pause-café
destinée aux informaticiens sur plateforme IBM i.
Pause-café #75
Version 7.3 / TR1
-
TR1 (certaines fonctions sont communes à la TR5 de la 7.2)
IBM continue sur la lancée des versions 7.1 et 7.2 en matière de livraison des nouveautés au fil de l'eau.
Ces dernières ont vu des améliorations livrées sous forme de TR, tous les six mois.
La TR1 de la 7.3 coïncide avec la TR5 de la 7.2. il n'y a plus de nouvelles TR en 7.1
- DB2 i
- JSON_TABLE pour parser du JSON en SQL
Aujourd'hui JSON est de plus en plus utilisé.
JSON (JavaScript Object Notation) est un format de données textuelles dérivé de la notation des objets du langage JavaScript (Wikipedia) ce qui s'écrit comme cela en XML s'écrit comme cela en JSON <producteurs>
<producteur>
<numero>45</numero>
<commune>Reims</commune>
<appellation>13</appellation>
</producteur>
</producteurs>-> {
"producteurs": {
"producteur": {
"numero":45
"commune":"Reims",
"appellation":13,
}
}
}
Un élément peut contenir un objet, une valeur ou un tableau de valeurs, marqué alors par [ et ]
<PO> <id>103</id>
<orderDate>2014-06-20</orderDate>
<customer>
<cid>888</cid>
</customer> <items>
<item>
<partNum>872-AA</partNum>
<shipDate>2014-06-21</shipDate>
<productName>Lawnmower</productName>
<USPrice>749.99</USPrice>
<quantity>1</quantity>
</item>
<item>
<partNum>837-CM</partNum>
<productName>Digital Camera</productName>
<USPrice>199.99</USPrice>
<quantity>2</quantity>
<comment>2014-06-22</comment>
</item>
</items>
</PO>devient (remarquez le tableau de "item")
{ "PO":{ "id": 103, "orderDate": "2014-06-20", "customer": {"@cid": 888}, "items": { "item": [ { "partNum": "872-AA", "productName": "Lawnmower", "quantity": 1, "USPrice": 749.99, "shipDate": "2014-06-21" }, { "partNum": "837-CM", "productName": "Digital Camera", "quantity": 2, "USPrice": 199.99, "comment": "2014-06-22" } ] } } }
Il y a trois manières d'utiliser JSON sur IBM i :- DB2nosql -- accès "nosql" en mode ligne de commandes
- Les API Java
- les fonctions SQL :
- SYSTOOLS.BSON2JSON / JSON2BSON
Permettant de stocker du JSON au format binaire
- SYSTOOLS.BSON2JSON / JSON2BSON
Les Technology Refresh 1 (7.3) et 5 (7.2) apportent une nouvelle fonction JSON_TABLE (dans QSYS2)
JSON_TABLE(
JSON_SOURCE
JSON_PATH
COLUMNS nom type PATH 'json_path', ... ) as X
- JSON_SOURCE
Flux JSON, peut-être- une variable
- une colonne base de données (JSON ou BSON)
- un flux (HTTPGETCLOB, par exemple)
- JSON_PATH
-
$ objet en cours . élément dans l'objet en cours [ ] élément dans un tableau un_nom la valeur de l'élément
-
- COLUMNS
Comme avec XMLTABLE il s'agit de "fabriquer" des pseudo-colonnes base de données, indiquez :
- un nom de colonne
- un type : CHAR(x) , DEC(x , y), etc...
- PATH
- une règle d'utilisation
- lax, utilisation souple
- on peut faire référence à un élément, même quand c'est un tableau, l'itération est alors automatique
- on peut faire référence à un tableau, même quand c'est un élément
- les cas impossibles génèrent valeur nulle
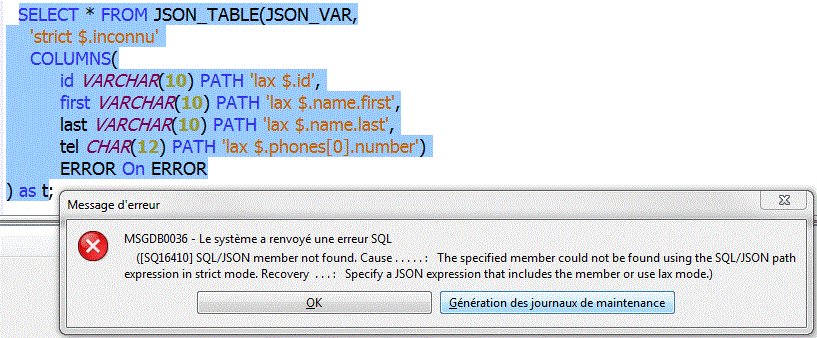
- strict, utilisation stricte, les cas précédents génèrent une erreur
- lax, utilisation souple
- L'élément JSON dont il faut extraire la valeur
- (options)
- NULL ON EMPTY
retourne valeur nulle sur un élément manquant
- ERROR ON EMPTY
retourne une erreur sur un élément manquant
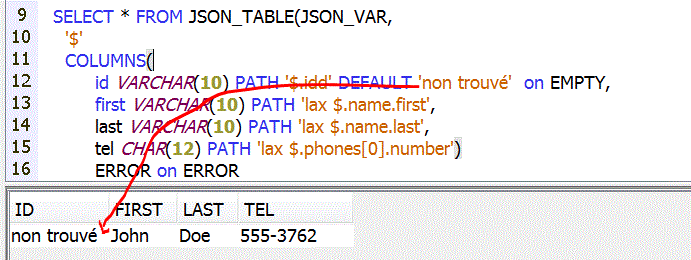
- DEFAULT <une-valeur> ON EMPTY
retourne une valeur par défaut sur un élément manquant
- ERROR ON ERROR
retourne une erreur en cas d'erreur (SQL16410)
- DEFAULT <une-valeur> ON ERROR
retourne une valeur par défaut suite à une erreur
- NULL ON EMPTY
- une règle d'utilisation
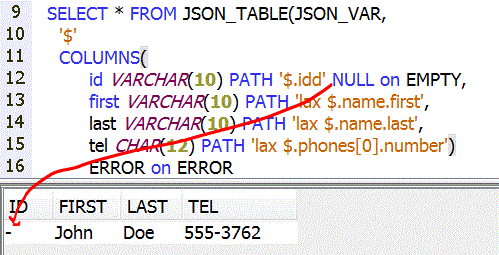
Par exemple avec ce flux
{ "id" : 901, "name" : { "first":"John", "last":"Doe" }, "phones" : [{"type":"home", "number":"555-3762"}, {"type":"work", "number":"555-7252"}] }'
COLUMNS( id VARCHAR(10) PATH 'lax $.id', first VARCHAR(10) PATH 'lax $.name.first', last VARCHAR(10) PATH 'lax $.name.last' )

•NULL ON EMPTY (c'est aussi ce qui se passe si vous ne dites rien)
•DEFAULT ON EMPTY
•Gestion de tableaux (éléments présents n fois)
Avec XMLTABLE, si nous avons plusieurs téléphones, vous pouvez->ne recevoir que la(les) première(s) valeur(s)
Ecrivez
SELECT X.nom ,x.rue, x.ville, x.TEL
FROM posample/Customer,
XMLTABLE (
XMLNAMESPACES(DEFAULT 'http://posample.org'),
'$c/customerinfo' passing INFO as "c"
COLUMNS
NOM CHAR(30) PATH 'name',
RUE VARCHAR(25) PATH 'addr/street',
VILLE VARCHAR(25) PATH 'addr/city',
TEL char(10) PATH 'phone[1]'
) AS X
JSON_TABLE, propose une syntaxe approchante :
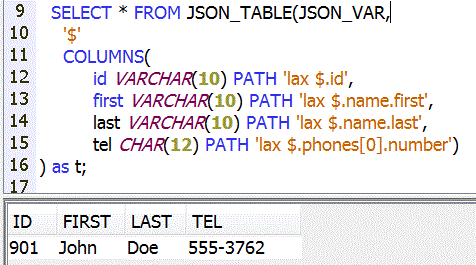
- -> retourner chaque téléphone avec la syntaxe suivante
SELECT X.nom ,x.rue, x.ville, x.TEL
NESTED avec JSON_TABLE
FROM posample.Customer,
XMLTABLE (
XMLNAMESPACES(DEFAULT 'http://posample.org'),
'$c/customerinfo/phone' passing INFO as "c"
COLUMNS
NOM CHAR(30) PATH '../name',
RUE VARCHAR(25) PATH '../addr/street',
VILLE VARCHAR(25) PATH '../addr/city',
TEL char(20) PATH '.'
) AS X
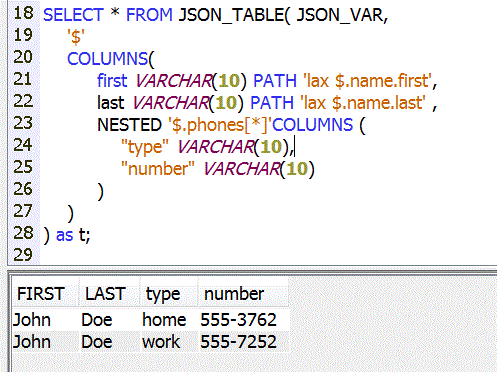
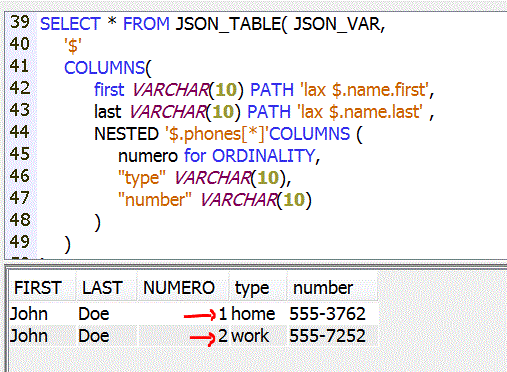
Dans ce cas, La clause FOR ORDINALITY permet de retrouver le n° d'occurrence
XMLTABLE possède aussi cette fonctionalité
SELECT X.nom ,x.rue, x.ville, x.TEL, X.NUMERO
FROM posample.Customer,
XMLTABLE (
XMLNAMESPACES(DEFAULT 'http://posample.org'),
'$c/customerinfo/phone' passing INFO as "c"
COLUMNS
NOM CHAR(30) PATH '../name',
RUE VARCHAR(25) PATH '../addr/street',
VILLE VARCHAR(25) PATH '../addr/city',
TEL char(20) PATH '.',
NUMERO FOR ORDINALITY
) AS X
- Enfin comme avec XMLTABLE, vous pouvez récupérer la totalité des téléphones, dans un flux
->retourner la totalité des téléphones sous forme XML
SELECT X.nom ,x.rue, x.ville, x.TEL
FROM posample/Customer,
XMLTABLE (
XMLNAMESPACES(DEFAULT 'http://posample.org'),
'$c/customerinfo' passing INFO as "c"
COLUMNS
NOM CHAR(30) PATH 'name',
RUE VARCHAR(25) PATH 'addr/street',
VILLE VARCHAR(25) PATH 'addr/city',
TEL XML PATH 'phone'
) AS X

