Trois éléments peuvent intervenir dans la gestion des performances
pour mesurer ces éléments vous avez à votre
disposition quelques outils :
-> commandes natives d'analyse de
l'activité:
-> Des outils graphiques intégrés à Operation Navigator :
Découpage logique de la mémoire afin de gérer les conflits de pagination
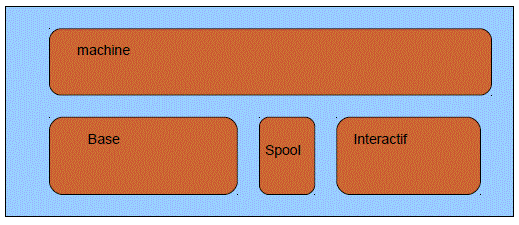
Deux pools particuliers
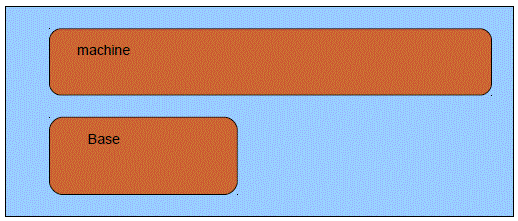
Regroupement logique de travaux d'un même « genre » afin de mieux :
Les pools dédiés (rares aujourd'hui) sont dédiés à un sous-système, créés en même temps que lui
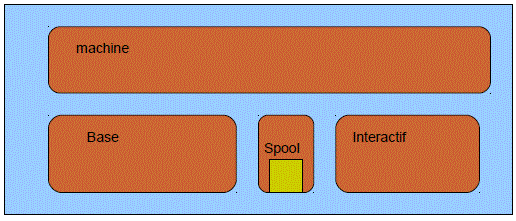
Les pools partageables (dont *BASE) , peuvent recevoir plusieurs sous-systèmes
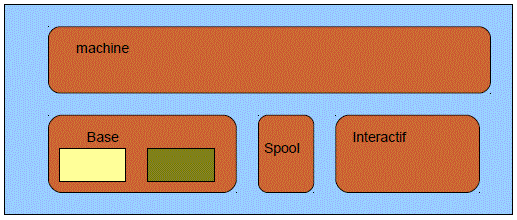
Il arrive qu'un sous système soit éclaté sur plusieurs pools mémoire
(on parle alors de pool de sous système)
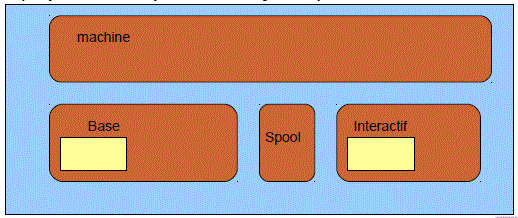
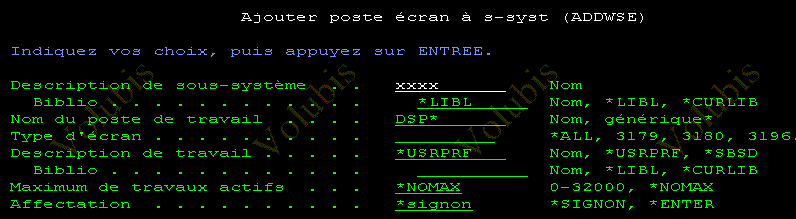
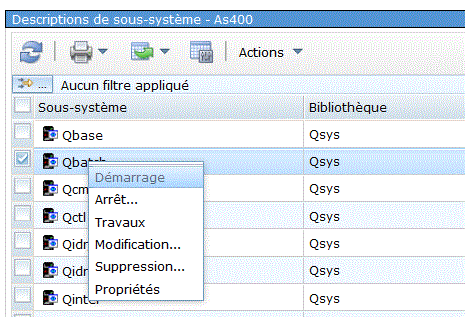
Regardons la commande CRTSBSD
CRTSBSD
SBSD(QINTER) POOLS ( (1 *BASE)
(2 *INTERACT)
)
TEXT('sous-système interactif') |
Ce sous-système a deux parties (2 pools de sous système)
Exemple
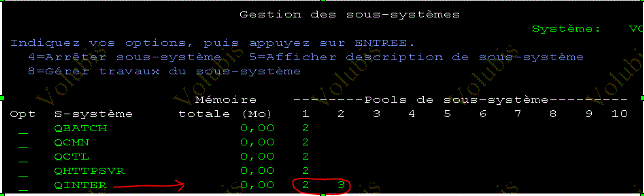
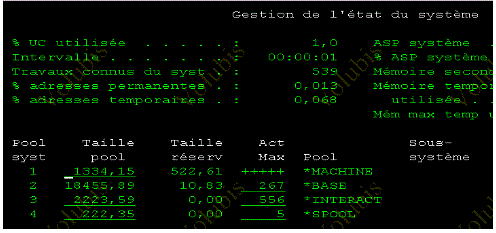
Pour le vérifier WRKSYSSTS, puis F11
CRTSBSD
SBSD(DEDIE) POOLS ( (1 2048 2 *KB)
)
TEXT('sous-système à pool dédié') |
Ce sous-système a une seule partie de 2Go, correspondant à un pool mémoire dédié, avec un niveau d'activité de 2

System i Navigator affiche aussi les pools mémoire
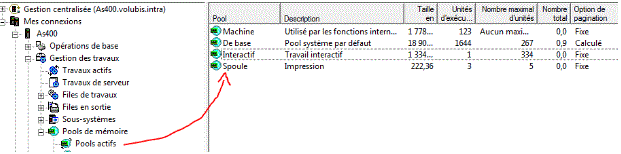
et permet (ce qui est difficile en mode caractère) de voir la liste des travaux 
Même chose avec navigator for I
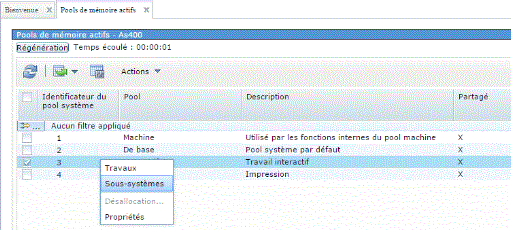
Le plus simple est aujourd'hui de toujours travailler avec des pools partageables (même si vous ne le partagez pas au départ)
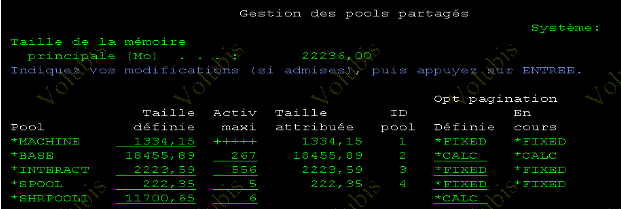
WHRSHRPOOL
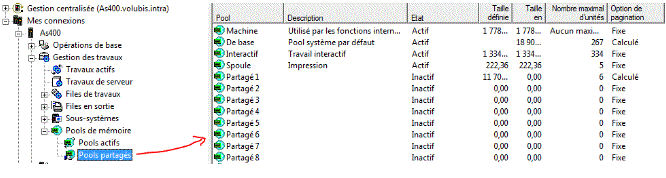
System i navigator
Pour continuer, nous devons revoir une notion élémentaire.
Un job actif consomme-t-il de la CPU ?
Il a plusieurs types d'attente, classés en deux catégories
UN JOB occupant un niveau d'activité est donc un job
Donc la question est : La taille mémoire que je vient d'indiquer permet de stocker des informations pour combien de job Actifs ?
D'où l’intérêt de l'ajustement automatique (QPFRADJ)
Vous pouvez mettre en place l'ajustement automatique (notre conseil)
ET indiquer des préférences (WRKSHRPOOL, puis F11)
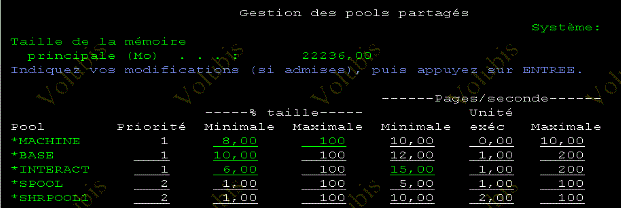
les valeurs en blanc sont d'origine
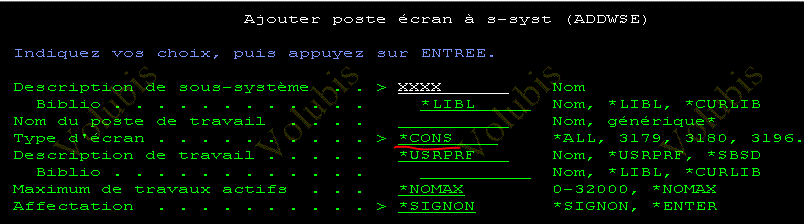
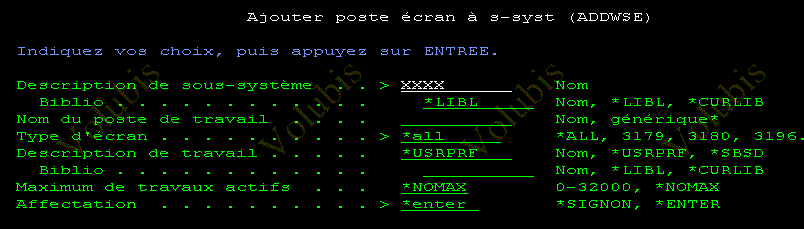
Quel pool de sous- système choisir ?

