un critère de tri particulier (index)
un format d'enregistrement particulier (sélection de
lignes, reformatage des colonnes, jointure)
Rappels sur les concepts de développement
La définition de la base de données peut être fait de deux manières :
- Langage historique SDD ou DDS
- SQL permettant le support de plus de types de données (voir ci-dessous)
L'accès à la base peut se faire selon deux modes :
- Accès séquentiel indexé (dit "natif")
- SQL embarqué
L'accès natif :
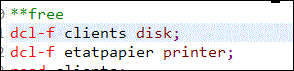
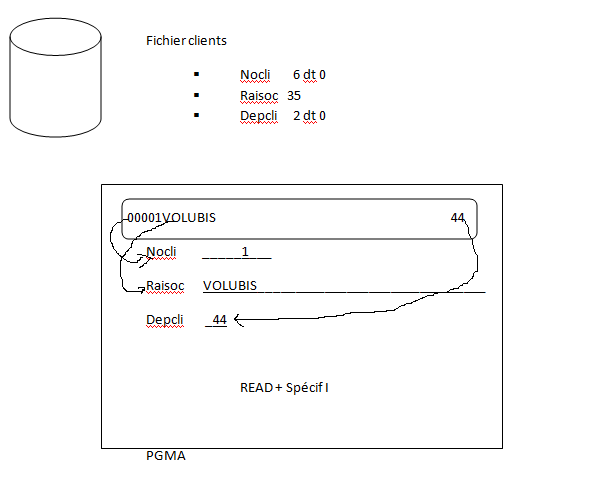
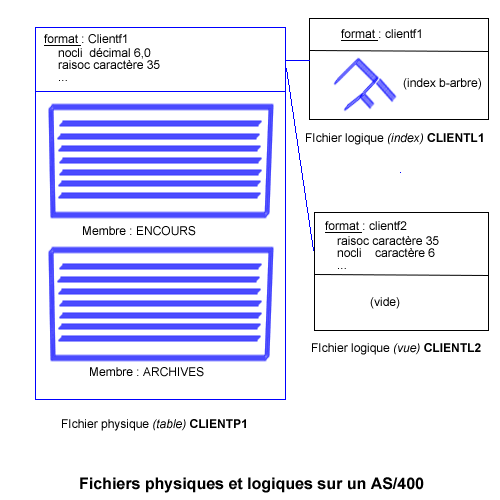
Les fichiers sont déclarés par le biais de "spécif F", une par fichier manipulé :
Attention, chaque nom doit être unique :
nom de fichier ET nom de format
(pourtant SQL par défaut donne un nom de format identique à la table, il faut alors utiliser RENAME)nom de fichier ET nom de zone
noms de zone identiques ayant des attributs différents
(nocli qui fait 6 dans le fichier clients et 7 dans le fichier commandes)
- types de fichiers reconnus
- DISK, base de données
- PRINTER, imprimante, génère un spool
- WORKSTN, gère l'affichage sur un terminal
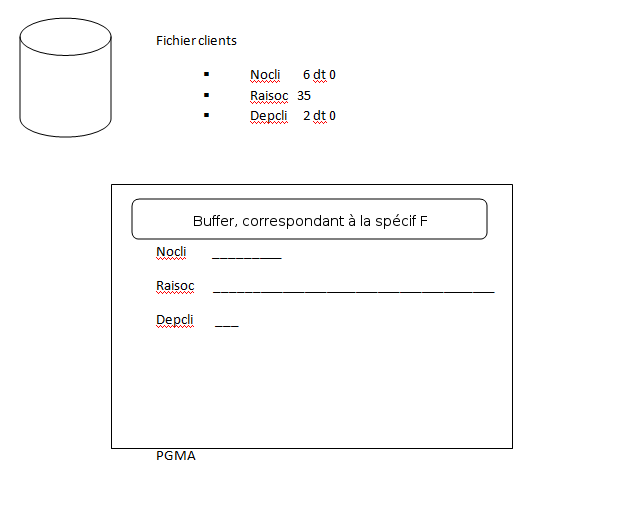
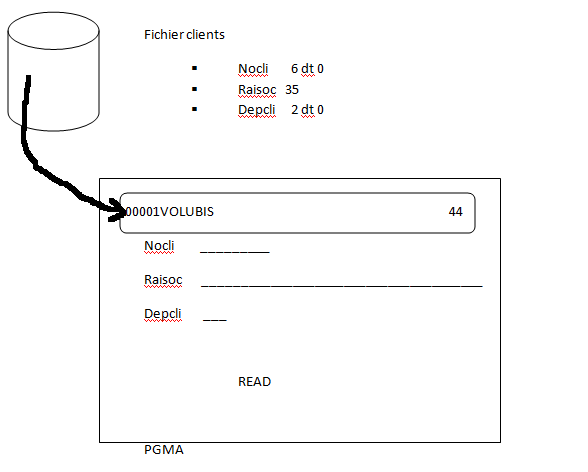
Quand le fichier est déclaré, le compilateur prévoit un "buffer" pour recevoir les lignes lues :
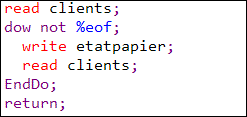
- READ, accès séquentiel de la ligne suivante
- CHAIN, accès direct à une ligne dont on fournit la clé
mais aussi
- WRITE, écriture d'une nouvelle ligne
- UPDATE, mise à jour de la dernière ligne lue
- DELETE, suppression de la dernière ligne lue
Le compilateur RPG a aussi prévu une variable RPG par colonne base de données, et celles-ci sont automatiquement alimentées par des spécif "I"
A noter qu'il se passe exactement l'opération inverse lors d'une écriture
- Alimentation du buffer à partir des variables RPG
- écriture de ce buffer
Le compilateur doit être appelé, il va créé un objet *PGM, autonome quant à son exécution.