Bien sur vous pouvez travailler avec des champs base de données (la table CUSTOMERJ, contenant du VARCHAR)

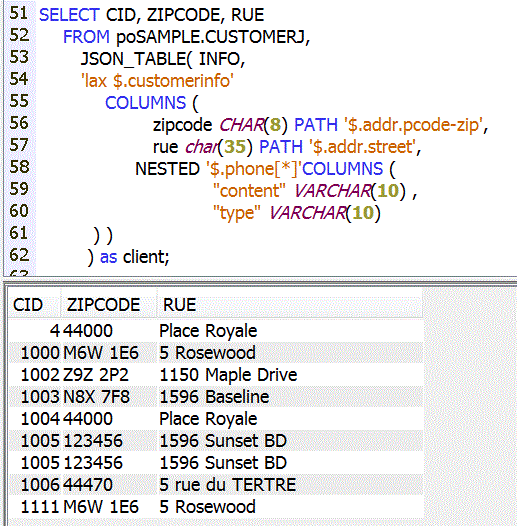
ou sur le résultat d'un Web service REST (voir l'exemple proposé sur developer Work's)
http://www.ibm.com/developerworks/ibmi/library/i-rest-web-services-server3/index.html

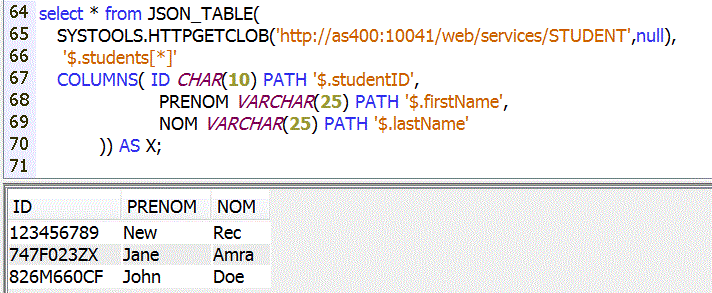
Avec des données OpenData de la ville de Nantes (voir http://data.nantes.fr)
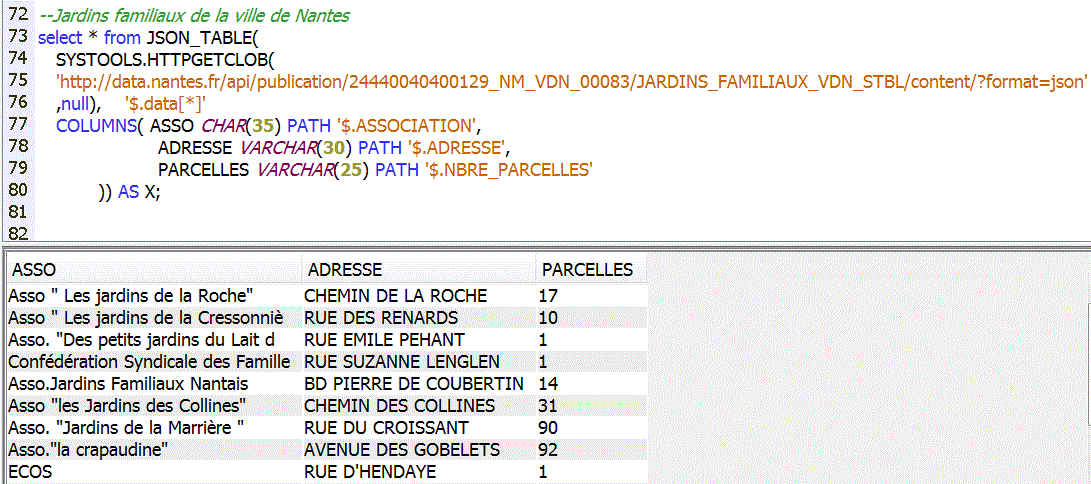
Lax vs Strict
- Avec lax, un élément manquant ne provoque pas d'erreur
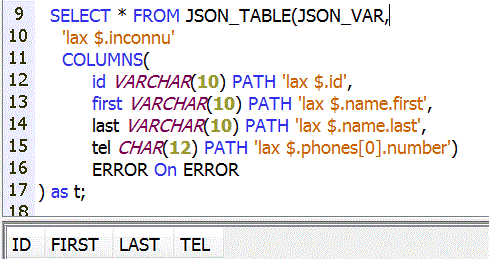
- Avec strict, si
Bien sur tout cela peut être utilisé en RPG


Voyez nos différentes manières de lire du JSON et les temps de réponse respectifs : http://www.volubis.fr/freeware/READJSON.html
- JSON_TABLE pour parser du JSON en SQL
- Autres nouveautés de la TR1
- CUME_DIST permettait d'avoir la distribution cumulée (le dernier valant 1)
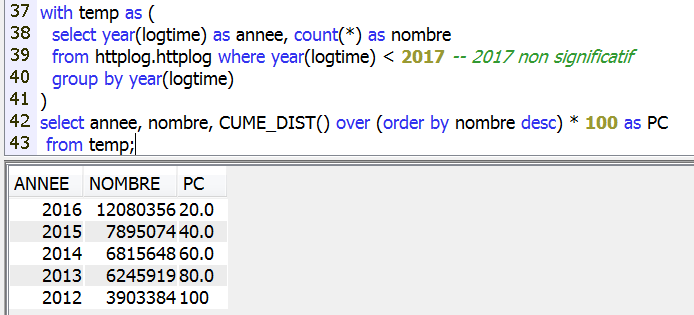
PERCENT_RANK affiche le rang (en %) le premier valant 0

