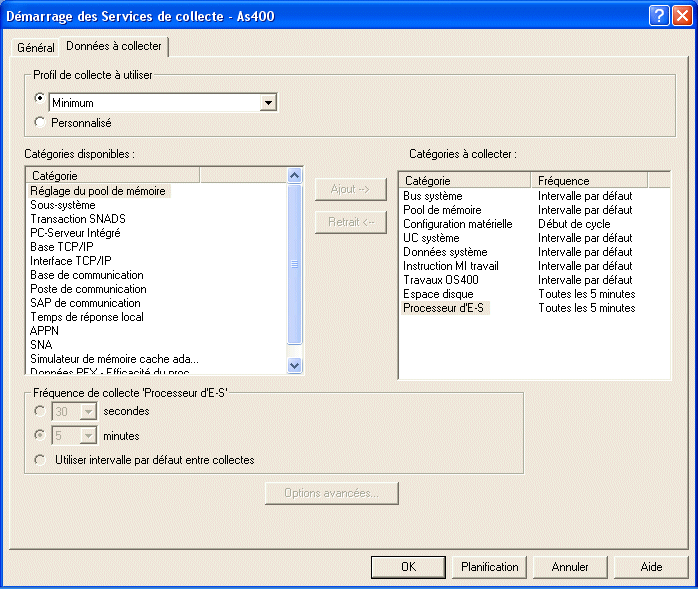
Vous pourrez aussi le faire avec IBM Navigator Director (voir plus loin dans ce cours)
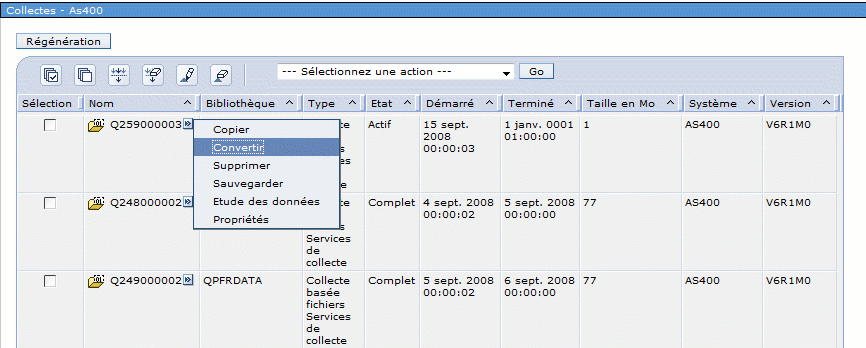
Une fois la collecte lancée ou terminée (Attention aux
volumes, il faut plus de 10 Mo pour une journée)
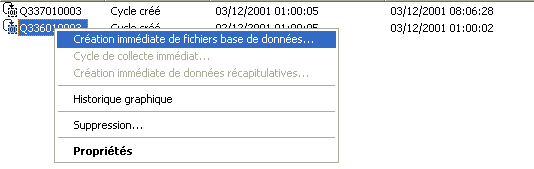
ici, un cycle a été créé à 23h00

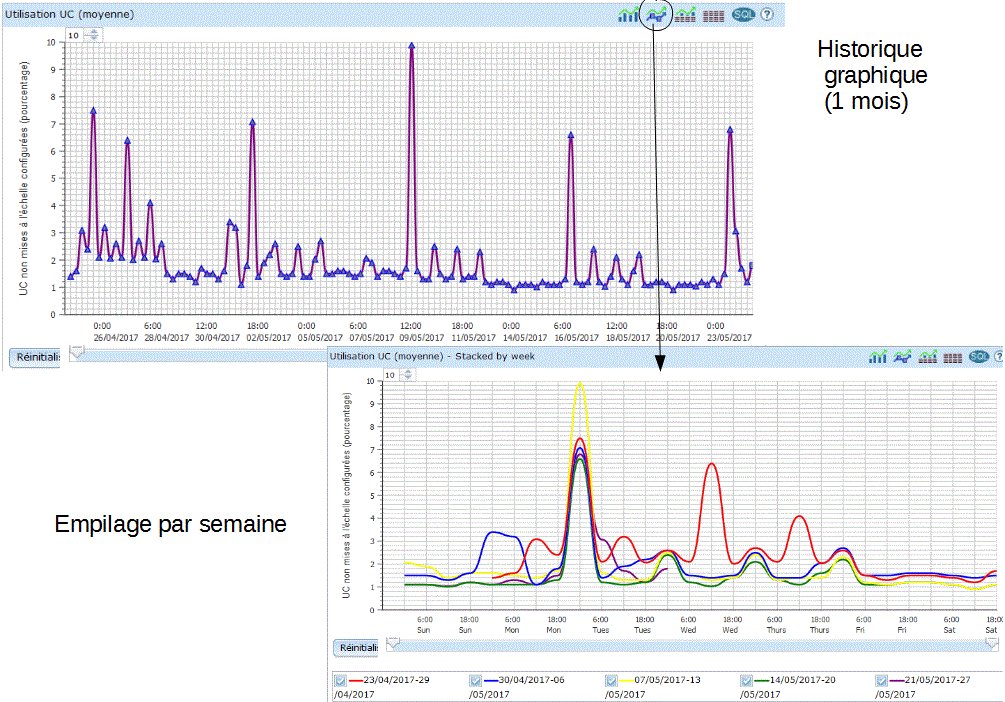
vous pouvez demander à voir l'historique graphique (click
droit)
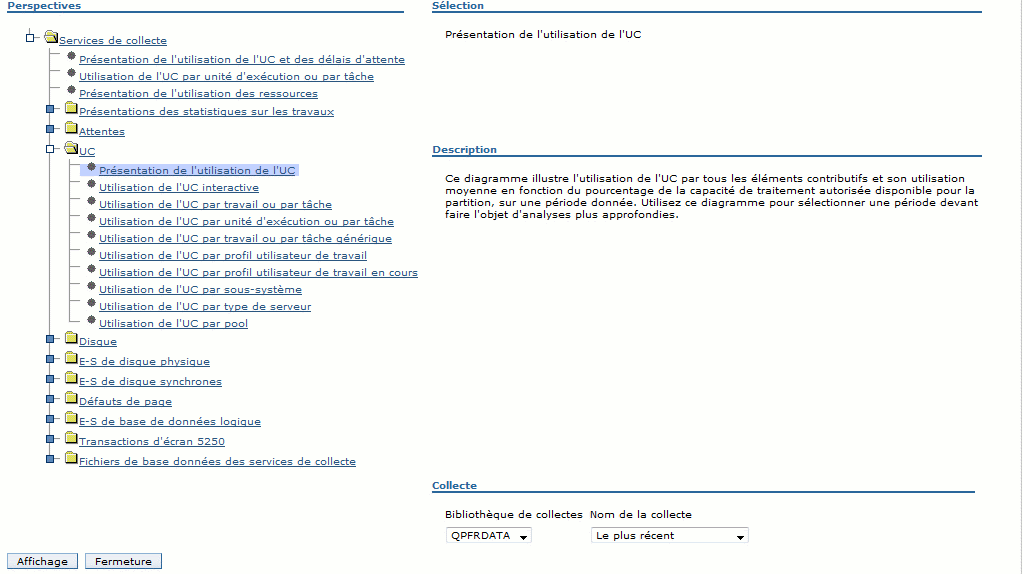
Choisissez vos critères d'affichage
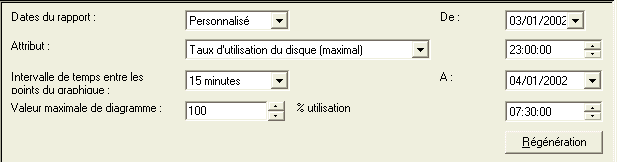