Commande CRTCLS
PURGE Indique si, quand le travail perd son niveau
|





Nouveaux mécanismes de routage vers les sous-système
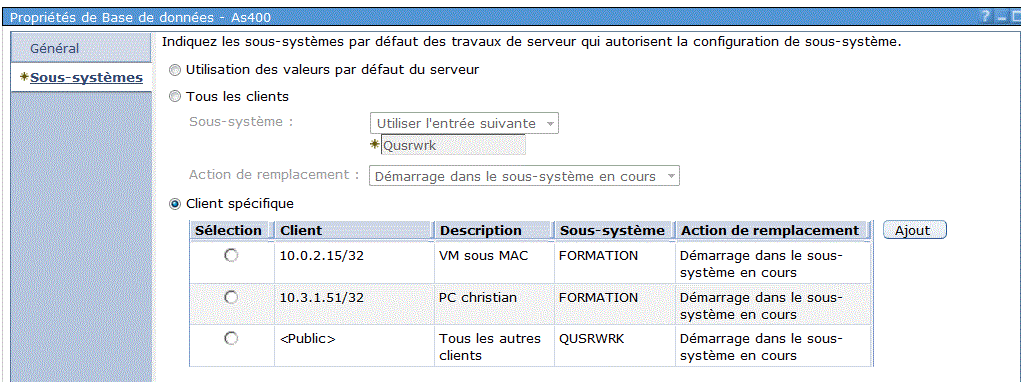
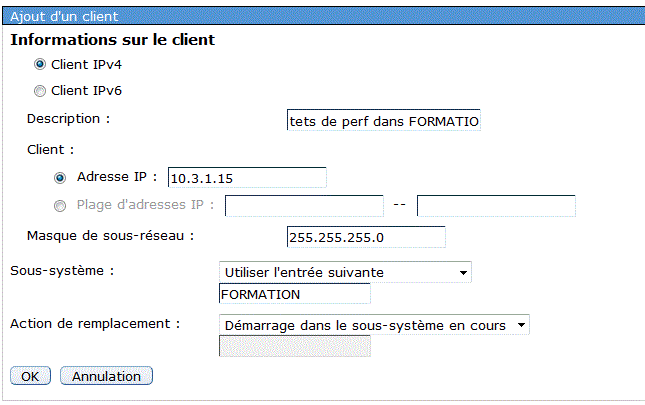
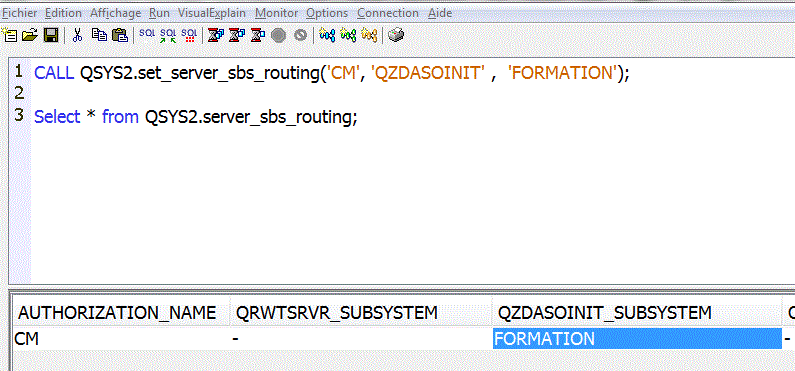
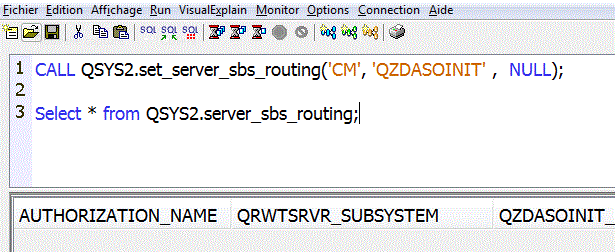
WRKSYSSTS (gestion de la mémoire)
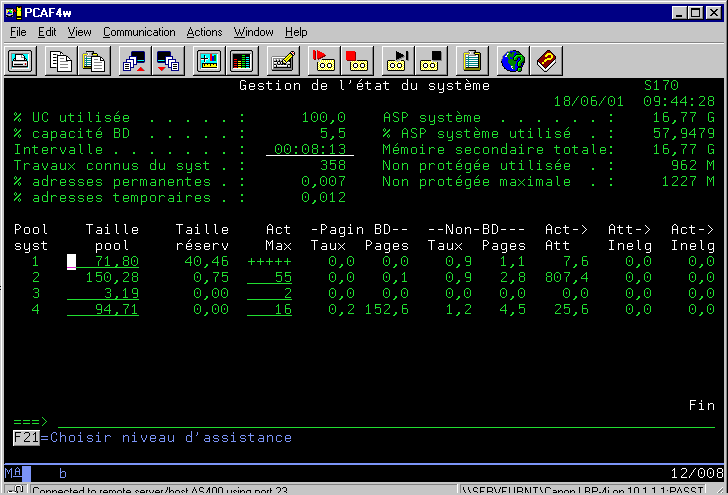
pour lire le WRKSYSSTS, vous devez comprendre la notion de pool
mémoire (vue plus haut)
le taux de pagination global (BD + NON BD) sur le pool machine doit être < à 10 !
Si vous êtes en ajustement automatique, passez la commande WHRSHRPOOL
et, rappelez vous, faites F11
Gestion des pools partagés Système: AS400 Taille de la mémoire principale (Mo) . . . : 3054,28 Indiquez vos modifications (si admises), puis appuyez sur ENTREE. |
Pour les autres pools, historiquement, il devait être < à
20-25 (maxi).
Pour une machine récente, calculez plutôt la pagination maximale comme suit :
| Interactif | 5 + (T x 0,5) |
| Batch | 10 + (T x 2,0) |
la documentation V5R40 indique comme base de calcul rapide, par pool :
c*p, ou c est le pourcentage de CPU utilisé
p est le nombre de processeurs de la partition
par exemple
1 processeur à 36 % = 36 de taux de pagination maxi
1,8 processeur (LPAR) utilisé à 80% = 144
fixer à *CALC, les options de pagination (par F11) si vous avez au moins 100 Mo ( sur les pools BATCH, au moins)
- la colonne activité maxi, indique elle , le nombre de job chargés
en mémoire en même temps.
(un job ayant besoin de traitement, mais qui doit attendre car ce nombre est
atteint, est dit inéligible)
-le nombre de job Attente/inéligible doit représenter
10 % maximum du nombre Actif/attente (ne demandant rien => attente
écran ou I/O disque)
-la colonne Actif/inéligible représente les jobs que le
système a rendu inéligible de manière
forcée (tranche de temps maxi consommée)
WRKACTJOB (travaux consommateur et temps de
réponse)
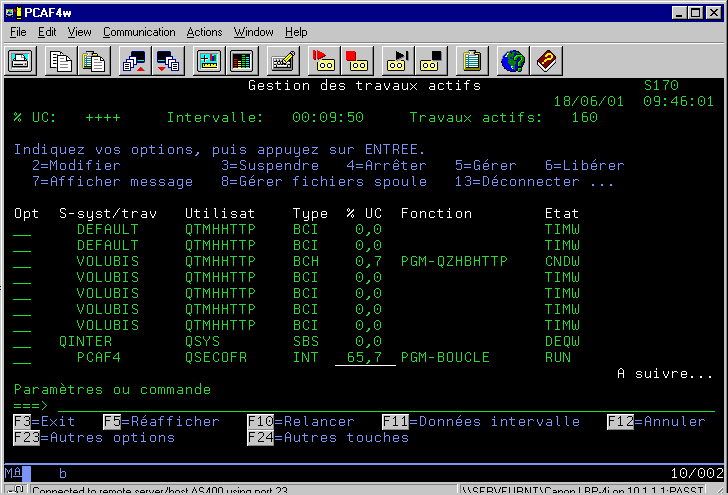
Remarquons :
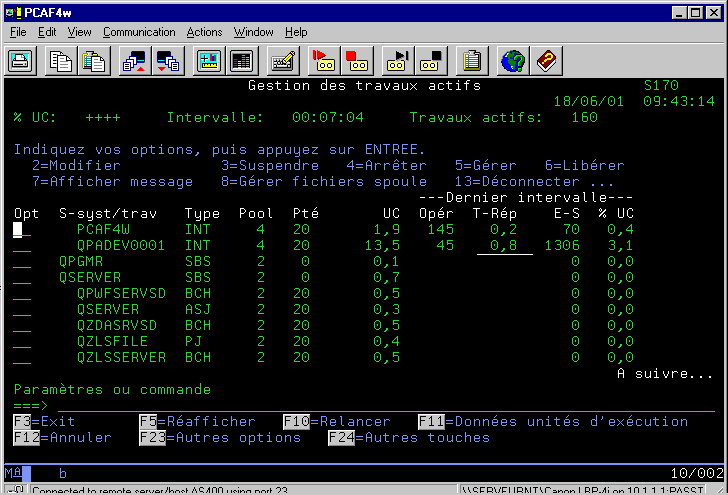
ces écrans permettent de retrouver les travaux les plus
consommateurs ou les plus mauvais temps de réponse.
Touches de fonctions :
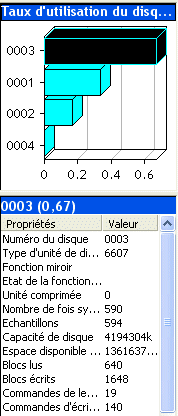
WRKDSKSTS (gestion des disques)
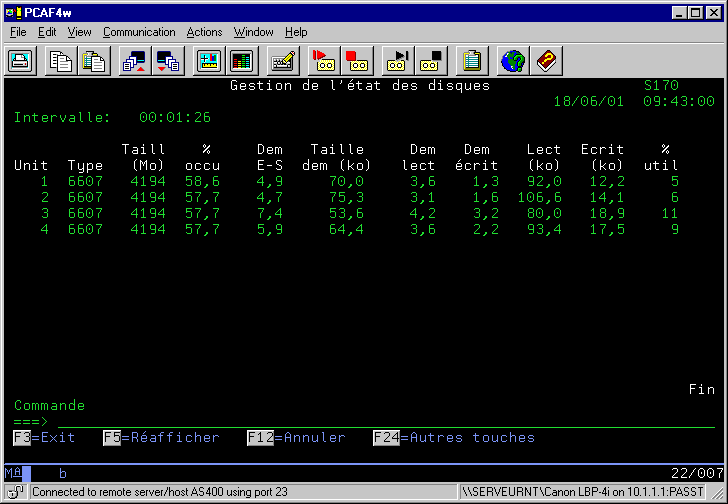
cet écran montre le taux d'occupation des disques
(l'idéal est un taux de 75 % au maximum)
ainsi que l'activité des bras (% util).Une activité au
delà de 50% indique des disques très occupés.
si la répartition n'est pas linéaire (achat de nouveaux disques, par exemple), passez la commande STRASPBAL TYPE(*CAPACITY)SI certains disques sont plus utilisés que d'autres (achat de disque suivi de l'installation de logiciel)