- en SQL PSM vous pouvez désormais inclure du code SQL ou C
- INCLUDE [SQL] bibliothèque/fichier(membre)
ou - INCLUDE [SQL] membre
- Si c'est du C, utilisez l'Api Qp0zLprintf
pour écrire dans la JOBLOG
- INCLUDE [SQL] bibliothèque/fichier(membre)
- en SQL PSM, vous pouviez utiliser SET OPTION pour indiquer des options destinées au compilateur
- BINDOPT permet désormais d'indiquer des options de liage (BNDDIR par exemple)
- INCFILE, le nom du fichier source à inclure
- BINDOPT permet désormais d'indiquer des options de liage (BNDDIR par exemple)
- SYSPARTITIONSTAT est un élément du catalogue SQL et contient la liste des membres des fichiers DB2 (ou sources)
- Il intègre désormais PARTITION_TEXT VARGRAPHIC(50) CCSID 1200, contenant le texte du membre.
- Il intègre désormais PARTITION_TEXT VARGRAPHIC(50) CCSID 1200, contenant le texte du membre.
- La fonction SQL REPLACE évolue :
- elle admetait trois paramètres
REPLACE(source, chaine-recherchée, chaine-remplacement)
- elle peut désormais être utilisée avec deux paramètres uniquement
REPLACE(source, chaine-recherchée)
La chaîne recherchée est tout simplement supprimée
- elle admetait trois paramètres
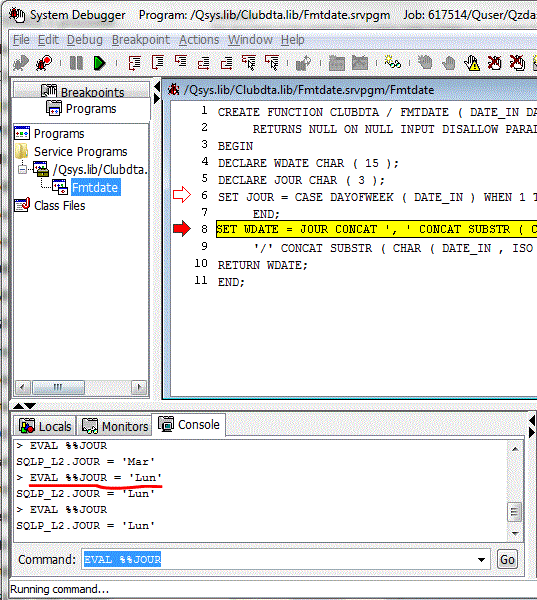
- le debugger SQL (accessible, entre autre, depuis ACS) évolue

cette évolution est accessible pour les procédures, les fonctions et les triggers, compilés avec SET OPTION DBGVIEW=*SOURCE
et recompiliés depuis la TR1
- les types de variables couvert par le dbug (visualisation) sont plus nombreux
- il est possible de modifier le contenu de variables
- Jusqu'à maintenant une fonction pouvait être indiquée :
- Non Déterministe (NOT DETERMINISTIC)
ne retournant pas toujours la même valeur (NOW, par exemple)
- Déterministe (DETERMINISCTIC)
Retournant toujours la même valeur (PI=3,1416, par exemple)
- Désormais vous avez le choix entre :
- Non Déterministe (NOT DETERMINISTIC)
- GLOBAL DETERMINISTIC
- STATEMENT DETERMINISTIC
Retournant la même valeur pendant la durée de la requête (taux de change, par exemple)
dans ce dernier cas, DB2 ne rappelle pas la fonction lors d'une même requête.
- DB2 for I service
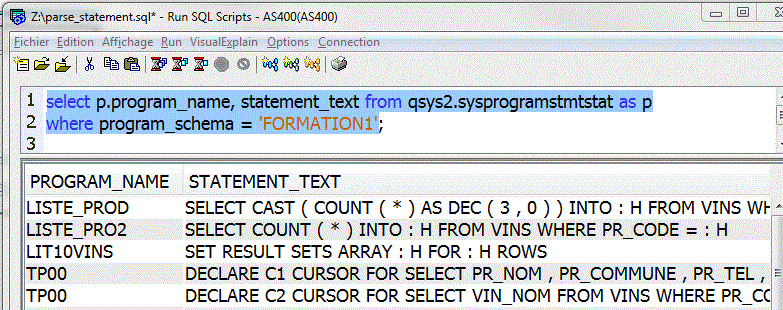
- Nouvelle fonction PARSE_STATEMENT
le fichier catalogue QSYS2.SYSPROGRAMSTMTSTAT donnait déjà la liste des instructions SQL
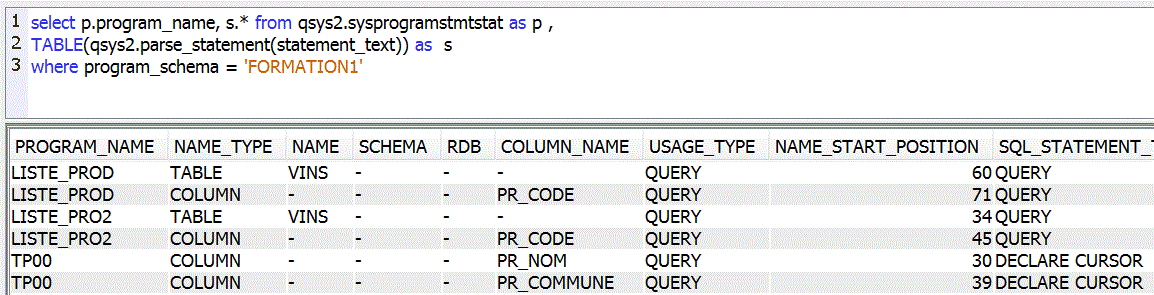
PARSE_STATEMENT permet de retrouver la liste des informations manipulées (Tables, colonnes, curseurs)
- IBM i Services
- QSYS2.HISTORY_LOG_INFO() affiche l'équivalent de DSPLOG

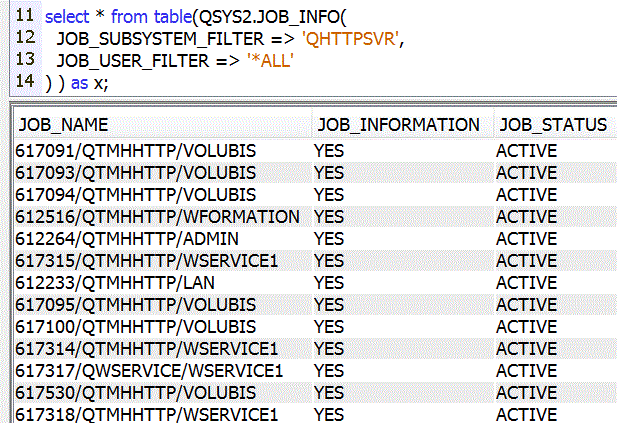
- QSYS2.JOB_INFO()
- affiche les travaux correspondant aux critères indiqués :
>>-JOB_INFO--(-------------------------------------------------->
>--+---------------------------------*ALL----+------------>
'-+------------------------------+--status-'
'-JOB_STATUS_FILTER--=>-'
>--+---------------------------------*ALL--+-------------->
'-,--+---------------------------+--type-'
'-JOB_TYPE_FILTER--=>-'
>--+------------------------------------*ALL---------+-->
'-,--+------------------------------+--sous-système-'
'-JOB_SUBSYSTEM_FILTER--=>-'
>--+------------------------------------USER--------+---->
'-,--+-----------------------------+--utilisateur-'
'-JOB_USER_FILTER-- => -' >--+---------------------------------------*ALL-----+----.
'-,--+----------------------------------+--travail-'
'-JOB_SUBMITTER_FILTER-- => -'
Exemple
- QSYS2.GROUP_PTF_CURRENCY
il faut les PTF suivantes, le fichier XML ayant été déplacé par IBM- HIPER PTF SI62612 for IBM i 7.1
- HIPER PTF SI62620 for IBM i 7.2
- HIPER PTF SI62621 for IBM i 7.3
- la colonne PTF_GROUP_CURRENCY peut prendre la valeur 'CURRENT AT THE NEXT IPL'
- QSYS2.GROUP_PTF_DETAIL
il faut les PTF suivantes, le fichier XML ayant été déplacé par IBM- HIPER PTF SI62612 for IBM i 7.1
- HIPER PTF SI62620 for IBM i 7.2
- HIPER PTF SI62621 for IBM i 7.3
- QSYS2.OBJECT_STATISTIC (équivalent à DSPOBJD) retourne de nouvelles colonnes en 7.3
- Admet désormais *ALLSIMPLE comme bibliothèque (toutes) et ne retourne alors que :
- OBJNAME
- OBJLONGNAME
- OBJTYPE
- OBJLIB
- OBJLONGSCHEMA
- OBJATTRIBUTE
- toutes les autres colonnes sont à NULL
- QSYS2.GET_JOB_INFO() retourne deux nouvelles colonnes
- V_PJ_REUSE_COUNT, pour un pré-start job, nombre de fois ou il a été utilisé
- V_PJ_MAXUSE_COUNT, pour un pré-start job, nombre de fois maxi ou il a peut être recyclé (dft=200)
- QSYS2.DISPLAY_JOURNAL()
- les fonctions de masquage (RCAC) et de cryptage (FIELD PROC) s'appliquent sur les données extraites.
- les fonctions de masquage (RCAC) et de cryptage (FIELD PROC) s'appliquent sur les données extraites.
- QSYS2.HISTORY_LOG_INFO() affiche l'équivalent de DSPLOG
- Nouvelle fonction PARSE_STATEMENT
- RPG
- Nouveau code opération On-Exit indiquant une séquence d'instructions à réaliser en fin de procédure, que cette dernière soir normale ou anormale
- On-Exit {flag-erreur}
si flag-erreur est indiqué, ce doit être un booléen, qui contiendra- *OFF ('0') en cas de fin normale
- *ON ('1') en cas de fin anormale de la procédure
- Exemple
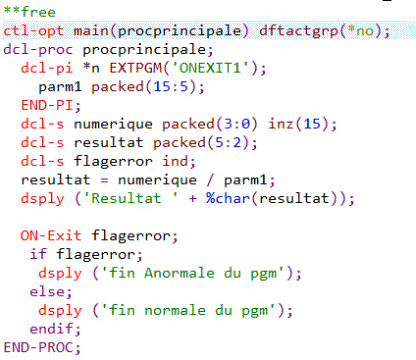

- On-Exit {flag-erreur}
- nouveau paramètre TGTCCSID permettant de compiler un fichier source de l'IFS codé en Unicode.
- Nouveau code opération On-Exit indiquant une séquence d'instructions à réaliser en fin de procédure, que cette dernière soir normale ou anormale
- RDI nouvelle version 9.5.1.1
-
Fixpack disponible en Décembre 2016. C'est une mise à jour de la 9.5.1, c'est la même licence.
-> mise à jour depuis la dernière version d'Installation Manager(1.8.6 du 18 Nov. 2016) , sous Windows et Mac, sans soucis.

