pause-café
destinée aux informaticiens sur plateforme IBM i.
Pause-café #51
SQL par l'exemple
* indique une nouveauté 6.10
Commencons par un rappel des ordres de base
SQL 89
SELECT colonne1 [as entete1],
colonne2 [as entete2]
( select imbriqué retournant une valeur) as entete3
FROM fichier1 [f1], fichier2 [f2]
WHERE [critères de jointure et sélection]
GROUP BY colonne
HAVING [sélection]
ORDER BY colonne [ASC|DESC]
ouN°-de-colonne
FETCH FIRST n ROWS ONLYSQL
92
(V3R10)
SELECT colonne1 [as entete1],
colonne2 [as entete2]
( select imbriqué retournant une valeur) as entete3
FROM fichier1 f1 join fichier2 f2 ON f1.clea = f2.clea
and f1.cleb = f2.cleb
[join fichier3 f3 on f2.clec = f3.clec]
WHERE [sélection]
GROUP BY [CUBE | ROLLUP *] colonne (ou expression en V4R40)
HAVING [sélection]
ORDER BY colonne [ASC|DESC]
ou N°-de-colonne (ou expression en V4R40)
FETCH FIRST n ROWS ONLYjoin = uniquement les enregistrements en correspondance
Left outer join = tous les enregistrements de fichier1
exception join = uniquement les enregistrements sans correspondance
right outer join = tous les enregistrements de fichier2
right exception join = uniquement les enregistrements sans correspondance(tables dérivées) Soit
SELECT colonne1 [as entete1],colonne2 [as entete2]
FROM (SELECT ... FROM ...) as nom-temporaire WHERE [sélection]
Soit
WITH nom-temporaire as (SELECT ... FROM ...)
SELECT colonne1 [as entete1],colonne2 [as entete2]
FROM nom-temporaire WHERE [sélection](Requête recursive)
as (select L.composant, L.compose, L.quantite
from liens L where composant = 'voiture'
UNION ALL
select fils.composant , fils.compose, fils.quantite
from temp AS Pere join liens AS Fils
on pere.compose=Fils.composant
)
SELECT * FROM TEMPUPDATE
(-> V4R20)UPDATE fichier SET colonne1 = valeur1
WHERE [sélection]UPDATE
(V4R30 et +)UPDATE fichier f SET colonne1 =
(select valeur1 from autrefichier where cle = f.cle)
WHERE [sélection]DELETE DELETE FROM fichier WHERE [sélection]INSERT
INSERT INTO fichier VALUES(valeur1, touteslescolonnes...)
ou
INSERT INTO fichier (colonne2, colonne3) VALUES(v2, v3)
ou
INSERT INTO fichier (SELECT ... FROM ...WHERE ...)INSERT +
FINAL TABLE *SELECT cle_auto, quand FROM FINAL TABLE (INSERT INTO fournisseur
(raisoc, quand) VALUES('IBM', now() ))-- affiche la nouvelle ligne inséréeVALUES * VALUES now() -- affiche le timestamp en coursSélections
Operateur logique Exemple(s)
colonne op. colonne
ou
colonne op. valeurop.