TRCASPBAL *ON (analyse de l'activité base de données sur une plage horaire significative)
TRCASPBAL *OFF
Puis
STRASPBAL *USAGELe système réparti sur l'ensemble de l'ASP un « panachage » de fichiers très utilisés et de fichiers peu utilisés
WRKSYSACT (Commande de Performance Tools, intégrée à l'OS en V6.1)
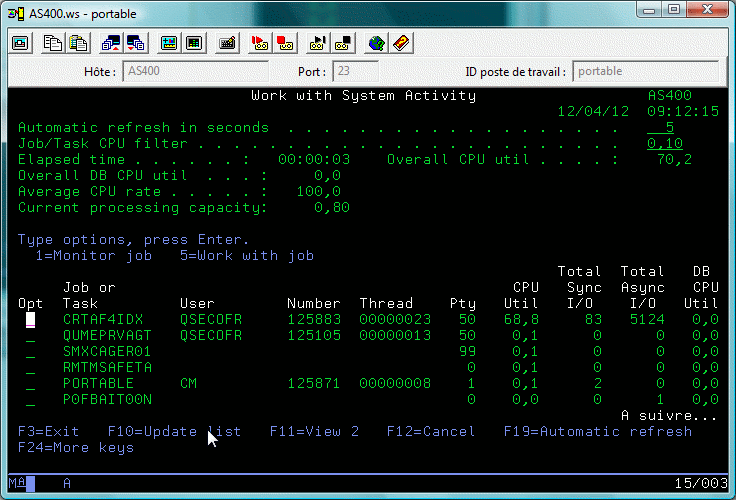
Cette commande possède deux particularités :
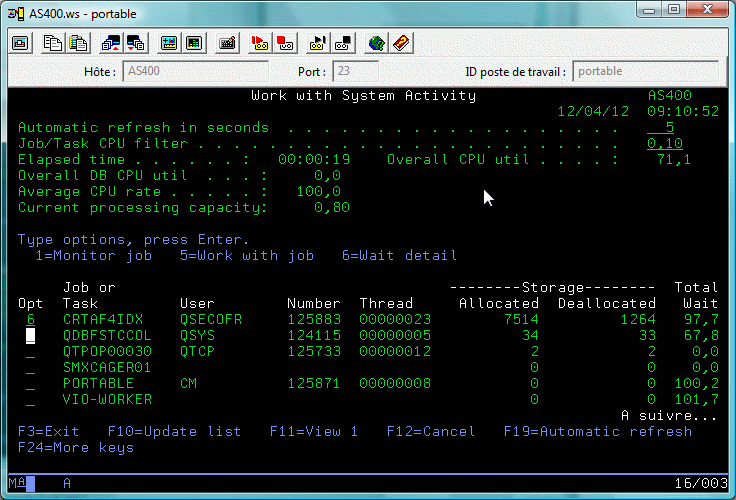
En effet les temps de traitement sont répartis de la manière suivante :
| Traitement CPU | Attente CPU |
Longue attente | Attente bloquante |
Les différents types d'attente :
| Lecture disque | Écriture disque | Verrouillage | fonction journal |
Il peut alors être intéressant de détailler ces mécanismes d'attente
(l'OS en interne en distingue 268, qui ont ici été regroupés en 32 groupes)
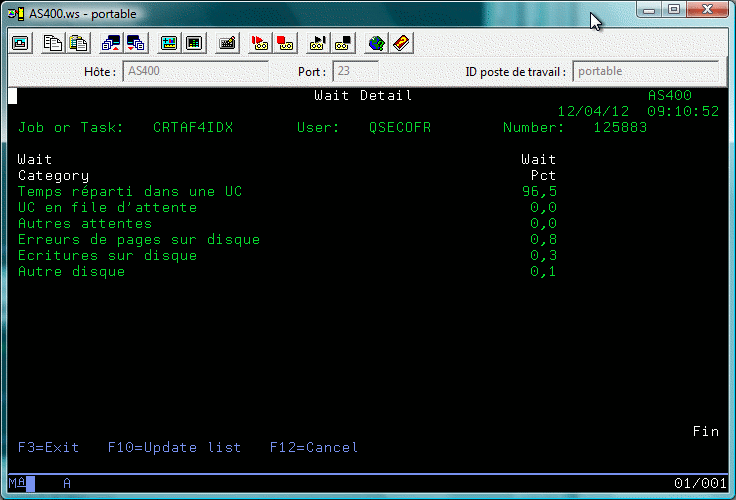
Détail de l'option 6 sur un travail ou une tâche
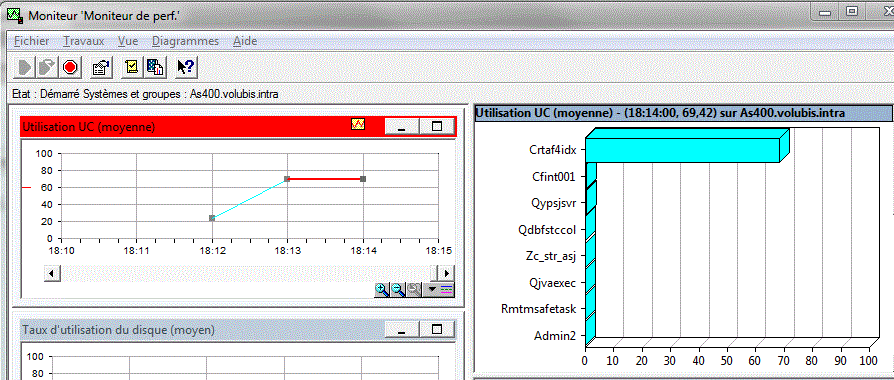
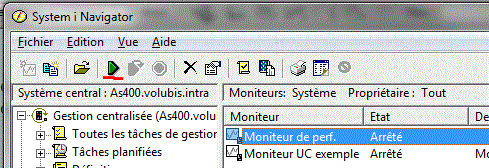
Un moniteur est une analyse graphique et temps réel des
performances:
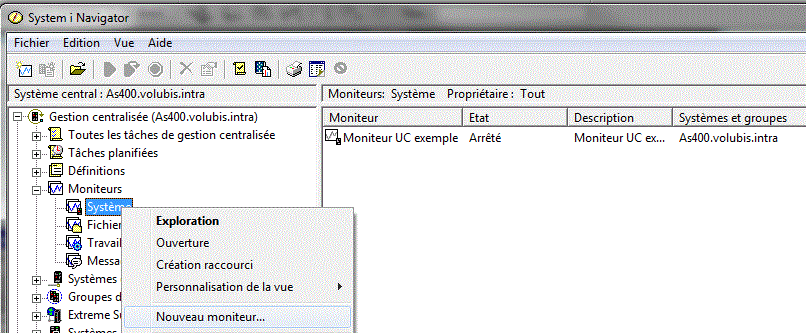
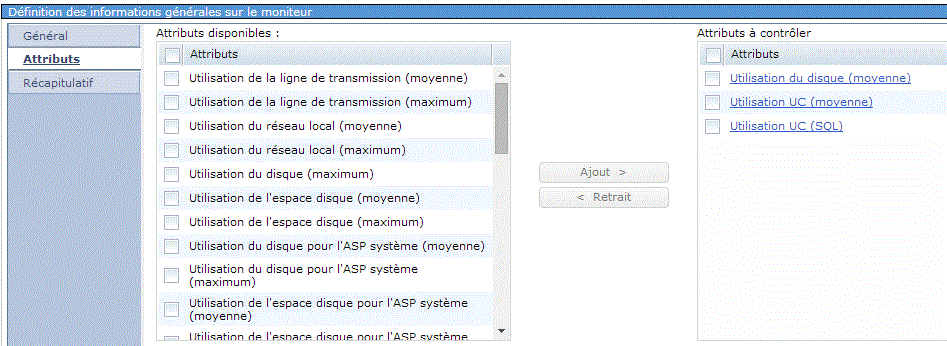
Indiquez : - la liste des événement à analyser
vous remarquerez :
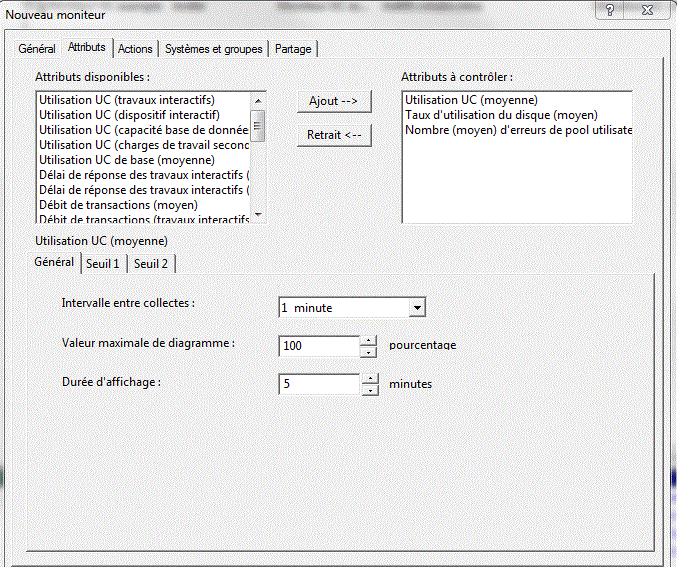
vous pouvez préciser :
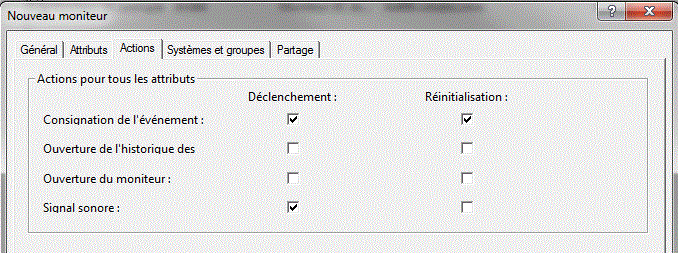
pour gérer les moniteurs, revenez à la fenêtre précédente :
le bouton vert (représentant une flèche) permet de lancer l'analyse.
le bouton rouge(représentant un panneau) permet de l'arrêter.
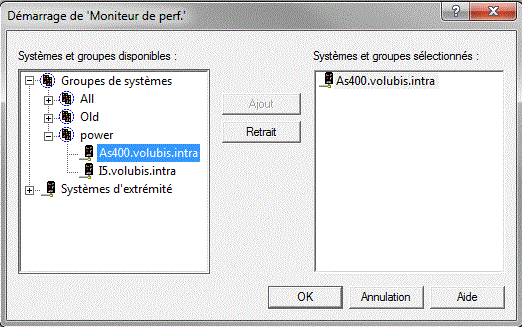
Quand vous démarrez le moniteur, le système vous demande les systèmes ou groupes de systèmes, devant participer à cette analyse
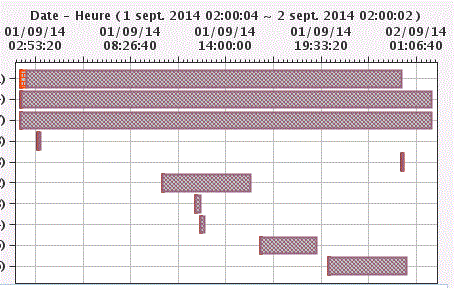
| Le démarrage effectué, doucle-cliquez sur la ligne pour voir l'analyse. l'affichage est alors découpé comme suit : ######################################################################### # # si vous pointez une mesure, # # .................................... # vous verrez ici le détail # # : : # sous forme d'histogramme # # : vos différents graphes : # # # : (autant que d'événements : # # # : à analyser) : # # # :..................................: ################################ # # # # .................................... # en cliquant sur une ligne # # : : # de l'histogramme ci-dessus # # : sur chaque graphe, un point : # vous verrez le détail du # # : représente une prise de mesure : # job dans cette fenêtre. # # : : # # # :..................................: # # # # # ######################################################################### |

