pause-café
destinée aux informaticiens sur plateforme IBM i.
Pause-café #73
TR4
TR4 (toutes ces fonctions sont aussi présentes en 7.3)
-
•Fonctions modifiées
•TIMESTAMP_FORMAT, accepte désormais•AP/PM
•Day -> nom du jour (extrait du message CPX90346)
•Dd -> nom abrégé du jour (extrait du message CPX9039)
•D -> jour de la semaine (entre 1 et 7)
•DDD -> n° de jour dans l’année
•HH12 -> heure sur 12 (avec AM/PM)
•J -> Nb de jours depuis calendrier julien (1er janv. 4713 Av J.C)
•Month -> nom du mois (extrait du message CPX3Bc0)
•Mon -> nom abrégé du mois (extrait du message CPX8601)
•RRRR -> année ajustée (arrondie sur année 50)
•SSSSS -> secondes depuis minuit précédent
•Y -> dernier chiffre de l’année
•YYY -> trois derniers chiffres de l’année

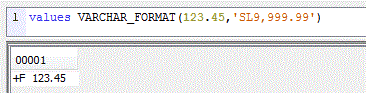
- •VARCHAR_FORMAT
• accepte désormais de transformer du numérique en VARCHAR
Dans ce cas, les codes suivants sont admis•0 -> représente un chiffre, les zéros de gauche sont affichés
•9 -> représente un chiffre, les zéros de gauche ne sont pas affichés
•S -> préfixe, représente le signe (- ou +) à gauche
•$ -> un dollar est ajouté
•MI -> Suffixe, représente le signe (- ou espace)
•PR -> les caractères < et > sont ajoutés en cas de valeur négative
•, -> la marque décimale est la virgule
•. -> la marque décimale est le point
•L -> symbole monétaire (extrait du message CPX8416)
•D -> marque décimale (extrait du message CPX8416)
•G -> séparateur des milliers (extrait du message CPX8416)
-
•ROUNDED•Accepte désormais de travailler avec un seul argument, l’arrondi se fait sur la partie entière
-
•TRUNCATE•Accepte désormais de travailler avec un seul argument, la troncature se fait sur la partie entière
- •VARCHAR_FORMAT
-
•Services (DB2 for I service) améliorés
Des informations supplémentaires sont retournées, pour- La procédure stockée SET_SERVER_SBS_ROUTING permettant de re-router un job serveur vers un sous-système
- Admet maintenant :
- le profil
- le Job serveur
- Admet maintenant :
- QRWTSRVR (DRDA/DDM)
- QZDASOINIT (ODBC/JDBC)
- QZRCSRVS (Serveur de commandes à distance)
- QZSCSRVS (central)
- QZHQSSRV (Data Queue)
- QPWFSERVSO (partage de fichiers)
- QNPSERVS (partage d'imprimante)
- le sous-système
- allow rollover
- YES comme avant, si le sous-système ne peux pas prendre le JOB, il va dans QUSRWRK
- NO, si le sous-système ne peux pas prendre le JOB, il ne démarre pas
- La procédure stockée SET_SERVER_SBS_ROUTING permettant de re-router un job serveur vers un sous-système
-
•Services (DB2 for I service) , nouveaux services
QSYS2.ENVIRONMENT_VARIABLE_INFO
Donne la liste des variables d’environnement (WRKENVVAR)
Donne la liste des services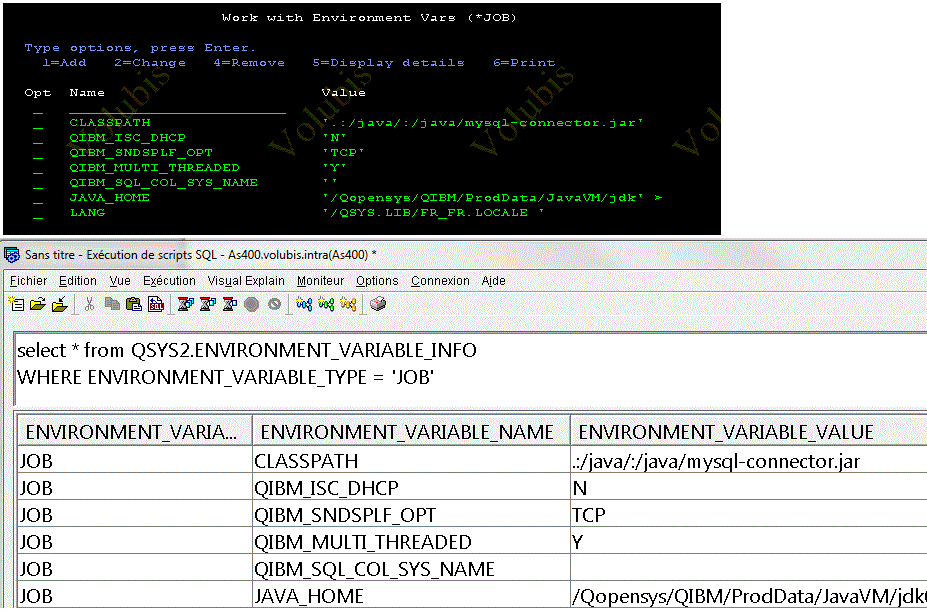

Un service qui donne la liste des services ;-)
mais qui surtout explique les utilisations possibles


-
•Nouvelle option dans QAQQINI, favorisant la modification d’une base en production.•ALLOW_DDL_CHANGES_WHILE_OPEN
•*YES
Possibilité d’ajouter un trigger (CREATE TRIGGER ou ADDPFTRG) sur une table en cours d’utilisation
•*NO
Aucun ajout de trigger n’est autorisé quand un fichier est en cours d’utilisation, vous recevez SQL0913
(qui maintenant contient les coordonnées du JOB qui lock)
- Nouvelles variables globales
-
PROCESS_ID
-
THREAD_ID
Automatiquement renseignées, en lecture seule
-
V7R30
Nouveautés de la version 7.3
Version 7.3
- Annoncée le 12 Avril 2016 (disponible au 15)
- intègre toutes les nouveautés de la version 7.2 TR4
- s'installe sur des POWER7, 7+ (sauf Blade Center et PureFlex...)
et Power8.