la liste des attributs utilisables, dépend
bien sûr de vos choix initiaux .

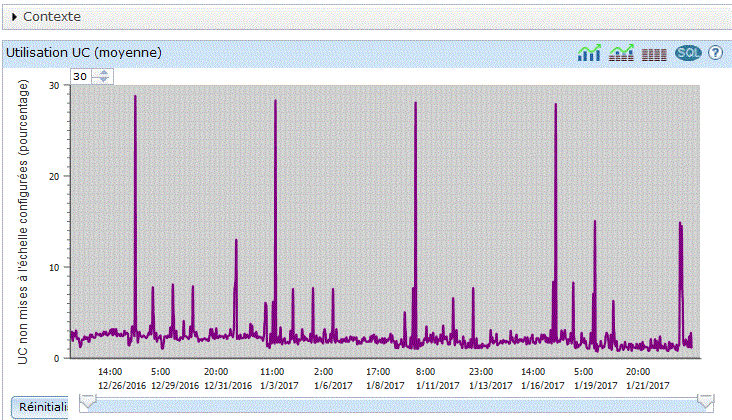
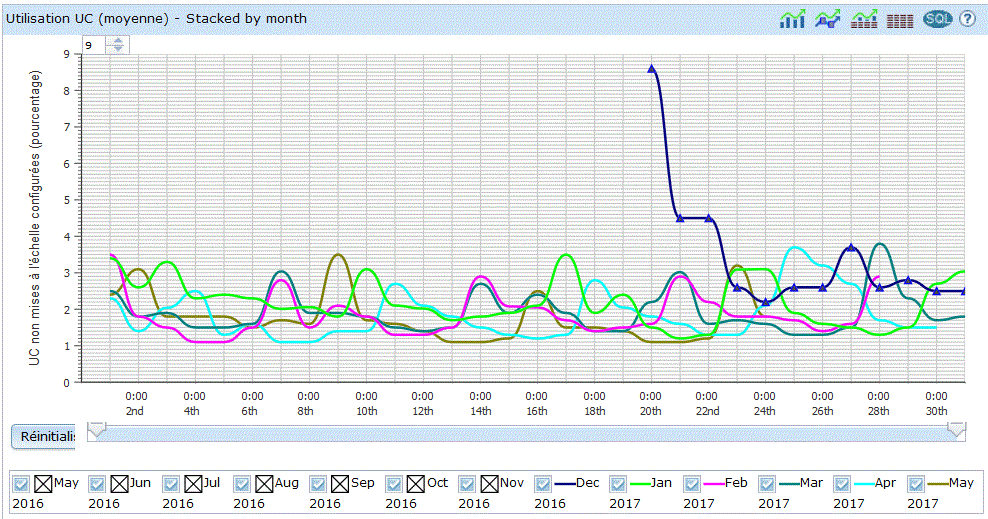
vous verrez sur la partie basse un graphique s'afficher :
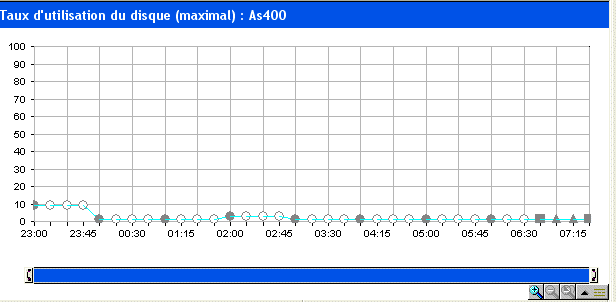
| Vous pouvez restreindre la durée affichée et vous déplacer en jouant avec la barre verticale. |
|
Les points qui vous sont affichés peuvent être:
|
 |
 |
information récapitulative (un triangle) |
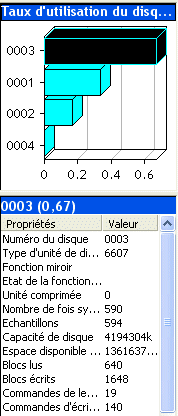 |
informations détaillées (un carré) le détail est dépendant du contexte - détail sur un job (CPU, priorité) - etc... |