En cas de modification de la structure, pour éviter un décalage lors des lectures :
- le système affecte à chaque fichier un Format Level Identifier
- ce niveau de format est mémorisé dans le programme par le compilateur
- il testé lors de l'exécution (précisément lors de l'OPEN)
- si le niveau mémorisé n'est pas le niveau rencontré => génération d'une ERREUR GRAVE !
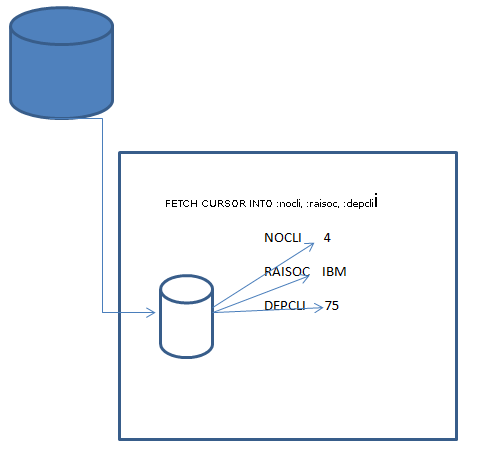
Ce n'est pas le cas avec SQL qui utilise des curseurs
et place directement les données du curseur dans des variables RPG (pas de buffer)
Comment moderniser la base de données / SQL vs DDS.
Le langage SQL est composé de sous ensembles
DDL
Data Definition Language (DDL) , instructions de création et de maintenance de la structure base de données
- CREATE - création d'objets
- ALTER - modification de structure
- DROP - suppression d'objets
- LABEL / COMMENT - documentation
- RENAME - renommage d'objet
DML
Data Manipulation Language (DML) instructions de manipulation de données:
- SELECT - lecture de données
- INSERT - insertion de données
- UPDATE - mise à jour de données
- DELETE - suppression de données
- MERGE - (insert or update)
- CALL - Appel d'une procédure cataloguée
DCL
Data Control Language (DCL) instructions de gestion des droits:
- GRANT - accord de droits
- REVOKE - retrait de droits
Autant l'utilisation de DML se démocratise chez les clients IBM i , autant DDL reste minoritaire...
Pourtant IBM préconise l'utilisation de SQL (DDL) pour concevoir la base de données.
- Les dernières modifications importantes de SDD datent de la V2R11 (1992 de mémoire...), sont mineures ensuite.
- variables dates/heures , valeur nulle (V2)
- support UNICODE (V5)
- PAGESIZE sur CRTLF (V5)
- Support disques SSD (V6)
- paramètre KEEPINMEM (V7)
- Toutes les autres avancées sont liées à SQL
- Nouveaux types
- Dates/Heures et valeur nulle sont intégrés au SQL de base
- BLOB /CLOB (champs images, PDF)
- OmniFind sait indexer de tels champs
- DATALINK
- champs de type URL avec possibilité de contrôle de l'existence du fichier dans l'IFS.
- NCHAR
- DECFLOAT
- ROWID
- zones auto-incrémentées (AS IDENTITY)
- SEQUENCES
- attribut HIDDEN
- cette colonne est cachée par défaut (SELECT * FROM ... ne la montre pas)
- attribut AS ROW CHANGE TIMESTAMP
- ce TIMESTAMP contient automatiquement date/heure de dernière modification.
- XML
- Intégrité référentielle directement définie avec la table (syntaxe SQL)
- Index EVI pour le BI
- FIELDPROC pour crypter les données
- TRIGGER à la colonne
Attention à la terminologie
Quels sont les avantages de SQL pour la création de tables
- plus de types de données disponibles, nous venons de le voir
- les contraintes sont définies dans le même source, le même langage
- noms plus longs
- 30 c. pour les noms de zone
- 128c pour les noms de table
- lectures plus rapides
En effet, pour des raisons historiques (fichiers décrits en internes) les fichiers créés par SDD ne controlent pas la données insérée.
(il est ainsi possible de stocker "ABC" dans une zone numérique, si vous utilisez des spécifs O en RPG).