Attention, pas de LAN console, utilisez ACS plutôt, nous dis ce BLOG :
http://blog.itechsol.com/upgrading-to-ibm-i-7-3/?utm_content=29232813
Installation, comme d'habitude...
passez par GO LICPGM, option 5 pour préparer l'installation
Nous avons installé une partition IBMi (7.2 vers 7.3) qui est "hostée' par une 7.2 (i dans i) , sans problème.
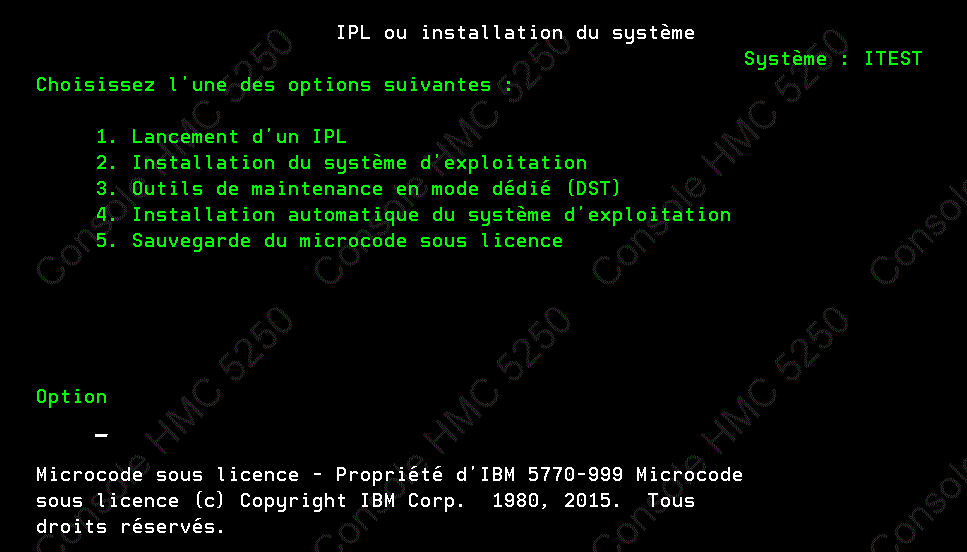
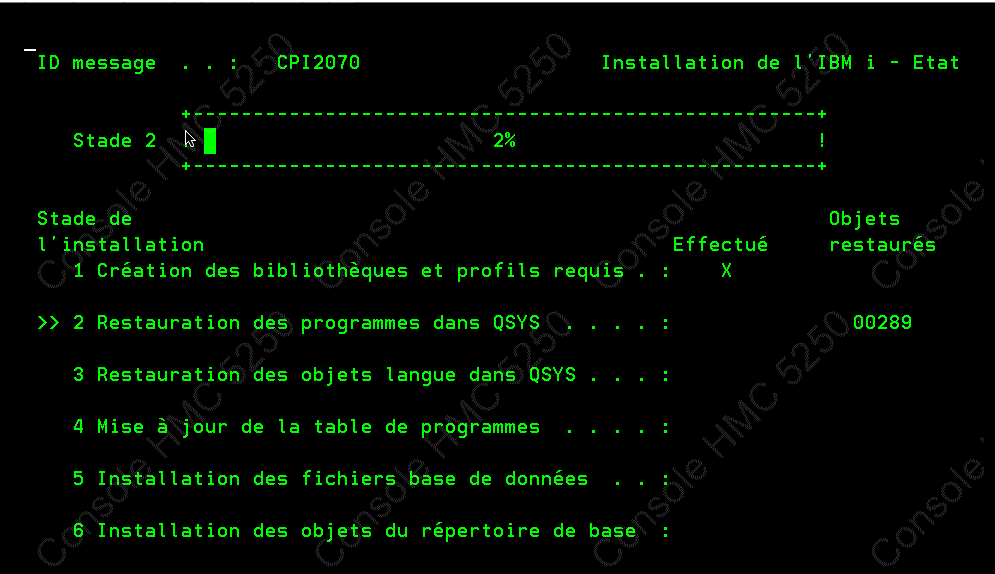
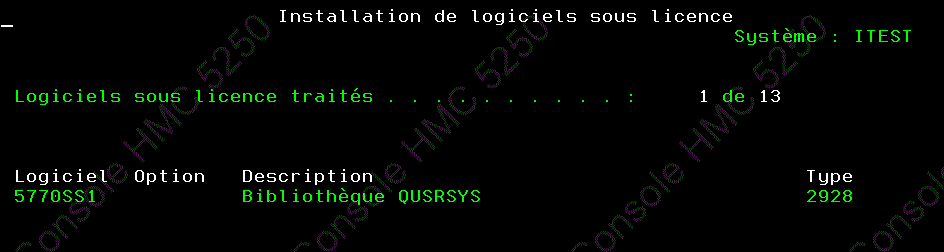
l'installation de l'OS a duré 1heure, puis les logiciels sous licence, une autre heure.
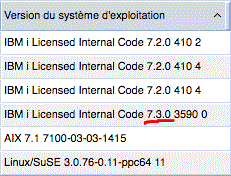
ET voilà (vu de la HMC)
Nouveautés Système de la version.