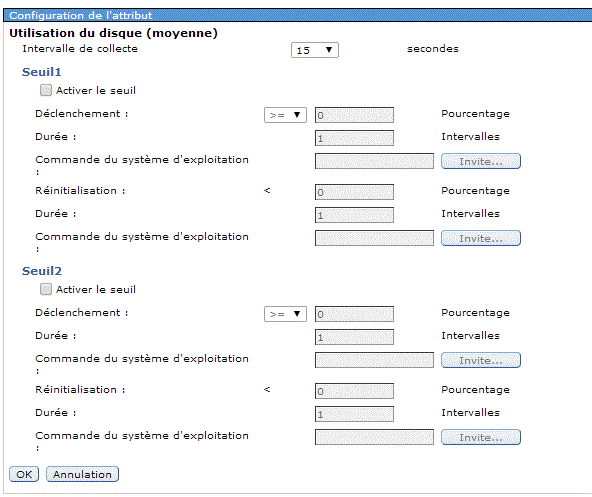
3/ Définition de seuils.
et vous pouvez utiliser des variables de substitution :
|
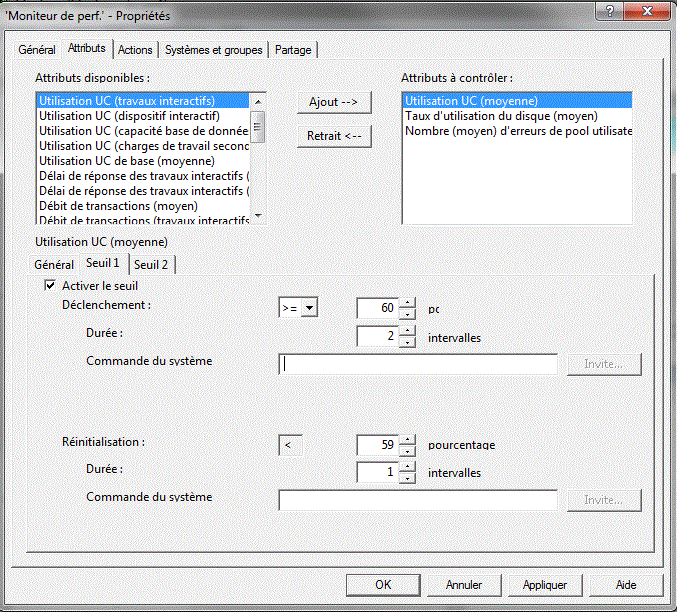
Vous voyez ici, l'influence des seuils (sur une machine très "confortable")
les moniteurs de performance changent en V5R10:

Collectes de
performances
Il s'agit de collecter des données de
performances afin d'offrir une vision d'ensemble de l'état de la
machine.
cela était possible avant grâce aux commandes
STRPFRMON/ENDPFRMON qui disparaissent en V5 au profit de cette nouvelle
notion de collecte.
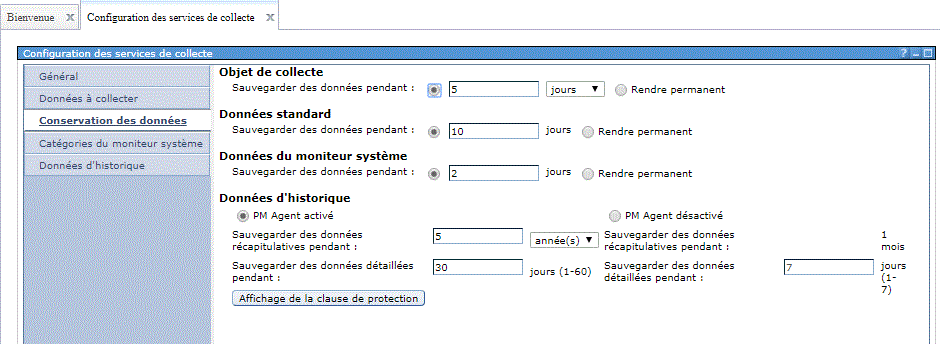
Les collectes écrivent dans un seul objet : *MGTCOL (avant il y avait jusqu'à 30 fichiers différents)
Vous pouvez choisir d'écrire dans des fichiers en fin de
traitement ou en temps réel.
Les collectes sont plus précises, les points de collectes plus
rapprochés (attention aux volumes !!! )
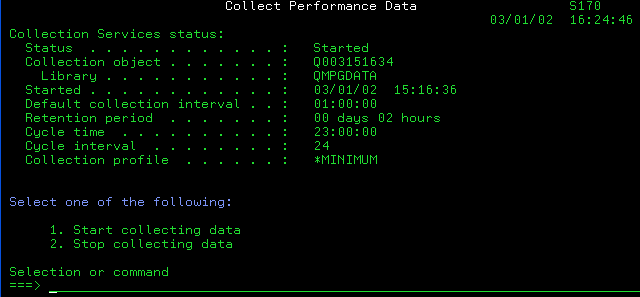
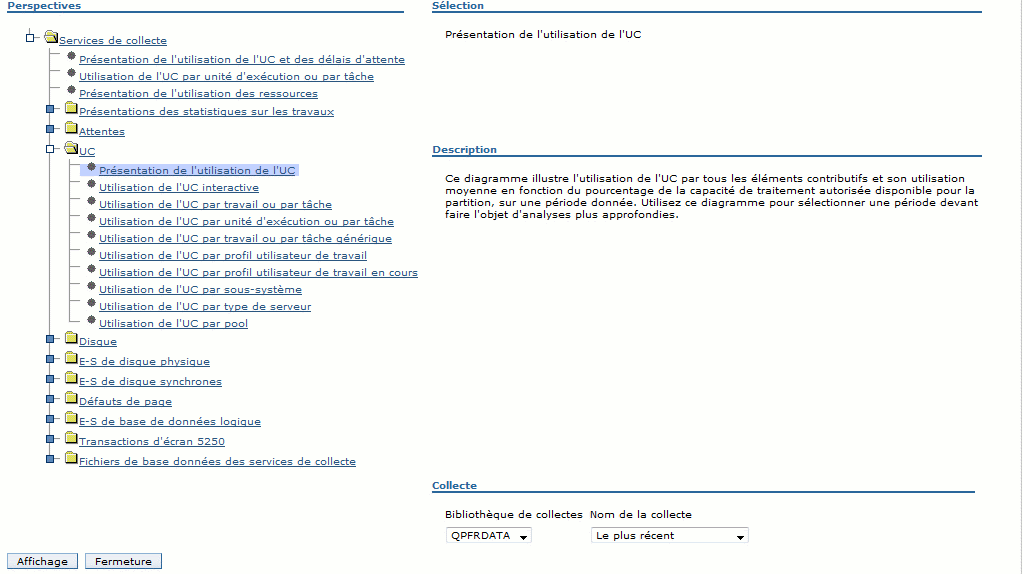
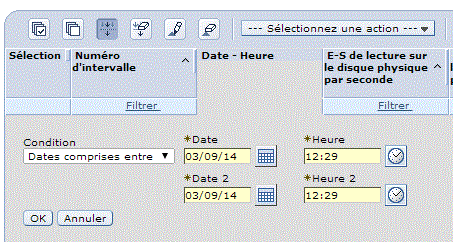
Pour lancer une collecte :
·Vous pouvez utiliser l'option 2 du menu PERFORM. Si une collecte est déjà active, on vous affiche l'écran suivant:
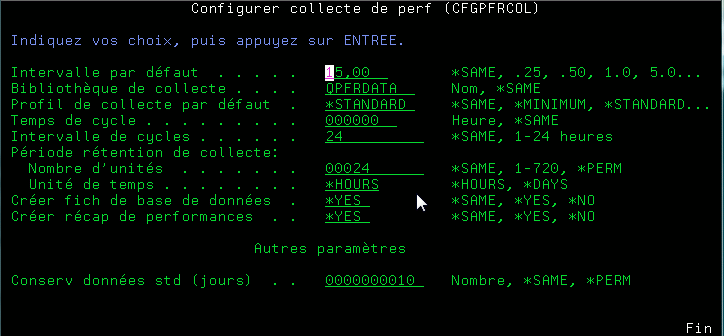
·Ou lancer les commandes STRPFRCOL / ENDPFRCOL
les commandes suivantes sont fournies
· utilisez Operation navigator qui permet de consulter les
données sous forme de graphiques sans écrire dans aucun
fichier.
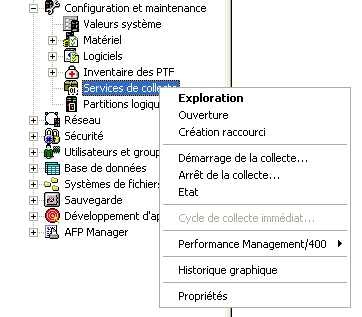 (depuis Op.navigator)
(depuis Op.navigator)
il vous faudra indiquer ensuite:
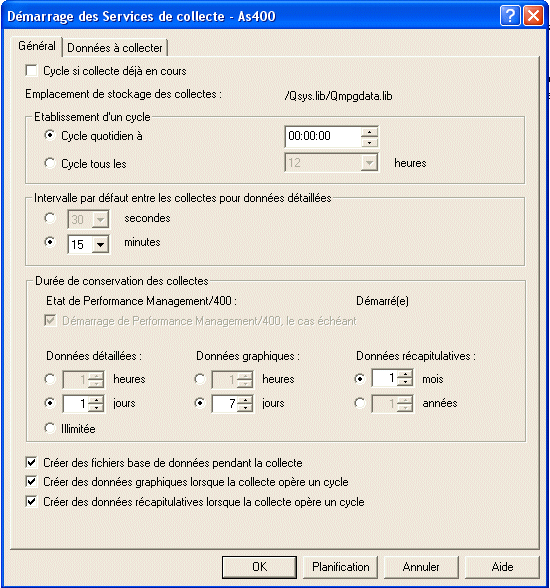
Si vous souhaitez établir un nouveau cycle au cas ou une collecte serait déja en cours de traitement.
rappel: les informations sont stockées dans
un seul objet : *MGTCOL (et non plus dans des fichiers),
établir un cycle, c'est changer d'objet.
|
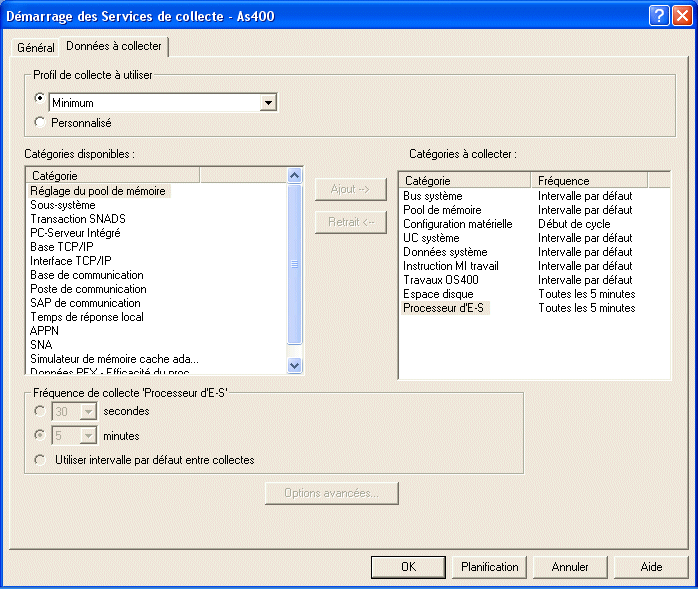
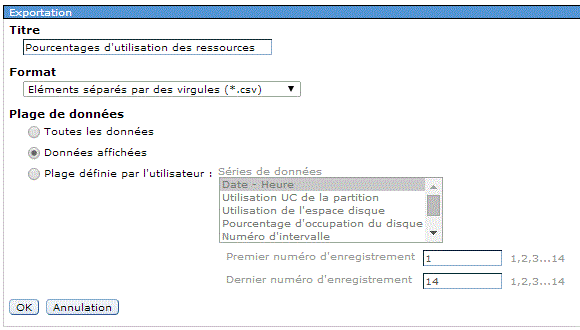
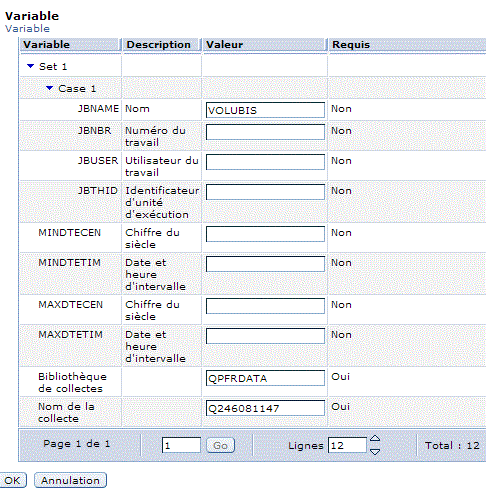
Puis indiquez les données à collecter, ou utilisez un
profil (modèle des données à collecter et des
intervalles associés).
Vous pourrez aussi le faire avec Navigator for I (version WEB)
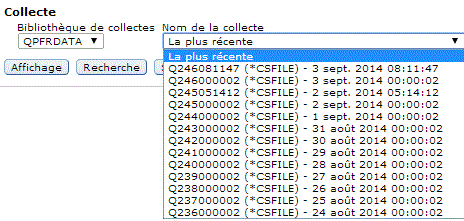
Une fois la collecte lancée ou terminée (Attention aux
volumes, il faut plus de 10 Mo pour une journée)
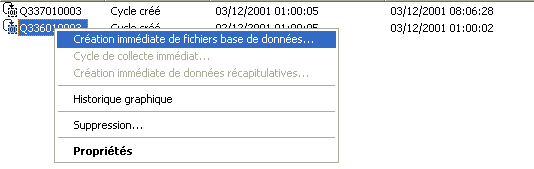
ici, un cycle a été créé à 23h00

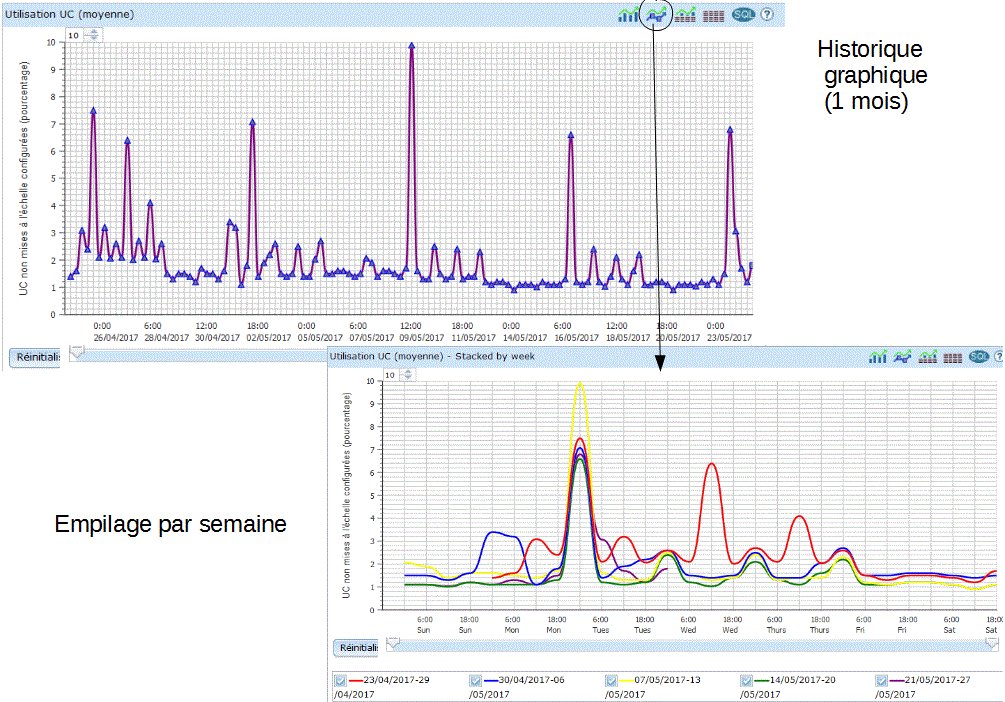
vous pouvez demander à voir l'historique graphique (click
droit)
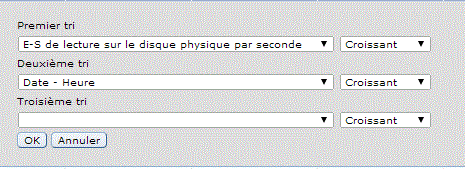
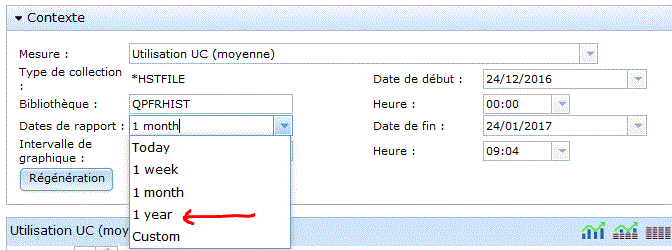
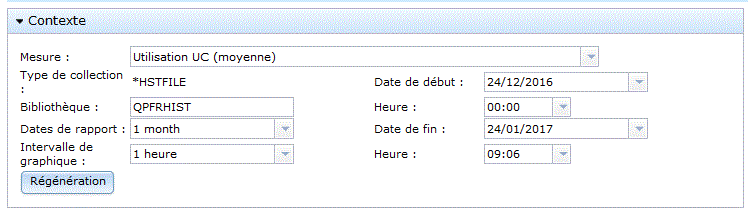
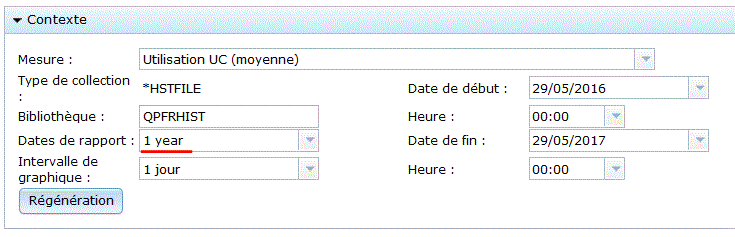
Choisissez vos critères d'affichage
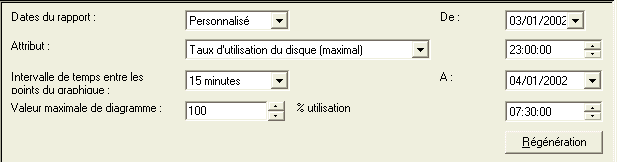
la liste des attributs utilisables, dépend
bien sûr de vos choix initiaux .