|
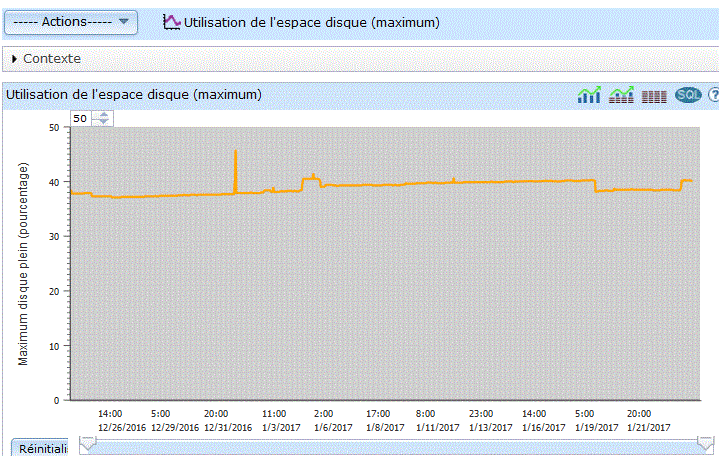
Voici les graphes proposés
|
 |
il s'agit du produit, nouveau en V6, regroupant
il tourne en tant qu'application avec le serveur d'administration, démarré par
STRTCPSVR SERVER(*HTTP) HTTPSVR(*ADMIN)
Il utilise le port 2004 ou 2005, et toute requête vers la racine sur le port 2001 est redirigée .
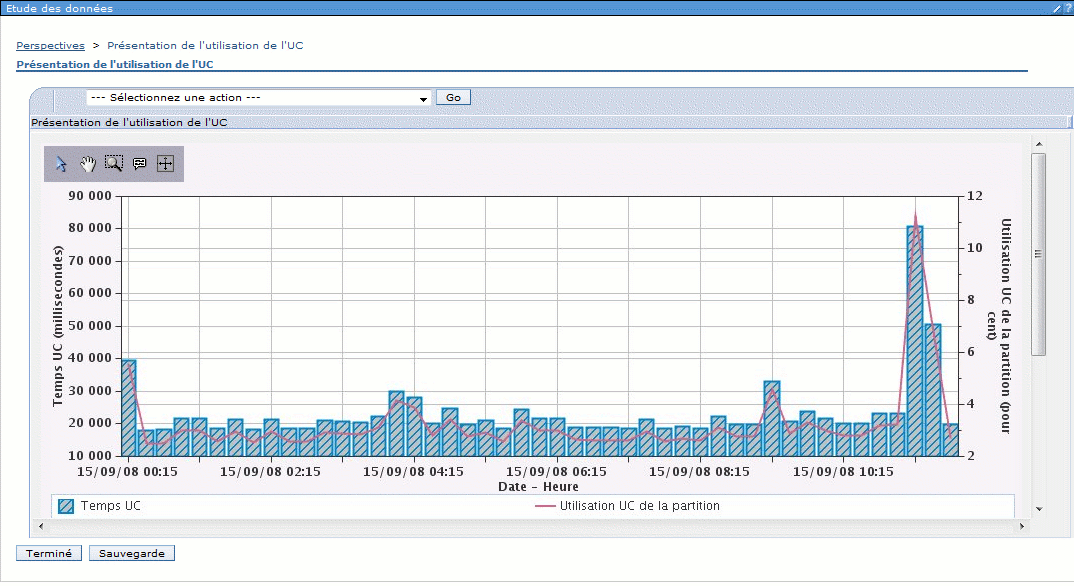
ou bien travailler par collecte
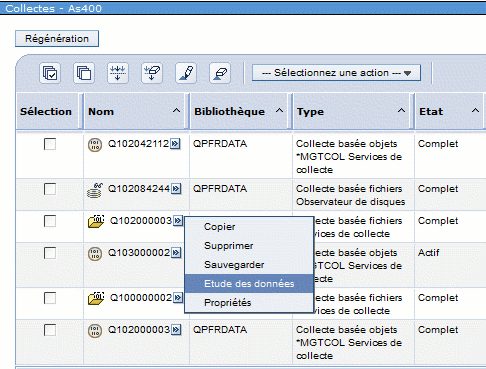
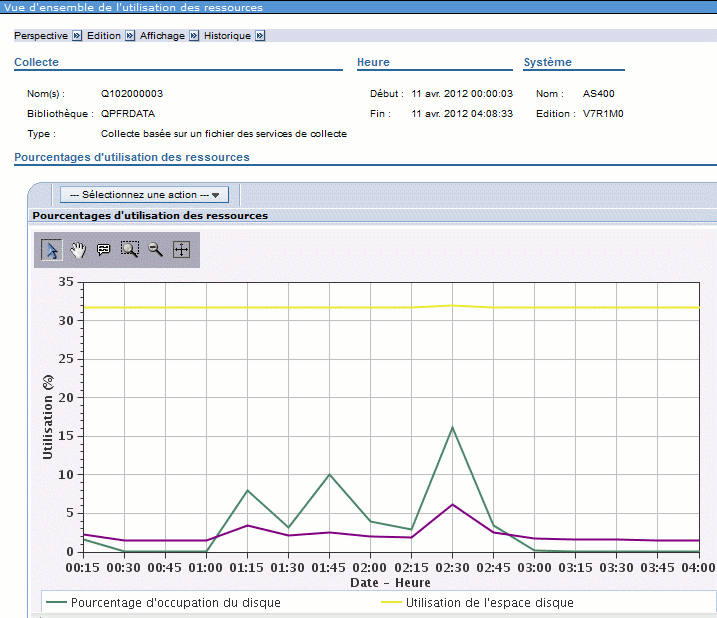
Et ensuite changer d'affichage par "sélectionnez une action"