- WORKLOAD (limitation en nb de processeurs)
avant on associait un Sous-système à une charge de travail, par une Data Area, ou à un job par CHGJOB (7.2)
en 7.3 : CRTSBSD/CHGSBSD WLCGRP( )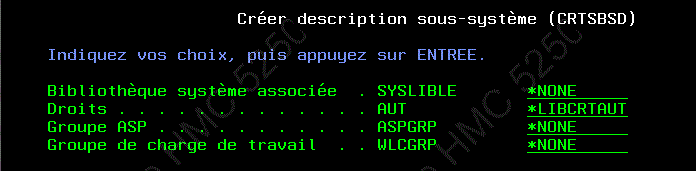
- SET_SERVER_SBS_ROUTING pour rerouter un job serveur dans un sous système, à l'origine par IP, puis par USER et type de job
Inclus désormais DRDA et tout ce qui est proposé par la V7R2, TR4 (voir ci-dessus)
- SAVE 21
- On peut indiquer, désormais DATE et heure de démarrage
- QAUDLVL
- Possibilité d'auditer l'activité TELNET
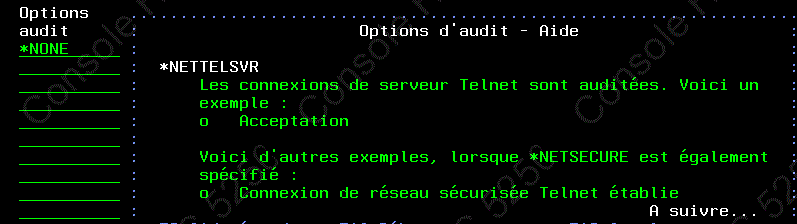
- Possibilité d'auditer l'activité TELNET
- IFS
- nouvelle commande DSPATR, pour voir les attributs d'un fichier stream (avant WRKLNK, option 8)
- nouveau paramètre *TEXT sur CHGATR permettant d'attribuer un texte aux fichiers de l'IFS avec attributs étendus. (pas QDLS, par ex.)
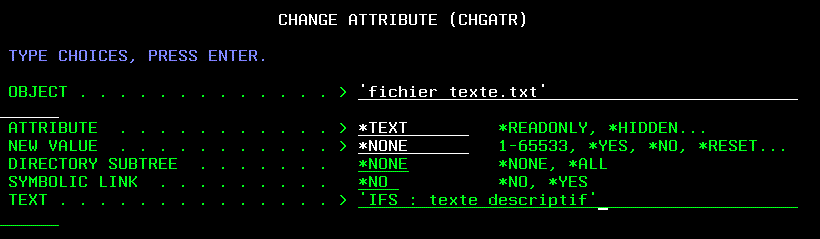
Résultat (WRKLNK)

- ILE/RPG
- Après pouvoir stocker le source RPG dans l'IFS
- On peut maintenant, aussi stocker le source de liage (BND) dans l'IFS
- Nouveau mot-clé NULLIND sur une déclaration, permet d'assigner la valeur nulle à une variable de travail (ALWNULL(*USRCTL) obligatoire)
- Au niveau d'une zone simple (DCL-S)
- sans paramètre, permet d'utiliser %NULLIND
DCL-S DATCMD DATE NULLIND;
IF %NULLIND(DATCMD);
- Avec paramètre, indique le nom d'une zone indicateur (booléen)
DCL-S DATCMD DATE NULLIND(DATCMD_VIDE);
DCL-S DATCMD_VIDE IND;
IF DATCMD_VIDE;
- sans paramètre, permet d'utiliser %NULLIND
- Au niveau d'un tableau ou d'une DS externe, doit fournir le nom d'un tableau ou d'une DS externe.
-
DCL-S DATPOSSIBLE DATE DIM(10) NULLIND(DAT_VIDE);
DCL-S DAT_VIDE IND DIM(10);
-
- NULLIND peut être indiqué au niveau d'une sous zone, en faisant référence à une autre sous zone de la même DS
-
DCL-DS CLIENT QUALIFIED;
NOCLI INT; NOM CHAR(25) NULLIND(NOM_NULL); DEP PACKED(2 : 0); NOM_NULL IND: END-DS;
-
- NULLIND peut être indiqué au niveau d'un paramètre, en faisant référence à un autre paramètre
- Les mots-clés EXTNAME et LIKEREC possédent une nouvelle option *NULL
demandant à ce que soit générer une liste de zones identique rerésentant les indicateurs de nullité du fichier.
- Au niveau d'une zone simple (DCL-S)
-
DCL-DS CLIENT EXT EXTNAME(CLIENTP1) END-DS;
DCL-DS CLIENT_NULL EXT EXTNAME(CLIENTP1:*NULL) END-DS;
IF CLIENT_NULL.NOM; - fonctions intégrées au RPG (BIF)
Avant la fonction %scan s'utilisait : pos = %SCAN('recherche' : machaine :[debut])