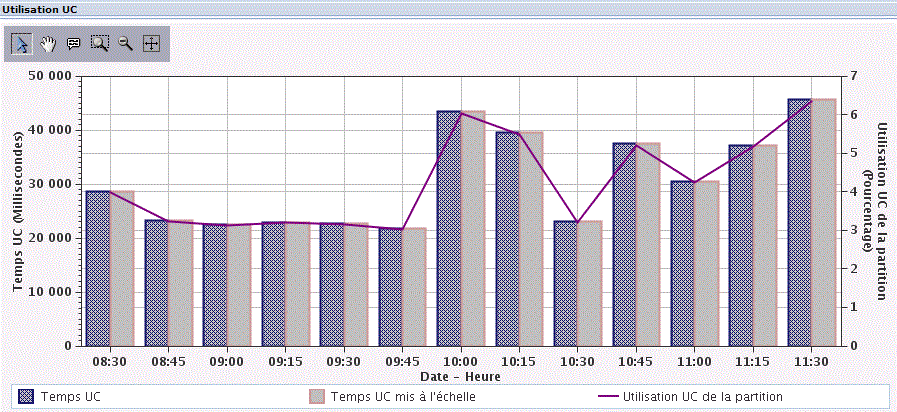
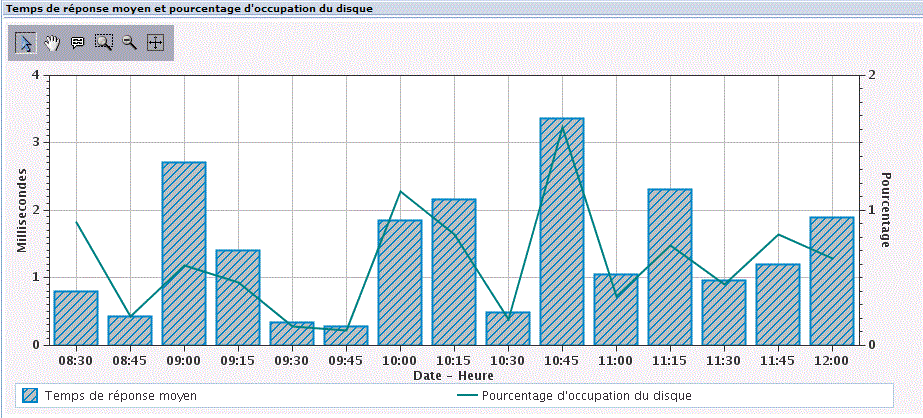
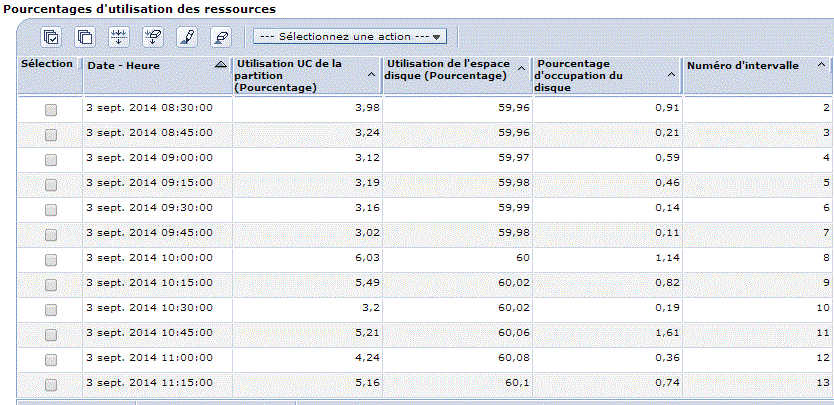
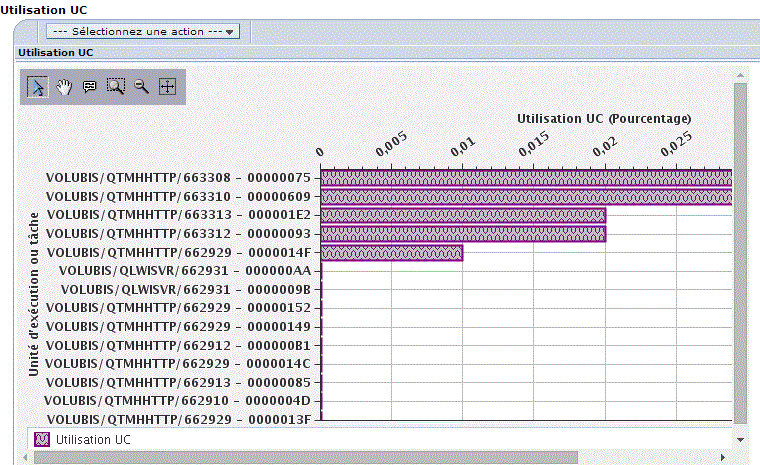
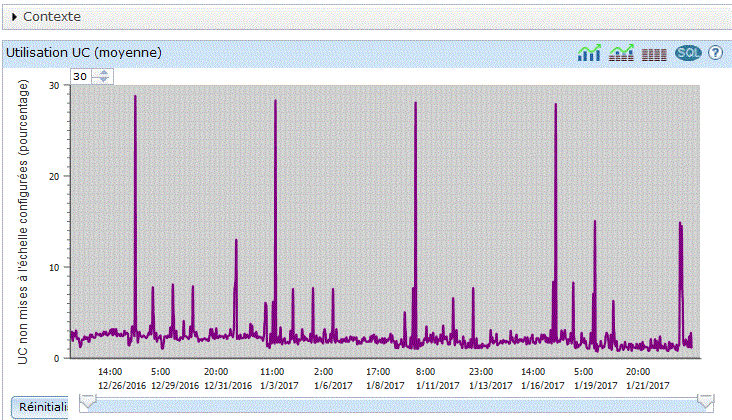
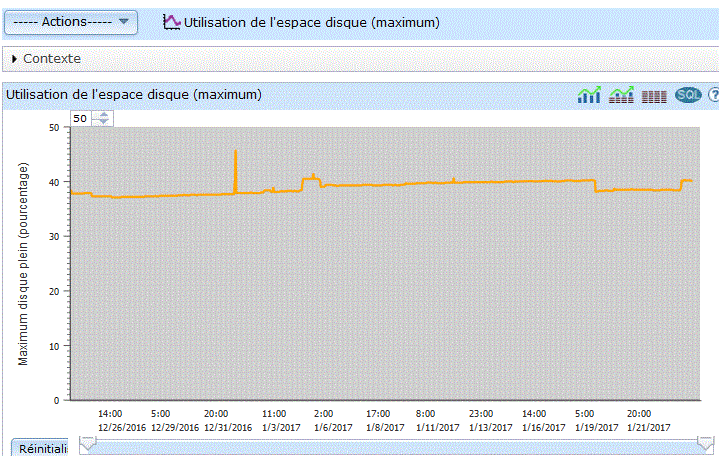
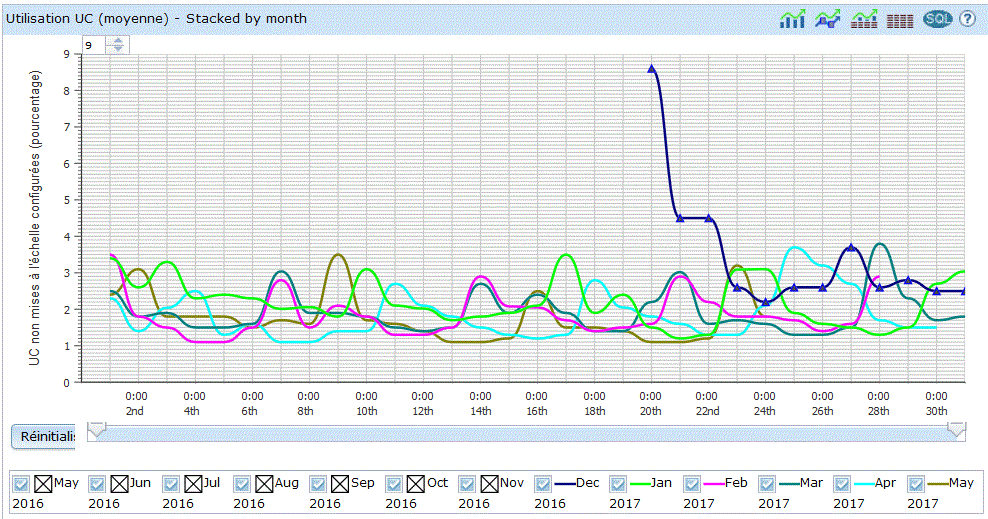
vous verrez sur la partie basse un graphique s'afficher :
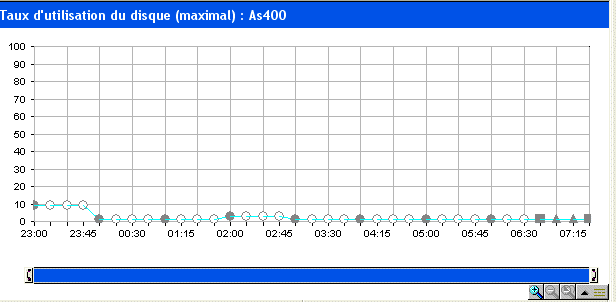
| Vous pouvez restreindre la durée affichée et vous déplacer en jouant avec la barre verticale. |
Les points qui vous sont affichés peuvent être:
|
 |
 |
information récapitulative (un triangle) |
 |
informations détaillées (un carré) le détail est dépendant du contexte - détail sur un job (CPU, priorité) - etc... |
Aujourdhui la version web (Navigator for I) , va sans doutes, prendre la pas.
il s'agit du produit, proposé depuis la V6, regroupant
il tourne en tant qu'application avec le serveur d'Administration, démarré par STRTCPSVR SERVER(*HTTP) HTTPSVR(*ADMIN)
Il utilise le port 2005, et toute requête vers la racine sur le port 2001 est redirigée vers :
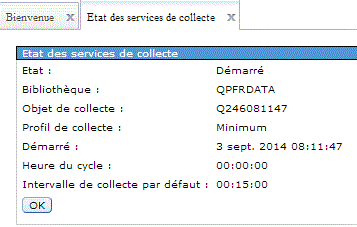
Il est important d'avoir des données récapitulative pour le bon fonctionnement de PDI
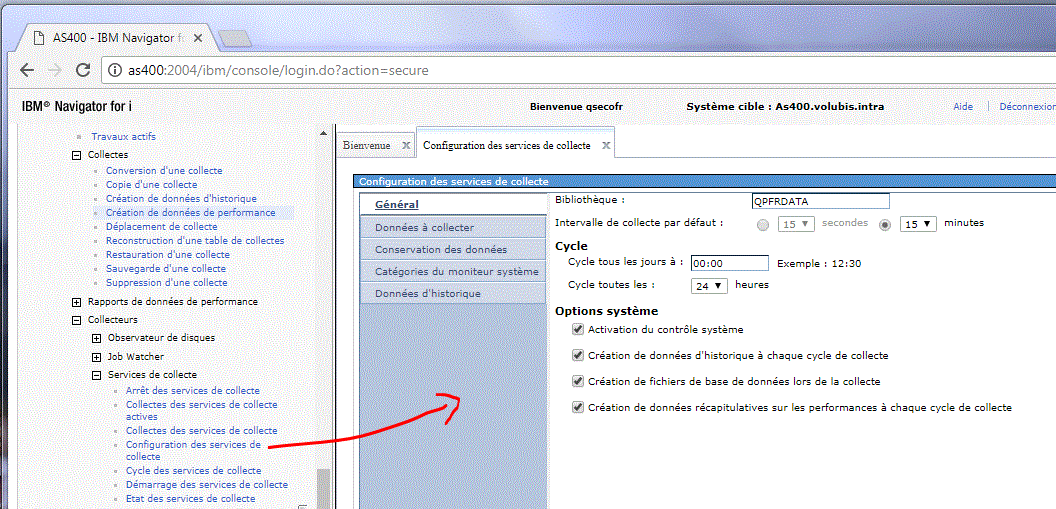
- CRTPFRSUM
- ou mieux CFGPFRCOL CRTPFRSUM(*YES) CRTDBF(*YES)
- ou cochez les cases suivantes :
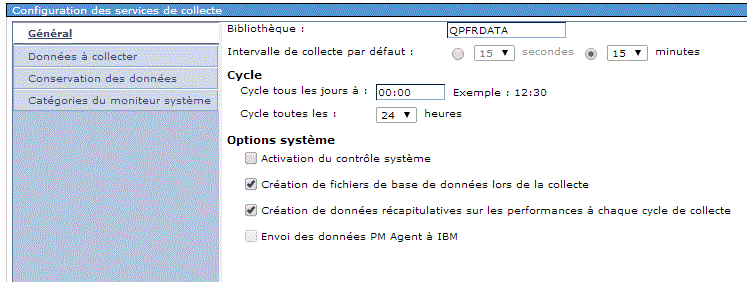



