pause-café
destinée aux informaticiens sur plateforme IBM i.
Pause-café #74
Retour sur les nouveautés 7.3
Statistiques
De nombreuses fonctions, annoncées en 7.3, sont en fait implémentées par la SF99703 / level 2
- Nous illustrerons, donc, les fonctions vues la dernière fois
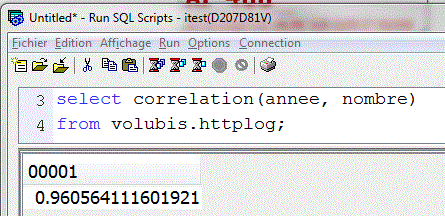
- CORRELATION(x , y)
la COVARIANCE divisée par le produit des écart-type (compris entre -1 et 1)
- Un signe négatif indique que les deux arguments évoluent
en sens contraire (l'un monte, l'autre descend)
- Proche de 0, ils évoluent de manière indépendante (non liée)
- Proche de 1, ils évoluent de manière liée
ex : température extérieure et consommation de crèmes glacées
- Ou de -1, ils évoluent de manière liée, mais inverse
ex : température extérieure et consommation de chauffage.
Exemple, avec le nombre de "hits" sur notre site Volubis.fr, qui croît depuis quelques années
La Covariance est peu lisible (ici, exprimée en nombre de "hits")
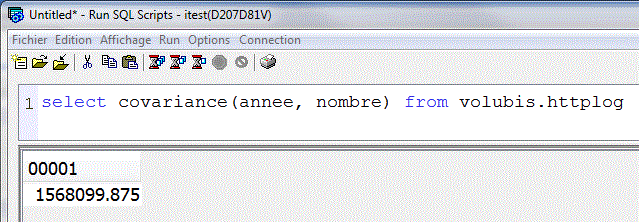
La corrélation avec l'année est avérée, et plus simple à lire (proche de 1)
- Un signe négatif indique que les deux arguments évoluent
en sens contraire (l'un monte, l'autre descend)
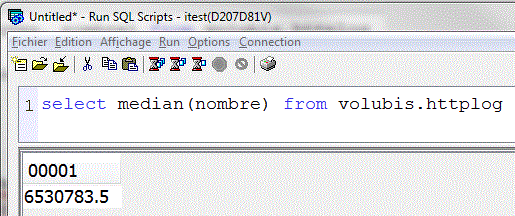
- MEDIAN(x)
Valeur médiane, valeur du milieu.
- PERCENTILE_CONT (continue)
- PERCENTILE_DISC (discret = échantillon)
- Ces deux fonctions calculent le « pourcentille », dont on donne la valeur en argument
- Ex : percentille_cont(0,5) donne la valeur médiane : identique à MEDIAN()
- Select percentille(0,33) WITHIN GROUP (order by salary) from employee
- Tri les lignes par salaire et donne le salaire ayant 33 % des lignes au dessus et 66 % en dessous
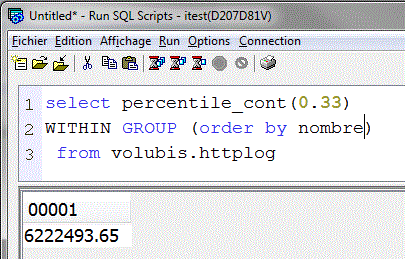
liste des années qui sont dans le premier tiers
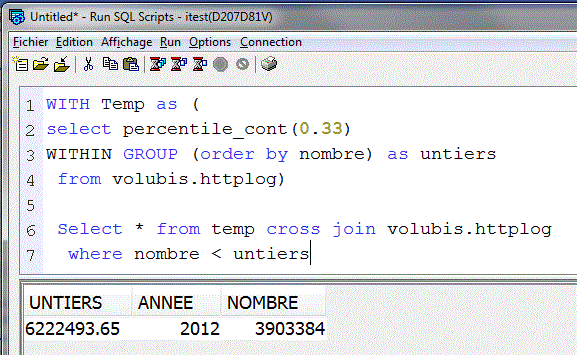
rappel
- Tri les lignes par salaire et donne le salaire ayant 33 % des lignes au dessus et 66 % en dessous
- Si le nombre de lignes est pair :
- PERCENTILLE_CONT Fait la moyenne entre les deux lignes du milieu
- PERCENTILLE_DISC Retourne la première
- PERCENTILLE_CONT Fait la moyenne entre les deux lignes du milieu
- Régression & Régression linéaire
- Définition
- Il s'agit de voir s'il y a une relation entre deux valeurs
- la température baisse-t-elle quand la l'altitude augmente, dans une région donnée ? (C'est probable)
- Le taux d'émission de gaz à effet de serre d'un pays est -il lié à son PIB ?
- Voyons si nous pouvons tracer une courbe (régression) ou une droite (régression linéaire) ayant
- sur l'axe des X l'altitude ou le PIB
- et sur l'axe des Y la température ou le taux d'émission des G.E.S
- La droite de régression

Avec les données collectées, nous observons un nuage de points de forme plus ou moins rectiligne.
Ci-dessus, la flèche noire indique, pour l'observation n° 7, la distance entre le modèle théorique (droite rouge) et la réalité (point bleu).
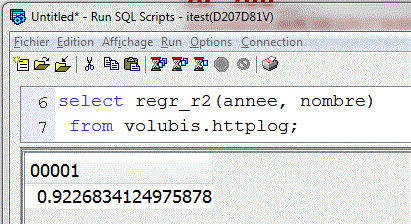
- Nouvelles fonctions de régression en 7.3 : REGR_nnnn(x, y)
X étant l'ordonnée (le PIB du Pays)
Y étant l'abscisse (le taux d'émission des G.E.S)
- REGR_COUNT() -> Nbr de paires non nul
- REGR_INTERCEPT /REGR_ICPT (ordonnée à l'origine (valeur de x quand y=0), ou constante de régression)
- REGR_R2 (coefficient de détermination, proche de 1, les points sont tous près de la droite)
- REGR_SLOPE (la pente)
- REGR_AVGX (moyenne de x, après élimination des valeurs nulles)
- REGR_AVGY (moyenne de y, après élimination des valeurs nulles)
- REGR_SXX ( REGR_COUNT(X, Y) * VARIANCE(Y) )
- REGR_SXY (REGR_COUNT(X, Y) * COVARIANCE(X, Y) )
- REGR_SYY ( REGR_COUNT(X, Y) * VARIANCE(X) )
Toujours avec notre historique sur le site Volubis.fr
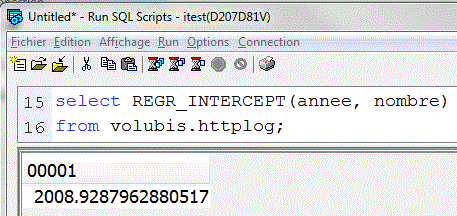
La pente est montante, plus le n° de l'année augmente, plus le nombre hits augmente.
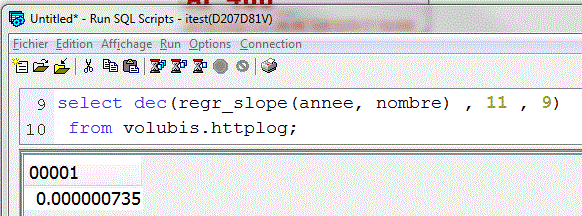
La pente avec l'ancienneté est descendante, plus l'ancienneté est petite, plus le nombre de "hits" augmente (même valeur, mais négative)
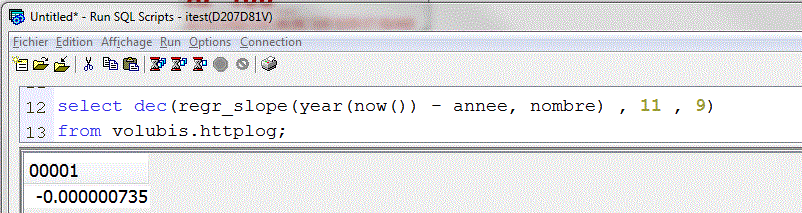
Ordonnées à l'origine, ou, si la pente est toujours vraie, année à laquelle nous étions à 0 hits (ce n'est pas le cas)
- Définition
- Fonctions OLAP
- Après
- ROW_NUMBER() over (order by xxx)
- RANK() over (order by xxx)
- DENSE_RANK() over (order by xxx)
- ROW_NUMBER() over (order by xxx)
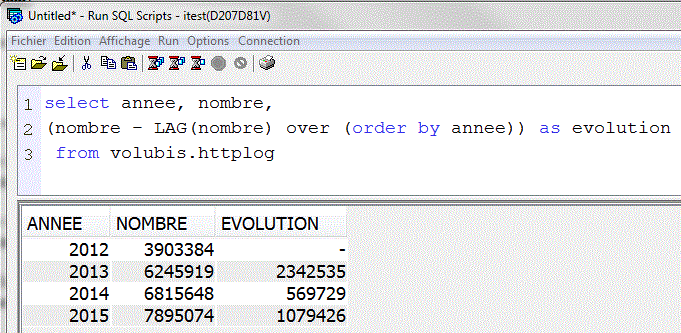
- LAG() over (order by xxx) retourne la valeur de la ligne du dessus, suivant le tri
- LEAD() over (order by xxx) retourne la valeur de la ligne de dessous, suivant le tri
- Génial pour calculer un % d'évolution (par rapport à l'année précédente, par ex.)
- On peut préciser un "offset" (Combien de lignes au dessus/au dessous)
- Génial pour calculer un % d'évolution (par rapport à l'année précédente, par ex.)
- Après
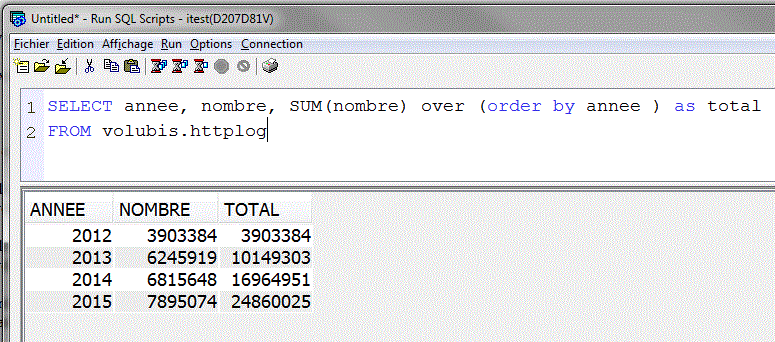
- Toutes les fonctions d'agrégation acceptent désormais OVER (Partition BY xx Order By yy)
- Nouvelles fonctions OLAP d'agrégation
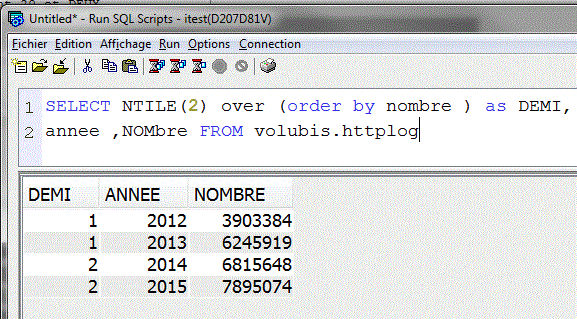
- NTILE() permet de calculer le quantile
- NTILE(4) la quartile
- NTILE(10) le décile
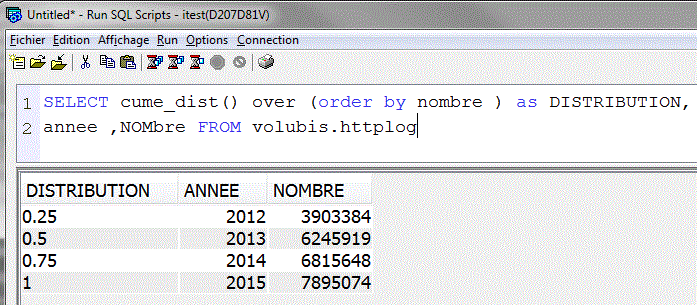
- CUME_DIST() Permet de calculer la distribution cumulée (sur le rang), le dernier valant 1
- FIRST_VALUE, la première valeur
- LAST_VALUE, la dernière valeur
- NTH_VALUE, la énième valeur
- FIRST_VALUE, LAST_VALUE
- Implique un argument
- la zone
- la zone
- Possède une option
- RESPECT NULLS | IGNORE NULLS
- Implique un argument
- NTH_VALUE
- Implique deux arguments
- La zone
- La position (valeur de n)
- La zone
- Possède deux options
- FROM FIRST | FROM LAST
- RESPECT NULLS | IGNORE NULLS
- FROM FIRST | FROM LAST
- Implique deux arguments
- FIRST_VALUE, LAST_VALUE
- RATIO_TO_REPORT (% de la somme cumulée, suivant les paramètres de OVER)
Exemple avec la fréquentation de Volubis.FR
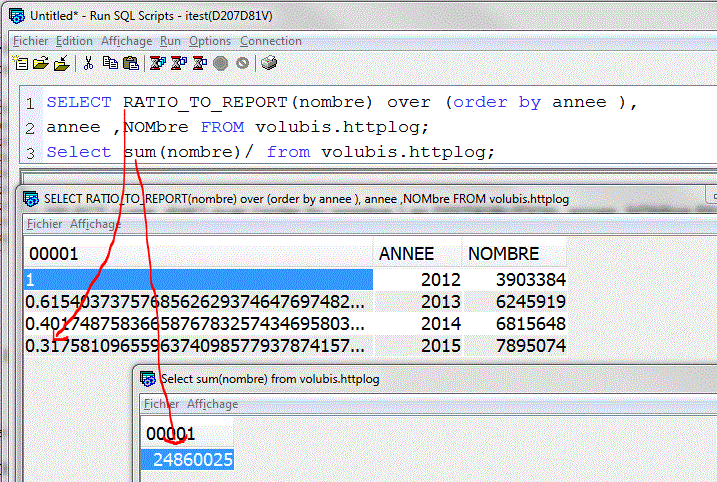
Effectivement la dernière ligne représente un tiers de la somme cumulée, c.a.d, puisque c'est la dernière, du total.
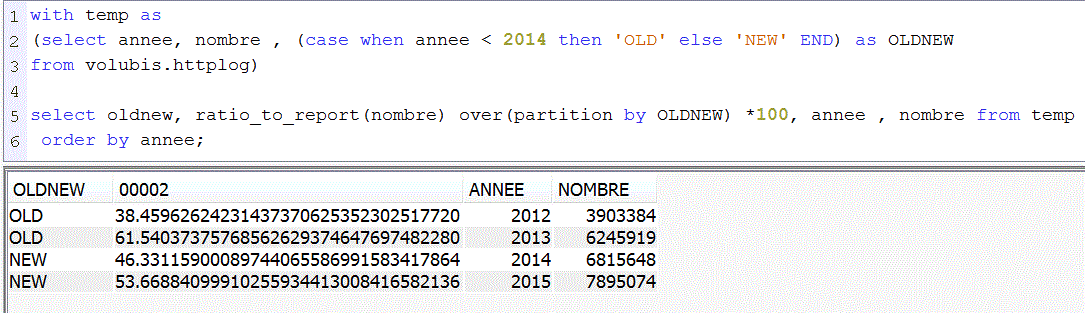
Ratio sur un classement "OLD" ou "NEW"
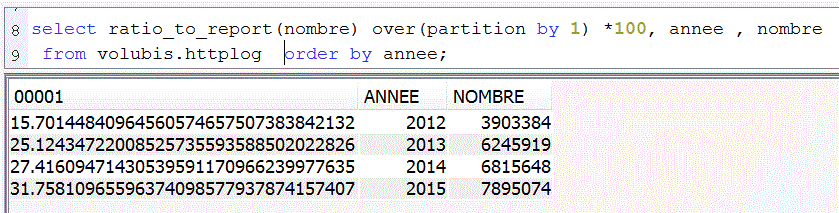
Ratio sur l'ensemble
- Fenêtrage : Pour ces fonctions d'agrégation
- Fonctions d'agrégation « traditionnelles » utilisée avec OVER (SUM, AVG, etc...)
- Fonctions d'agrégation OLAP (First_value, Last_value, Nth_value, Ratio_to_report)
- Fonctions d'agrégation « traditionnelles » utilisée avec OVER (SUM, AVG, etc...)
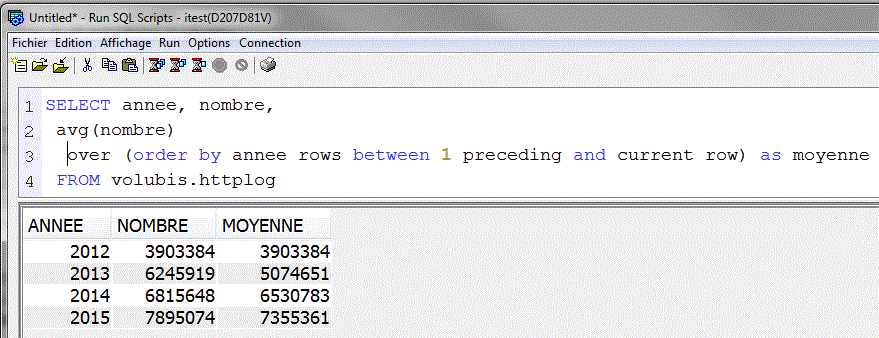
- Il est possible d'indiquer une « fenêtre » de travail
- ROWS → fenêtre basée sur les x lignes précédentes et suivantes
- RANGE → fenêtre basée sur les x valeurs de clé précédentes et suivantes
- Vous pouvez indiquer
- Une position de départ (sous-entendu jusqu'à la ligne en cours)
- Une position d'arrivée (sous-entendu à partir de la ligne en cours)
- Une plage avec BETWEEN début AND fin
- Début (position de départ ou BETWEEN)
- UNBOUNDED PRECEDING
- n PRECEDING (n lignes ou clés précédentes)
- CURRENT ROW
- UNBOUNDED PRECEDING
- Fin (position d'arrivée ou BETWEEN)
- UNBOUNDED FOLLOWING
- n FOLLOWING (n lignes ou clés suivantes)
- CURRENT ROW
- UNBOUNDED FOLLOWING
- Une position de départ (sous-entendu jusqu'à la ligne en cours)
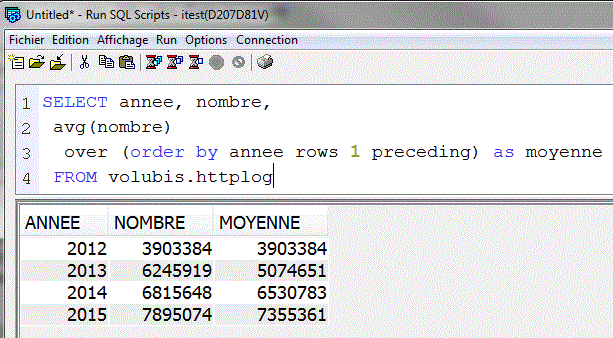
Exemple
Qui aurait pu s'écrire
Dernière minute : les TR5/TR1 sont annoncées et intègrent une gestion du format JSON en SQL (JSON_TABLE)
- NTILE() permet de calculer le quantile
5733OPS : Produits Open Source : Orion & Git
- IBM propose via un nouveau produit, l'intégration de projets Open source : 5733OPS
- A l'origine Node.JS
- en TR2, Python
- en TR3, le compilateur GCC.
- en TR4 ou version 7.3
- Tools (zip/unzip)
- Orion
- Git
- en TR5/TR1
- PERL
- PERL
Tools
implémenté par 5733OPS option 7 et trois PTF (à ce jour) :
- SI61064 -> unzip
- SI61065 -> zip
- SI61062 -> bash
Pour les utilitaires zip/unzip, ils se trouvent dans /QOpenSys/QIBM/ProdData/OPS/tools/bin/
ils fonctionnent comme cela :
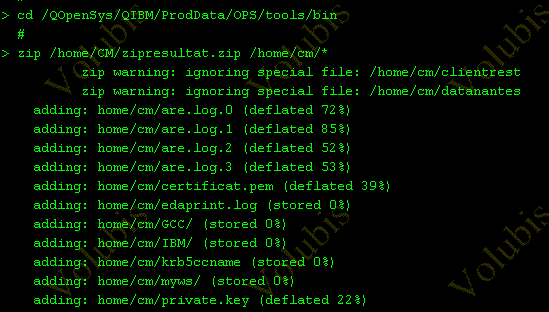
le fichier résultat est lisible par Windows, 7zip ET IBM i (cde CPYFRMARCF)