Nouveautés
- L'authentification Kerberos fonctionne réellement en mode SSO (sans re-saisie de quoi que ce soit) sous Windows.
- les préférences permettent de choisir l'ouverture en lecture, comme mode d'ouverture par défaut (Parcourir avec..)
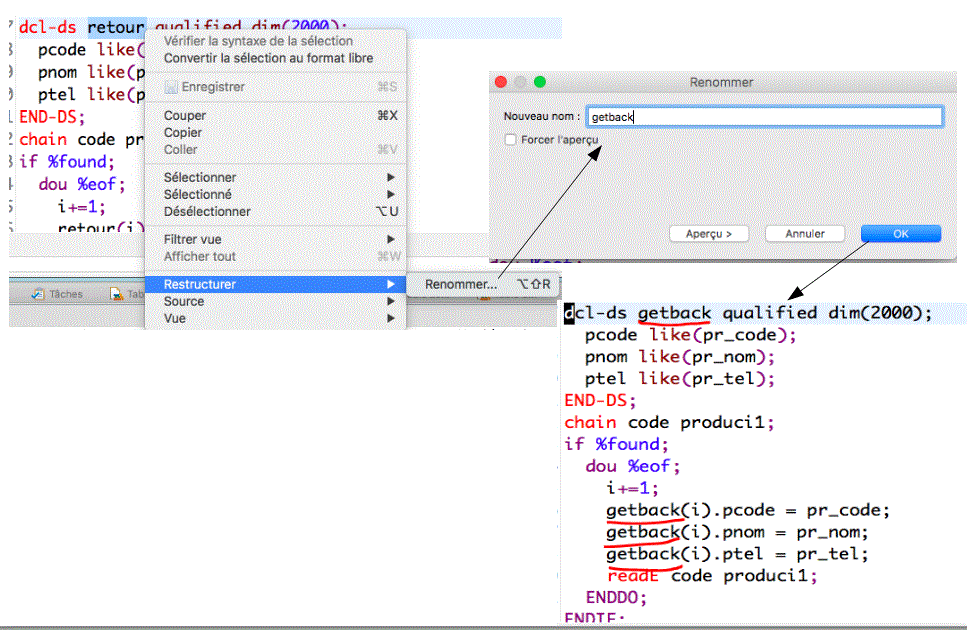
- Nouvelle fonctionnalité "Refactoring" en anglais, appelée en Francais : Restructurer
- Permet, de renommer toutes les occurrences d'un champ (demain, sans doute plus)
- sur un langage colonné, on vous prévient si ca "coince"
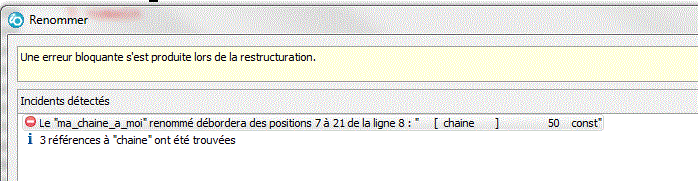
la seule option est alors le bouton "Précédent"
- Avec Apercu, pour mesurer à l'avance les différences
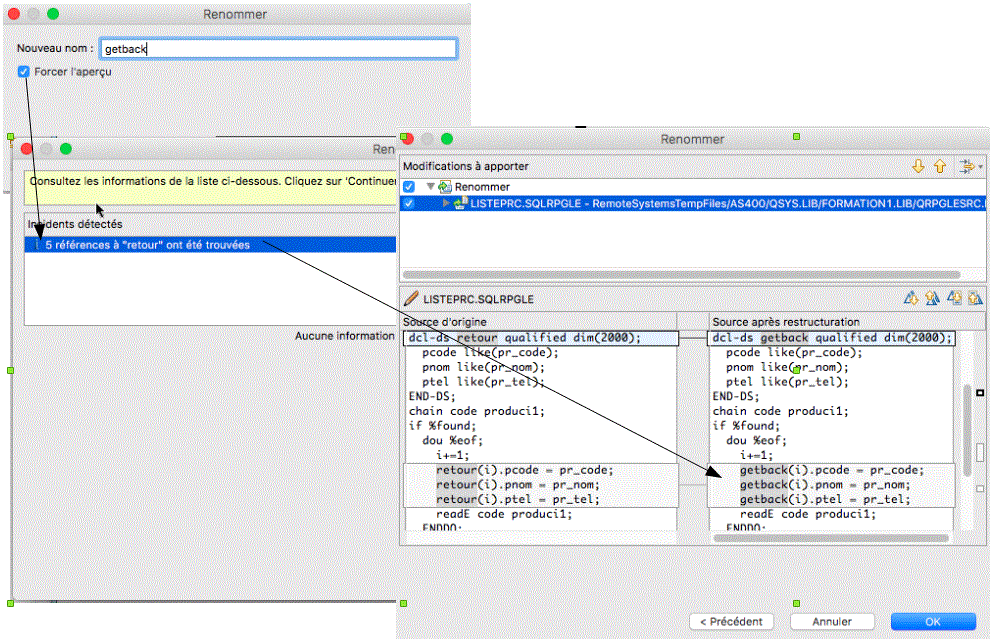
- Vous pouvez descendre au niveau détail (ici une procédure change de nom)
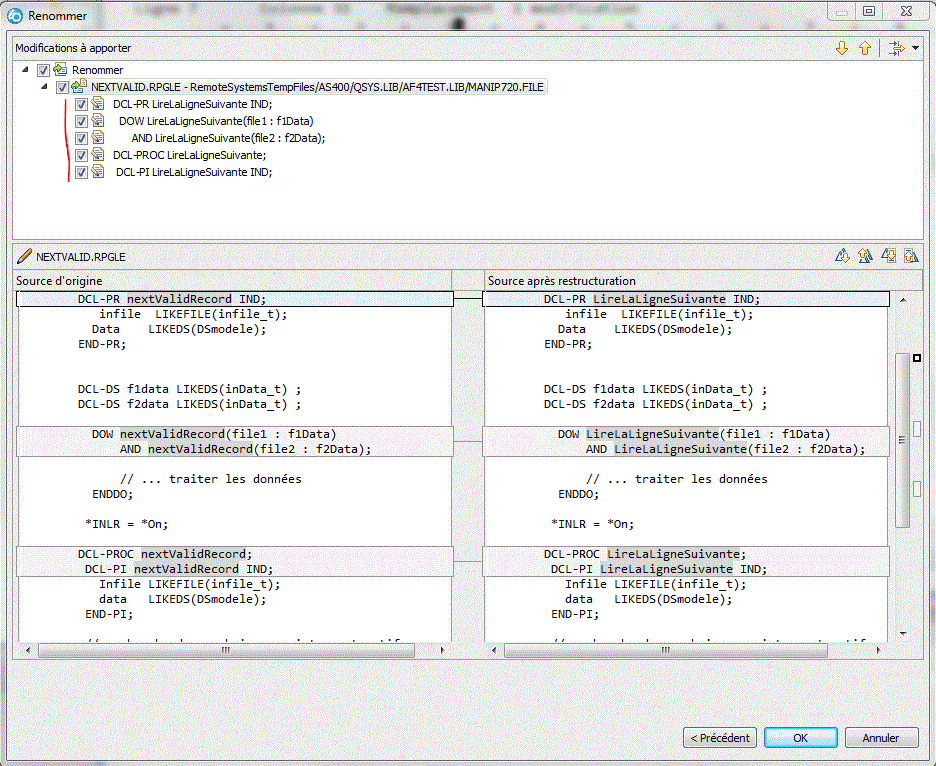
- Affichage des messages d'erreur sous forme d'annotation
- Avant
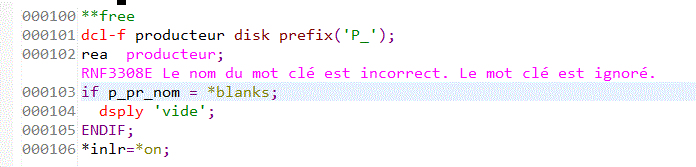
- paramétrage
- Après


- Avant
- Enfin cette version supporte parfaitement le nouveau code opération On-Exit vu plus haut.