En contrepartie, lors de l'utilisation de ces fichier sur un mode externe ou par SQL la donnée est controlée lors de la lecture,
d'où une perte de temps (nous réalisons en général plus d electures que d'écritures sur nos bases)
- Historiquement, journalisation automatique. Désormais nous pouvons utiliser STRJRNLIB
- Possibilité d'utiliser des outils de modélisation (IBM Infosphere Data Architect, Mega Database Builder ou XCASE vu plus loin, par exemple)
- CREATE or REPLACE TABLE (verison 7.2 niveau de correctif TR2)
Quels sont les inconvénients de SQL pour la création de tables
- Ecritures plus lentes (contrôle de la donnée)
- pas de DDM (possibilité d'utiliser DRDA)
- gestion plus complexe des Multi-membres (ALIAS)
Quels sont les avantages de SQL pour la création d'index (vs LF)
- Choix du type (b-arbre ou EVI)
- Pages de 64 K
- Ces index à larges pages sont plus efficaces lors de manipulation de volumes
- les indexs créés par SDD ont des pages de 8k plus efficaces pour recherche une donnée unitaire (CHAIN en RPG)
- Depuis la V6, les index peuvent avoir
- une clé composée
- une sélection
where raisoc <> ' ' and nocli > 1 ;- un format particulier
RCDFMT clientf8 add raisoc ; -- en plus de la clé
Quels sont les avantages de SQL pour la création de vue (vs LF)
- Beaucoup plus de puissance
- une vue peut avoir une jointure interne et les autres externes gauche
- une vue peut retourner des données agrégées (GROUP BY, GROUP BY ROLLUP)
- une vue peut avoir une sélection utilisant toute la puissance du WHERE SQL (CASE par exemple)
- une vue peut utiliser une fonction "maison" c.a.d une UDF
(select nocli, raisoc, dispo(nocli)
from clients) ;- une vue peut utiliser une UDTF (fonction retournant une table à partir de données non BdeD)
(select * FROM TABLE (litrepertoire('/PDF') as PDF);
- Attention, les vues ne sont pas indexées
- C'est un problème pour remplacer un LF par une vue sur une spécif F RPG
(mais revoyez les nouvelles possibilités des index SQL)- Ce n'est pas un problème lors d'un accès SQL, c'est le moteur qui trouve tout seul le meilleur chemin
Nous savions déjà que SQL sait utiliser des objets créés par SDD, mais les programmes natifs peuvent aussi utiliser des objets SQL
- Bien sûr SQL sait utiliser des fichiers physiques créés par SDD
- Un INDEX SQL fait une bonne spécif F en RPG.
- Une vue SQL peut-être utiliser en progammation RPG (accès séquentiel uniquement)
- on peut :
- créer des index ou des vues SQL sur des physiques SDD
- créer des logiques SDD sur des tables SQL, ce que nous allons voir
Tout cela en attendant d'être FULL SQL ;-)
Voici la vision d'IBM concernant la phase de transition de modernisation de la base de données
Modernisation, phase 1
la phase 2 consiste à faire des modules d'accès à la base (*SRVPGM par exemple)la phase 3 à reporter sur la base de données un maximum de logique métier
- Intégrité référentielle
- contraintes
- Cryptage de données
- Auto-Incrémentation
enfin, la phase 4 propose d'externaliser l'accès aux données
- User Defined Fonction (UDF et UDTF)
- Procédures cataloguées
- etc....