Pour bash, cela permet d'utiliser ce Shell plutôt que celui fourni en standard par QP2TERM qui est plutôt un Korn Shell
(les spécialistes Unix/Linux apprécierons)
il est situé dans le même répertoire

Pour le lancer- Sous QP2TERM

- En automatique
echo 'exec /QOpenSys/QIBM/ProdData/OPS/tools/bin/bash' >> .profile

- Sous QP2TERM
Node.JS V4
- Node.JS version 4 est installé par la PTF SI59404 et l'option 5 de 5733OPS
- les deux versions 0.12 et 4 cohabitent
- Vous pouvez choisir la version "active" par /QOpenSys/QIBM/ProdData/OPS/Node4/bin/nodever.sh
- un-numéro : vous indiquez la version de Node.js à utiliser
- list, la liste des versions disponibles vous est affichée pour faire un choix
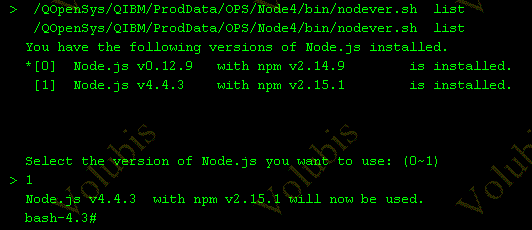
- Node.JS V4 est plus rapide et utilise ECMAScript 2015 (ES6), voir https://nodejs.org/en/docs/es6/
Python2
IBM recommande Python 3 plutôt que Python 2, mais parce que certaines librairies ne supportent pas Python, 3 l'option 4 de 5733-OPS installe cette ancienne version du langage
Cloud-Init
- 5733OPS option 9 et SI59978 & SI61037 installent Cloud-Init (pour cloner une machine virtuelle, voir la doc Power VC)
- Placez vous dans /QOpenSys/QIBM/ProdData/OPS/cloudinit/install/
- sous QP2TERM lancez cloud-init-setup.sh -download_and_install.
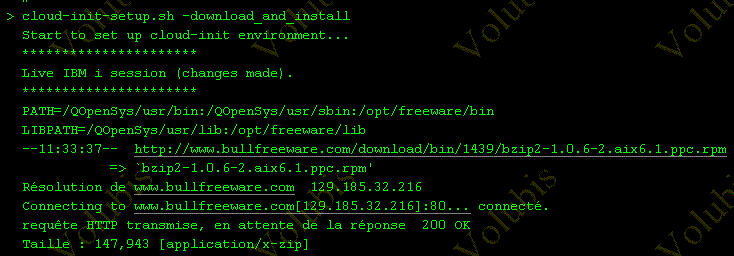
Comme pour le compilateur GCC, cela va chercher le RPM sur le net
- Sur chaque machine virtuelle devant être capturée :
- CALL PGM(QSYS/QAENGCHG) PARM(*ENABLECI)
- CALL PGM(QSYS/QAENGCHG) PARM(*ENABLECI)
- Voyez ensuite la procédure de capture sur knowledgecenter
- Placez vous dans /QOpenSys/QIBM/ProdData/OPS/cloudinit/install/
Git
Amené par 5733OPS option 6 et la PTF
- SI61060
Il s'agit d'un produit de gestion de version décentralisé ou Version Control System (VCS en angl. ), voir la définition Wikipedia
Il est accessible en mode Web, par exemple GitHub (voyez ce projet sur iconv() ou celui ci pour envoyer des SMS) ou bitBucket.org (Sur ce site notre projet gratuit SU )
Une fois le produit installé vous devez trouver cette arborescence
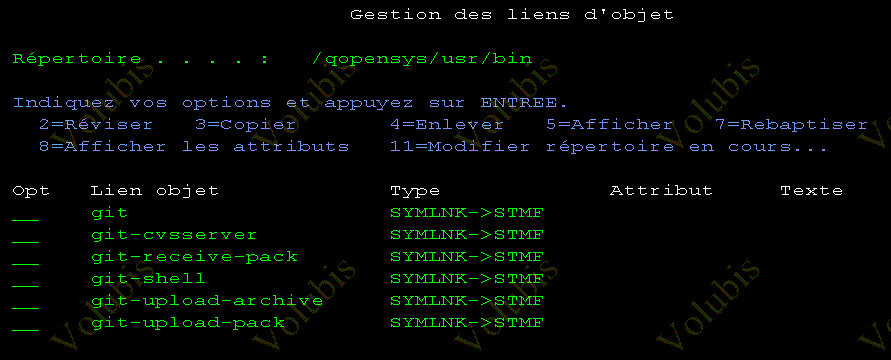
Vous pouvez, désormais, utiliser le produit en mode commande -> voir la documentation en Français (PDF)
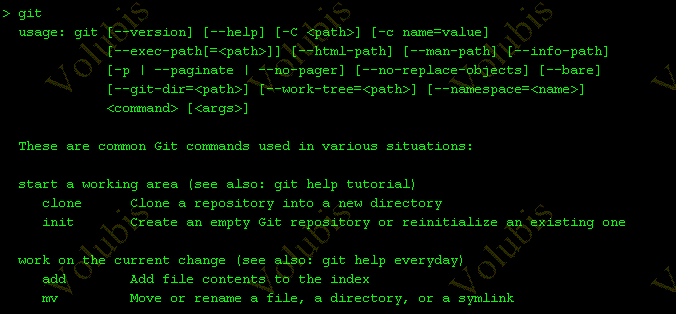
Pour paramétrer git config
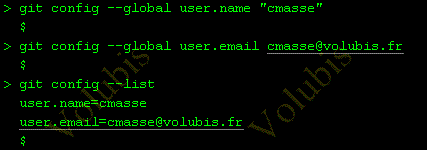
Après avoir créé un fichier README.MD, ajoutons le au repository et commitons
Encore une fois, la doc détaillée est ici : https://progit2.s3.amazonaws.com/fr/2016-03-05-4c838/progit-fr.1062.pdf
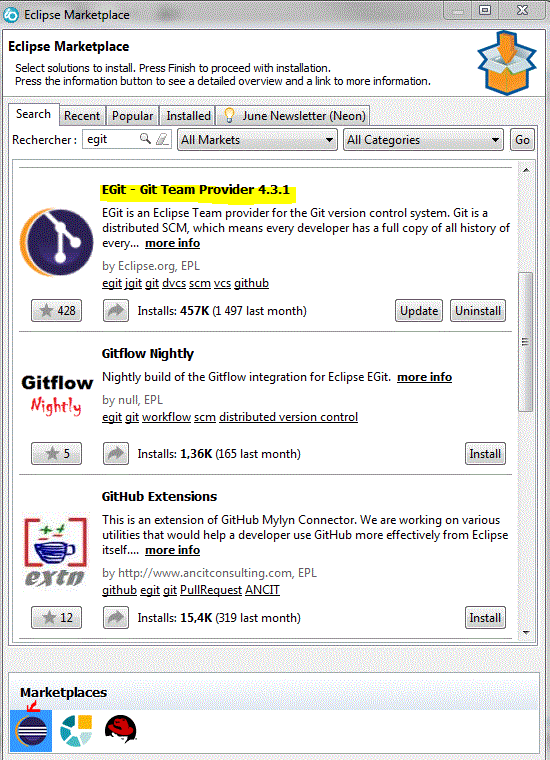
Mais si nous préférerons l'utilisation via Orion ou du PlugIn RDI "EGit"
Pour l'installer Aide/Eclipse MarketPlace
résultat :
Attention, vous devez travailler avec des fichiers locaux (du WorkSpace)
La meilleure solution est alors de créer un projet IBM i
Commençons par créer ou cloner un repository (dépôt) git
•Un clonage depuis un dépôt créé sur IBM i en mode commande (voir ci-dessus)
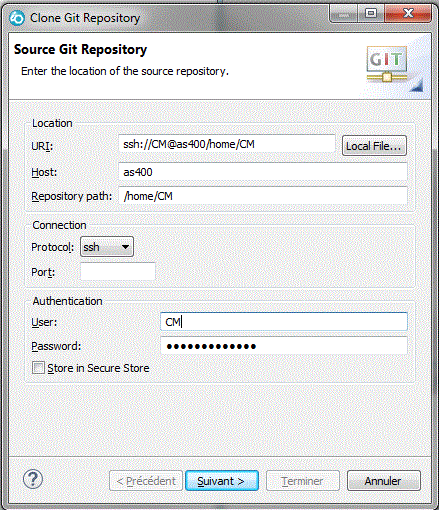
Le seul protocole accepté aujourd'hui est SSH, qu'il faut avoir démarré sur IBM i par STRTCPSVR *SSHD
Le dépôt est alors trouvé
Importons le localement
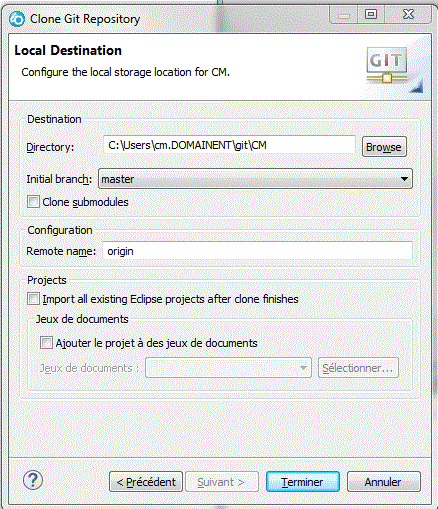
et voilà 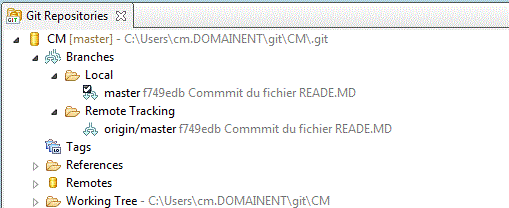
•Un clonage depuis bitbucket.org que nous associerons à un projet IBMi
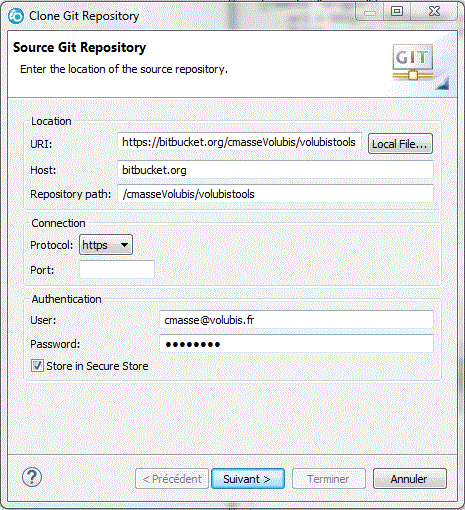
N'oubliez pas d'enregistrer votre user/password, ou bien il vous sera demandé en permanence
Dans ce cas le projet est vide (nous venons de le créer sur bitbucket)
Notez bien l'emplacement que nous avons choisi (dans le workspacede RDI, ce n'est pas par défaut))
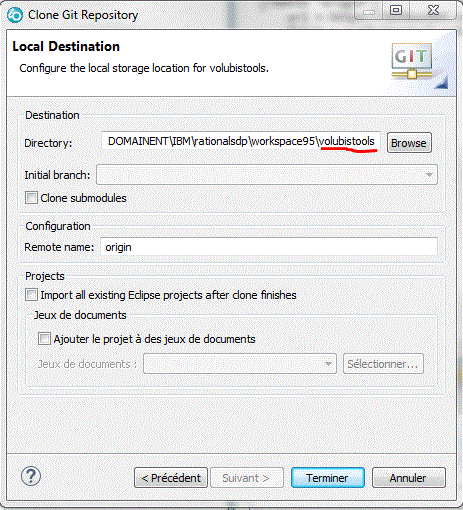
basculez sous la perspective
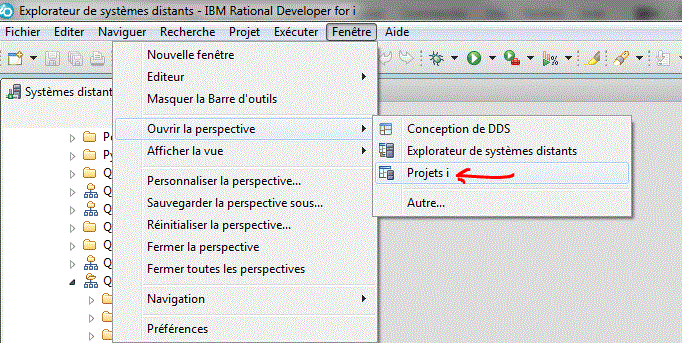
Créez un projet
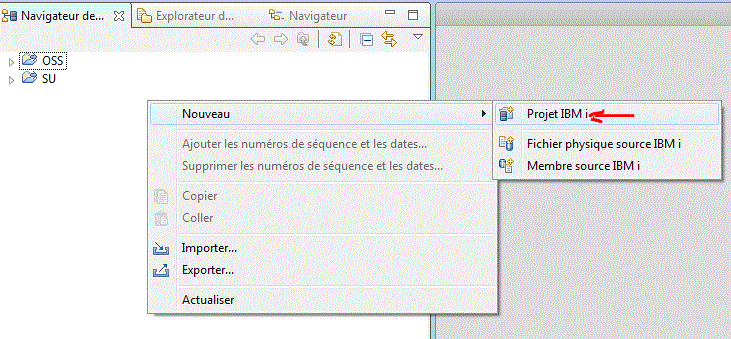
Notez son nom, son emplacement
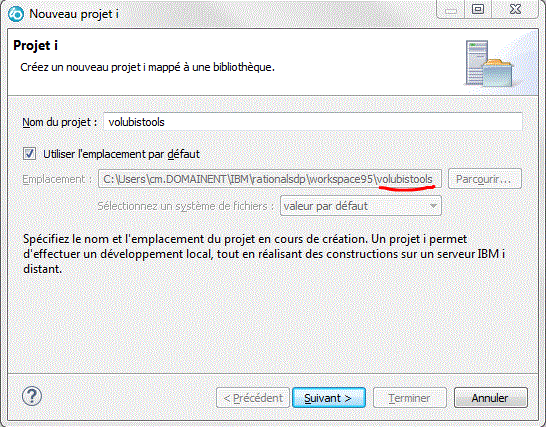
ce projet doit faire référence à
- une connexion
- une bibliothèque sur le serveur
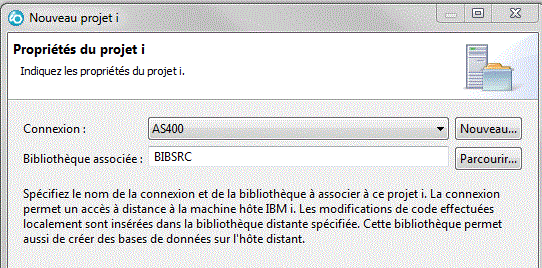
- puis indiquer une méthode de compilation
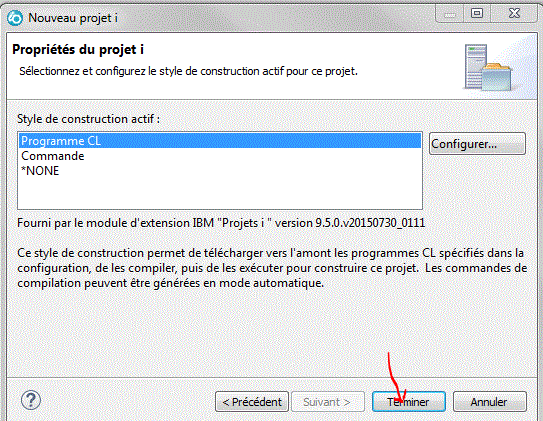
Importez des sources (si vous ne partez pas de rien)
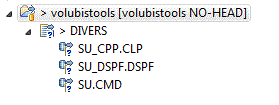
Après avoir indiqué la bibliothèque et choisi quelques membres d'un fichier source (DIVERS)
-> 
Puis, important, activez cette option dans fenêtre/Préférences

Après l'importation, enlevez les n° de ligne (qui feraient "désordre" sur le site)
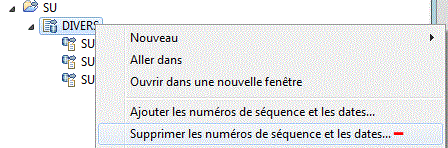
Re-basculons sur la perspective Git
en bas à droite, les nouveaux sources sont reconnus, mais non intégrés au repository