 ->
-> 

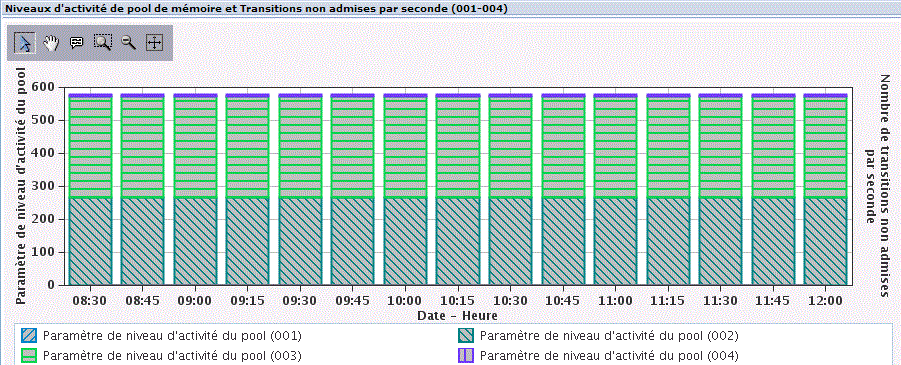

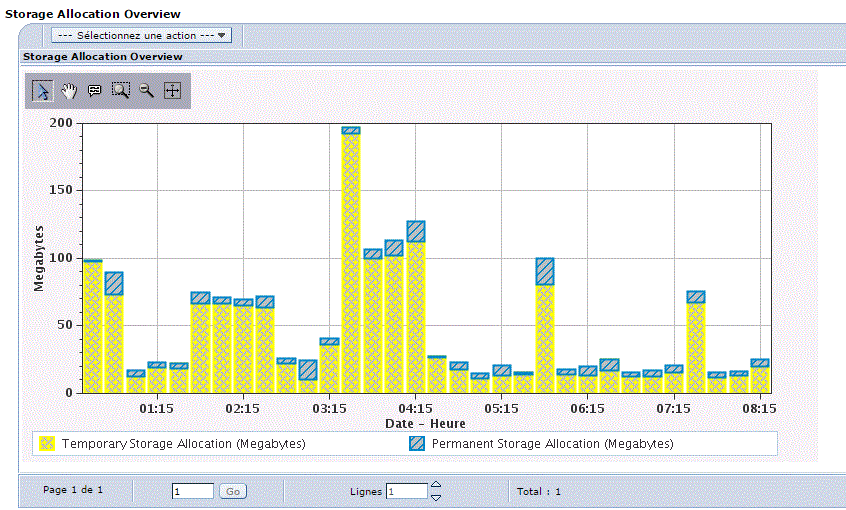
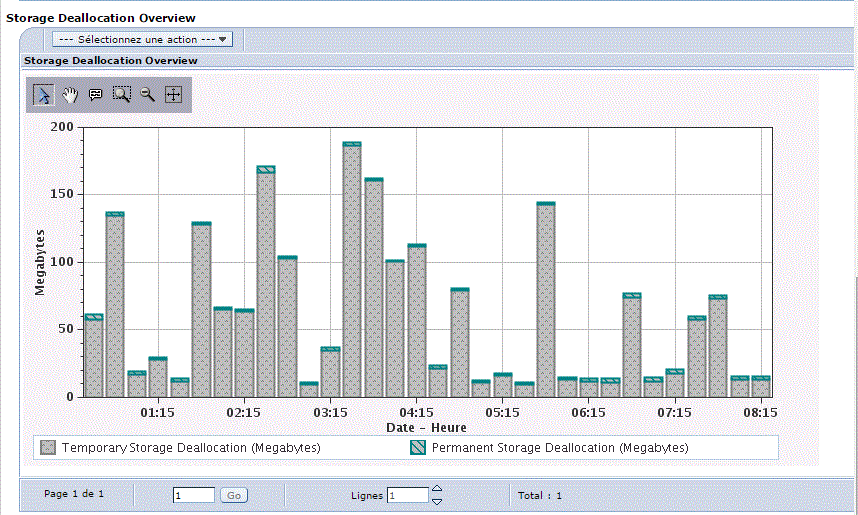
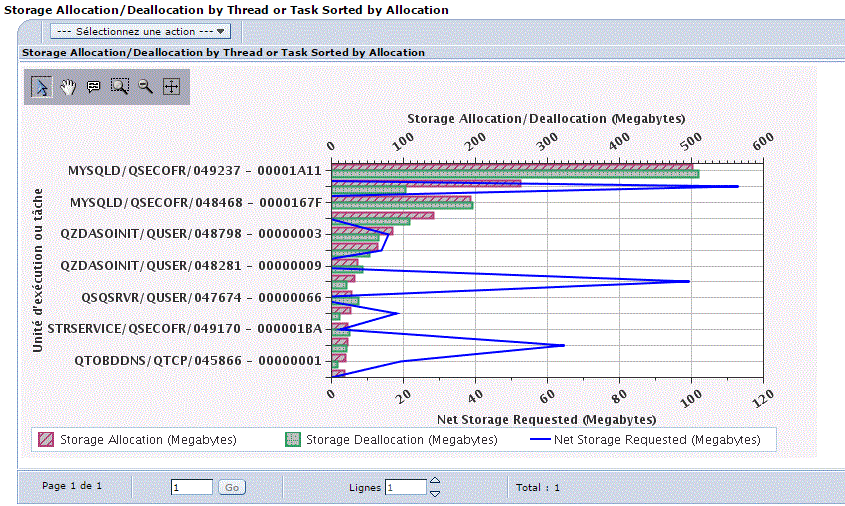
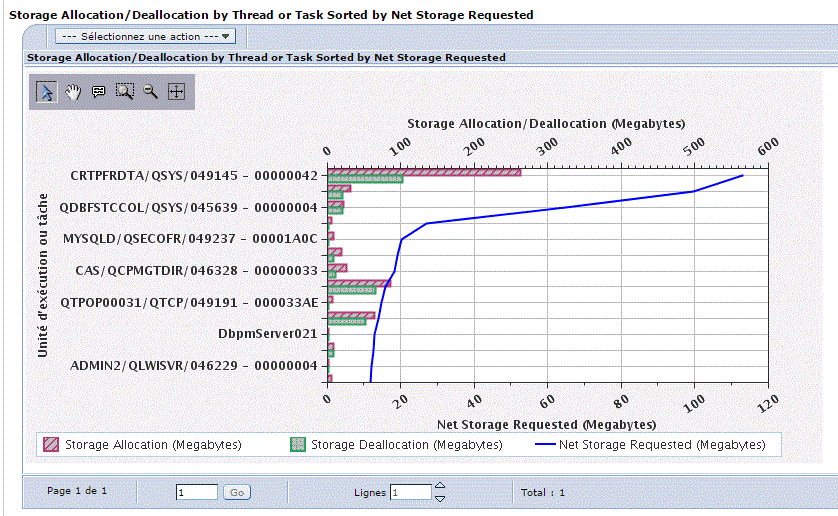
Un seau est alloué au démarrage du JOB et le lien perdure pendant la durée de ce dernier.
Quand le JOB se termine,
l'espace est normalement vide et peux donc être alloué à un autre JOB.
Si l'espace mémoire n'est pas vide, alors il s'agit d'un job n'ayant pas bien fait le "ménage" et l'état est noté *ENDED.
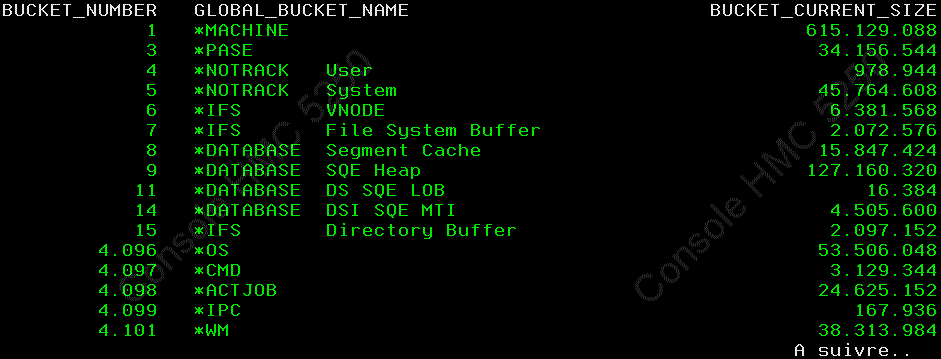
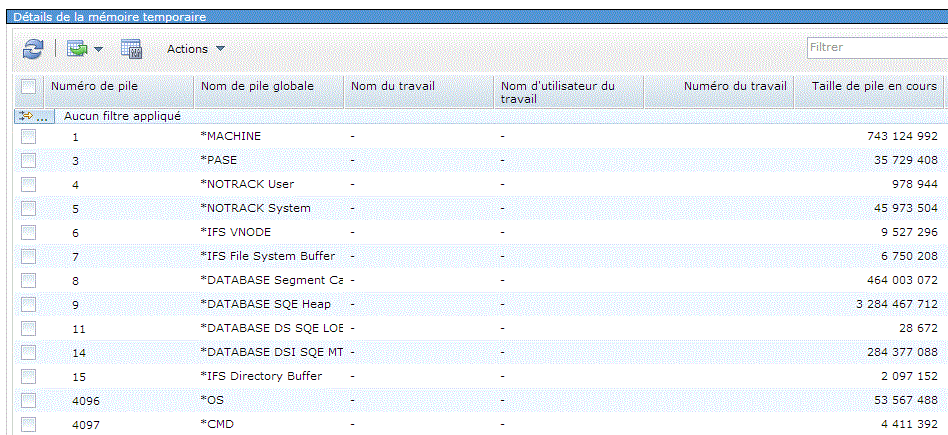
Structure de SYSTMPSTG
dans QSYS2
| BUCKET_NUMBER GLOBAL_BUCKET_NAME JOB_NAME JOB_USER_NAME JOB_NUMBER BUCKET_CURRENT_SIZE BUCKET_LIMIT_SIZE BUCKET_PEAK_SIZE JOB_STATUS JOB_ENDED_TIME |
INTEGER |
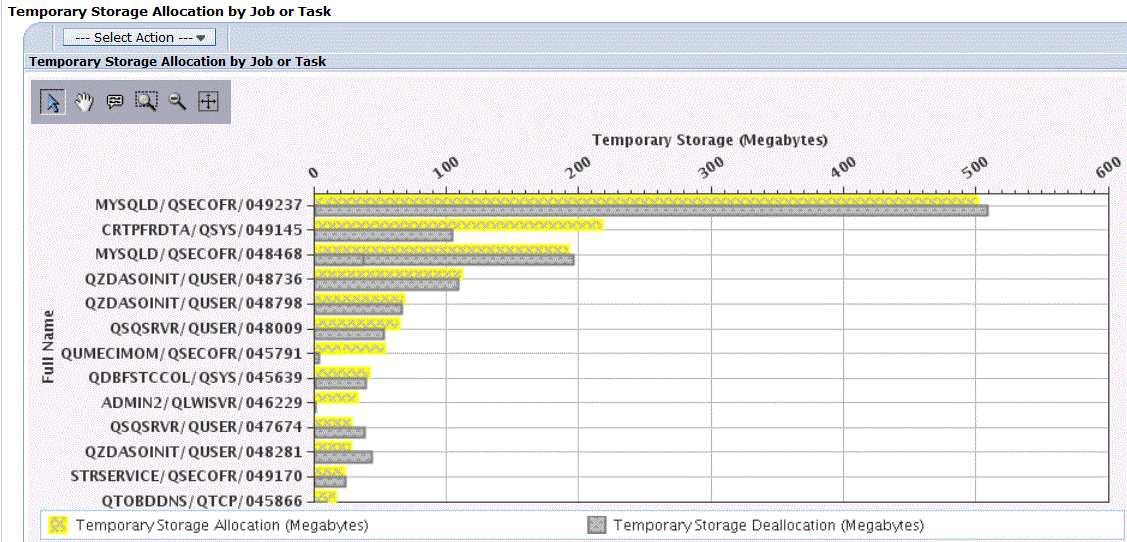
par JOB : (... WHERE JOB_NAME is not null Order by 3 DESC)
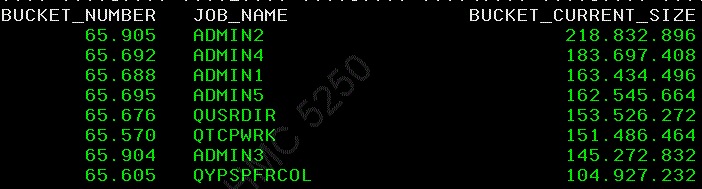
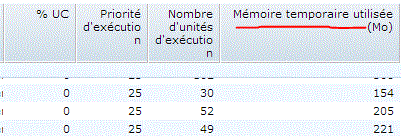
D'ailleurs la mémoire temporaire utilisée par JOB est aussi affichée sur WRKACTJOB et est un critère tri possible (F16)
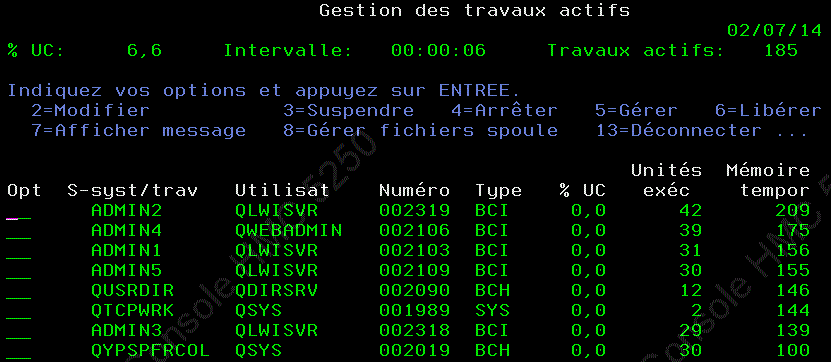
et sur le détail d'un JOB (5 / Attributs d'exécution), vous verrez maintenant :