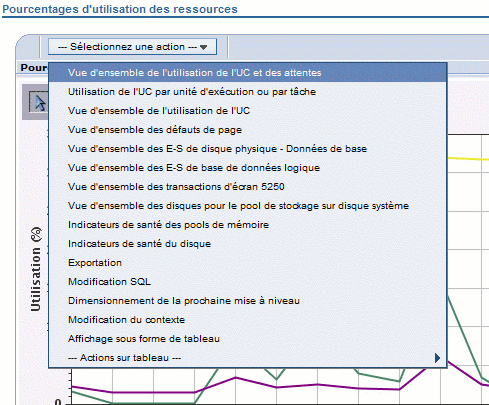
Quelques exemples (les titres sont notés en dessous de "sélectionnez une action")
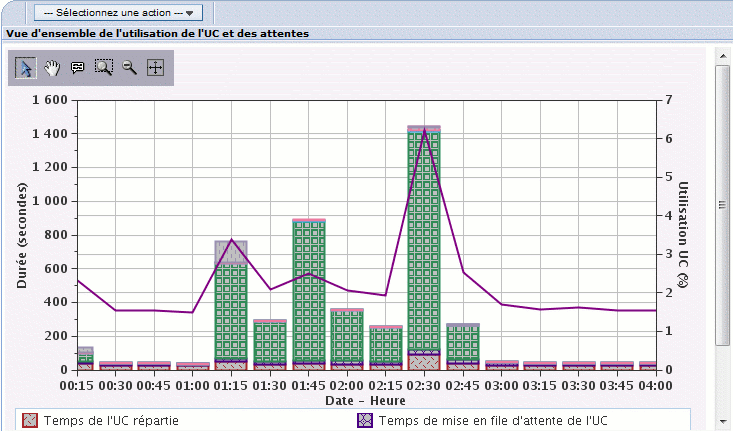
Vue d'ensemble de l'utilisation de l'UC et des attentes.
—> Attention à bien défiler en bas d'écran afin de voir tous les labels

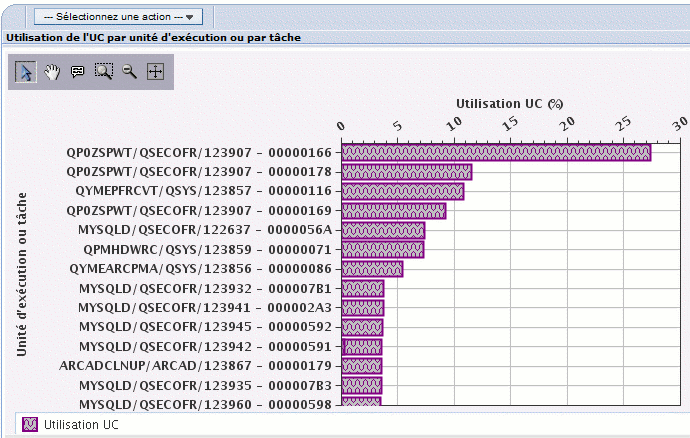
Utilisation de l'UC par unité d'exécution ou par tâche
Sur certains graphiques, vous pouvez focaliser sur un travail ou une tâche
Parmi les nouveautés 7.2 , deux moniteurs, déjà présents dans Gestion centralisée de la version Windows