Ajoutons les (git add)
Nous pouvons alors valider (git commit) et les transmettre (git push) sur le serveur.
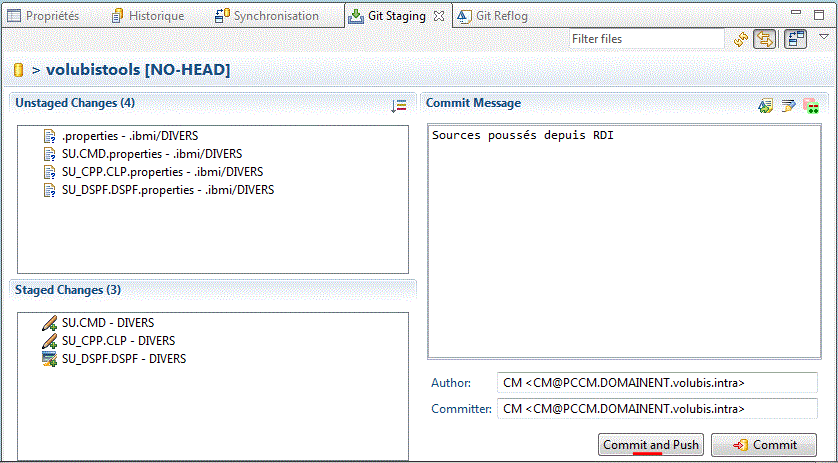
Résultat sur le site de bitbucket.org
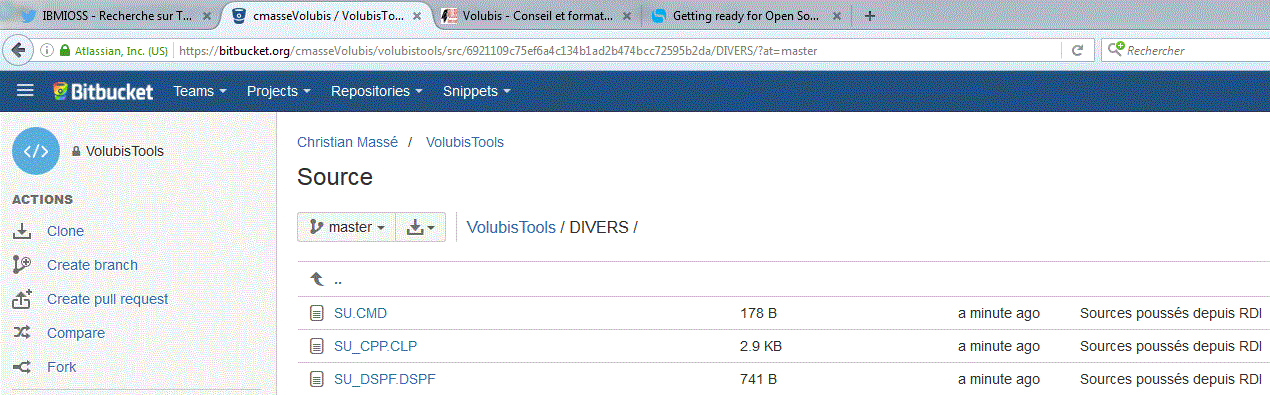
Orion
Amené par 5733OPS option 8 et la PTF
- SI60170
Il s'agit d'un projet Eclipse contenant un éditeur de source (en mode Web) doublé d'un client Git.
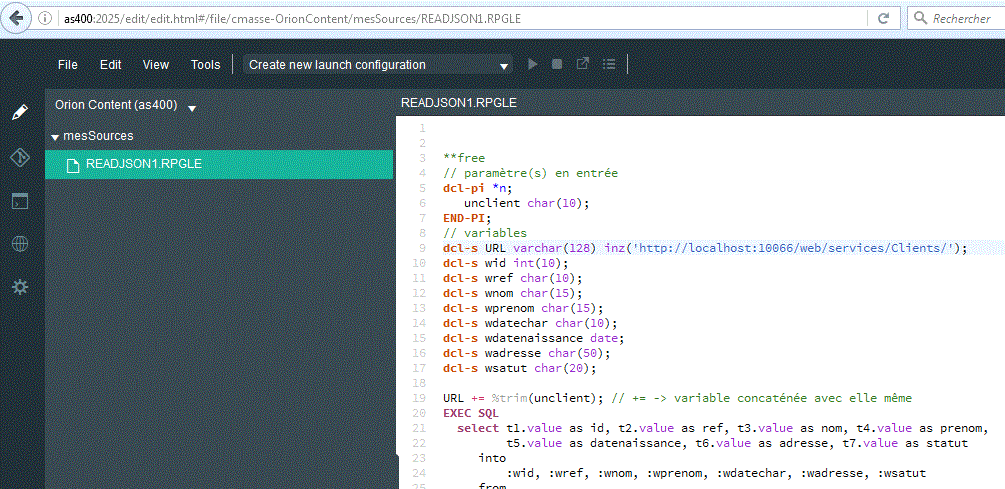
- Pour démarrer le serveur QSH CMD('/QOpenSys/QIBM/ProdData/OPS/Orion/orion')
- Pour l'arrêter QSH CMD('/QOpenSys/QIBM/ProdData/OPS/Orion/StopOrion')
Ce dernier est lancé dans QHTTPSVR et utilise le port 2025 :
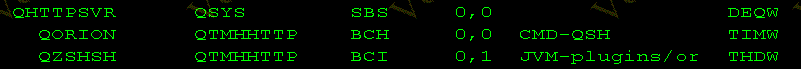
les deux fichiers de config, sont
- /QOpenSys/QIBM/UserData/OPS/Orion/orion.ini
- /QOpenSys/QIBM/UserData/OPS/Orion/orion.conf
A la première utilisation vous verrez
- Try it now permet de s'enregistrer
- Sign In (en haut à droite), permet de s'authentifier ensuite
- Vous pouvez aussi, dans orion.conf
- Créer l'utilisateur admin et lui attribuer un mot de passe, par orion.auth.admin.default.password=unmotdepasse
Arrêtez, redémarrer Orion
Signez vous admin, changez le mot de passe
Enlevez la ligne orion.auth.admin.default.password dans orion.conf, elle ne sert plus.
- Indiquez que seul admin peut créer des utilisateurs, par orion.auth.user.creation=admin
- Voyez cet exemple complet de config https://github.com/fabric8io/fabric8-eclipse-orion/blob/master/orion.conf
- Créer l'utilisateur admin et lui attribuer un mot de passe, par orion.auth.admin.default.password=unmotdepasse
- Vous pouvez ensuite
- Créer un projet
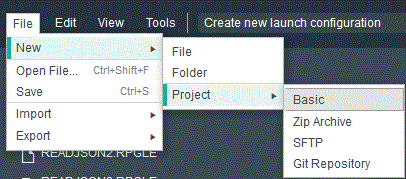
- Basic (Local => dans le workspace)
 (dans notre exemple , mesSources)
(dans notre exemple , mesSources)
Ensuite créez des fichiers dans ce projet (par exemple RPG, qui est un langage reconnu, comme html, js et CSS)
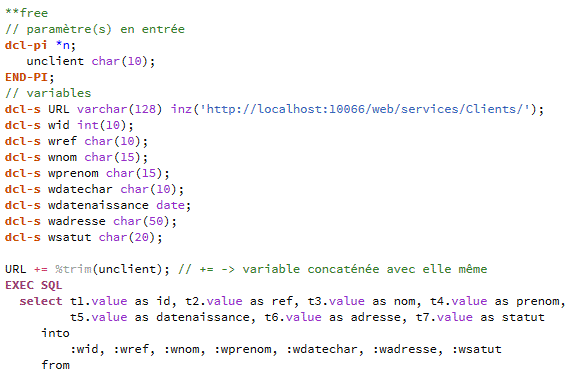
Pour compiler
Attention, ORION insère des tabulations, mal gérées par le compilateur
Demandez à les remplacer par des espaces

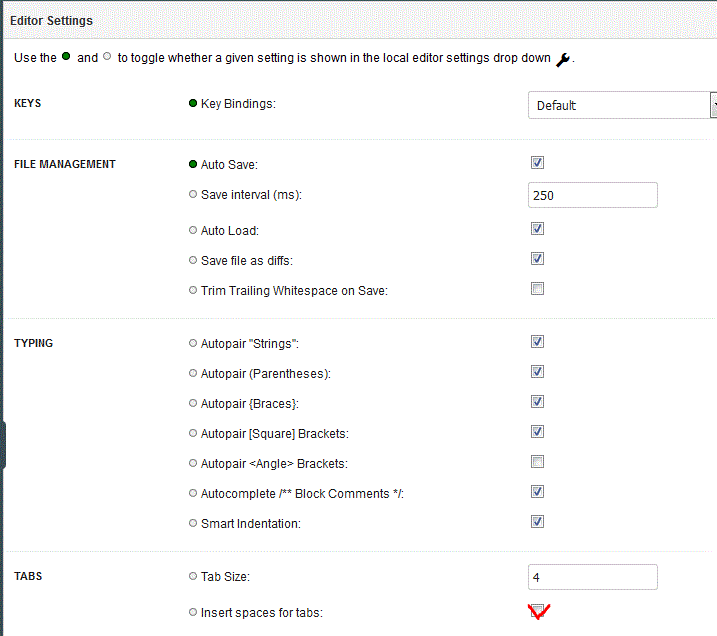
- Local, mais extérieur au Workspace en créant un lien
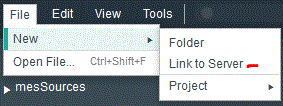
Attention- par défaut, seul /QOpenSys/etc/orion/links est autorisé dans orion.conf (orion.file.allowedPaths)
- N'essayez pas de faire un lien vers une bibliothèque (/QSYS.LIB/xxx.LIB) le produit est sous Pase et ne convertit pas l'EBCDIC
- Après avoir modifié Orion.conf


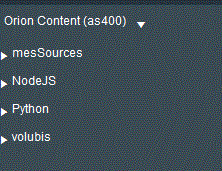
Orion reconnaît aussi (dans une moindre mesure) les langages : Java, Ruby, Node.JS et Phython

- Git (faisant référence à un serveur Git sur le web)

Par exemple, pour nous : https://bitbucket.org/cmasseVolubis/volubis
Voyez la localisation de nos deux projets
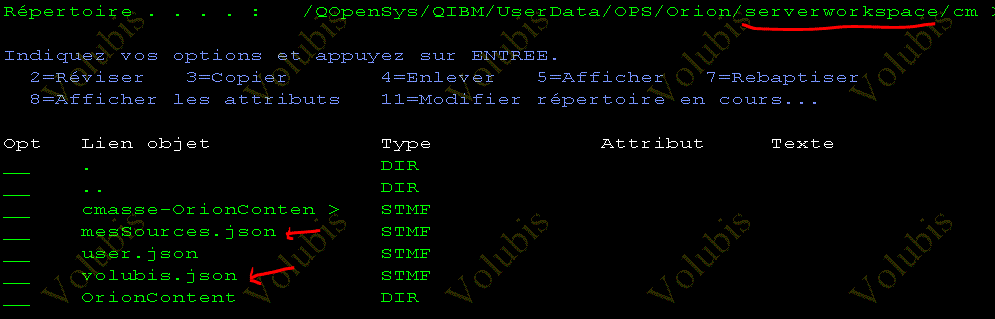
- Sur ce dernier Point, Orion est un très bon client Git
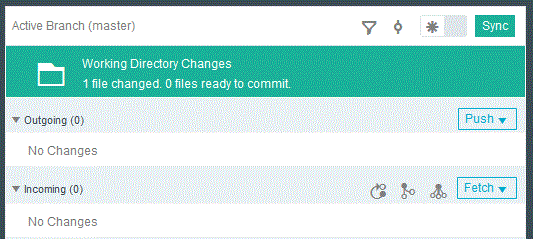
Créons un nouveau fichier README.MD (affiché sur la page de garde du serveur git)

- Basic (Local => dans le workspace)
- Créer un projet
-
Pour infos, le standard pour les fichiers README.MD est :
### niveau d'entête (H1 à H6)** en gras **
* italique *
remarquez la mise en forme, réalisée temps réel ci-dessus. - la validation apparaît dans l'arborescence à gauche
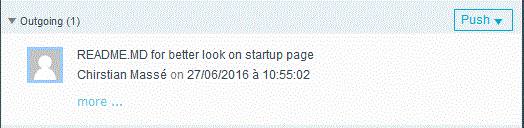
- Pour la pousser (Push), authentifiez vous sur le serveur git

- ET c'est transmis sur le serveur

- De fait , sur le site bitBucket.org
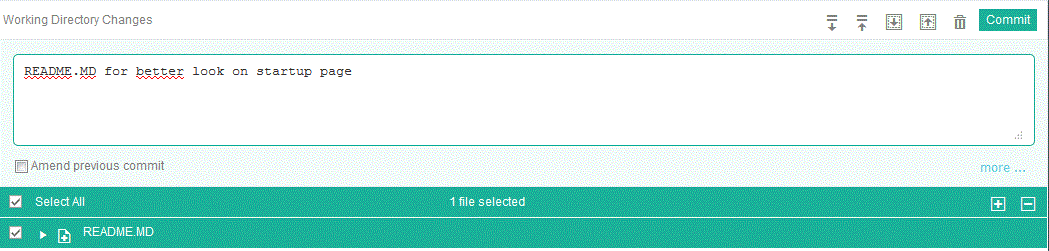
la modification est reconnue, il faut la valider (commit) et associer un texte explicatif à la validation.
Puis indiquer les paramètres de validation (Auteur de la modif.)