—
=
<
>
<>
<=
>=QTECDE <> 0
LIBART = 'Pamplemousse'
PRIX >= 45IN (val1, val2, val3, ...) DEPT IN (44, 49, 22, 56, 29)BETWEEN val1 AND val2 DEPT BETWEEN 44 AND 85LIKE
nom LIKE 'DU%' (commence par))
nom LIKE '%PON%' (contient)
nom LIKE '%RAND' (se termine pardepuis la V5R1 : nom LIKE '%'concat ville concat '%'IS (IS NOT) NULL et aussi OR, AND, NOT, (, ). CODART = 1245 or LIBART = 'Pamplemousse'V5R40 : les valeurs peuvent être comparées en ligne ... where (cepage1, cepage2) = ('Syrah' , 'Grenache')Fonctions valides (fonctions de groupe)
Fonction(x) Retourne ? Exemple AVG(x) la moyenne de X pour un groupe de ligne AVG(quantite)COUNT(*) le nombre de lignes sélectionnées COUNT(DISTINCT X) le nombre de valeurs différentes pour X COUNT(distinct nocli)MAX(X) retourne la plus grande valeur sélectionnée MAX(DATLIV)MIN(X) retourne la plus petite valeur sélectionnée MIN(prix)SUM(x) retourne la somme de X SUM(qte * prix)VAR(X) retourne la variance STDDEV(X) retourne l'écart type Fonctions valides (ligne à ligne)
Fonction(x) Retourne ? Exemple MAX(X,Y) retourne la plus grande valeur de X ou de Y MAX(prixHA, pritarif) * qteMIN(X,Y) retourne la plus petite valeur de X ou de Y MIN(datce, datliv)ABSVAL(x) la valeur absolue de x ABSVAL(prix) * qteCEIL(x) Retourne l'entier immédiatement supérieur à X
CEIL(2,56) = 3RAND() Retourne un nombre aléatoire ROUND(x , y) Retourne l'arrondi comptable à la précision y SIGN(x) Retourne -1 si x est négatif, 1 s'il est positif, 0 s'il est null Where SIGN(x) = -1TRUNCATE(x , y) Retourne le chiffre immédiatement inférieur à X
(à la précision y)
TRUNCATE(2,56 , 1) = 2,50DEC(x , l, d) x au format numérique packé avec la lg et la précision demandée. DEC(zonebinaire))
DEC(avg(prix), 9, 2DIGITS(x) x en tant que chaîne de caractères DIGITS(datnum)CHAR(x) x en tant que chaîne de car. (x étant une date) CHAR(current date)FLOAT(x) x au format "virgule flottante" FLOAT(qte)INT(x) x au format binaire INT(codart)ZONED(x) x au format numérique étendu ZONED(prix)CAST(x as typeSQL[lg]) x au format indiqué par typeSQL :
types valides
INT | INTEGER
SMALLINT
DEC(lg, nb-décimales)
NUMERIC(lg, nb-décimales)
FLOAT | REAL | DOUBLE
CHAR | VARCHAR
- --FOR BIT DATA-
-- -FOR SBCS ---
----FOR n°-ccsid *--
DATE
TIME
TIMESTAMP
* : un CSSID est un équivalent code-page associé à une donnée (france = 297)CAST(qte AS CHAR(9))
Attention les zéros de gauche sont éliminés
CAST(prixchar asNUMERIC(7, 2))
cast('123456,89' as numeric(8, 2)) fonctionne
cast('123456,89' as numeric(7, 2))
donne une erreur(trop d'entiers)STRIP(x) ou
TRIM(x)
RTRIM(x) LTRIM(x)supprime les blancs aux deux extrémités de x.
• les blancs de droite
• les blancs de gaucheTRIM(raisoc)
LENGTH(x) ou
OCTET_LENGTH(x)la longueur de x LENGTH(nom)
LENGTH(TRIM(nom))CONCAT(x , y) concatene X et Y (aussi x CONCAT y ou X !! Y) CONCAT(nom, prenom)SUBSTR(x, d, l) extrait une partie de x depuis D sur L octets SUBSTR(nom, 1, 10)
SUBSTR(nom, length(nom), 1)LEFT(x, l) extrait une partie de x depuis 1 sur L octets LEFT(nom, 10)RIGHT(x, l) extrait les L derniers octets de x RIGHT(nom, 5)SPACE(n) retourne n blancs nom concat space(5) concat prenomREPEAT(x , n) retourne n fois x repeat('*', 15)MOD(x, y) le reste de la division de x par y MOD(annee, 4)RRN(fichier) N° de rang en décimal RRN(clientp1)RID(fichier) * N° de rang en binaire RID(clientp1)TRANSLATE(x)
UPPER(x)
UCASE(x)X en majuscule WHERE
UCASE(RAISOC) LIKE 'VO%'LOWER(x)
LCASE(x)x en minuscule WHERE
LCASE(ville) LIKE 'nan%'TRANSLATE( x, remplace, origine) Remplace tous les caractères de X présent dans origine par le caractère de même position dans remplace. TRANSLATE(prixc, ' F', '0$')