en V7.3%SCAN('recherche' : chaine : [debut : longueur ] )
et %SCANR idem à %SCAN mais de droite à gauche-
Attention, l'INFDS subit quelques modifications
// I-O FEEDBACK AREA (partie commune) nb_write UNS(10) POS(243); // avant INT(10) nb_read UNS(10) POS(247); // avant INT(10) nb_exfmt UNS(10) POS(251); // avant INT(10)
La nouvelle version de RDI 9.5.0.3, reconnait ces nouveautés
- Après pouvoir stocker le source RPG dans l'IFS
Navigator for I
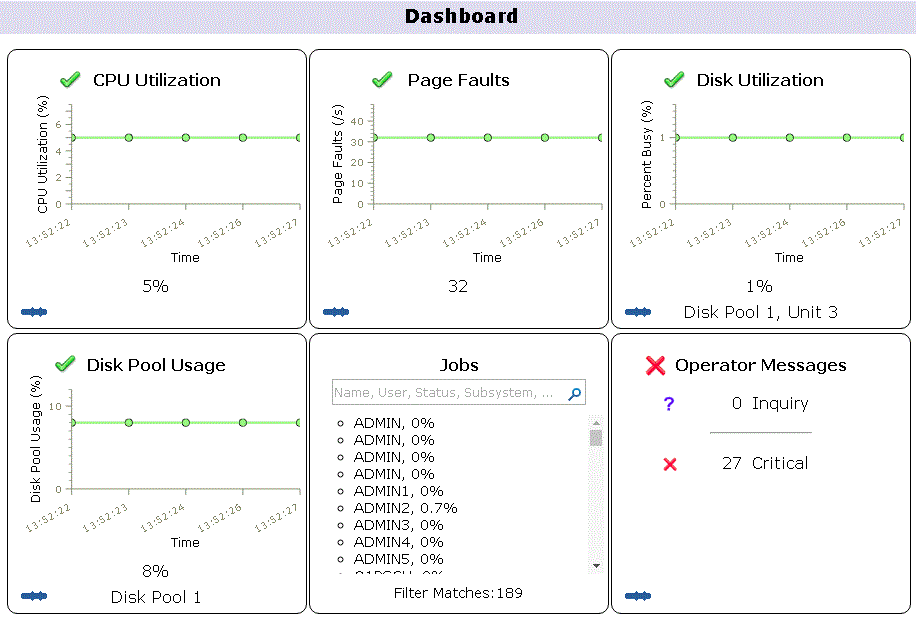
Tableau de bord des principaux éléments à surveiller
accessible par
->
Nouveautés DB2 de la version 7.3
- STRAUTCOL
- log (trace) tous les accès pour un profil donné (USRPRF)
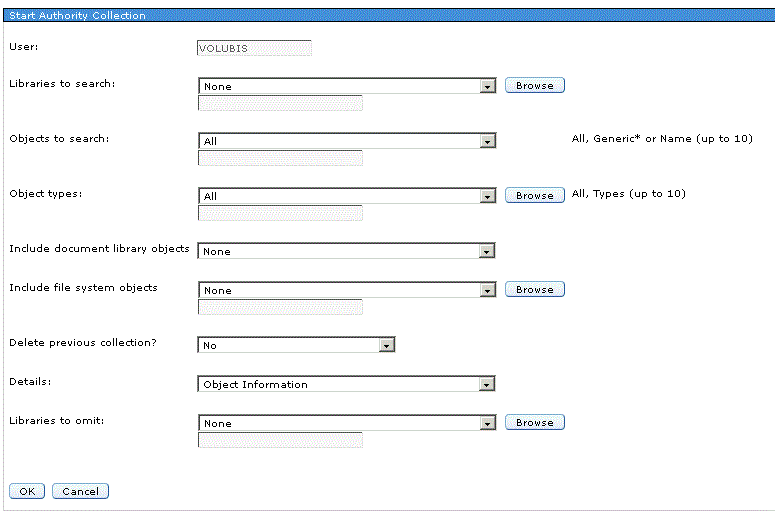
- LIBINF choix de la bibliothèque
- OBJ *ALL / OBJTYPE *ALL
- INCLDO dossiers *NONE / *ALL
- INCIFSOBJ *NONE / *ALL
- DLTCOL annule et remplace les collectes précédente
Visualisable ensuite par System i Navigator
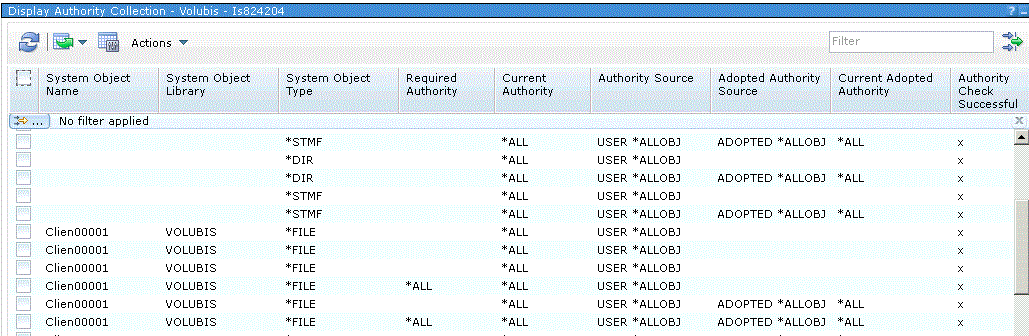
Notez les deux colonnes- Current authority (droits actuels)
- Required Authority (ce qui était nécessaire et suffisant)
- log (trace) tous les accès pour un profil donné (USRPRF)
- Pour voir les détails, vous pouvez aussi lire (par pgm, par exemple)
- QSYS2.AUTHORITY_COLLECTION
- QSYS2.AUTHORITY_COLLECTION
- Pour arrêter
- ENDAUTCOL
5733OPS, Mot-clé dièse (Hash tag) : #IBMiOSS
- Open Source
- Node.JS V4
- Python V 2.7
- GIT (définition Wikipedia)
- Orion (définition Wikipedia)
- PHP
- Zend annonce des temps de réponse divisés par 2 avec PHP 7
http://www.itjungle.com/tfh/tfh051616-story02.html
- Zend annonce des temps de réponse divisés par 2 avec PHP 7
- Voyez le projet SEUEXIT
- le dépot https://github.com/starbuck5250/SEUEXIT
- le mode d'emploi http://archive.midrange.com/midrange-l/201605/msg00663.html
- Voyez l'article de Aaron Bartell sur Orion : http://www.mcpressonline.com/rpg/techtip-shoot-for-orion-with-your-rpg.html?platform=hootsuite
La plupart des autres nouveautés sont liées à SQL
- Les maximas évoluent
- Objets dans une bibliothèque : 1.000.000 (avant 360.000)
- Paramètres d'une procédure SQL : 2000 (avant 1024)
- Paramétres d'une fonction : 2000 (avant 90)
- Membres (ou tables) référencés dans une vue : 1000 (avant 256)
- Nouvelles variables globales
- PROCESS_ID
- THREAD_ID
Automatiquement renseignées, en lecture seule
Rappel JOB_NAME, bien pratique, en disponible depuis la 7.2/TR1.
- Clause GENERATED ALWAYS améliorée
pour chaque champs vous pouvez assigner des valeurs pour faciliter l'Audit (qui a fait quoi ?)