- Permet, de renommer toutes les occurrences d'un champ (demain, sans doute plus)
- L'authentification Kerberos fonctionne réellement en mode SSO (sans re-saisie de quoi que ce soit) sous Windows.
-
- IBMi Access Client Solution
- Rappel, il intègre de nouvelles fonctions Database, dont Visual Explain
- le transfert de fichier en mode natif n'était plus disponible avec la version 1.1.6 (bug) il revient en 1.1.6.1
voir https://twitter.com/CmasseVolubis/status/803268709649293312
dans ce tweet, le plugin CLDOWNLOAD transfert une vue en fichier Excel
Rappel : comment faire une vue paramétrable ?
•Créez des variables globales (CREATE VARIABLE)
•Créez une vue utilisant ces variables dans la clause WHERE
•Modifiez le contenu des variables, juste avant le transfert - La mise à jour de Janvier 2017, permet
- plus de filtres sur la gestion des spools
AVANT
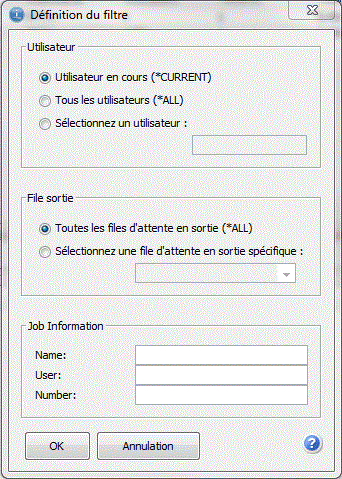
APRES
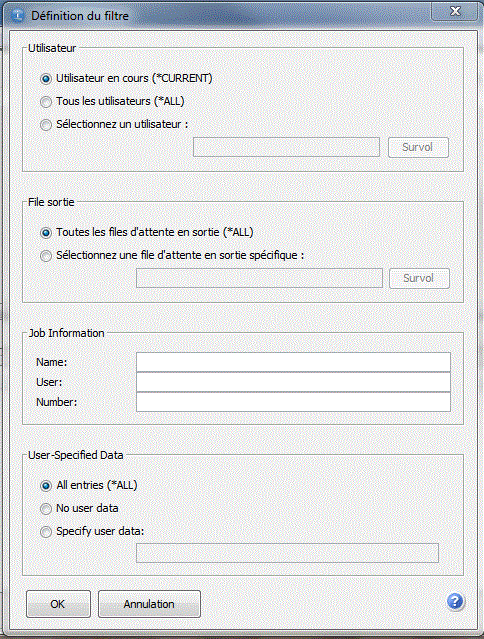
OUTQ multiples

- une extension EHLLAPI (spécifique Windows) offrant des API pour "piloter" l'émulateur
- Enfin, cette version permet de restreindre les fonctions utilisables avec Administration d'applications
Nos exemples utiliserons Navigator for I
Choisir "Gestion locale"
Pour la fonction spool
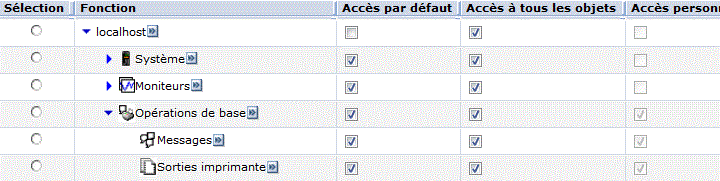
Personnalisation

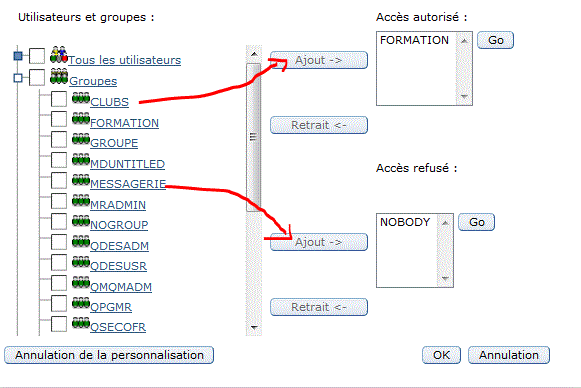
Résultat

Le nom de la fonction qui vous est rappelé, est celui montré par le mode commande WRKFCNUSG

Accès à l'IFS

Accès à l'émulateur et au transfert de fichiers
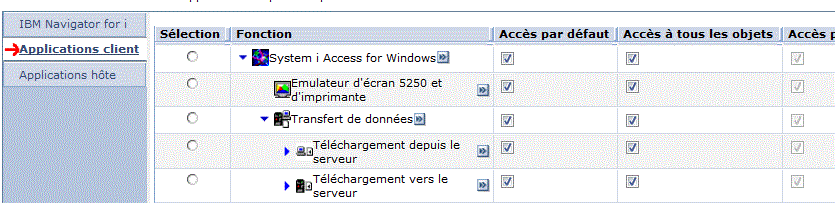
Accès aux scripts SQL et à performance Center
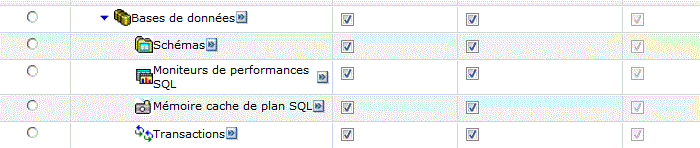
- plus de filtres sur la gestion des spools
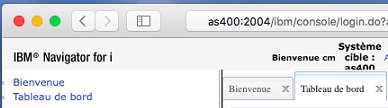
- Navigator for I
- Avec SI62073 et SI62074, Navigator for I utilise http (et non plus https) sur le port 2004
- Cerise sur le gâteau, Safari fait partie des navigateurs supportés
- Serveur intégré
- Avec SI99722 level5, le serveur de web services génère des fichiers swagger pour les services REST
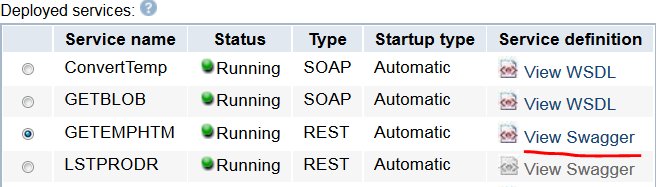
- Avec SI99722 level5, le serveur de web services génère des fichiers swagger pour les services REST
- IBM i
- la commande PWRDWNSYS possède un nouveau paramètre INSPTFDEV
- *NONE
Aucune PTF n'est installée avant que le système ne soit mis hors tension.
- *SERVICE
Les PTF envoyées par le système du service de maintenance sont installées avant que le système ne soit mis hors tension
- OPTxx/RMSxx
Spécifiez le nom de l'unité optique ou de l'unité amovible (USB) à partir de laquelle les PTF sont installées avant que le système ne soit mis hors tension.
Toutes les PTF sont marquées pour une application différée et seront appliquées au prochain IPL sans contrôle opérateur.
- *NONE
- Et la commande CHGSRVA propose de télécharger automatiquement les derniers Groupes PTF
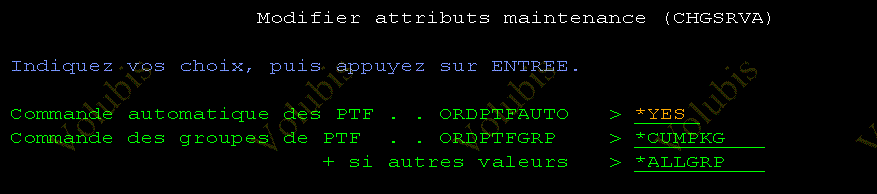
Voici les valeurs admises
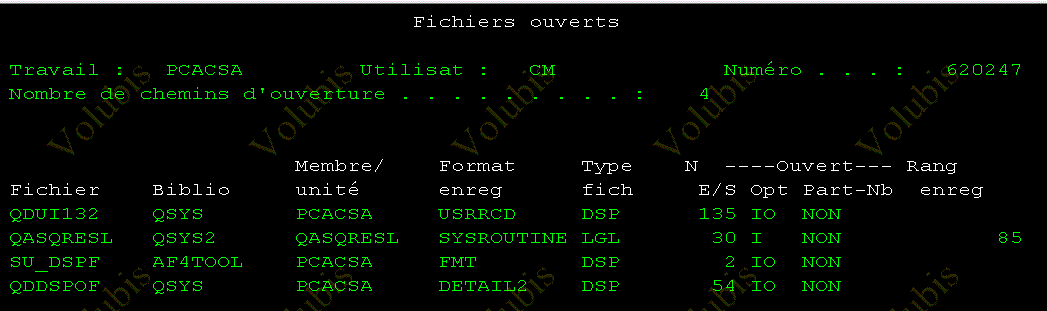
- WRKJOB, option 14 (fichiers ouverts)
SI vous créez la Data area QDMDSPFOIO, par
CRTDTAARA DTAARA(QUSRSYS/QDMDSPOFIO) TYPE(*LGL) LEN(1) AUT(*USE)
Vous verrez, d'abord les IO
Avant de voir les groupes d'activation (F11)

Enfin, nouveauté, si vous faites F11 une 3ème fois, vous verrez les textes des fichiers ouverts :