Revenons à l'étape 1, le principe est le suivant :
- Conversion des fichiers physiques en tables SQL
- Création d'un logique SDD ayant le même format que l'ancien physique
- Recréation des différents logiques
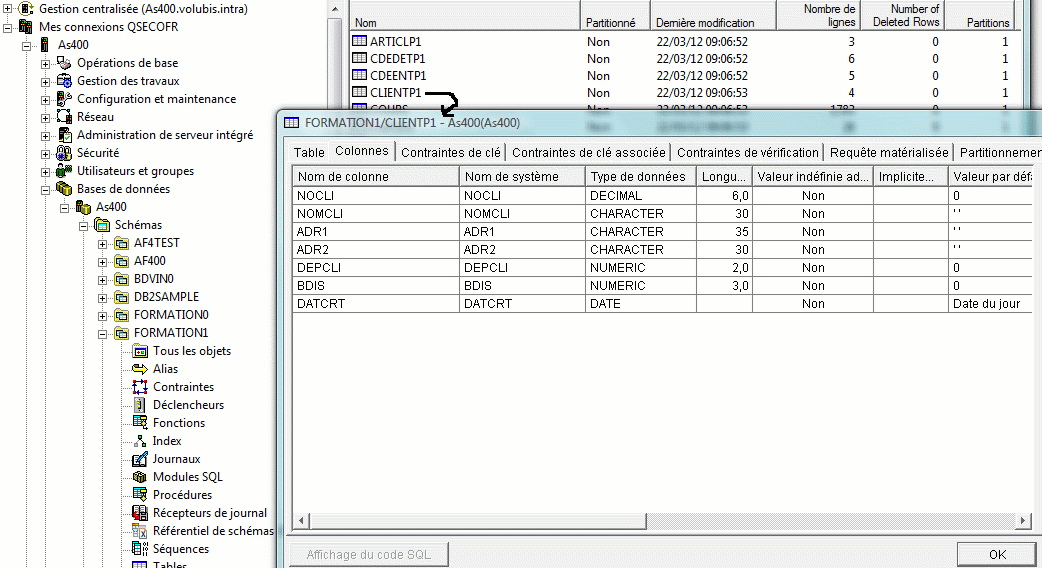
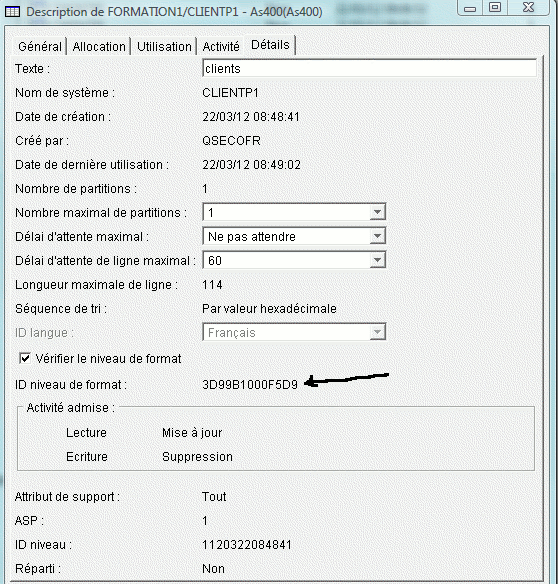
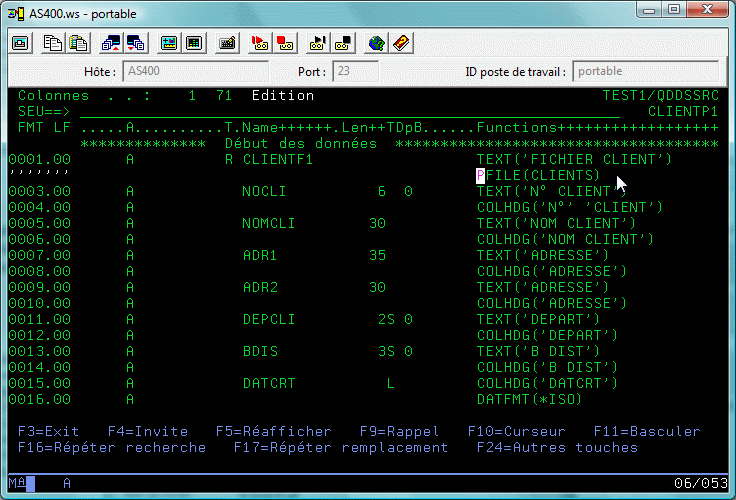
Partons donc d'un fichier physique existant (bibliothèque FORMATION1) que nous souhaitons "moderniser" dans le Schéma TEST1
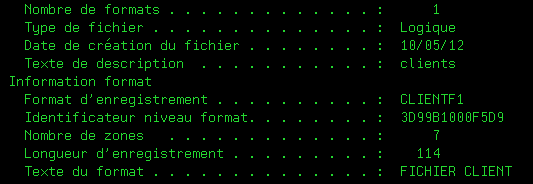
dont voici l'identifiant de format (3D99B1000F5D9)
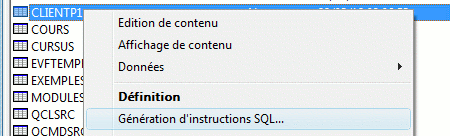
La fonction génération d'instructions SQL permet de retrouver le source SQL
y compris des fichiers créés par SDD
Les fonctions non supportées sont notées en commentaire
- SQL1509 nom de format ignoré (inutile depuis que SQL admet la clause RCDFMT)
- SQL150B attribut de la table ignoré, REUSEDLT(*NO) par exemple
- SQL150D attribut de la colonne ignoré, EDTCDE par exemple
Que nous transformons en :
Nous aurions aussi pu ajouter une zone AS ROW CHANGE TIMESTAMP, par exemple.
Créons ensuite le logique portant le même nom que l'ancien physique SDD
Vérifions
Proposition de stratégie pour moderniser les programmes
- Moderniser Le code (RPG particulièrement)
- Pour nous cela est clair, à partir de maintenant, il faut écrire vos programmes en free-form RPG
- plus lisible
- plus facile d'intégrer de jeunes développeurs
- plus facile d'évoluer, de basculer vers d'autres langages
- faut-il revoir l'existant ?
- des outils vous le propose
- A la main, c'est compliqué (CVTRPGSRC ne fait pas vraiment le boulot !)