- Generated Always AS
- DATA CHANGE OPERATION (dernière opération sur la ligne)
- U -> Update
- I -> Insert
- D -> Delete
- U -> Update
- « Registre »
- CURRENT CLIENT_ACCTNG
- CURRENT CLIENT_APPLNAME
- CURRENT CLIENT_PROGRAMID
- CURRENT CLIENT_USERID
- CURRENT CLIENT_WRKSTNNAME
- CURRENT SERVER
- SESSION_USER
- USER
- CURRENT CLIENT_ACCTNG
- « variable globale »
- QSYS2.JOB_NAME
- QSYS2.SERVER_MODE_JOB_NAME
- SYSIBM.CLIENT_HOST
- SYSIBM.CLIENT_IPADDR
- SYSIBM.CLIENT_PORT
- SYSIBM.PACKAGE_NAME
- SYSIBM.PACKAGE_SCHEMA
- SYSIBM.PACKAGE_VERSION
- SYSIBM.ROUTINE_SCHEMA
- SYSIBM.ROUTINE_SPECIFIC_NAME
- SYSIBM.ROUTINE_TYPE
- QSYS2.JOB_NAME
- DATA CHANGE OPERATION (dernière opération sur la ligne)
create table clients
(nocli int as identity,
nomcli char(50),
depcli dec(2 , 0) ,
datcrt date ,
usrcrt varchar(128) generated always as (session_user) , |
- Grosse avancée : Tables temporelles (Toujours dans la logique Data Centric, voir http://www.itjungle.com/tfh/tfh052316-story02.html )
- Elles permettent d'avoir une trace de ce qui c'est passé
- mais surtout permet d'interroger la base comme si on était à une date antérieure
- exemple
- le client UN habite Paris
- le 15 Avril, il déménage à Nantes, le chanceux ;-)
- select * from clients, vous le montre à Nantes
- select * from clients for system_time as of '2016-04-01-00.00.00.00000000000'
Vous l'affiche Parisien !
create table clients (nocli int as identity, nomcli char(50), depcli dec(2 , 0) , datcrt date , usrcrt varchar(128) generated always as (session_user) , |
Create table clients_histo like clients |
--liaison des deux tables |
Sous Navigator for i
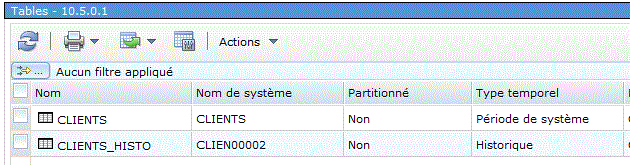
Définition de CLIENTS
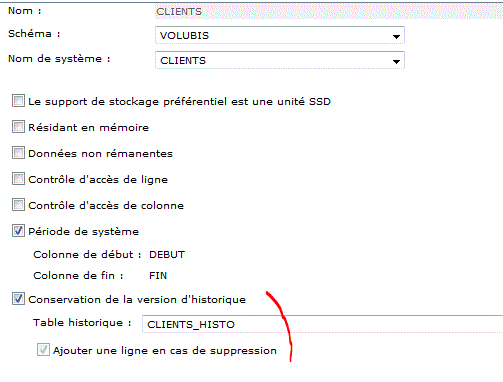
Définition de CLIENTS_HISTO
remarques
- les deux tables doivent être dans la même bibliothèque
- ces nouveaux champs peuvent être cachés (implicitly hidden)
- Start ID, représente le début de la transaction
(5 lignes impactées par un Update ont le même "start id") - lors de l'association des deux tables ON DELETE ADD EXTRA ROW
demande à ce que soit placé dans la table historique, lors d'un Delete, une ligne matérialisant la suppression.
Après avoir ajouté Quatre clients, puis modifié l'un d'entre eux
| select nocli, action, debut, fin from clients |
NOCLI ACTION DEBUT FIN 1 U 2016-02-11-14.18.48.915480000244 9999-12-30-00.00.00.000000000000 2 I 2016-02-08-14.30.33.608585000244 9999-12-30-00.00.00.000000000000 3 I 2016-02-08-14.30.58.621274000244 9999-12-30-00.00.00.000000000000 4 I 2016-02-08-14.31.14.640404000244 9999-12-30-00.00.00.000000000000 |
| select nocli, action, debut, fin from clients_histo |
NOCLI ACTION DEBUT FIN 1 I 2016-02-08-14.29.58.915480000244 2016-02-11-14.18.48.915480000244 |
Mais surtout
- Select * From clients
Vous affiche l'état actuel des clients (seule la table CLIENTS est lue), situation "normale".
- Select * From clients
for system_time as of '2016-02-10-12.00.00.00000000000'
Vous affiche les clients comme si on était le 10 Février
- Select * From clients
for system_time from '2016-02-01-00.00.00.00000000000'
to '2016-02-10-23.59.59.00000000000'
Vous affiche les différents états des clients existant complétement entre le 1er Février et le 10 Février
- un enregistrement vous est affiché si la date de début est > au 1er Février et la date de fin < au 10
- le même client peut vous être affiché plusieurs fois (s'il a été modifié plusieurs fois)
- Select * From clients
for system_time between '2016-02-01-00.00.00.00000000000'
and '2016-02-10-23.59.59.00000000000'
Vous affiche les différents états des clients existant entre le 1er Février et le 10 Février
- un enregistrement vous est affiché si la date de début est > ou = au 1er Février et la date de fin < au 10)
- à l'identique, le même client peut vous être affiché plusieurs fois
- Vous pouvez aussi renseigner le registre CURRENT TEMPORAL SYSTEM_TIME, par
SET CURRENT TEMPORAL SYSTEM_TIME = CURRENT TIMESTAMP - 1 MONTH (par ex.)
- SELECT * from clients
ou - SELECT * from clients FOR SYSTEM_TIME AS OF CURRENT TEMPORAL SYSTEM_TIME
Vous affiche les clients, comme ils étaient il y a un mois
- Par contre, toute requête contenant for system_time alors que le registre CURRENT TEMPORAL SYSTEM_TIME n'est pas nul
provoque SQ20524 'Period Spécification not Valid'.