- la commande PWRDWNSYS possède un nouveau paramètre INSPTFDEV
- 5733OPS
- Intégration de gzip avec SI62331

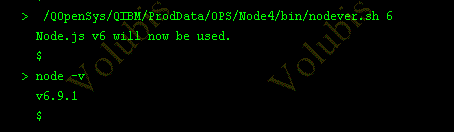
- Support de Nodejs V6 (option 10 de 5733OPS) avecSI61901
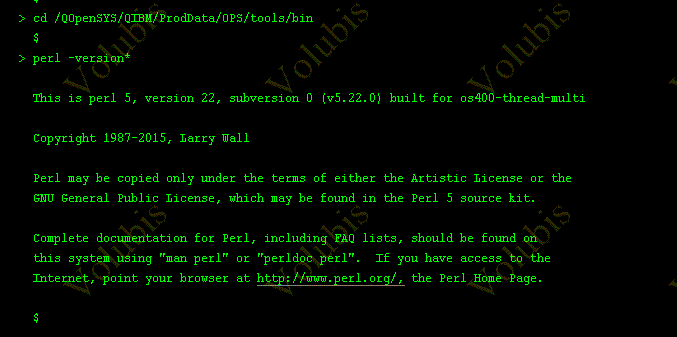
- Intégration de PERL (option 7 de 5733OPS) avec SI62570
- Git passe en version 2.10.2 et intègre curl (la possibilité de cloner un dépot avec le protocole HTTP)
par exemple : git -c http.sslverify= false http://github.com/OSSILE/OSSILE
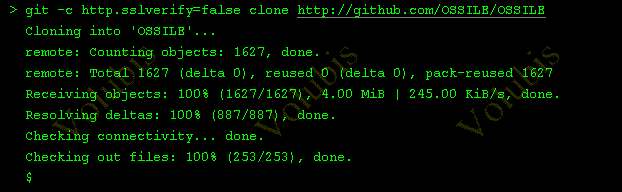
résultat
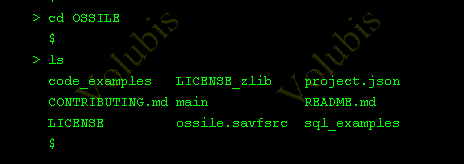
Sous RDI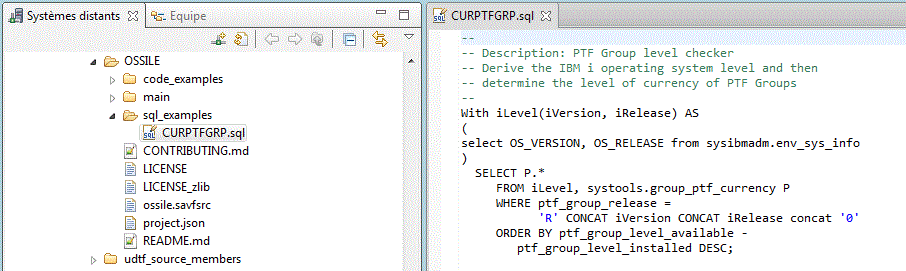
Tout cela arrive avec la PTF SF99225, level 2