- mais apprendre le GAP III (ou II) au moins de 30 ans, est-ce raisonnable ?
- Moderniser l'architecture
- MVC

Le pgm qui constitue la donnée (qui fait la liste, qui valorise la données, etc...) n'est PAS le programme qui affiche !
Le pgm qui écrit/met à jour la donnée, est autonome, unique !
- SOA
un programme=un service / un service(un besoin)=un programme
les autres concepts sont un peu plus compliqués à matérialiser, surtout sur des langages procéduraux.
Tout programme, peut ainsi devenir :
- une fonction SQL
- une procédure stockées pour ODBC/JDBC
- un service web (Couplages externes "lâches") qui respectent le mieux l'architecture SOA
Exemple
Il parait assez simple d'imaginer un programme réalisant (de manière autonome) la mise à jour d'un fichier

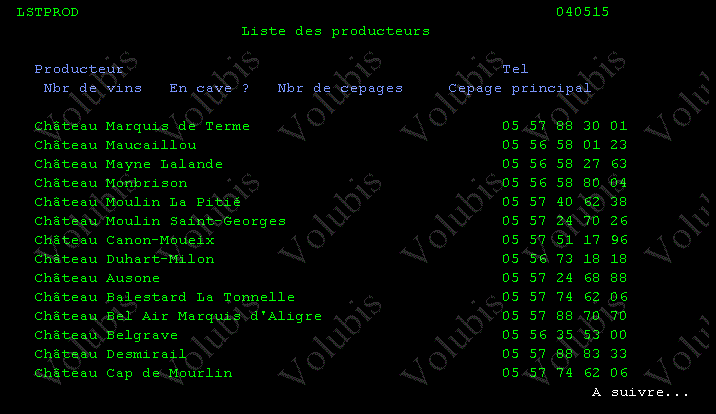
Regardons plutôt un programme de constitution d'une liste de données valorisées.
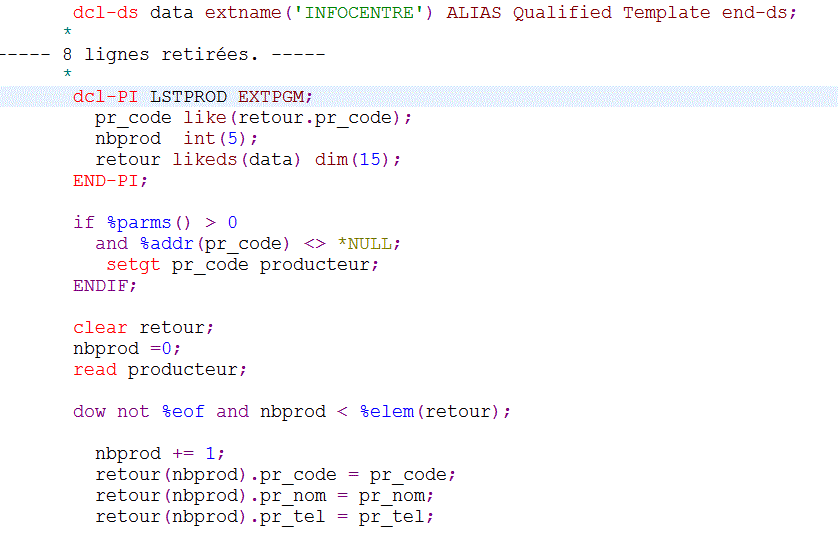
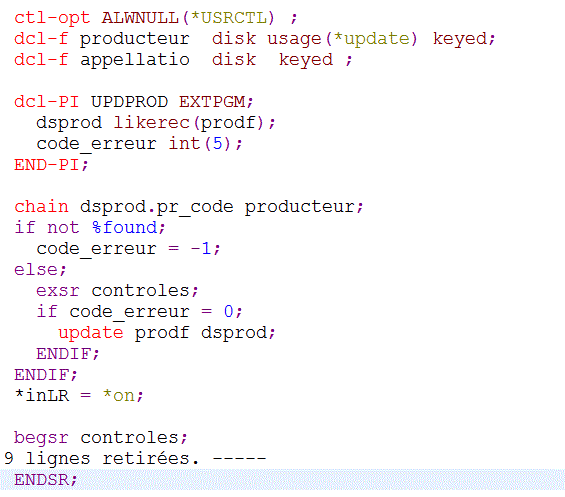
Soit un programme (sans doute avec une partie du code hérité d'un ancien traitement)
Qui retourne des informations concernant les 15 producteurs qui suivent (SETGT) celui passé en paramètre
Ce pgm a trois paramètres en entrée
- Pr_code pour le positionnement
- NbProd pour retourner le nombre lu