- SELECT * from clients
Quelques compléments
- ALTER TABLE CLIENTS
ADD COLUMN CACLI DEC (11 , 2) NOT NULL WITH DEFAULT
Ajoute aussi CACLI à la table historique (clients_histo)
- Catalogue système (dans QSYS2)
- SYSTABLES possède une nouvelle zone TEMPORAL_TYPE
Select * from systables where temporal_type = S
(donne la liste des tables ayant une table temporelle ==> clients)
- SYSHISTORYTABLES contient la liste des tables temporelles
select * from syshistorytables
(donne la liste des tables temporelles ==> clients_histo)
- SYSPERIODS contient le détail (champs de début et de fin)
Select * from sysperiods
(donne la liste des périodes c.a.d les caractéristiques de la clause period )
- SYSTABLES possède une nouvelle zone TEMPORAL_TYPE
Statitiques
fonctions d'agrégation
- Moyenne, pas très significative (la tête dans le four, les pieds au congélateur, vous êtes à température ambiante)
- VARIANCE , sur une population
→ la moyenne des carrés des écarts par rapport à la moyenne
plus la valeur est petite, plus la population est homogène (varie peu)
- Ecart-type (STDDEV en SQL)
Racine carrée de la variance
Mesure un écart moyen par rapport à la moyenne générale
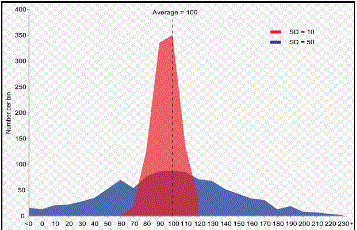
Exemple de deux échantillons ayant la même moyenne mais des écarts types différents
Nouvelles fonctions
- COVARIANCE(x ,y) (on parle de covariance empirique)
Si la variance permet d’étudier les variations d’une variable par rapport à elle-même, la covariance va permettre d’étudier les variations simultanées de deux variables par rapport à leur moyenne respective.
Du résultat obtenu par cette mesure on en déduit que- plus la covariance est faible et plus les séries sont indépendantes
- inversement plus elle est élevée et plus les séries sont liées.
- COVARIANCE_SAM
Comme la COVARIANCE, mais non biaisée (sur une population de n-1)
- COVARIANCE(X,Y)= SUM( (X - AVG(X)) * (Y – ACG(Y)) ) / COUNT(X)
- COVARIANCE_SAM(X,Y)= SUM( (X - AVG(X)) * (Y – ACG(Y)) ) / COUNT(X-1)
- COVARIANCE(X,Y)= SUM( (X - AVG(X)) * (Y – ACG(Y)) ) / COUNT(X)
- CORRELATION(x , y)
COVARIANCE divisée par le produit des écart-type (compris entre -1 et 1)
- Un signe négatif indique que les deux arguments évoluent
en sens contraire (l'un monte, l'autre descend)
- Proche de 0, ils évoluent de manière indépendante (non liée)
- Proche de 1, ils évoluent de manière liée
ex : température extérieure et consommation de crèmes glacées
- Ou de -1, ils évoluent de manière liée, mais inverse
ex : température extérieure et consommation de chauffage.
- Un signe négatif indique que les deux arguments évoluent
en sens contraire (l'un monte, l'autre descend)
- MEDIAN(x)
Valeur médiane, valeur de la ligne du milieu...
- PERCENTILE_CONT (continue)
- PERCENTILE_DISC (discret = échantillon)
- Ces deux fonctions calculent le « pourcentille », dont on donne la valeur en argument
- Ex : percentille_cont(0,5) donne la valeur médiane : identique à MEDIAN()
- Select percentille(0,2) WITHIN GROUP (order by salary) from employee
- Tri les lignes par salaire et donne le salaire de la ligne ayant 20 % des lignes au dessus et 80% en dessous
- Tri les lignes par salaire et donne le salaire de la ligne ayant 20 % des lignes au dessus et 80% en dessous
- Si le nombre de lignes est pair
- PERCENTILLE_COUNT Fait la moyenne entre les deux lignes médianes
- PERCENTILLE_DISC Retourne la première
- PERCENTILLE_COUNT Fait la moyenne entre les deux lignes médianes
- Régression & Régression linéaire
- Définition
- Il s'agit de voir s'il y a une relation entre deux valeurs
- la température baisse-t-elle quand la l'altitude augmente, dans une région donnée ?(C'est probable)
- Le taux d'émission de gaz à effet de serre d'un pays est -il lié à son PIB ?
- Voyons si nous pouvons tracer une courbe(régression) ou une droite (régression linéaire) ayant
- sur l'axe des X l'altitude ou le PIB
- et sur l'axe des Y la température ou le taux d'émission des G.E.S
- La droite de régression

Avec les données collectées, nous observons un nuage de points de forme plus ou moins rectiligne.
Comment trouver l'équation de la droite qui le résume au mieux ?
En minimisant les distances qui la séparent des points. Quelles distances ? Généralement les carrés des distances euclidiennes
D'où l'expression droite des moindres carrés.
Graphiquement, il s’agit des distances VERTICALES, parallèles à l’axe y.
Ci-dessus, la flèche noire indique, pour l'observation n° 7, la distance entre le modèle théorique (droite rouge) et la réalité (point bleu).