remplace 0 par espace et $ par FREPLACE( x, origine, remplacement) Remplace la chaîne de caractère origine par la chaîne remplacement dans x REPLACE(x, 'Francs' , 'Euros')
remplace Francs par EurosSOUNDEX( x) Retourne le SOUNDEX (représentation phonétique) de X [basé sur un algorhytme anglo-saxon] Where SOUNDEX(prenom) = SOUNDEX('Henri')DIFFERENCE( x) Retourne l'écart entre deux SOUNDEX
[0 = très différents, 4 = trés proches]Where DIFFRENCE(prenom, 'HENRI)> 2VALUE(x, y)
IFNULL(x, y)retourne X s'il est non null, sinon Y IFNULL(DEPT, 0)NULLIF(x, y) retourne NULL si X = Y NULLIF(Prix, 0)LOCATE(x, y ,d) retourne la position à laquelle x est présent dans y ou 0
(la recherche commence en D, qui est facultatif)LOCATE(' ', raisoc)POSITION(x IN y) idem LOCATE POSITION(' ' IN raisoc)INSERT(x, d, nb, ch) insert ch dans x à la position d, en remplacant nb octets (0 admis) DATABASE() retourne le nom de la base (enregistré par WRKRDBDIRE) ENCRYPT_RC2(x, p, a) Encrypte x en utilisant p comme mot de passe
(a est l'astuce mémorisée pour se souvenir du mot de passe)ENCRYPT_RC2(data, 'AS400', 'avant I5') ENCRYPT_TDES(x, p, a) Encrypte (algorithme TDES) x en utilisant p comme mot de passe
(a est l'astuce mémorisée pour se souvenir du mot de passe)ENCRYPT_TDES(data, 'AS400', 'avant I5') ENCRYPT_AES(x, p, a) Encrypte (algorithme AES) x en utilisant p comme mot de passe
(a est l'astuce mémorisée pour se souvenir du mot de passe)ENCRYPT_AES(data, 'AS400', 'avant I5') GET-HINT(x) retrouve l'astuce associée à x
GET-HINT(data) --> 'avant I5' DECRYPT_BIT(x) retourne (en varchar for bit data) les données d'origine de x.
(on doit lancer avant SET ENCRYPTION PASSWORD = p)DECRYPT_BINARY(x) retourne (en binary) les données d'origine de x.
(on doit lancer avant SET ENCRYPTION PASSWORD = p)DECRYPT_CHAR(x) retourne (en VARCHAR) les données d'origine de x.
(on doit lancer avant SET ENCRYPTION PASSWORD = p)CASE
when ... then ..
when ... then ..
[else]
ENDretourne la valeur du premier THEN ayant la clause WHEN de vérifiée.
CASE dept
WHEN 44 then 'NANTES'
WHEN 49 then 'ANGERS'
ELSE 'Hors région'
END AS METROPOLE
ou bien
CASE
WHEN prix < 0 then 'négatif'
WHEN codart = 0 then 'inconnu'
ELSE 'positif ou nul'
ENDFonctions OLAP (V5R40 et V6R10)
ROW_NUMBER() numérote les lignes sur un critère de tri
select ROW_NUMBER() over (order by prix), codart, libart from articles
[order by autre-chose]RANK() attribue un rang
(en gérant les ex-aequo, par exemple 1-1-3-4-4-4-7)select RANK() over (order by prix), codart, libart from articlesDENSE_RANK() attribue un rang consécutif (par exemple 1-1-2-3-3-3-4)
select DENSE_RANK() over (order by prix), codart, libart from articlesoptions pour GROUP BY soit le SELECT basique suivant -->
SELECT SOC, DEP, Count(*) .../... GROUP BY (soc, Dep)
SOC DEP Count(*) 01 22 15 01 44 20 02 22 5 02 44 10 GROUPING SET * affiche les totaux pour 2 GROUPES consécutifs
SELECT SOC, DEP, Count(*) ...GROUP BY Grouping Set (soc, Dep)
SOC DEP Count(*) 01 - 35 02 - 15 - 22 20 - 44 30 ROLLUP * affiche 1 total par groupe puis des ruptures de niveau supérieur
SELECT SOC, DEP, Count(*) ...GROUP BY ROLLUP (soc, Dep)
SOC DEP Count(*) 01 22 15 01 44 20 01 - 35 02 22 5 02 44 10 02 - 15 - - 50 CUBE * affiche les totaux pour tous les groupes possibles
SELECT SOC, DEP, Count(*) ... GROUP BY CUBE (soc, Dep)
SOC DEP Count(*) 01 22 15 01 44 20 01 - 35 02 22 5 02 44 10 02 - 15 - - 50 - 22 20 - 44 30 GROUPING() * indique si cette ligne est un total de niveau supérieur (rupture)
SELECT SOC, DEP, Count(*), GROUPING(DEP) .../...