Dernier point, le groupe PTF SI99223 (7.2) ou SF99225 (7.3) représente désormais toutes les PTF liées au produit 5733OPS
![]()
IBM i Access Client Solution & scripts SQL
La version 1.1.5 (Décembre 2015) apportait le gestionnaire de scripts SQL
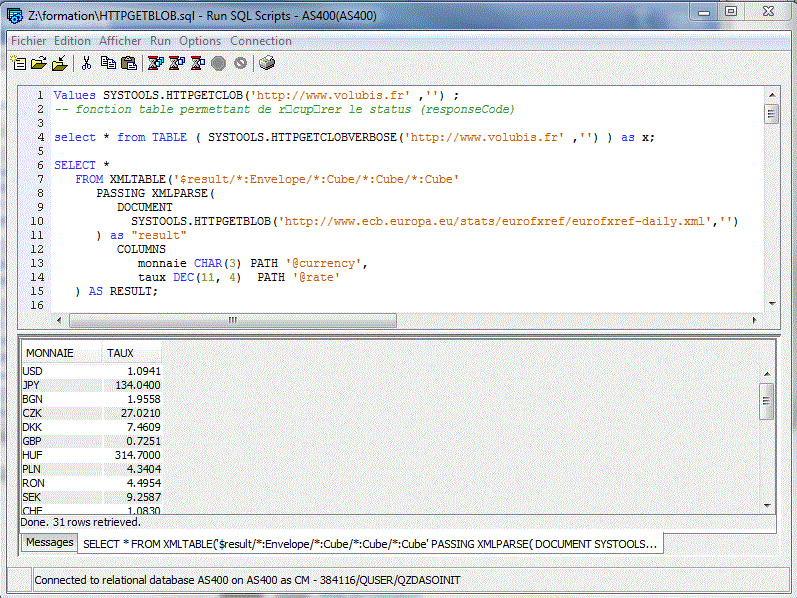
La sauvegarde des résultats est prévue
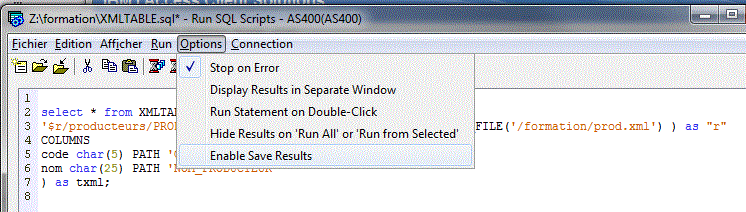
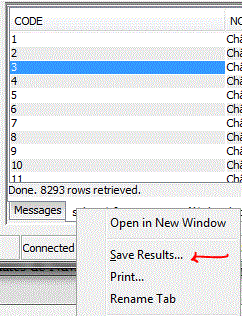
Mais la sauvegarde du script, pour l'instant, ne peux se faire que sur le PC.
(la version Windows propose membre source et IFS)
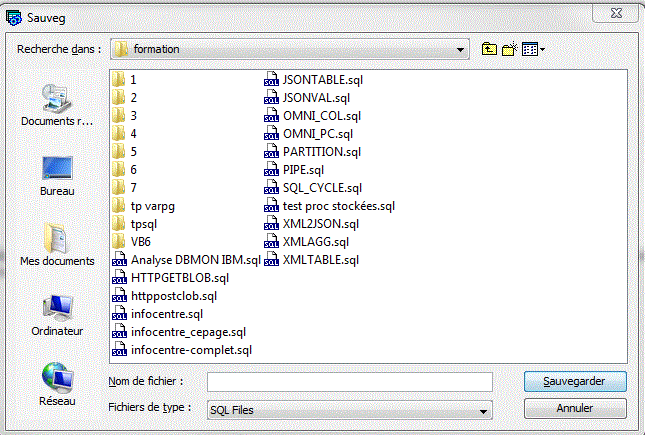
l'option Insert From Exemple, propose de nombreux exemples
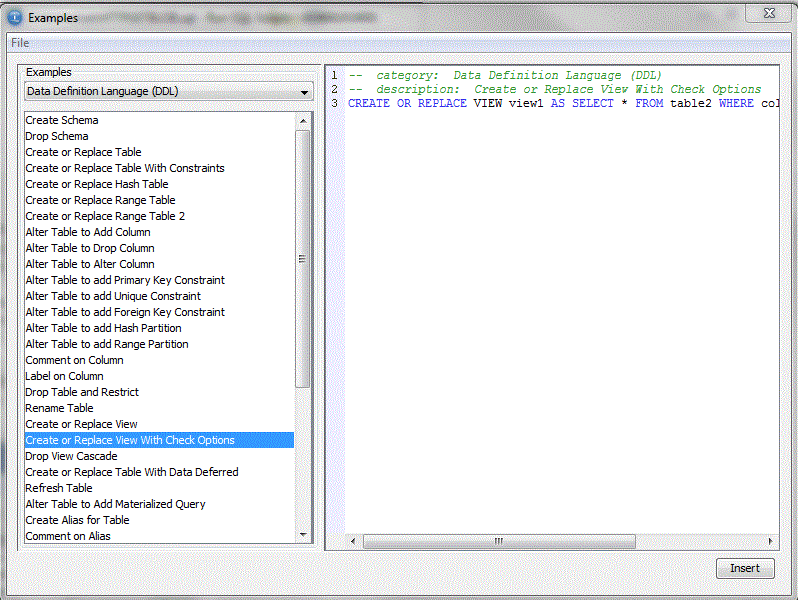
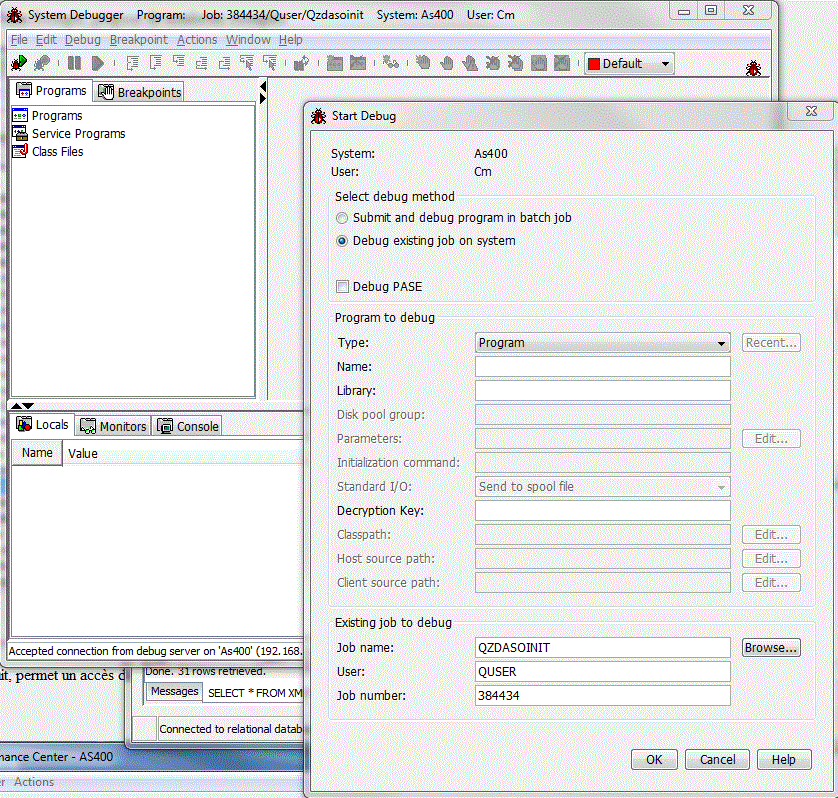
Enfin, ce produit, permet un accès direct au Debugger SQL (Procédures et Fonctions, particulièrement)
Run/System Debugger
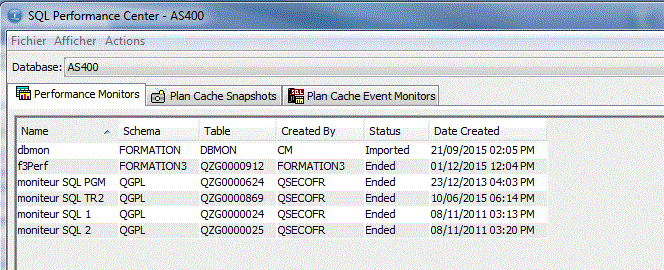
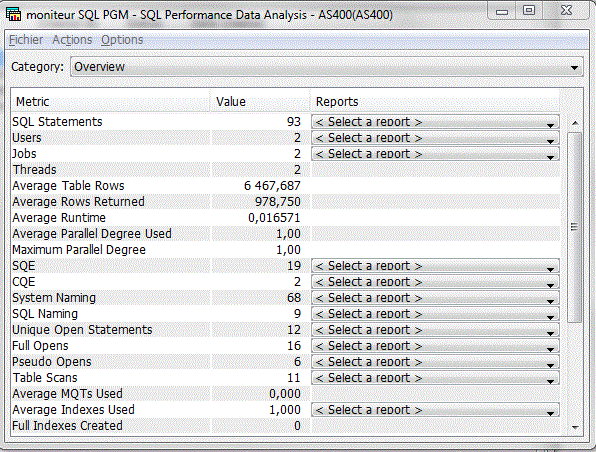
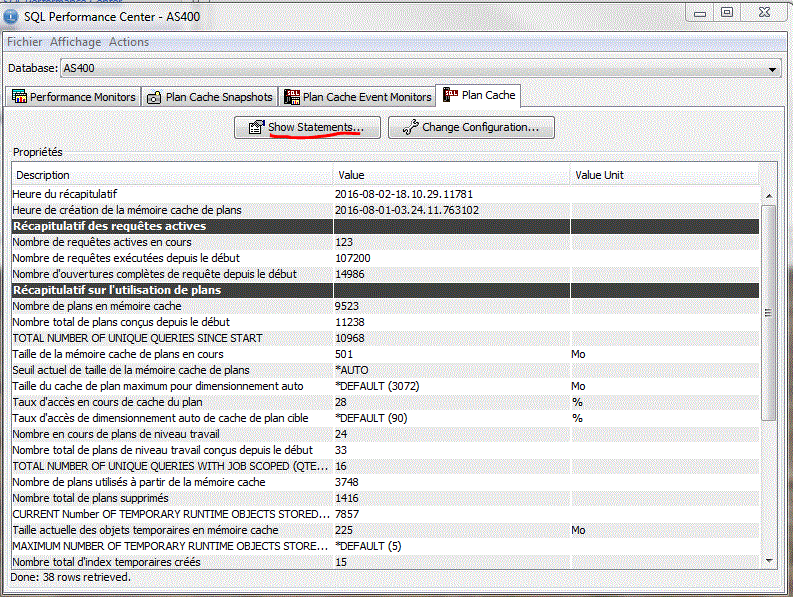
Performance Center, permet un accès aux :
- Moniteur de perf. SQL (STRDBMON)
- Aux images du cache des plans d'accès (pour sauvegader le cache, avant un IPL par exemple)