Moniteur système , permet de surveiller les performances
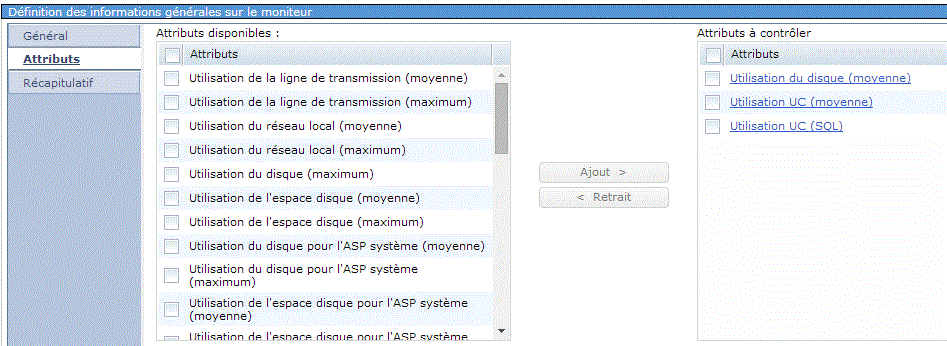

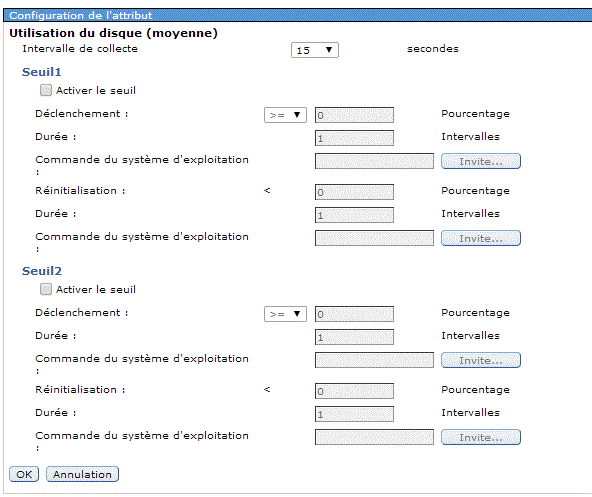
Le moniteur a été créé

On peut le visualiser dans PDI (Performance Data Investigator)
Ou, plus simple, par un clic droit après avoir coché la ligne
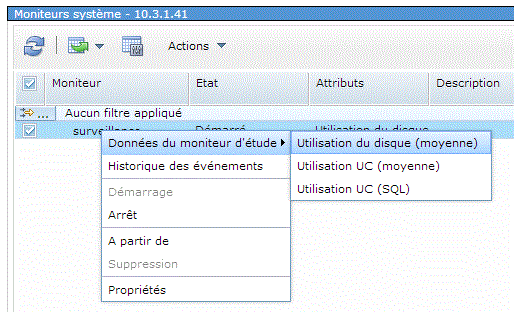
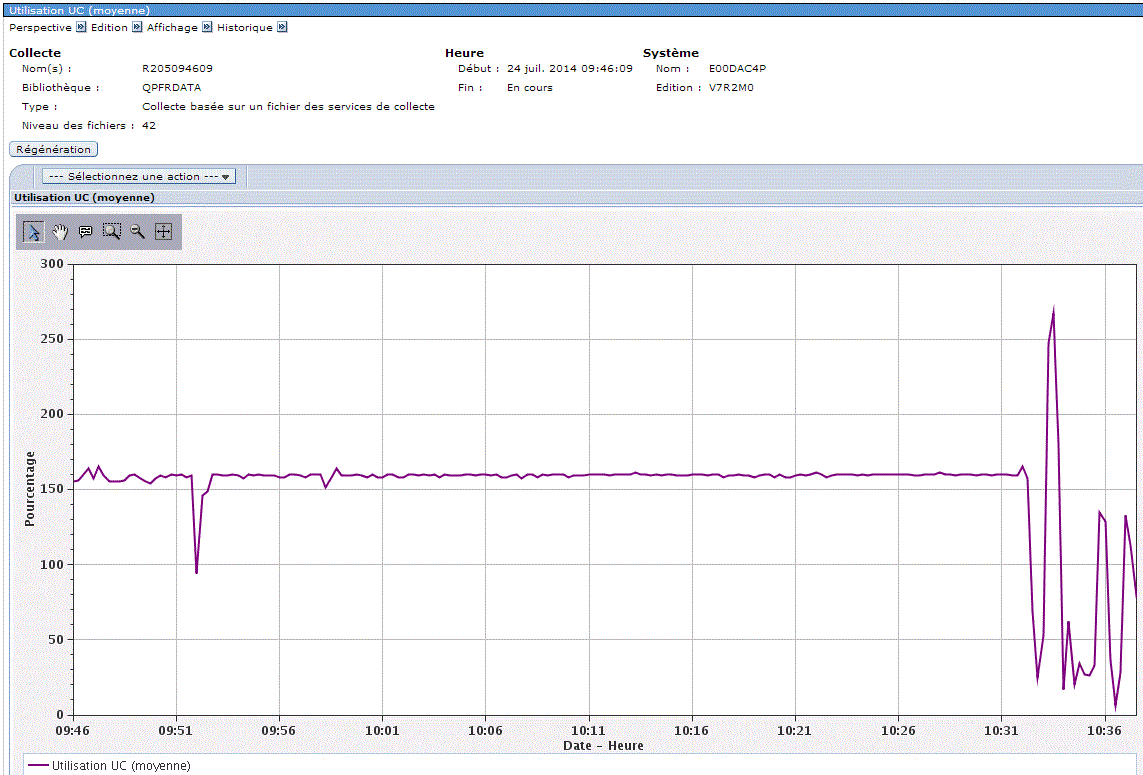
(cliquez pour agrandir)
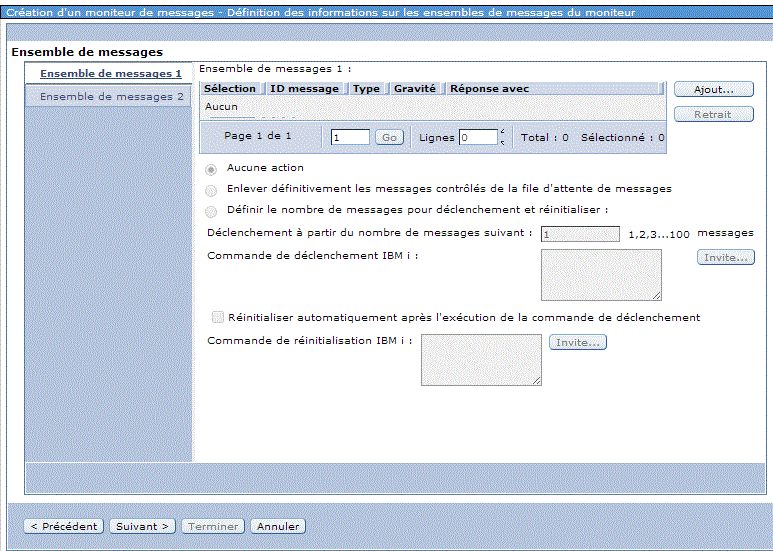
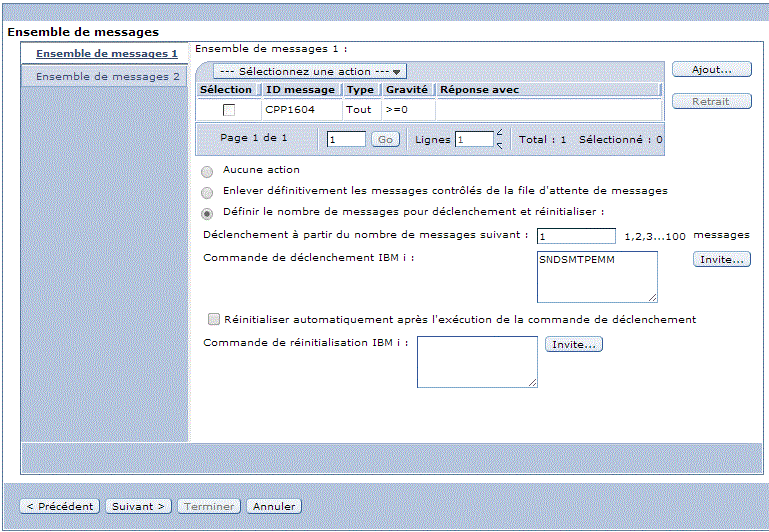
Moniteur message , permet de surveiller une MSGQ

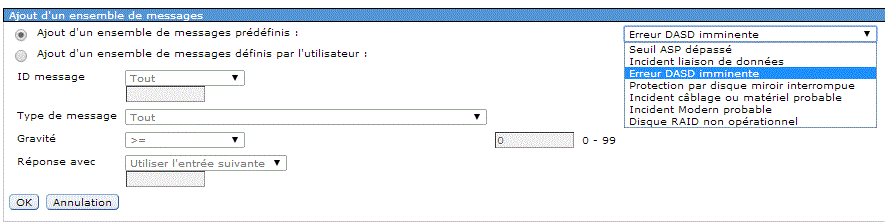
Indiquez l'ID message devant constituer événement (Ajout...)
Navigator vous propose une série de message déjà définie
Ensuite, indiquez la commande à exécuter quand l'événement a lieu
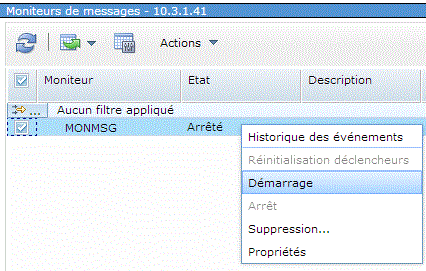
Comme avec les moniteurs système, il vous reste à le démarrer
(cliquez pour agrandir)
Enfin cette nouvelle version 7.2 propose aussi une modélisation des données pour étude,
permettant de répondre aux questions :
ET si mon volume de données à traiter double ?
et si j'ajoute un processeur ?
et si j'ajoute deux disques, ai-je un véritable gain ?