- Nouvelles fonctions de régression en 7.3 : REGR_nnnn(x, y)
X étant l'ordonnée (le PIB du Pays)
Y étant l'abscisse (le taux d'émission des G.E.S)
- REGR_COUNT() -> Nbr de paires non nul
- REGR_INTERCEPT /REGR_ICPT (ordonnée à l'origine (valeur de x quand y=0), ou constante de régression)
- REGR_R2 (coefficient de détermination, proche de 1, les points sont tous près de la droite)
- REGR_SLOPE (la pente)
- REGR_AVGX (moyenne de x, après élimination des valeurs nulles)
- REGR_AVGY (moyenne de y, après élimination des valeurs nulles)
- REGR_SXX ( REGR_COUNT(X, Y) * VARIANCE(Y) )
- REGR_SXY (REGR_COUNT(X, Y) * COVARIANCE(X, Y) )
- REGR_SYY ( REGR_COUNT(X, Y) * VARIANCE(X) )
- Toutes ces fonctions servent dans des calculs usuels en statistique :
- Coefficient de détermination ajusté (tiens compte du nombre de valeurs)
1 - ( (1 - REGR_R2) * ((REGR_COUNT - 1) / (REGR_COUNT - 2)) )
- Erreur type
SQRT( (REGR_SYY-(POWER(REGR_SXY,2)/REGR_SXX))/(REGR_COUNT-2) )
- Somme des carrés totaux (TSS)
REGR_SYY
- Somme des carrés de régression (RSS)
POWER(REGR_SXY,2) / REGR_SXX
- Somme des carrés des résidus (SSE)
(TSS)-(RSS)
- Test t (de student) de la pente
REGR_SLOPE * SQRT(REGR_SXX) / (Erreur Type)
- Test t (de student) de l'ordonnée de l 'origine
REGR_INTERCEPT/((Erreur Type) * SQRT((1/REGR_COUNT)+(POWER(REGR_AVGX,2)/REGR_SXX)))
- Coefficient de détermination ajusté (tiens compte du nombre de valeurs)
- Définition
- Fonctions OLAP
- Après
- ROW_NUMBER() over (order by xxx)
- RANK() over (order by xxx)
- DENSE_RANK() over (order by xxx)
- ROW_NUMBER() over (order by xxx)
- Rappel
- numérote les lignes
select ROW_NUMBER() over (), codart, libart from articles order by codart
- numérote les lignes sur le prix (1 = le prix le plus bas)
select ROW_NUMBER() over (order by prix), codart, libart from articles order by codart
- numérote les lignes sur le prix (1 = le prix le plus haut)
select ROW_NUMBER() over (order by prix DESC), codart, libart from articles order by codart
- numérote les lignes sur le prix (A l'intérieur d'une FAMILLE)
select ROW_NUMBER() over (Partition BY FAM Order by prix), codart, libart from articles order by codart
- numérote les lignes
- LAG() over (order by xxx) retourne la valeur de la ligne du dessus, suivant le tri
- LEAD() over (order by xxx) retourne la valeur de la ligne de dessous, suivant le tri
- Génial pour calculer un % d'évolution (par rapport à l'année précédente, par ex.)
- On peut préciser un offset (Combien de lignes au dessus/au dessous)
- Après
- Toutes les fonctions d'agrégation acceptent désormais OVER (Order By xx)
SELECT cacli, SUM(cacli) over (order by nocli ) as sum
FROM clientsCACLI SUM 493.00 493.00 987.00 1,480.00 1,481.00 2,961.00 1,974.00 4,935.00 10,368.00 15,303.00 10,861.00 26,164.00 11,355.00 37,519.00 11,849.00 49,368.00
SELECT depcli, Sum(cacli) over (partition by depcli order by nocli ) as sum, cacli, nomcli FROM clients order by depcli DEPCLI SUM CACLI NOMCLI 31 1,481.00 1,481.00 Client TROIS 31 12,836.00 11,355.00 Client 20 et TROIS 44 493.00 493.00 Client UNO 44 10,861.00 10,368.00 Client 20 et UNO 69 1,974.00 1,974.00 Client QUATRE 69 13,823.00 11,849.00 Client 20 et QUATRE 75 987.00 987.00 Client DEUX 75 11,848.00 10,861.00 Client 20 et DEUX
- Nouvelles fonctions OLAP d'agrégation
- NTILE() permet de calculer le quantile
- NTILE(4) la quartile
- NTILE(10) le décile
SELECT NTILE(3) over (order by cacli ) ,
CACLI ,NOMCLI FROM clientsNTILE CACLI NOMCLI 1 493.00 Client UNO 1 987.00 Client DEUX 1 1,481.00 Client TROIS 2 1,974.00 Client QUATRE 2 10,368.00 Client 20 et UNO 2 10,861.00 Client 20 et DEUX 3 11,355.00 Client 20 et TROIS 3 11,849.00 Client 20 et QUATRE
- CUME_DIST() Permet de calculer la distribution cumulée (sur le rang), le dernier valant 1
SELECT cume_dist() over (order by cacli ) ,
CACLI ,NOMCLI FROM clientsCUME_DIST CACLI NOMCLI
0.125 493.00 Client UNO
0.25 987.00 Client DEUX
0.375 1,481.00 Client TROIS
0.5 1,974.00 Client QUATRE
0.625 10,368.00 Client 20 et UNO
0.75 10,861.00 Client 20 et DEUX
0.875 11,355.00 Client 20 et TROIS
1 11,849.00 Client 20 et QUATRE
- FIRST_VALUE, la première valeur
- LAST_VALUE, la dernière valeur
- NTH_VALUE, la énième valeur
SELECT first_value(cacli) over (order by cacli ) , CACLI ,
cacli / first_value(cacli) over (order by cacli) AS NBRDEFOISPLUS
FROM clientsFIRST_VALUE CACLI NBRDEFOISPLUS
493.00 493.00 1.00000000000000000000
493.00 987.00 2.00202839756592292089
493.00 1,481.00 3.00405679513184584178
493.00 1,974.00 4.00405679513184584178
493.00 10,368.00 21.03042596348884381338
493.00 10,861.00 22.03042596348884381338
493.00 11,355.00 23.03245436105476673427
493.00 11,849.00 24.03448275862068965517
- FIRST_VALUE, LAST_VALUE
- Implique un argument
- la zone
- la zone
- Possèdent une option
- RESPECT NULLS | IGNORE NULLS
- Implique un argument
- NTH_VALUE
- Implique deux arguments
- La zone
- La position (valeur de n)
- La zone
- Possède deux options
- FROM FIRST | FROM LAST
- RESPECT NULLS | IGNORE NULLS
- FROM FIRST | FROM LAST
- Implique deux arguments
- FIRST_VALUE, LAST_VALUE
- RATIO_TO_REPORT (% de la somme cumulée, à ce niveau)
SELECT SUM(cacli) over (order by cacli ) , CACLI ,
ratio_to_report(cacli) over (order by cacli) AS RATIO
FROM clientsSUM CACLI RATIO
493.00 493.00 1
1.480.00 987.00 0,666891891891 (1)
2.961.00 1,481.00 0,500186861187
4.935.00 1,974.00 0,4
15.303.00 10,368.00 0,677514212899
26.164.00 10,861.00 0,415112368139
37.519.00 11,355.00 0.302645659026
49.368.00 11,849.00 0,240013774104 (2)
(1) 987 = 66% de 1480
(2) 11849 = 24% de 49368
- Fenêtrage : Pour ces fonctions d'agrégation
- Fonctions d'agréation « traditionnelles » utilisée avec OVER (SUM, AVG, etc...)