- Aux moniteurs d'événement (pour une sauvegarde automatique du cache)
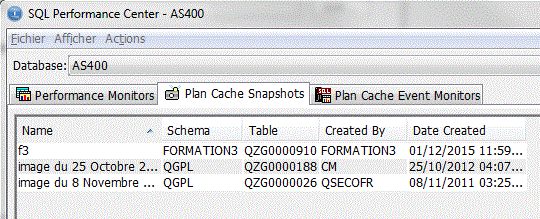
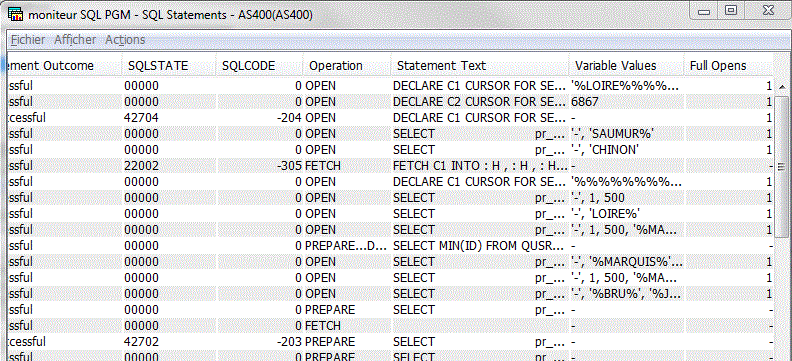
Etudions un moniteur de performances SQL (option Analyse)
Voyons les choix
Rapport global
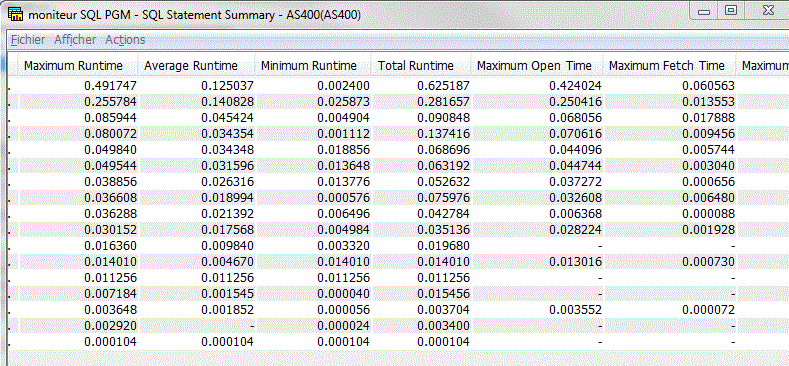
Rapport détaillé
Certaines fonctions utilisent les nouveautés de Navigator for I
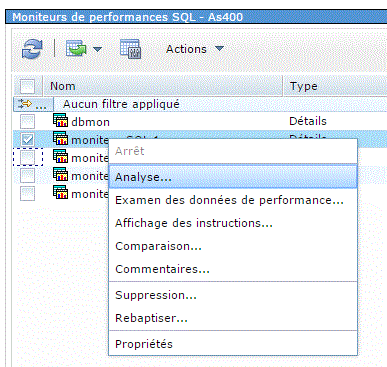
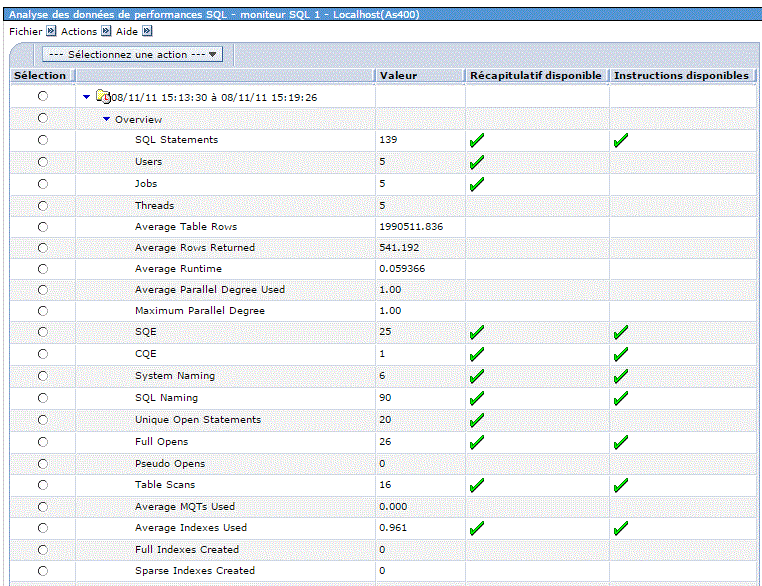
Analyse (Investigate sous ACS)
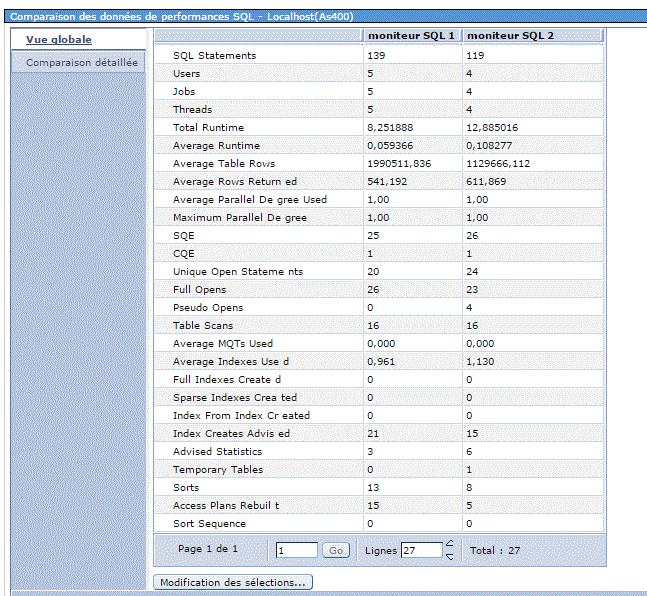
Comparaison (compare sous ACS)
La nouvelle version est la 1.1.6 (Août 2016)
http://www-03.ibm.com/systems/power/software/i/access/solutions.html#updates
Elle continue les évolutions concernant SQL et DB2
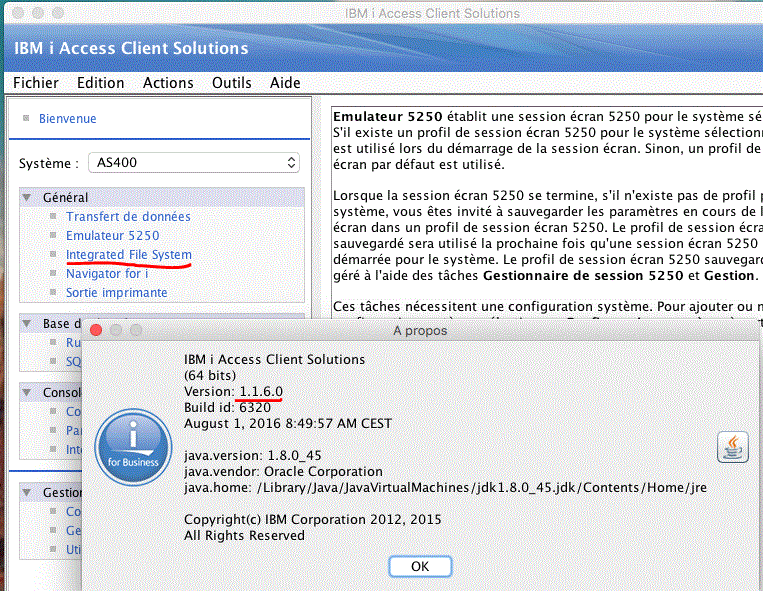
Elle propose aussi une option de gestion des fichiers de l'IFS
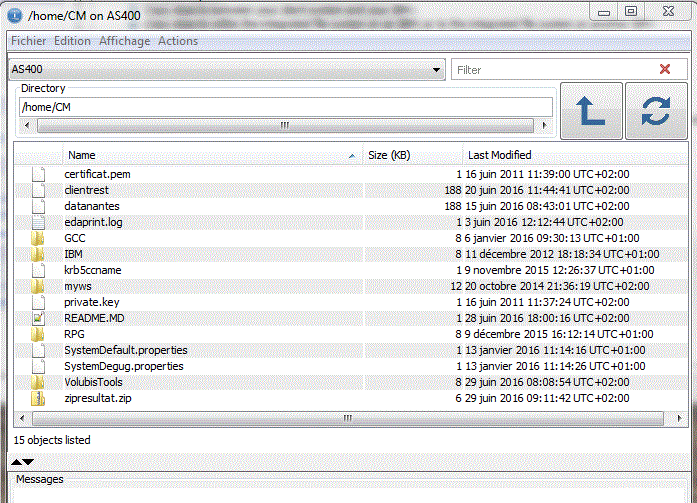
Actions possibles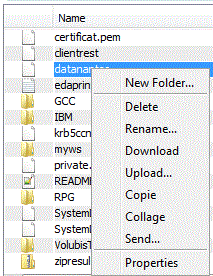
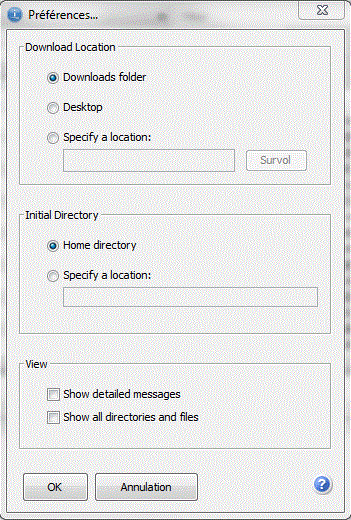
Les préférences permettent de choisir le répertoire de Download
Upload 
Send : envoi sur un autre serveur IBM i