Pour cela vous devez créer un modèle de traitement par lot (batch) , depuis une collecte :
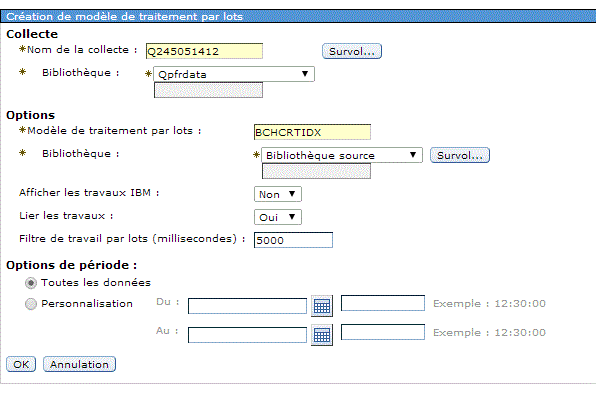
Vérifiez que les données correspondent à ce que vous voulez analyser
Regardez ensuite dans Modèle de traitement par lot, le détail des données collectées
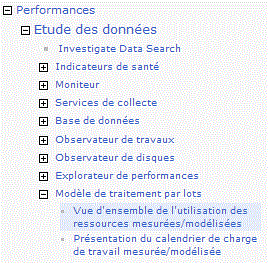
Utilisation des ressources mesurées, que vous allez modéliser
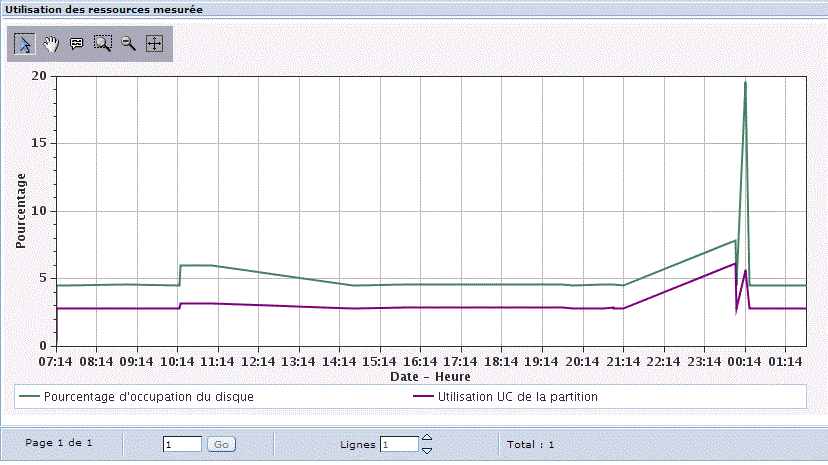
Et la répartition de la CPU dans le temps (calendrier de la charge mesurée)
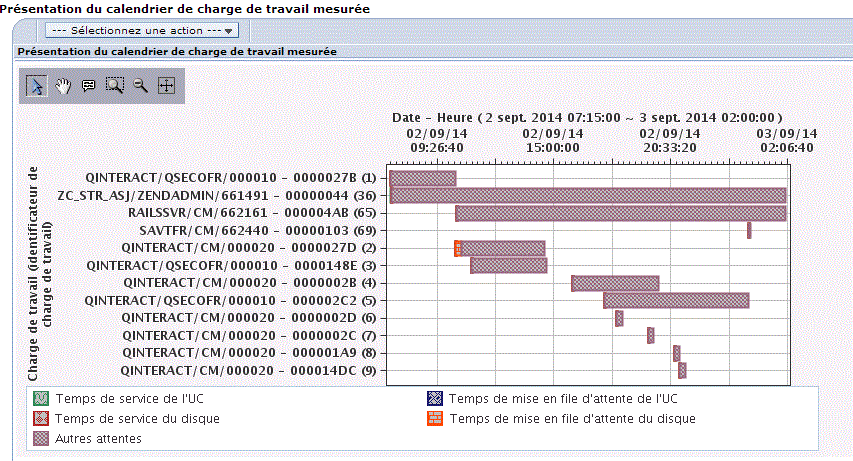
Puis,
Utilisez l'option  qui permet de voir la liste des modèles
qui permet de voir la liste des modèles
et cliquez droit sur le modèle que vous venez de créer
Dans un premier temps vous devez calibrer ce modèle, soit :
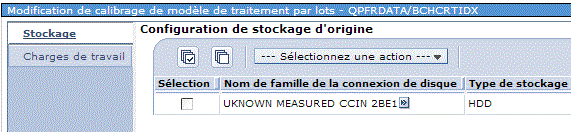
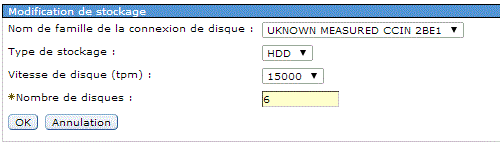
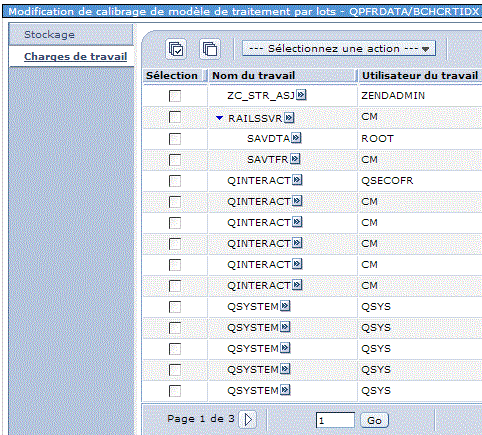
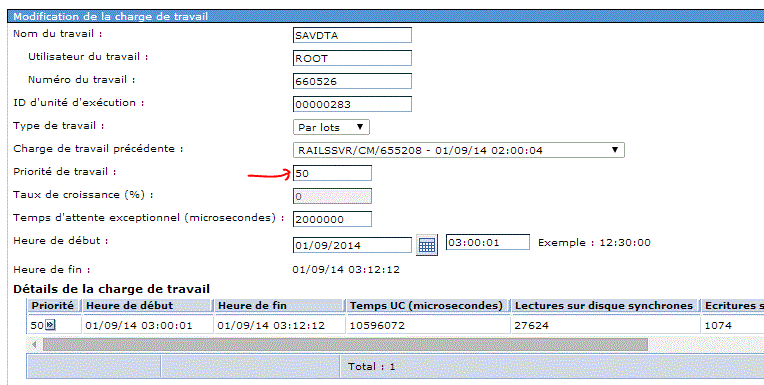
Attendez ensuite que l'état passe à Complet
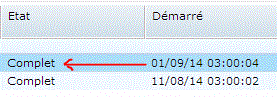
Vous pouvez alors
demander à Modifier le modèle
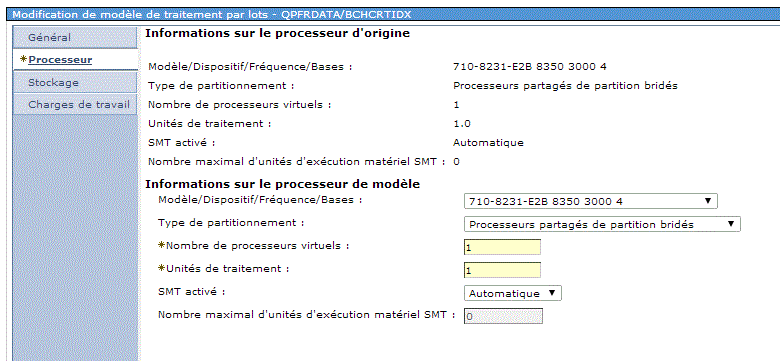
•taux de croissance prévu : (et si ma volumétrie double ?)