GROUP BY ROLLUP (soc, Dep)
SOC DEP Count(*) Grouping(dep) 01 22 15 0 01 44 20 0 01 - 35 1 02 22 5 0 02 44 10 0 02 - 15 1 - - 50 1
Cas particulier des dates
- On ne peut utiliser l'arithmétique temporelle qu'avec des dates, des heures, des horodatages
- les calculs peuvent se faire sous la forme
- date + durée = date
- date - durée = date
- date - date = durée
- heure + durée = heure
- etc ..
- les durées peuvent être exprimées de manière explicite avec
YEARS MONTHS DAYS HOURS MINUTES SECONDS - les durées résultat (DATLIV - DATCDE) seront toujours exprimées sous la forme AAAAMMJJ, où :
AAAA represente le nombre d'années MM le nombre de mois JJ le nombre de jours
- Ainsi, si SQL affiche 812, il faut comprendre 8 mois, 12 jours
- 40301 signifie 4 ans , 03 mois, 01 jour (attention SQL risque d'afficher 40.301)
Fonctions liées aux dates
Fonction(x) Retourne ? Exemple DATE(x)
X doit être une chaîne au format SQL
(celui du JOB par défaut)
une date (sur laquelle les fonctions suivantes s'appliquent) DATE(
substr(digits(dat8), 7, 2)
concat '/' concat
substr(digits(dat8), 5, 2)
concat '/' concat
substr(digits(dat8), 3, 2) )DAY(D)
DAYOFMONTH(D)retourne la partie jour de D
(doit être une date ou un écart AAAAMMJJ).DAY(DATCDE)MONTH(D) retourne la partie mois de D (idem)
MONTH(current date)YEAR(D) Retourne la partie année de D (idem) YEAR(current date - DATCDE)DAYOFYEAR(D) retourne le n° de jour dans l'année (julien) DAYOFYEAR(datdep)DAYOFWEEK(D) retourne le N° de jour dans la semaine
(1 = Dimanche, 2=Lundi, ...)DAYOFWEEK(ENTRELE)DAYOFWEEK_ISO(D) retourne le N° de jour dans la semaine
(1 = Lundi, ...)DAYOFWEEK_ISO(ENTRELE)DAYNAME(d) retourne le nom du jour de d (Lundi, Mardi, ...) MONTHNAME(d) retourne le nom du mois de d (Janvier, Février, ...) EXTRACT(day from d) Extrait la partie jour de D (aussi MONTH et YEAR) DAYS(D) retourne le nbr de jours depuis 01/01/0001 DAYS(datcde)- DAYS(datliv)QUARTER(D) retourne le n° du trimestre QUARTER(DATEFIN)WEEK(D) retourne le n° de semaine
(Attention 01/01/xx donne toujours semaine 1)WHERE
WEEK(DATLIV)= WEEK(DATCDE)WEEK_ISO(D) retourne le n° de semaine
(la semaine 1 est celle qui possède un JEUDI dans l'année.)WHERE
WEEK_ISO(DATLIV)= WEEK_ISO(DATCDE)CURDATE() retourne la date en cours, comme CURRENT DATE CURTIME() retourne l'heure en cours, comme CURRENT TIME NOW() retourne le timestamp en cours JULIAN_DAYS(d) retourne le nbr de jours qui sépare une date du 1er Janv. 4712 av JC. LAST_DAY(d) retourne la date correspondant au dernier jour du mois. LAST_DAY('2006-04-21') = 2006-04-30ADD_MONTHS(d, nbr ) ajoute un nbr de mois à une date ,
si la date est au dernier jour du mois, la date calculée est aussi au dernier jour du moisADD_MONTHS('2006-04-30' , 1) = 2006-05-31NEXT_DAYS(d, 'day' ) retourne le timestamp de la prochaine date ayant le jour demandé NEXT_DAYS('2006-12-31' , 'DIM')
= ' 2007-01-07-00.00.00.000000'MONTHS_BETWEEN(d, d) * retourne l'écart en date (avec des décimales sur 31 jours) entre deux mois months_between('25/09/08' , '31/08/08')