Mais revenons à SQL
le gestionnaire de script pouvait être lancé depuis RDI
C'est désormais aussi le cas depuis une session 5250
Ce dernier propose un formatage de code
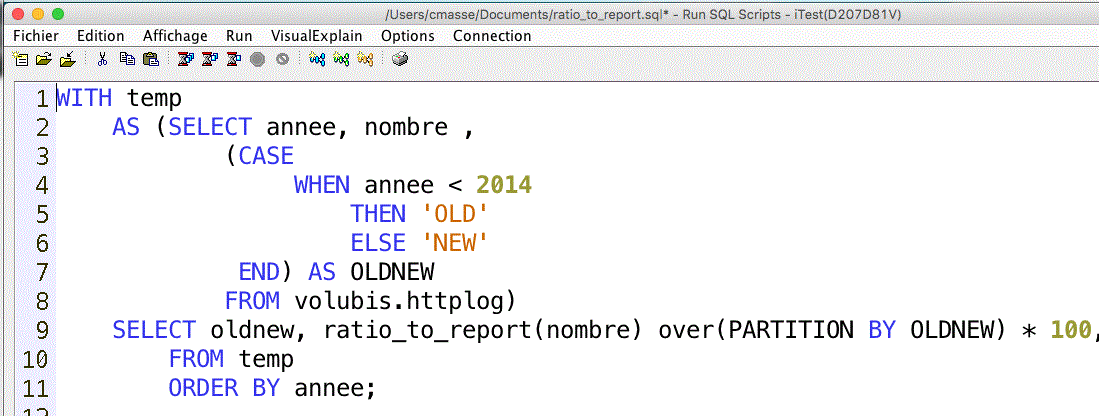
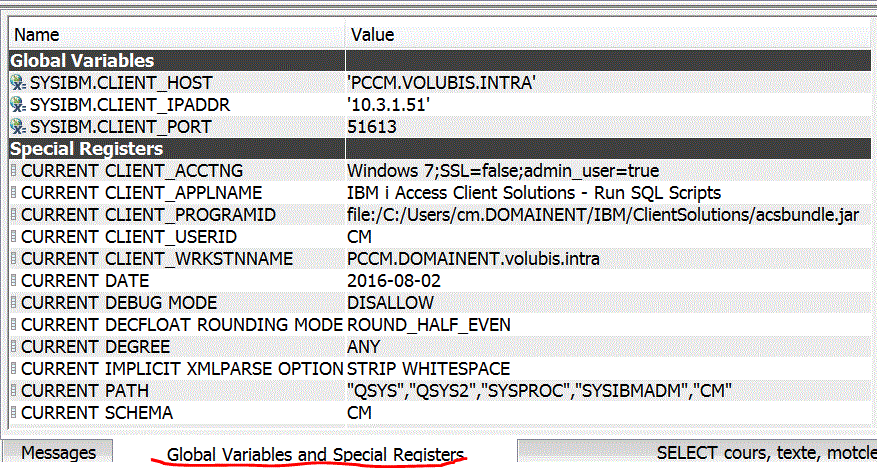
Une fenêtre de visualisation des variables globales et registres spéciaux
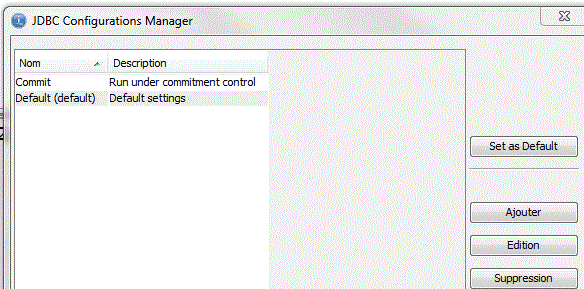
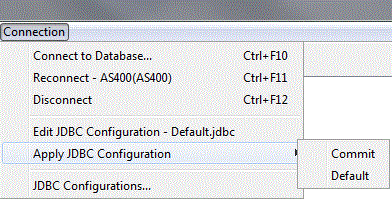
Une mémorisation de plusieurs configurations JDBC en parallèle (Connection/JDBC Configurations...)
Plus d'exemples à insérer, mieux classés (Edition/Insert from Examples)
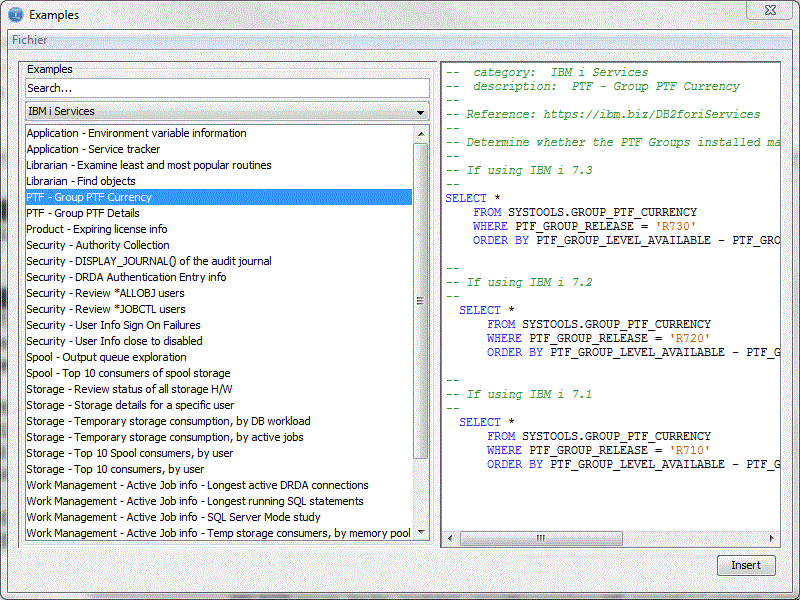
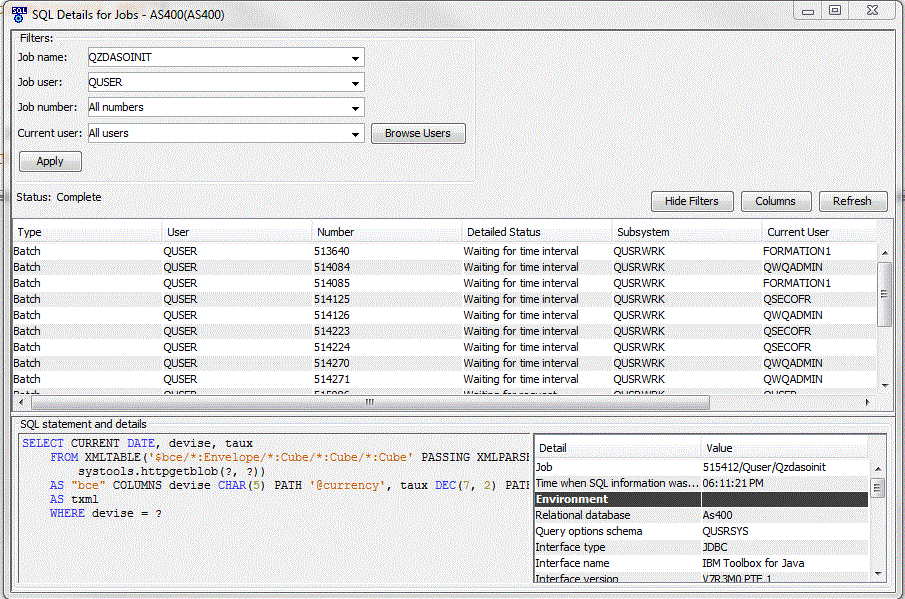
Un accès aux travaux et à la dernière requête SQL pour chacun d'eux (Affichage/SQL details for a Job)
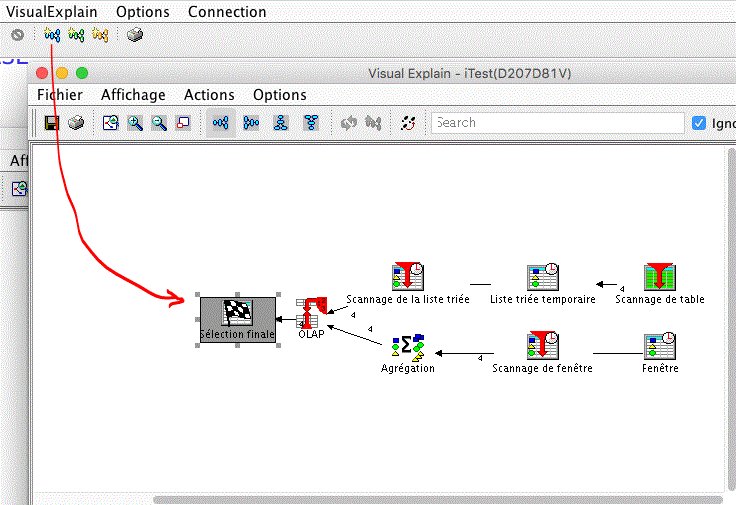
mais surtout nous retrouvons Visual Explain (ici sur une partition 7.3)
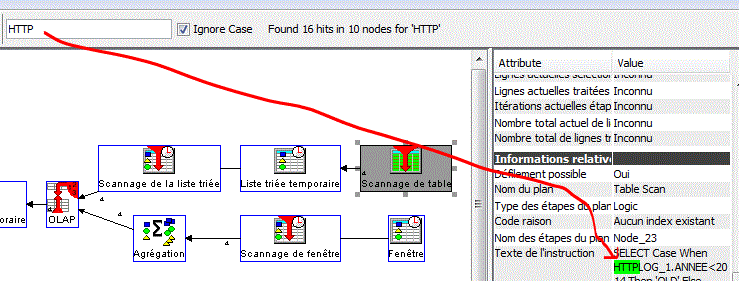
Ce dernier proposant une recherche d'une chaîne de caractères
 SQL Performance Center, propose un quatrième Onglet -> Plan Cache
SQL Performance Center, propose un quatrième Onglet -> Plan Cache
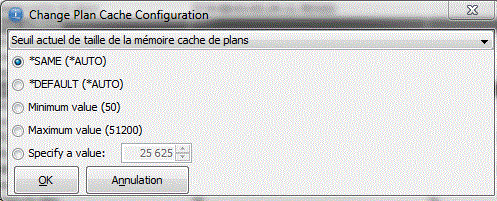
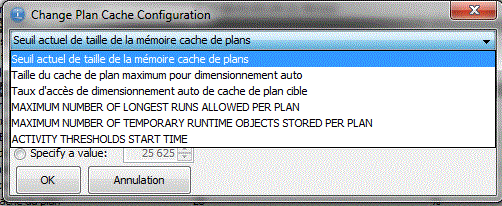
"Change configuration", permet une modification assistée des différents paramètres du cache
"Show Statement", affiche les instructions SQL actuellement dans le cache
1ere étape, choix des critères d'affichage :
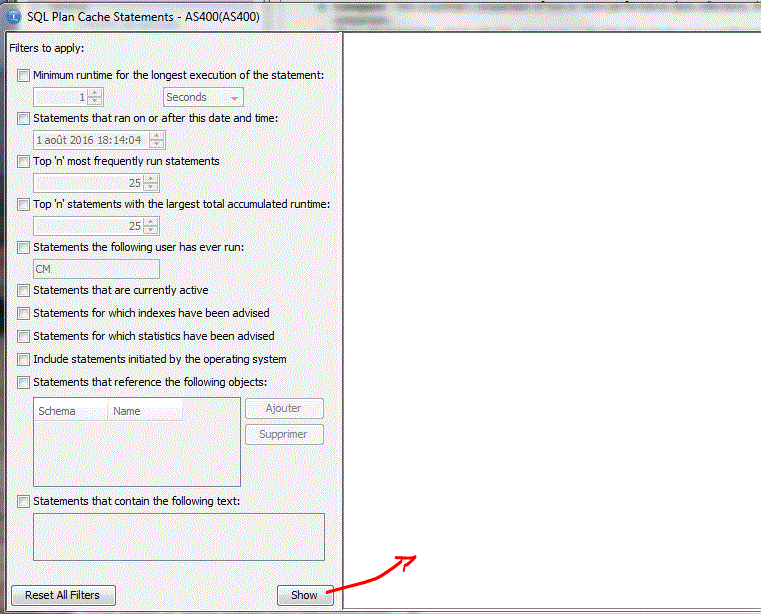
2/ Affichage des instructions :
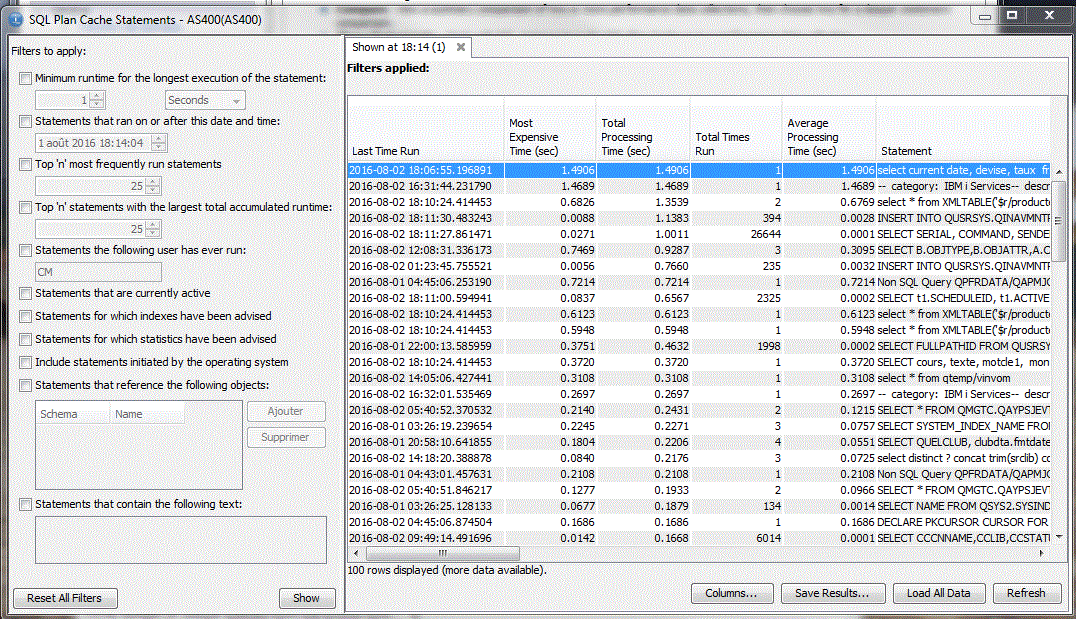
Un nouveau filtre "Top n" est assez sympa (ici les 25 requêtes les plus fréquentes)
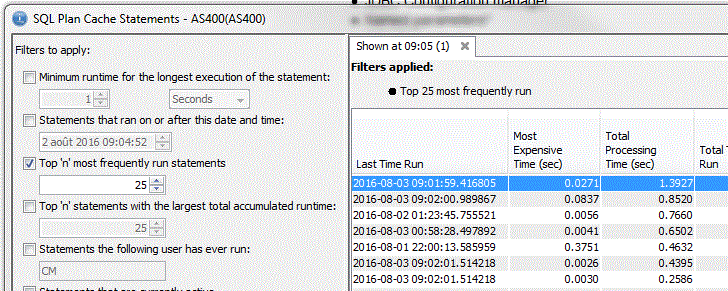
ET vous pouvez voir plusieurs affichages en parallèle
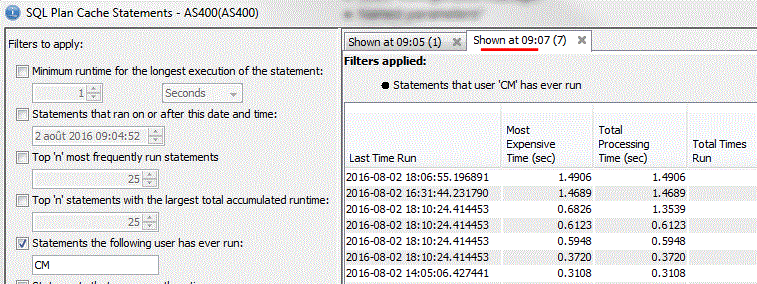
Nous retrouvons l'accès à Visual Explain sur chaque liste d'instructions SQL
- D'un moniteur de performances.
- D'une image instantanée (Snapshot)
- D'une sauvegarde suite à événement (Event Monitor)
- Sur le cache des plans d'accès
Option "show statement", puis clic droit sur l'instruction (ici sur le cache)
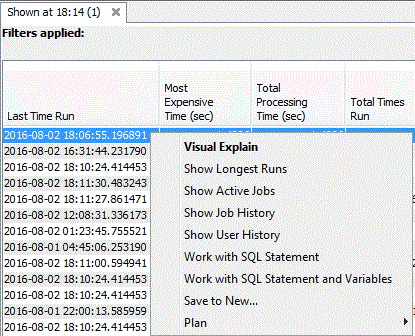
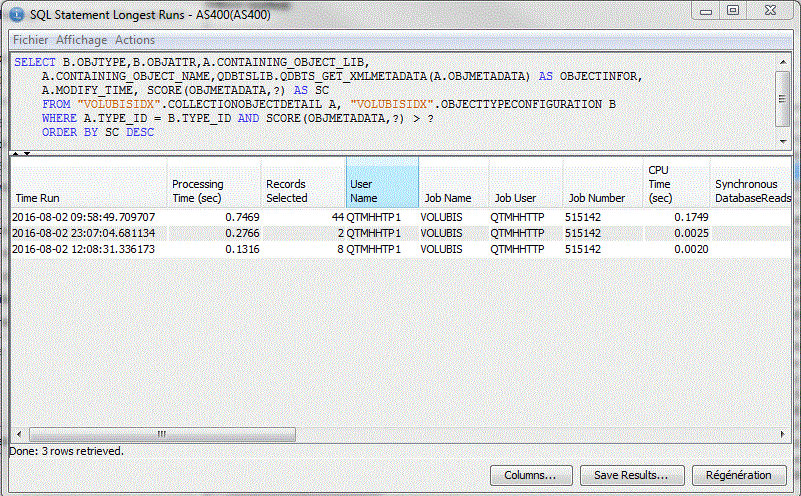
Longuest Run
Job History
User History
Work with SQL Statement, place la requête dans le gestionnaire de scripts.