- Intégration de gzip avec SI62331
Nous avons essayé de participer (modestement) au projet OSSILE sur Github avec Orion comme client
Nous n'avons pas le droit de faire des modifications sur le site (nous ne sommes pas administrateur), il faut faire une branche (fork)Après nous être signé (il faut un compte)
Résultat
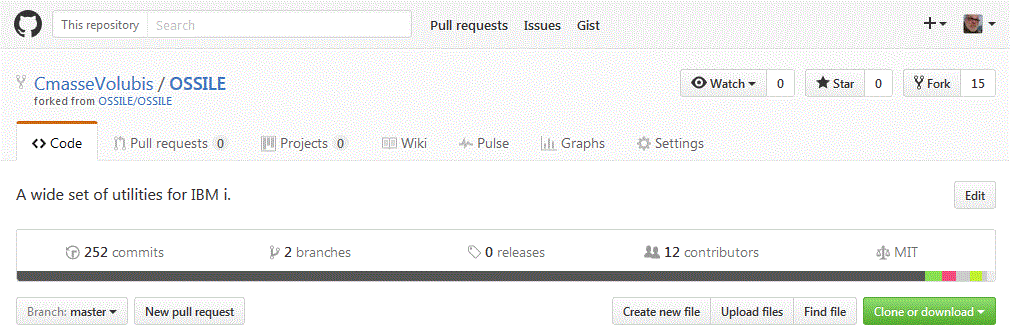
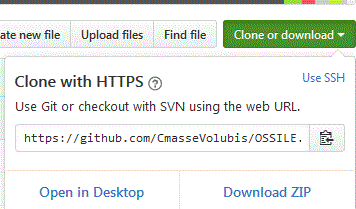
Regardons le lien pour le cloner (copie locale)
Sous ORION
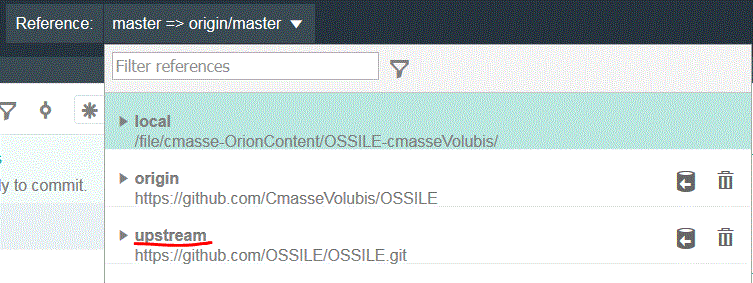
Si vous voulez que les modifications effectuées par d'autre sur la branche d'origine, soit répercutées localement, ajoutez :
Saisissons quelques nouveautés
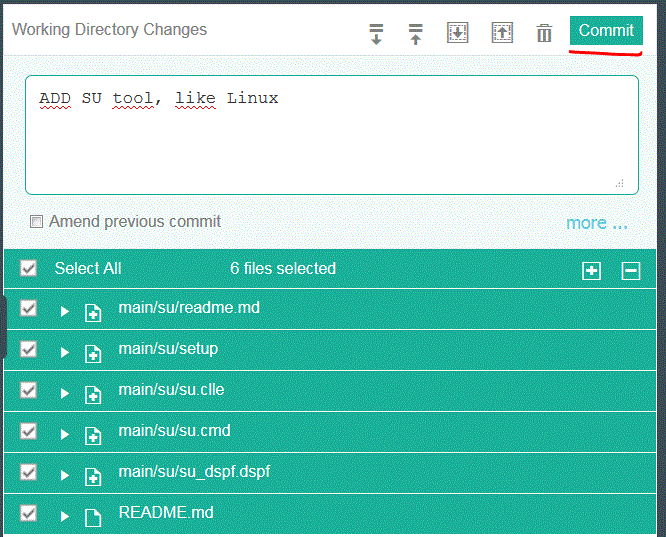
Quand nous basculons sur le client git
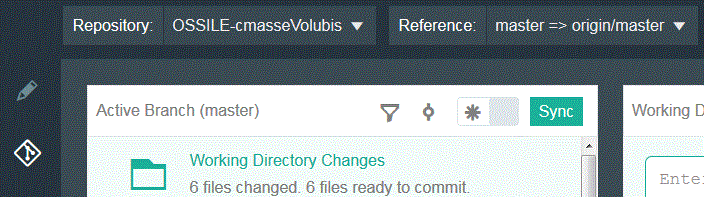
Commitons (COMMIT)
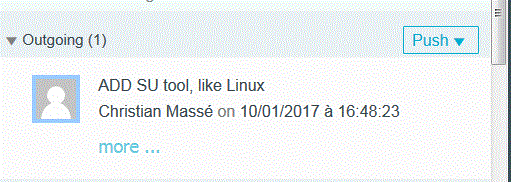
Puis transmettons les modifications (PUSH)
Avec authentification
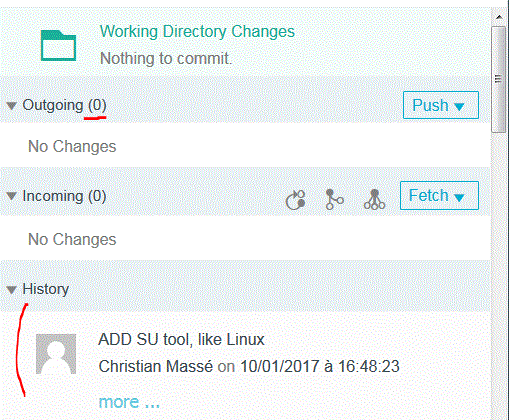
Et voilà
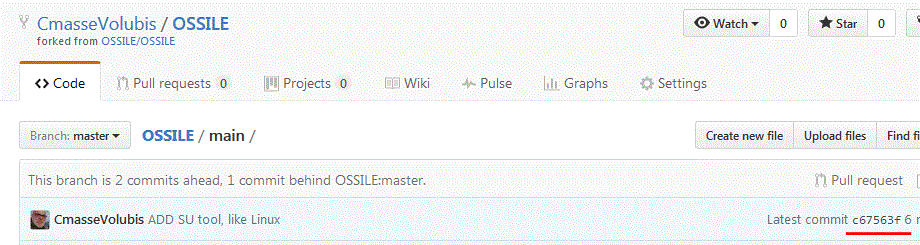
Vérifions sur le site github (dans notre branche)
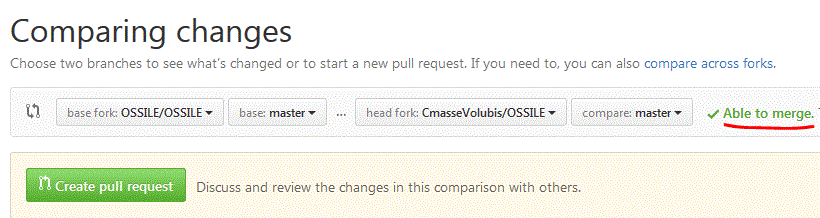
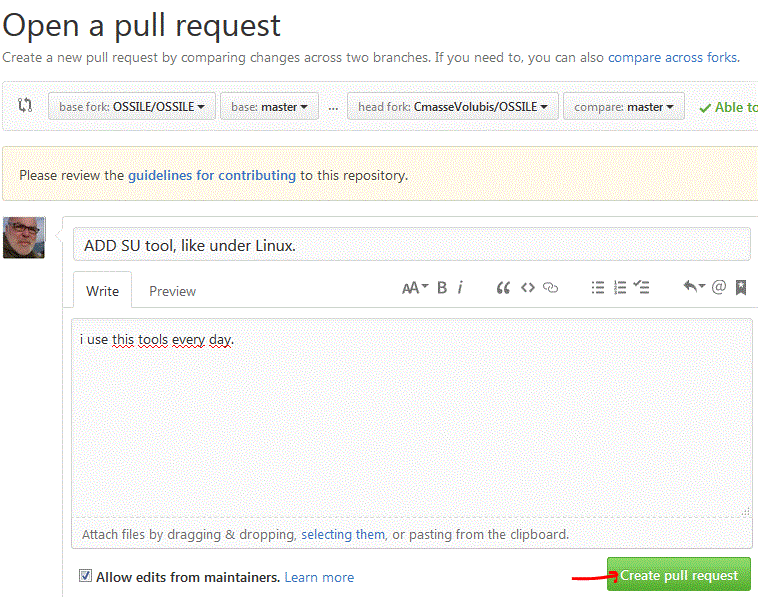
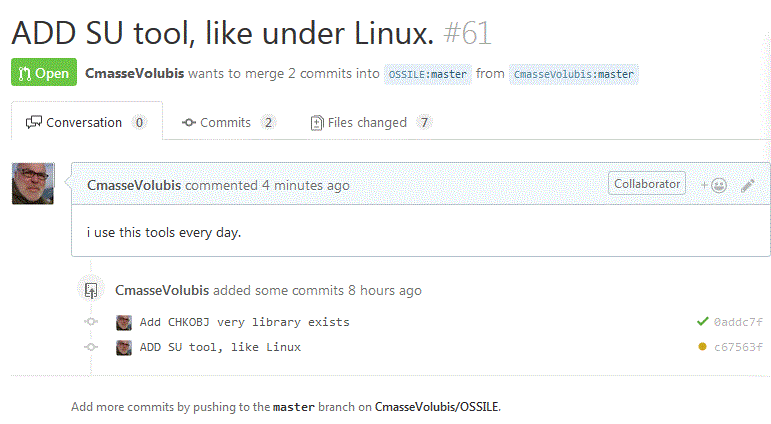
Pour faire une demande de fusion (avec la branche principale) PULL REQUEST
Create PULL Request
Cette demande porte le n° 61 (en attente de validation par l'administrateur)
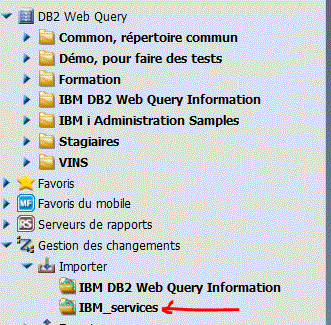
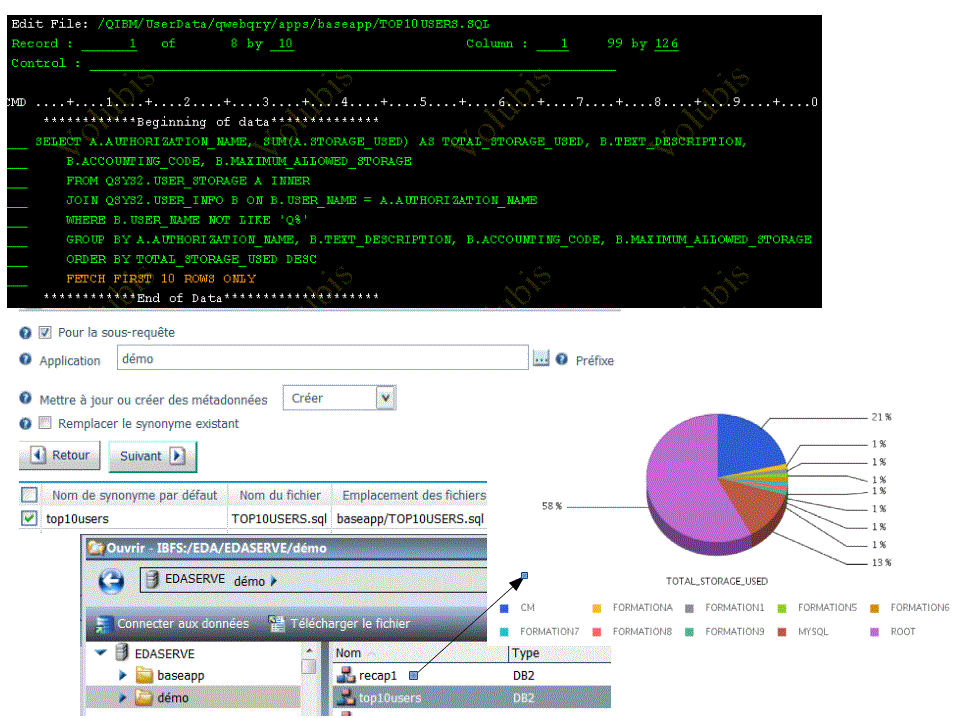
Janvier 2017, IBM propose une installation simplifiée (ez-setup) de DB2 Web Query et quelques rapport "IBM i Services"
Voyez http://db2webqueryi.blogspot.fr/ou envoyez un mail à QU2@US.IBM.com pour les obtenir, restaurez comme indiqué dans le document founi
Puis importez les
ET voilà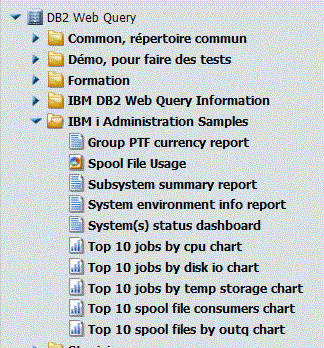
Liste des groupe PTF (à jour / pas à jour, utilise HTTPGETBLOB)
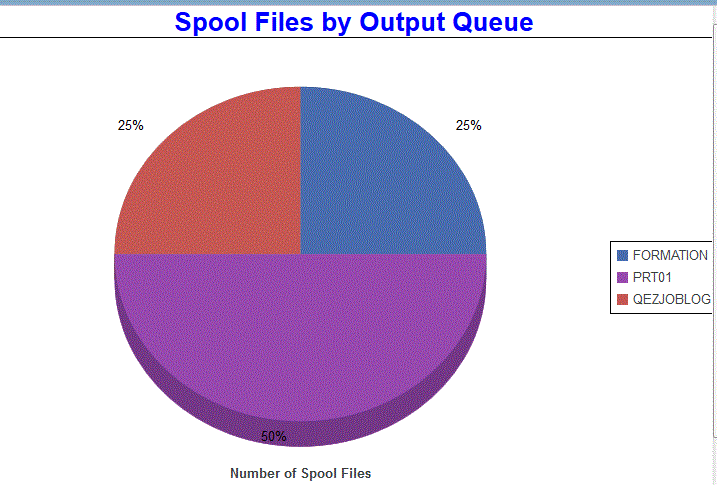
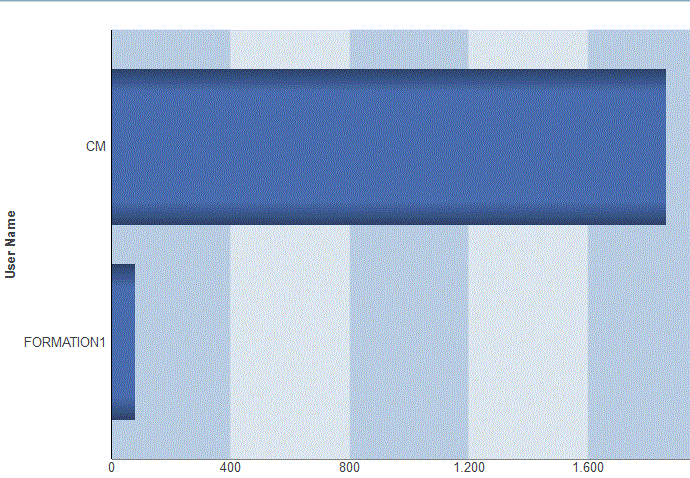
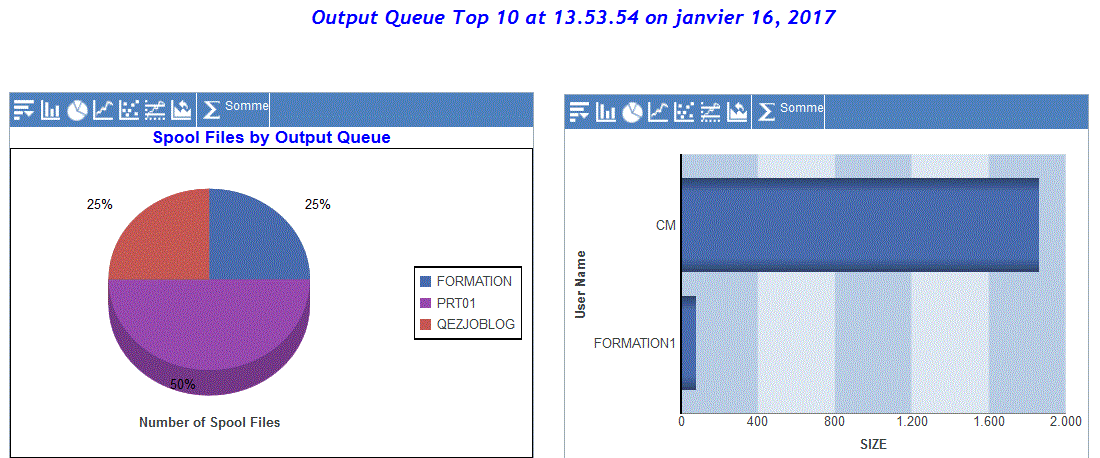
Spools
Par OUTQ
Par Utilisateur
Récapitulatif
Sous-systèmes
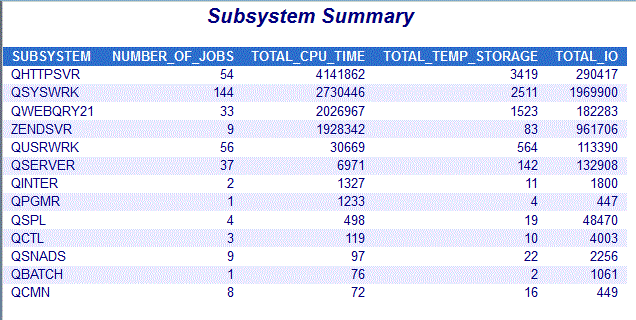
Informations Système