= 0,806451612903225Fonctions liées aux heures
Fonction(x) Retourne ? Exemple TIME(T) une heure TIME(
substr(digits(h6), 1, 2)
concat ':' concat
substr(digits(h6), 3, 2)
concat ':' concat
substr(digits(h6), 5, 2) )HOUR(T) retourne la partie heure de T HOUR(Pointage)MINUTE(D) retourne la partie minute de T
SECOND(T) Retourne la partie secondes de T EXTRACT(hour from t) la partie heure de T (aussi MINUTE et SECOND) Fonctions liées aux Timestamp
Fonction(x) Retourne ? Exemple TIMESTAMP(T) un timestamp (date - heure - microsecondes) TIMESTAMP('
1999-10-06.15.45.00.000001 ')TIMESTAMP
(D T)un timestamp (microsecondes à 0) TIMESTAMP(datcde heure)TIMESTAMP_ISO(x)
un timestamp à partir de x
Si x est une date, l'heure est à 00:00:00
Si x est une heure, la date est à aujourd'hui.TIMESTAMP_ISO(heure_pointage)TIMESTAMPDIFF
(c 'DIFFERENCE')
C indique l'unité de mesure de l'écart que vous souhaitez obtenir
1 = fractions de s. 16 = jours 2 = secondes 32 = semaines 4 = minutes 64 = mois 8 = heures 128 = trimestres 256 = Année 'DIFFERENCE' est la représentation caractères [ CHAR(22) ] d'un écart entre deux timestamp.
TIMLESTAMPDIFF(32 , CAST(CURRENT_TIMESTAMP - CAST(DATLIV AS TIMESTAMP) AS CHAR(22)) )
indique l'écart en semaines entre DATLIV
et aujourd'huiMIDNIGHT_SECONDS retourne le nbr de secondes qui sépare un timestamp de minuit VARCHAR_FORMAT(d, 'YYYY-MM-DD HH24:MI:SS' ) Transforme un timestamp en chaine
(le format est imposé en V5R40 ,libre en V6R10 *)TIMESTAMP_FORMAT('c', f) * Transforme la chaîne c en timestamp, suivant le format f
f pouvant contenir :
- - . / , ' : ; et (espace)
- DD (jours) MM (mois) YY (années sur 2) YYYY (sur 4)
- RR année ajustée (00 à 49>2000, 50 à 99>1900)
- HH24 l'heure (24h) SS (secondes) NNNNNN (micro-secondes)
TIMESTAMP_FORMAT('99/02/05' , 'RR/MM/DD')
=1999-02-05-00.00.00.000000
le format YY/MM/DD aurait donné 2099GENERATE_UNIQUE() genère une valeur unique de type CHAR(13) basée sur le timestamp en cours. plus toutes les fonctions liées aux dates et aux heures
Sous sélections, Ordre SQL intégré dans la clause WHERE (ou dans la liste des colonnes) d'un ordre SQL :
SELECT * FROM tarif WHERE prix < (SELECT AVG(prix) from tarif)donne la liste des articles ayant un prix inférieur à la moyenne
SELECT * FROM tarif WHERE prix BETWEEN
(SELECT AVG(prix)*0,9 from tarif) AND (SELECT AVG(prix)*1,1 from tarif)donne la liste des articles ayant un prix variant d'au maximum +/- 10 % par rapport à la moyenne
SELECT * FROM tarif T WHERE prix <
(SELECT AVG(prix) from tarif Where famille = t.famille)donne la liste des articles ayant un prix inférieur à la moyenne de leur famille
Select codart , (qte * prix) as montant, (select sum(qte * prix) from commandes where famcod = c1.famcod) as global_famille from commandes c1donne la liste des commandes (article, montant commandé), en rappelant sur chaque ligne le montant global commandé dans la famille.