Prochaine mise à jour prévue en Octobre 2016.
DB2 Web Query version 2.2
Une nouvelle version de DB2 Web query est annoncée en Avril 2016
- Elle ne s'installe que sur une version 7 (à partir de 7.1, pas en version 6)
- Elle est obligatoire pour passer en 7.3, qui ne supporte que cette dernière version
- Voyez les PTF et les produits obligatoires : APAR II14818
Vous pouvez installer la version 2.2 sur une 2.1, la migration se fera automatiquement.
la commande WRKWEBQRY montre la version et de nouvelles informations
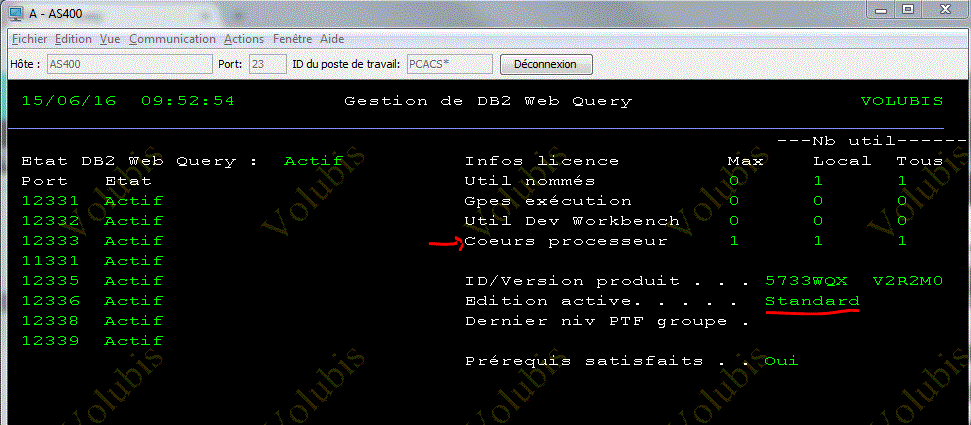
NB: les bibliothèques QWQREPOS et QWQCENT sont désormais classées comme des bibliothèques utilisateur et sont sauvegardées par SAVLIB *ALLUSR
Pour utiliser DB2 Web Query, lancez votre navigateur et saisissez la même URL qu'avant:
http://<votre-as400>:12331/webquery/, notez le nouveau look :
Quelques nouveautés
- Support d'Excel 2007 en format de sortie
- Pour la sortie DB2 (dans une TABLE ou fichier physique), l'option Ajout ou Remplacement est enfin disponible
- Quand vous travailler avec des dates (groupes ou segments) un calendrier vous est proposé pour saisir une date
- Enfin, une nouvelle option permet de faire des "super groupes" pour regrouper des valeurs de groupes existants
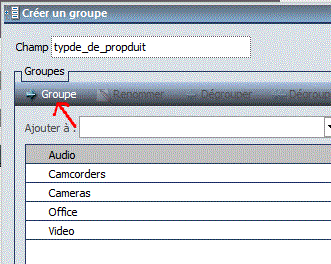
- Faites un clic droit sur un groupe
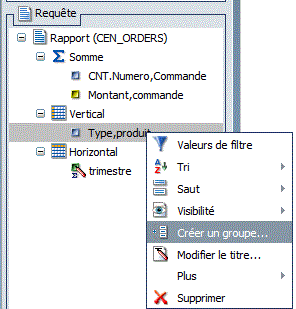
- cette fenêtre est affichée
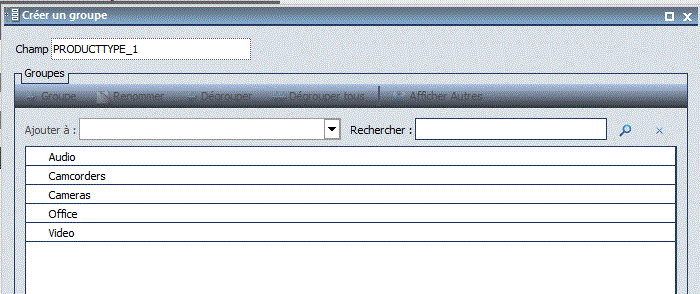
- Créez un groupe
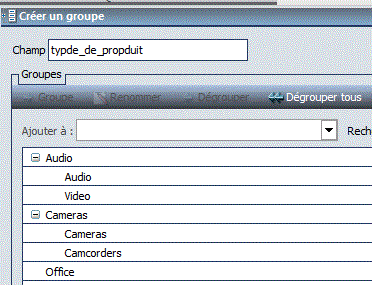
- Rassemblez plusieurs valeurs
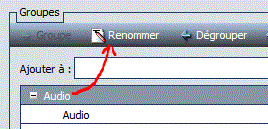
- Renommez le groupe (qui par défaut se nomme comme la première valeur)
- voilà
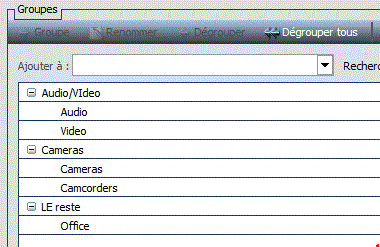
- Résultat dans le rapport
- Faites un clic droit sur un groupe
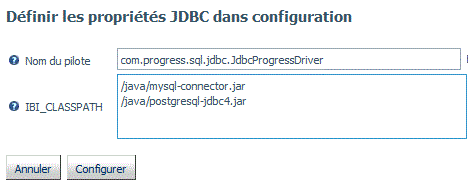
Une des belles améliorations est due à la possibilité de se connecter à des bases externes (MYSQL, PostgreSql ou autre via un driver JDBC)
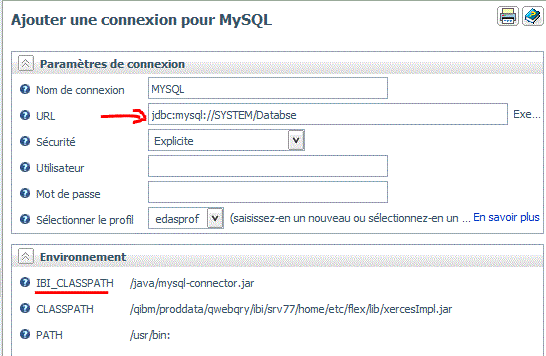
Pour renseigner la CLASSPATH , choisissez propriétés
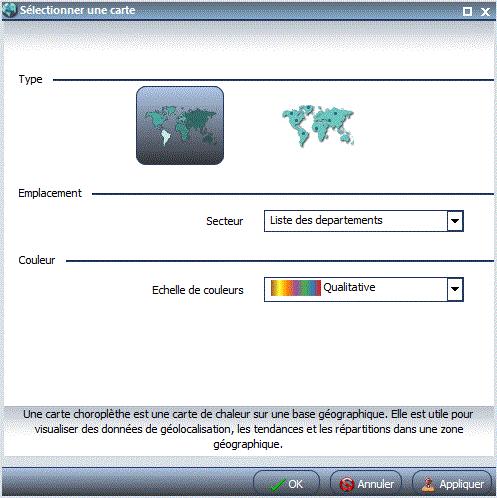
Enfin, les versions 2.1 et 2.2, savent travailler avec des cartes :
Pour cela, vous devez commencer comme pour un graphique
Indiquez, de suite le format de sortie HTML5