- Retour DS à 15 occurrences
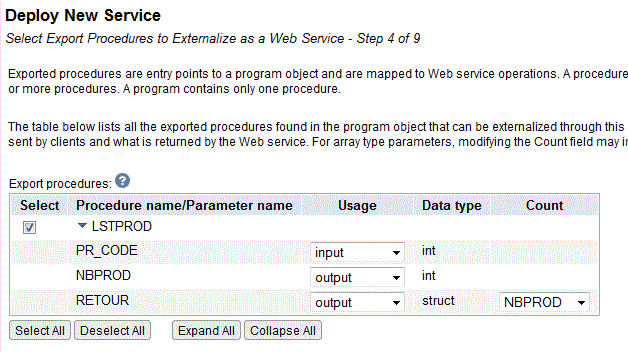
Ce programme peut facilement être transformé en Web service (ici SOAP)
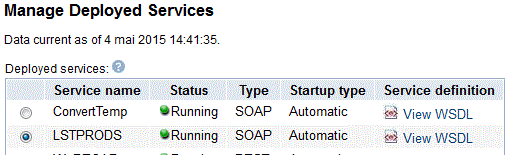
Testons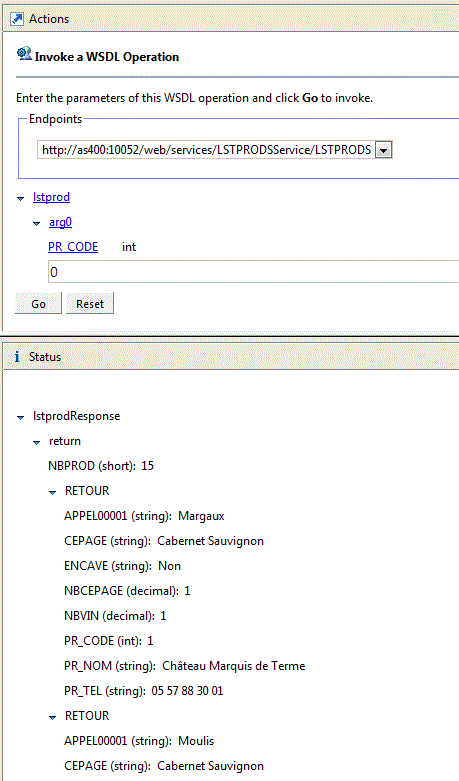
Mais aussi, avec les derniers niveaux de PTF, en web service REST
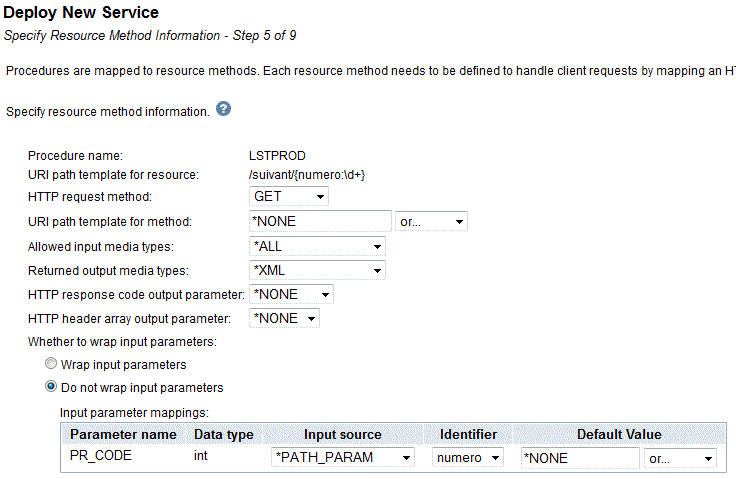
et voilà
Donc lancé, depuis une simple URL
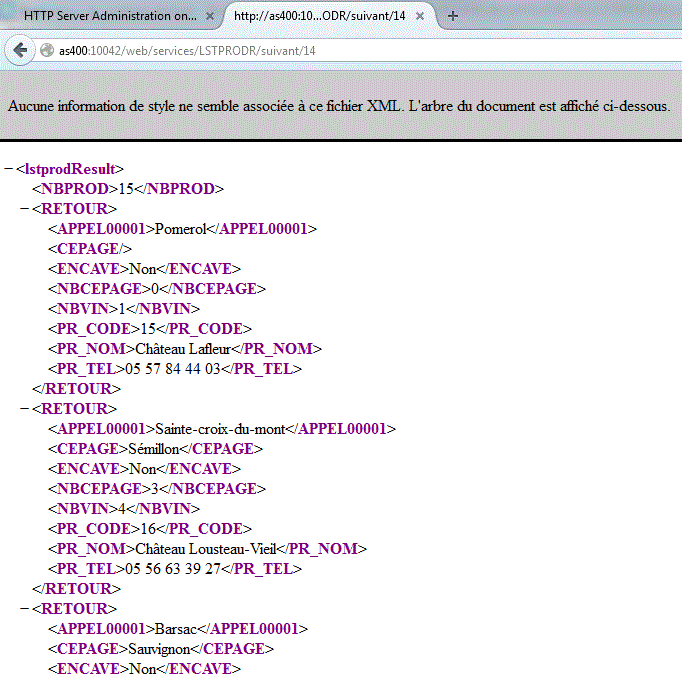
voire, utilisé en SQL (fonction HTTPGETBLOB + XMLTABLE)
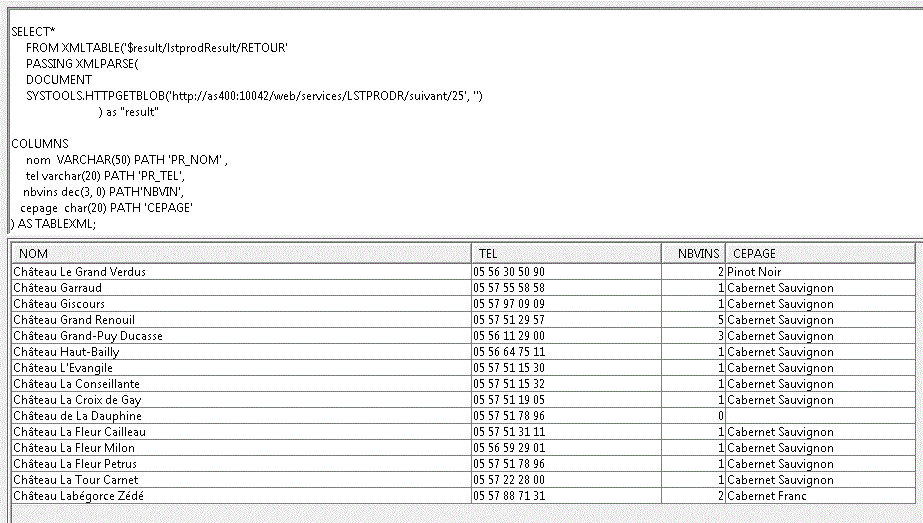
Ou si vous le préférez, transformé en Procédure stockée (on ajoute une interface pour gérer le RESULT SET SQL)