•processeur (et si j'en ajoute 1 ?)
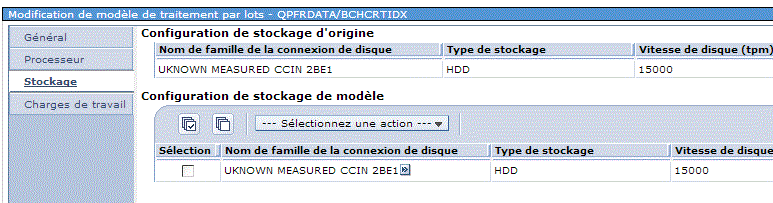
•disque (et si j'en achète deux ?)
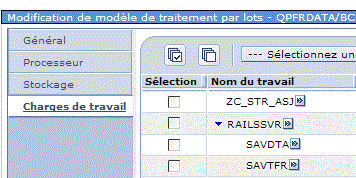
•charge de travail (et si je baisse la priorité des travaux concurrents ?)
Confirmez

L'état passe à Analyse, puis repasse à Complet
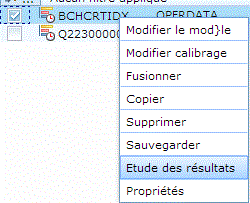
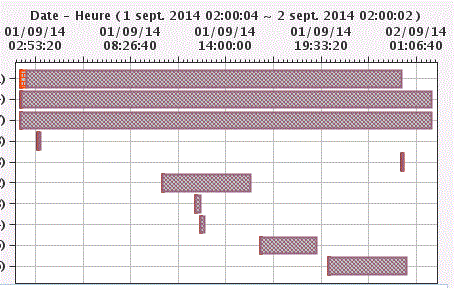
demandez l'étude des résultats :
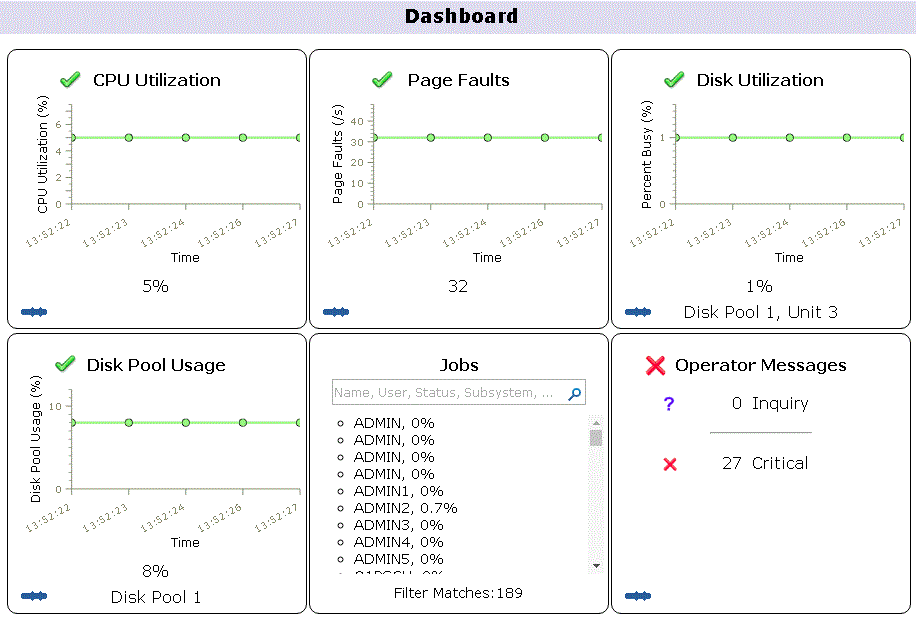
Enfin en version 7.3 , la page d'acceuil de Navigator for i affiche un tableau de bord contenant des informations de performances

Copyright © 1995,2017 VOLUBIS