• Elle indique VRAI si le select imbriqué retourne une ligne (ou plus)
• Elle indique FAUX si le select imbriqué ne retourne aucune ligne.
soit un fichier article ayant une colonne "unité_stockage" et un fichier stock,
il s'agit de supprimer les articles dans le fichiers stock si la zone "unité_stockage" est à blanc dans le fichier article.
DELETE from stock S where exists
(SELECT * from articles where codart = S.codart
and "unité_stockage" = ' ')
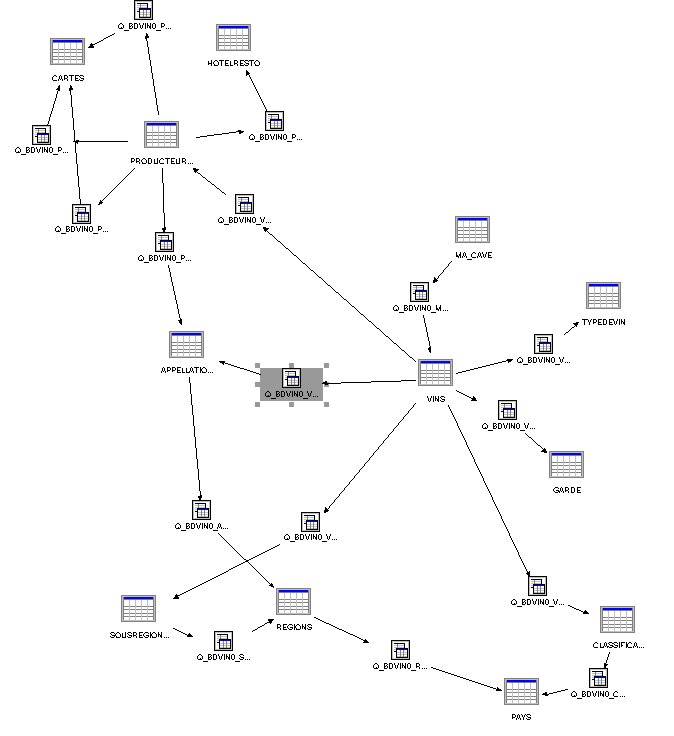
Soit la base de données suivante :
créé par le script :
-- table des régions create table BDVIN1/regions ( region char(30) , region_code integer primary key , pays_code integer references pays) ;
-- table des appellations (Coteau du Layon, Côtes roties ...) create table BDVIN1/appellations ( appellation char(80) , region_code integer references regions , appel_code integer primary key ) ;
-- table des sous-régions create table BDVIN1/sousregions ( sregion char(30) , region_code integer references regions ,
sregion_code integer primary key ) ;
-- table des cartes (fichiers images, associées au producteur) create table BDVIN1/cartes ( carte_code char(10) primary key , carte_titre varchar(40) ) ;
-- table des classifications (1er cru, ...) create table BDVIN1/classification ( classification varchar(60) , class_code integer primary key , pays_code integer references pays) ;
-- table des tableaux de garde (image donnant l'apogée d'un vin) create table BDVIN1/garde ( millesime varchar(255) , garde_code integer primary key ) ;
-- table des hotel/restaurants (associés à un producteur) create table BDVIN1/hotelresto ( hr_code integer primary key , hr_type char(15) check (hr_type in ('Restaurant', 'Hôtel')) , hr_nom char(50) not null , hr_cdpst char(12) , hr_commune char(50) , hr_tel char(20) , hr_fax char(20) , hr_cote char(10) ,
hr_prix char(15) ) ;
-- les plus importantes pour nos TP
--================================= -- table des producteurs create table BDVIN1/producteurs ( pr_code integer primary key ,
pr_nom char(50) not null , pr_adresse char(60) , pr_cdpst char(12) , pr_commune char(50) ,
pr_proprio char(60) , pr_responsable char(50) , pr_tel char(20) , pr_fax char(20) , pr_vente char(3) check (pr_vente in ('oui' , 'non')) ,
pr_visite char(3) check (pr_visite in ('oui' , 'non')) , hr_code integer references hotelresto , pr_avis varchar(255) , pr_cote char(10) ,
pr_photo integer , pr_carte1 char(10) references cartes , pr_carte2 char(10) references cartes , pr_carte3 char(10) references cartes ,
cree char(1) check (cree in ('O' , 'N')) , mon_avis varchar(50) , ma_cote char(10) ,
appel_code integer references appellations) ;