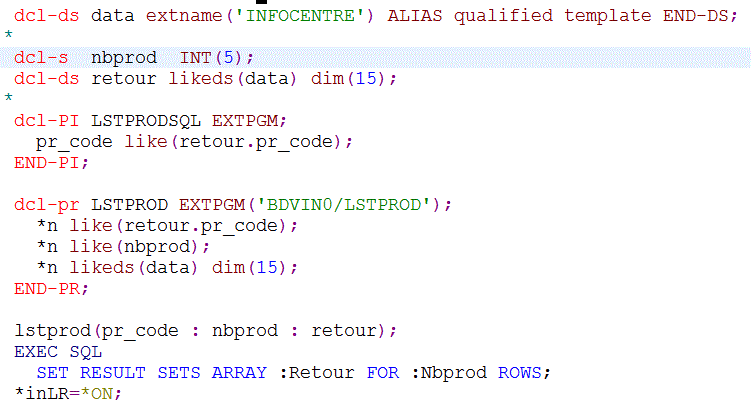
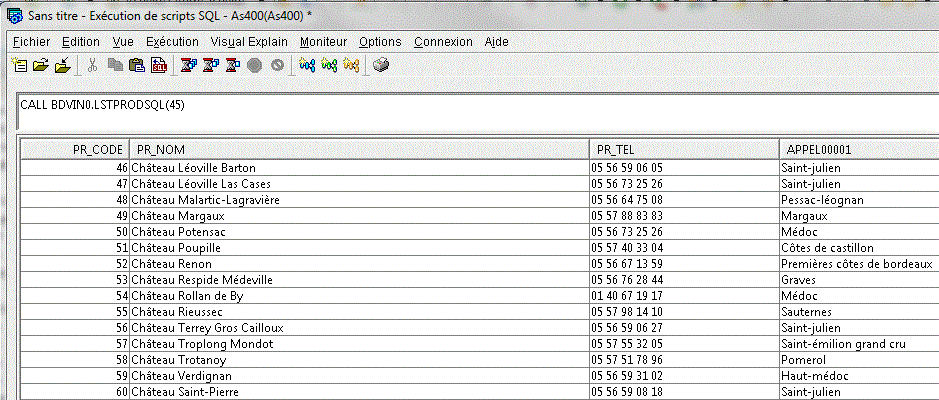
ET il devient utilisable directement, via JDBC/ODBC
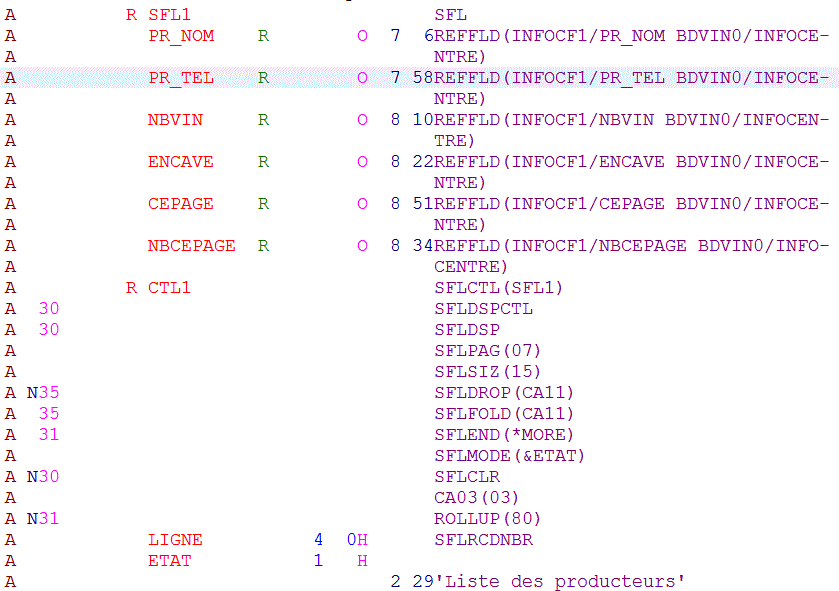
Enfin, le monde 5250 n'est pas oublié pour autantsoi le DSPF suivant (avec sous fichier)
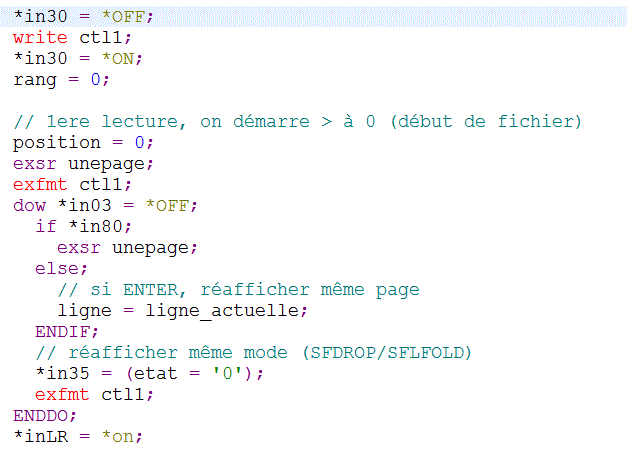
ET le PGM RPG
déclarations
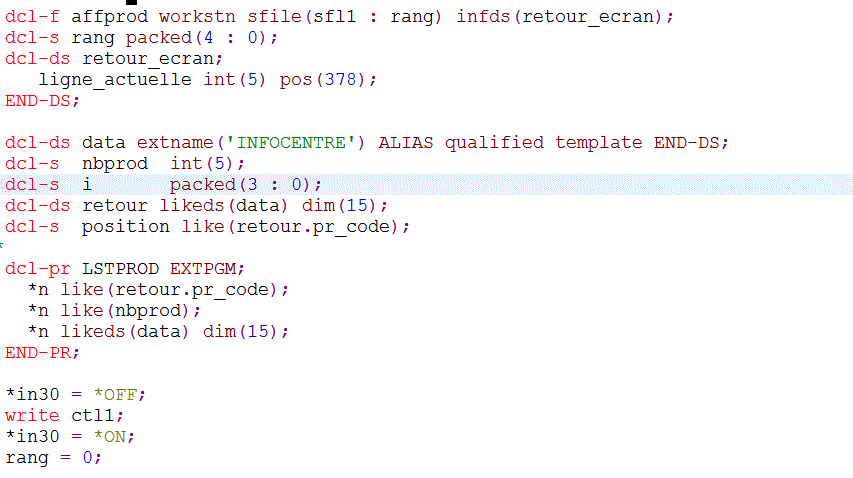
boucle principale
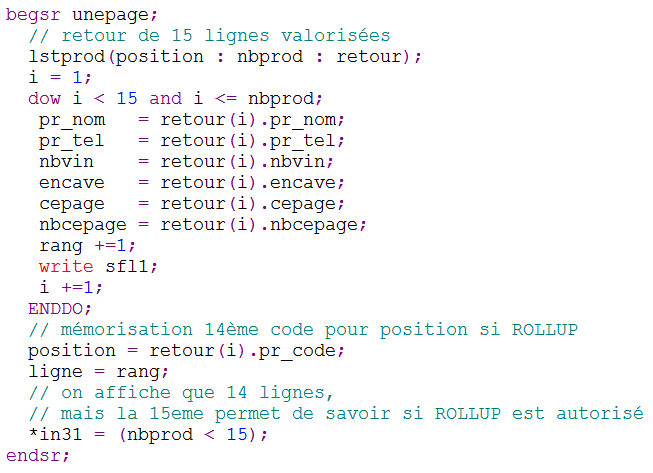
Sous programme de chargement d'une page
On ne charge que 14 lignes par page (SFLPAG)
Remarquez la gestion de l'indicateur 31, qui teste s'il y a 15 lignes (au moins encore une ligne = ROLLUP autorisé)
Résultat
© AF400 - Volubis