- Fonction d'agrégation OLAP (First_value, Last_value, Nth_value, Ratio_to_report)
- Fonctions d'agréation « traditionnelles » utilisée avec OVER (SUM, AVG, etc...)
- Il est possible d'indiquer une « fenêtre » de travail
- ROWS → fenêtre basée sur les x lignes précédentes et suivantes
- RANGE → fenêtre basée sur les x valeurs de clé précédentes et suivantes
- Vous pouvez indiquer
- Une position de départ (sous entendu jusqu'à la ligne en cours)
- Une position d'arrivée (sous entendu à partir de la ligne en cours)
- Une plage avec BETWEEN début AND fin
- Début (position de départ ou BETWEEN)
- UNBOUNDED PRECEDING
- n PRECEDING (n lignes ou clés précédentes)
- CURRENT ROW
- UNBOUNDED PRECEDING
- Fin (position d'arrivée ou BETWEEN)
- UNBOUNDED FOLLOWING
- n FOLLOWING (n lignes ou clés suivantes)
- CURRENT ROW
- UNBOUNDED FOLLOWING
- Une position de départ (sous entendu jusqu'à la ligne en cours)
- Exemple
SELECT nocli, avg(cacli) over (order by nocli rows between 2 preceding and current row) as moy, cacli,NOMCLI FROM clients order by nocli
ou bien
SELECT nocli, avg(cacli) over (order by nocli rows 2 preceding) as moy, cacli,NOMCLI FROM clients order by nocliNOCLI MOY CACLI NOMCLI
1 493.0000000000000000000000 493.00 Client UNO
2 (1) 740.0000000000000000000000 987.00 Client DEUX
3 987.0000000000000000000000 1,481.00 Client TROIS
4 1,480.6666666666666666666666 1,974.00 Client QUATRE
21 (2) 4,607.6666666666666666666666 10,368.00 Client 20 et UNO
22 7,734.3333333333333333333333 10,861.00 Client 20 et DEUX
23 10,861.3333333333333333333333 11,355.00 Client 20 et TROIS
24 (3) 11,355.0000000000000000000000 11,849.00 Client 20 et QUATRE
Vérifions :
- (493+740)/2=740
- (1481+1974+10368)/3=4607
- (11849+11355+10861)/3=11355
- NTILE() permet de calculer le quantile
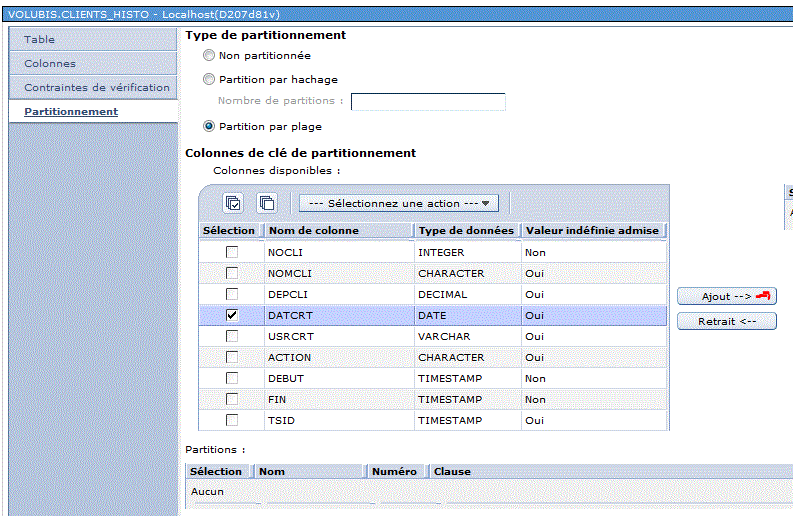
- Rappel sur les tables partitionnées
- Historiquement les tables sont partitionnées sur différentes machines (car une seule n'y suffit pas)
- Aujourd'hui les tables sont partitionnées sur différents membres pour améliorer les performances
- nécessite l'option 27 de 5770SS1
CREATE TABLE Personnel
(matricule INT as identity
..........
DateDepart date)PARTITION BY RANGE ( datedepart )
(PARTITION p2013 STARTING (‘01/01/2013’) INCLUSIVE ENDING (‘12/31/2013’ ) EXCLUSIVE,
PARTITION p2014 STARTING (‘01/01/2014’) INCLUSIVE ENDING (‘12/31/2014’ ) EXCLUSIVE,
PARTITION p2015 STARTING (‘01/01/2015’) INCLUSIVE ENDING (‘12/31/2015’ ) EXCLUSIVE )
Nouveautés
- Il existait déjà un ordre ALTER TABLE DROP PARTITION, qui détruisait le membre
- ALTER TABLE DETACH PARTITION
-> le membre concerné, devient une table indépendante
- ALTER TABLE ATTACH PARTITION
-> la table indépendante, devient un membre d'une table paritionnée
Sous Navigator for i