-- table des types de vin (blanc, rouge, ...) create table BDVIN1/typedevin ( typedevin char(50) , type_code integer primary key ) ;
-- table des vins create table BDVIN1/vins ( vin_code integer primary key , pr_code integer references producteurs ,
vin_nom char(50) not null , vin_cepage1 char(25) , vin_cepage2 char(25) , vin_cepage3 char(25) , vin_cepage4 char(25) ,
vin_etiquette integer , class_code integer references classification , sregion_code integer references sousregions , appel_code integer references appellations ,
type_code integer references typedevin , garde_code integer references garde) ;
-- table de vins de votre cave create table BDVIN1/ma_cave ( cav_code integer primary key , vin_code integer references vins ,
cav_millesime integer , cav_lieu char(50) , cav_format char(50) , cav_apogee date , cav_quantite integer ,
cav_prix dec(7 , 2) , cav_prxactuel dec(7 , 2) , cav_entreele date , cav_sortiele date ) ;TP SQL
nombre de vins entrés cette année dans votre cave (fichier MA_CAVE)
ce trimestre
dans l'année écoulée.
il y a t-il des appellations dans la région Alsace ne contenant pas le mot "Alsace"
liste des vins de la région "Loire" (région contient le mot "Loire")
augmentez de 10 % ,le prix actuel des vins de plus de 2 ans (MA_CAVE) cave
dans le fichier producteurs, certains noms de communes ne sont pas cadrés à gauche, cadrez les à gauche.
nombre de vins par producteurs
select pr_code, count(*) from vins
group by pr_code
nombre de vins en moyenne par producteurs (le résultat est 3)
liste des producteurs produisant un nombre > à la moyenne (classée par nombre de vins produits, en décroissant)
le TOP 10 des producteurs (en nombre de vins produits)
les 10 producteurs suivants
il y a-t-il des appellations sans producteur ? si oui, combien ?
il y a-t-il des appellations n'ayant ni producteur ni vin, si oui combien ?
par producteur, nombre de vins: blanc , rouge/rosé le fichier des type de vins indique :
TYPEDEVIN TYPE_CODE
Blanc effervescent 1
Blanc 2
Rouge effervescent 3
Rouge 4
Rosé effervescent 5
Rosé 6
Moelleux effervescent 7
Moelleux 8
producteur | nbr de blanc | nbr de rouges | ---------------------------------------------
puis demandez le total des vins blanc et des vins rouges
augmentez le prix-actuel des vins ayant plus de 5 ans
de 10% si le prix est < à 10 € de 15% si le prix est < à 15 € de 20% au dela de 15 €
ajoutez au fichier des vins une zone prix_tarif acceptant NULL
alter table vins add column prix_tarif dec(7 , 2)
renseignez cette zone pour les vins de votre cave avec le prix actuel
si la zone n'avait pas accepté la valeur nulle, ou pour des raisons de perf. comment fallait-il écrire la requête?
enlever la zone prix_tarif
alter table vins drop column prix_tarif
Copyright © 1995,2009 VOLUBIS