En 7.2, deux moniteurs, déjà présents dans Gestion centralisée de la version Windows, sont ajoutés :
Moniteur système , permet de surveiller les performances
Le moniteur a été créé

On peut le visualiser dans PDI
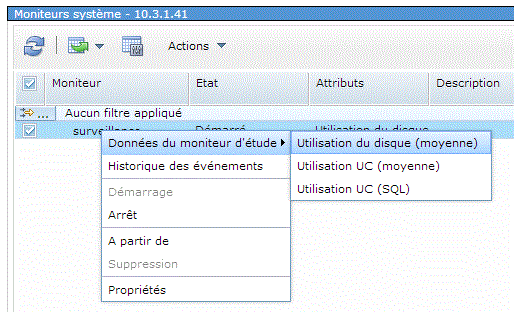
Ou, plus simple, par un clic droit après avoir coché la ligne
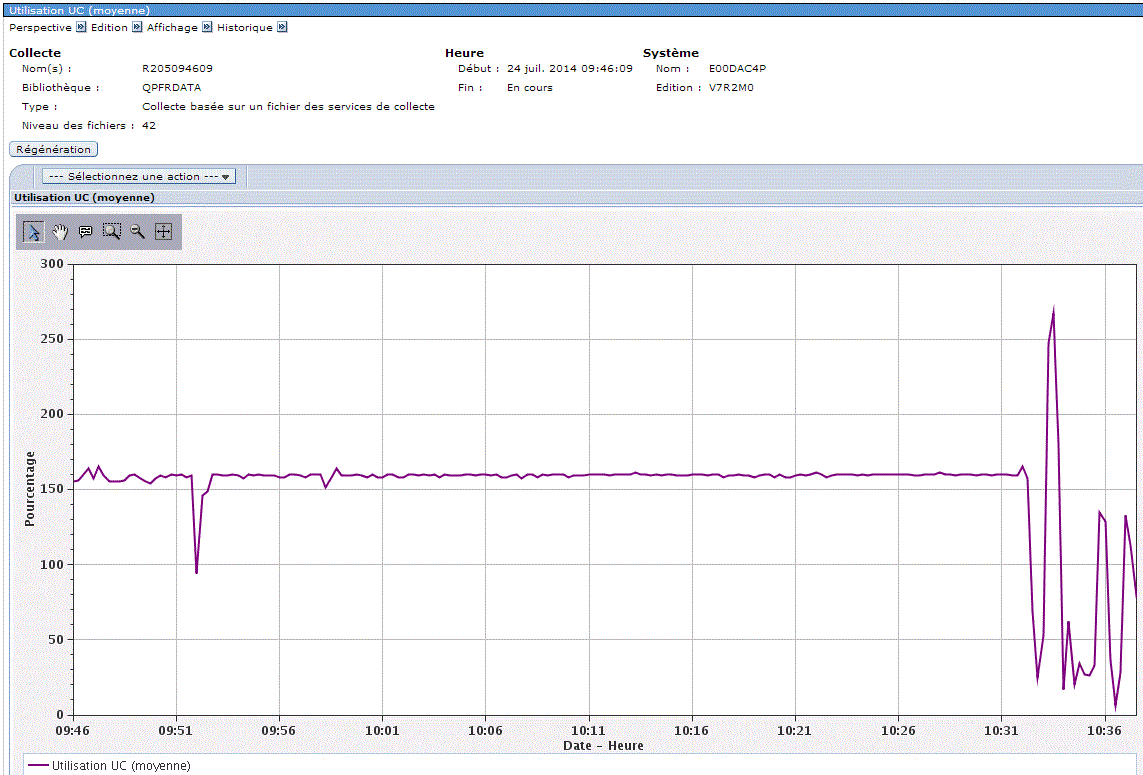
(cliquez pour agrandir)
Enfin cette nouvelle version 7.2 propose aussi un modélisation des données pour étude,
permettant de répondre aux questions :
ET si mon volume de données à traiter double ?
et si j'ajoute un processeur ?
et si j'ajoute deux disques, ai-je un véritable gain ?
Pour cela vous devez créer un modèle de traitement par lot (batch) , depuis une collecte :
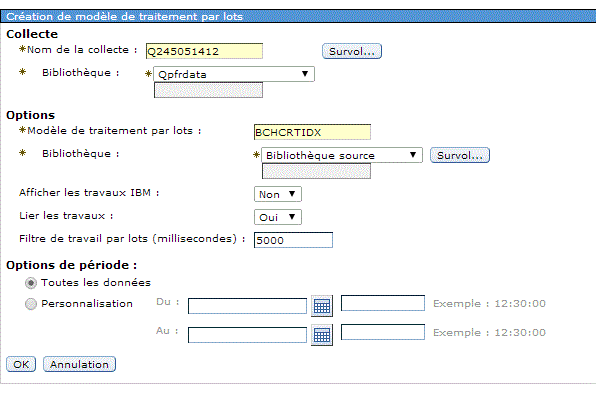
Vérifiez que les données correspondent à ce que vous voulez analyser
Regardez ensuite dans Modèle de traitement par lot, le détail des données collectées
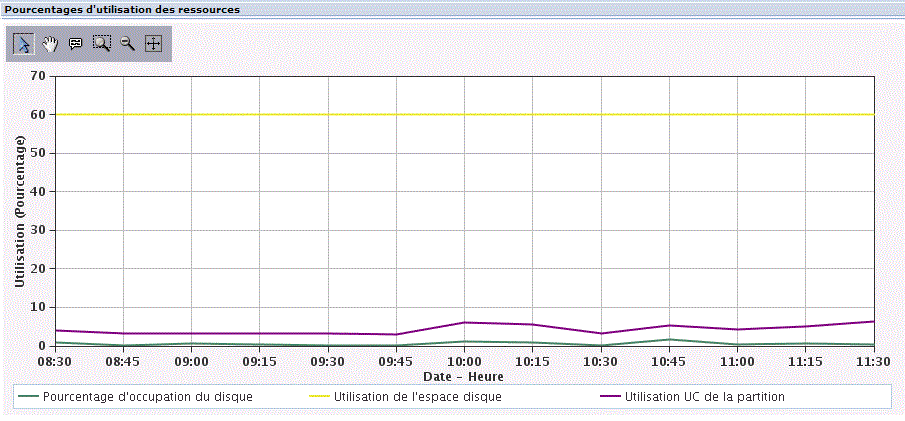
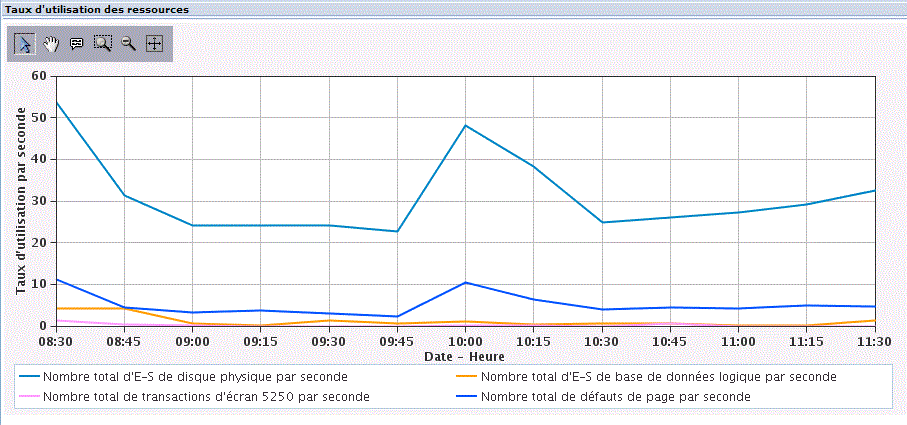
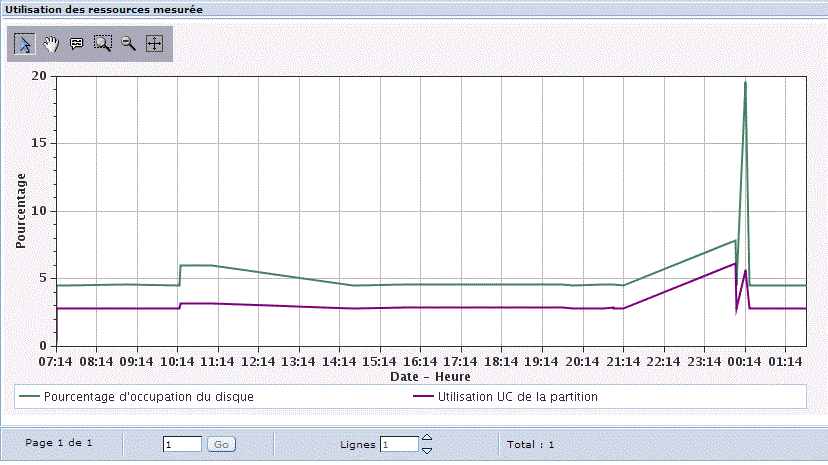
Utilisation des ressources mesurées, que vous allez modéliser
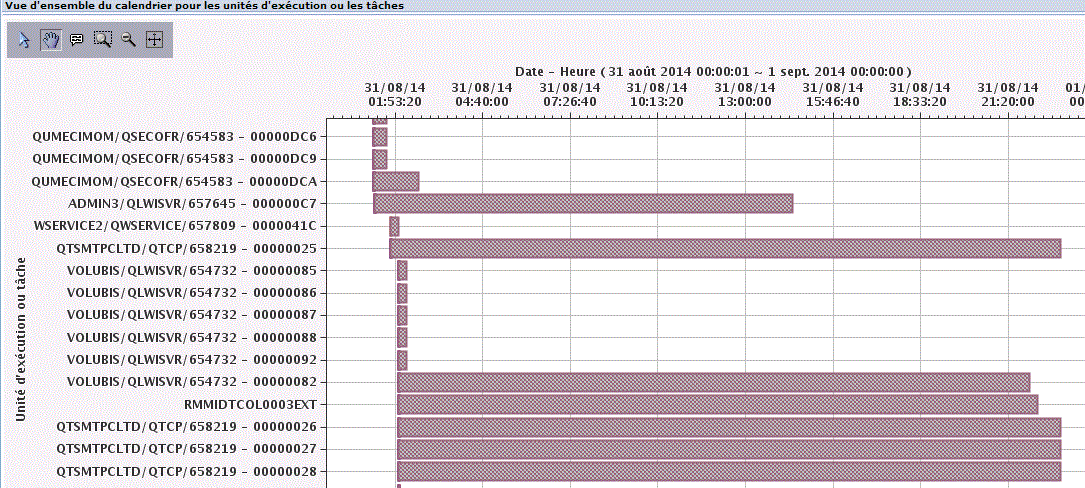
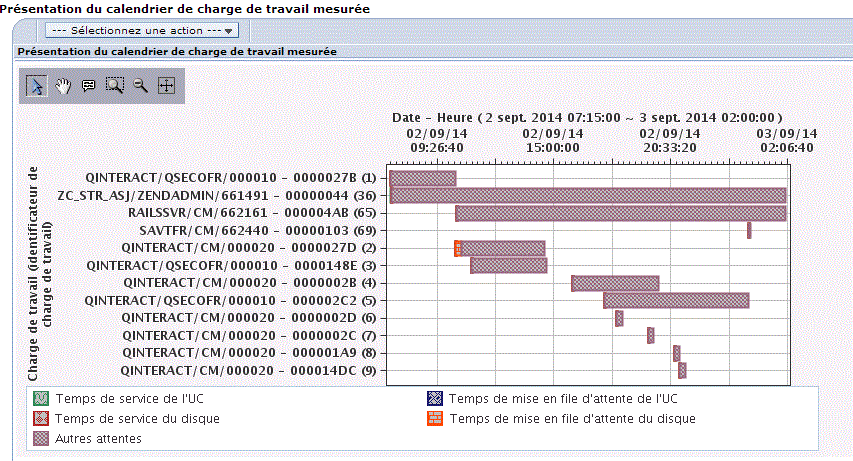
Et la répartition de la CPU dans le temps (calendrier de la charge mesurée)
Puis,
Utilisez l'option 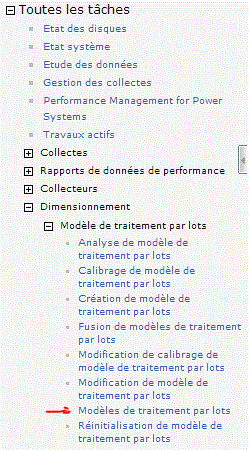 qui permet de voir la liste des modèles
qui permet de voir la liste des modèles
et cliquez droit sur le modèle que vous venez de créer
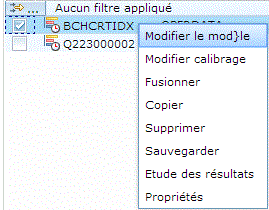
Dans un premier temps vous devez calibrer ce modèle, soit :
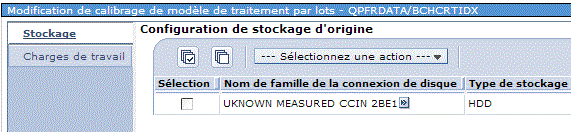
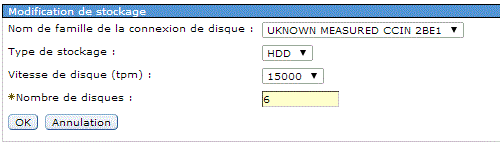
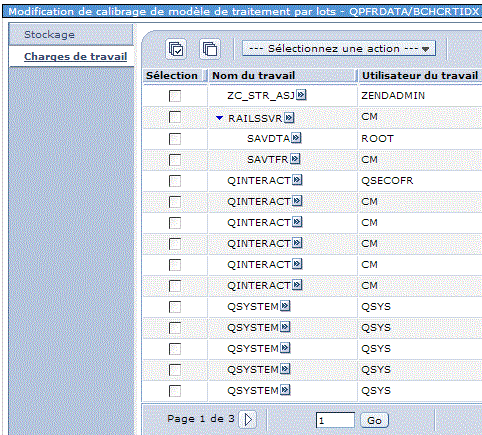
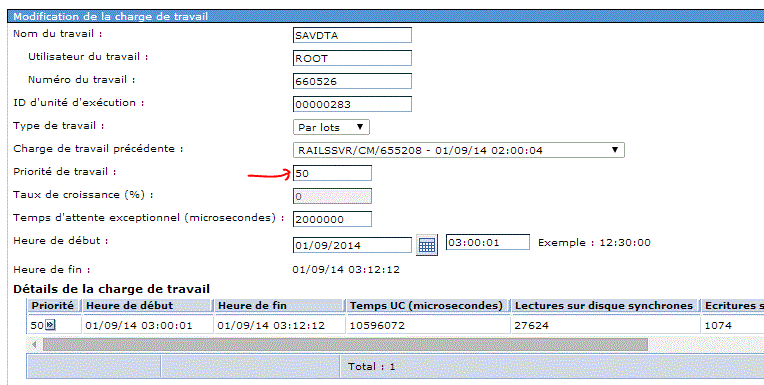
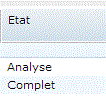
Attendez ensuite que l'état passe à Complet
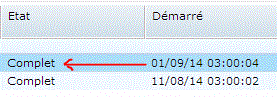
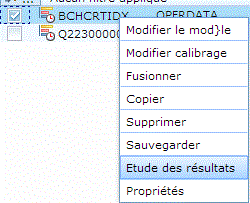
Vous pouvez alors
demander à Modifier le modèle
•taux de croissance prévu : (et si ma volumétrie double ?)

•processeur (et si j'en ajoute 1 ?)
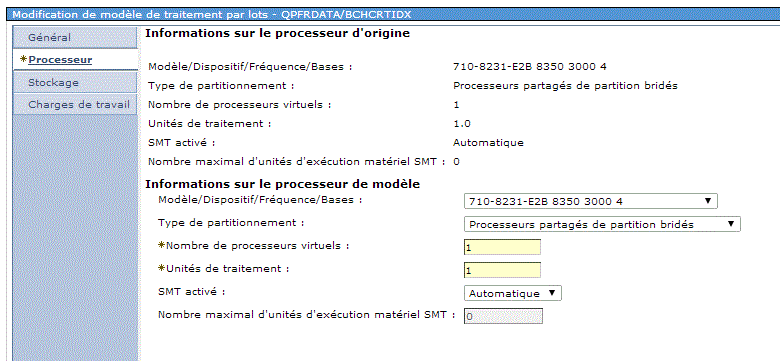
•disque (et si j'en achète deux ?)
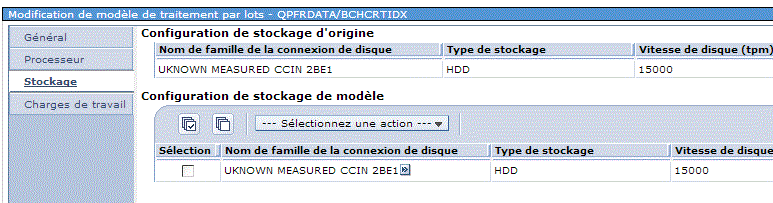
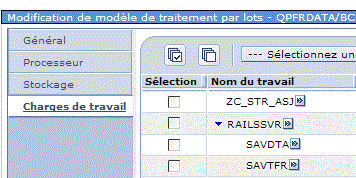
•charge de travail (et si je baisse la priorité des travaux concurrents ?)
Confirmez

L'état passe à Analyse, puis repasse à Complet
demandez l'étude des résultats :
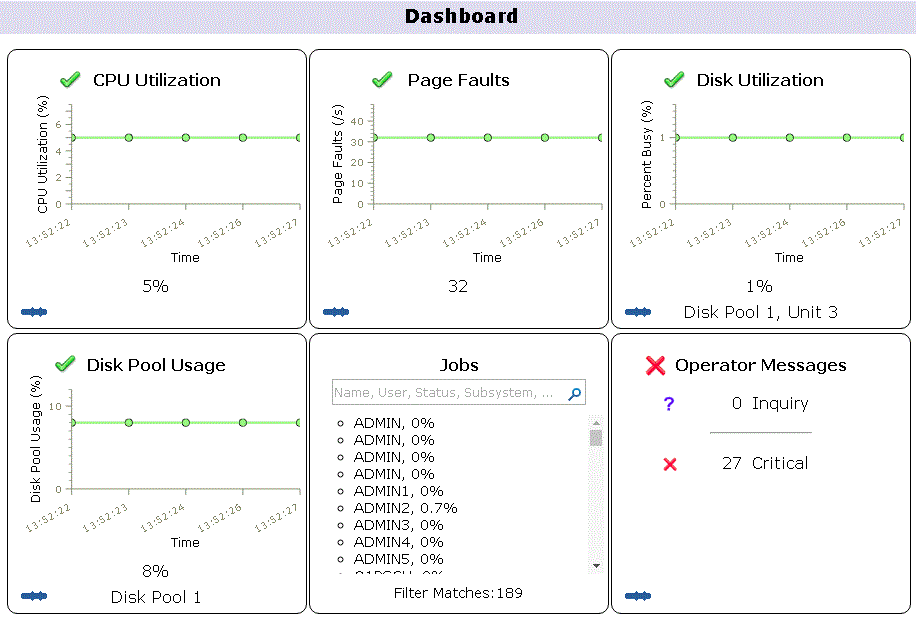
Enfin en version 7.3 , la page d'accueil de Navigator for I affiche un tableau de bord contenant des informations de performances


Copyright © 1995,2017 VOLUBIS