Etat du système
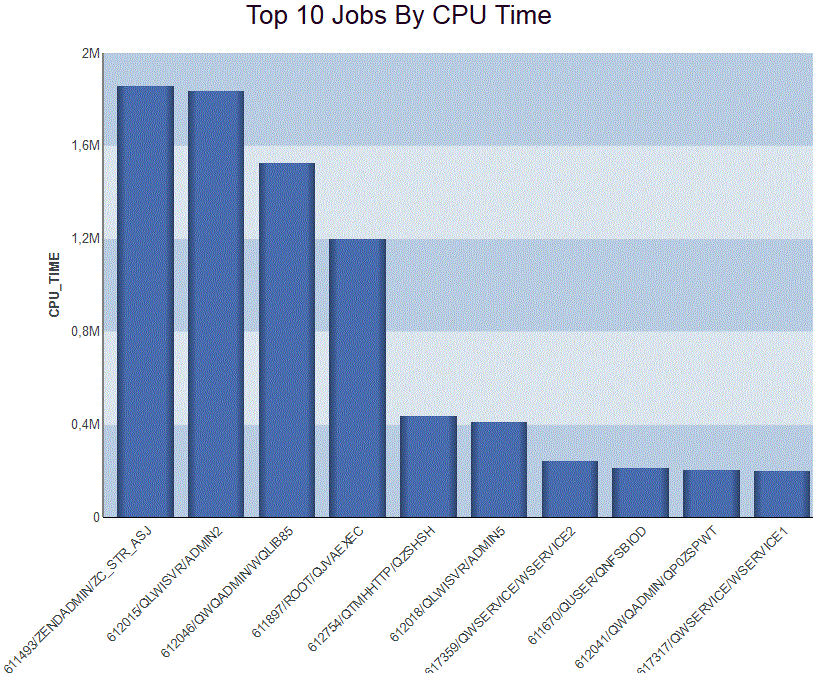
TOP 10 de la CPU par Utilisateur
TOP 10 de l'utilisation disque
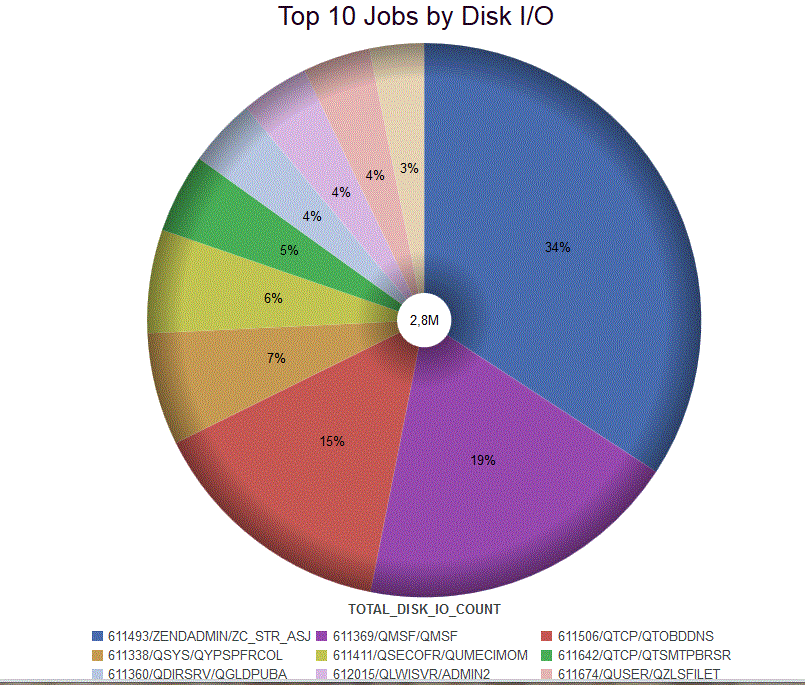
TOP 10 de la mémoire temporaire consommée

Vous pouvez bien sur faire vos propres rapports
Inspirez vous des exemples fournis dans ACS
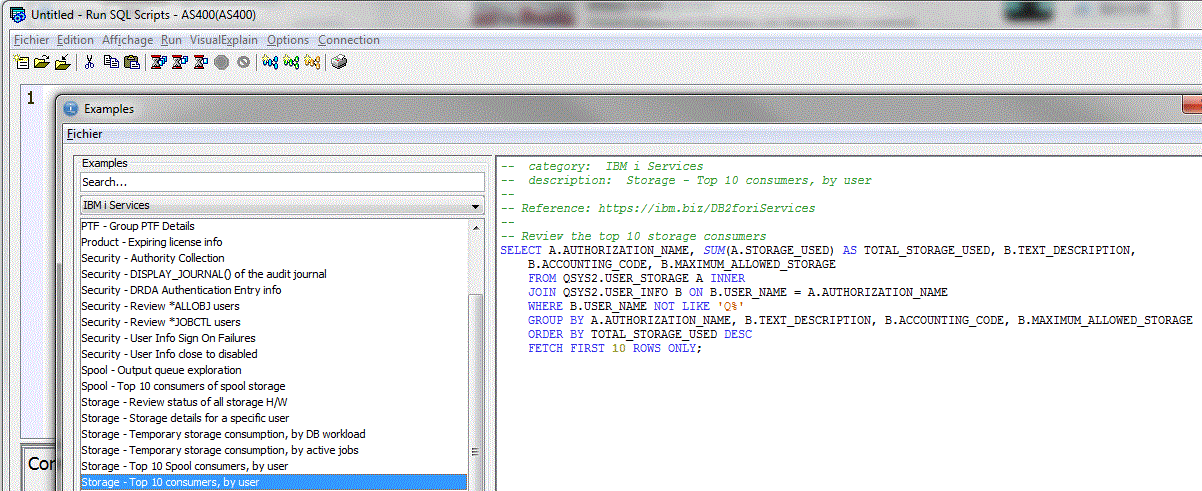
Créez une nouvelle méta-donnée (ici basée sur une requête stockée dans l'IFS), puis faites un rapport.