- L'icône "Carte" apparaît, choisissez la.
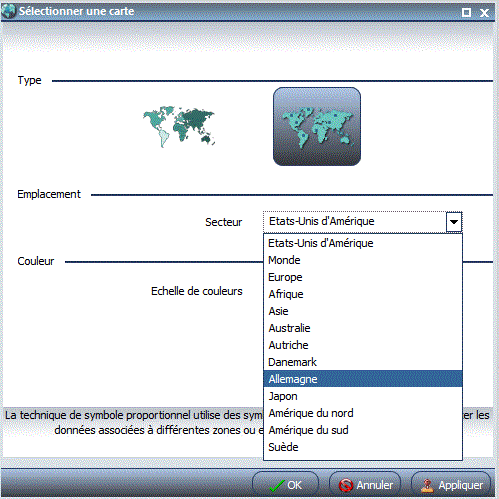
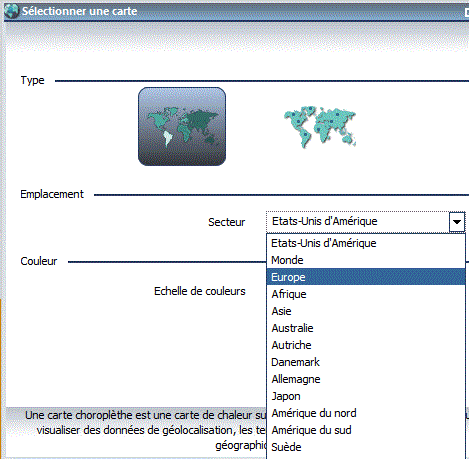
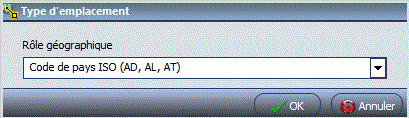
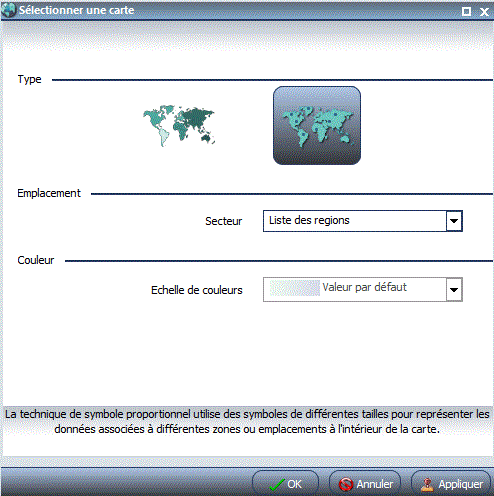
Indiquez le type de carte
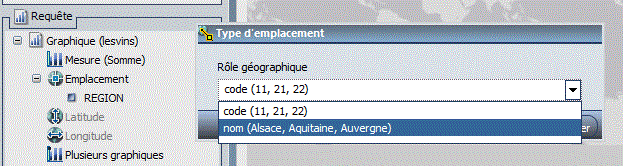
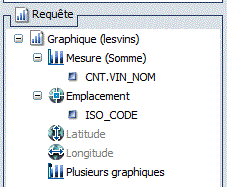
Indiquez la zone géographique
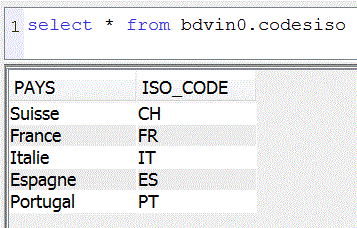
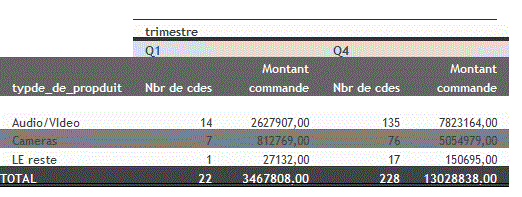
Exemple sur notre base vinicole (nbr de vins par Pays)
Nous avions les noms de pays en clair et en Français.
nous avons donc créé une table et fait la jointure dans une vue
Informations géographiques
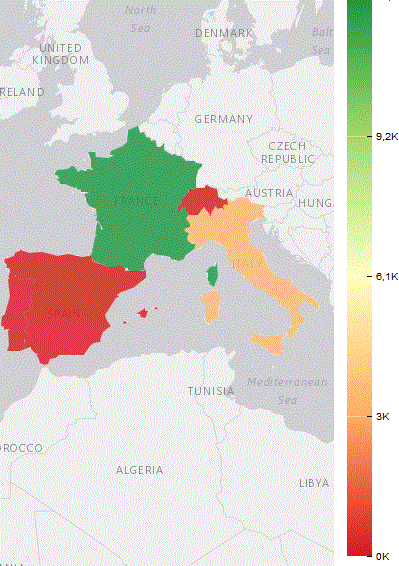
Résultat avec le type Choroplèthe
Avec le type Symbole proportionnel
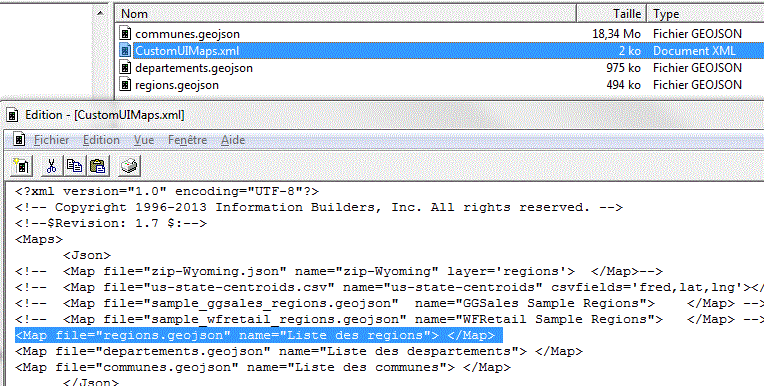
Vous pouvez ajouter vos propres cartes au format GeoJson.Nous en avons trouvé sur le site https://github.com/gregoiredavid/france-geojson
Chargez les fichiers GeoJson dans /QIBM/UserData/qwebqry/base80/config/web_resource/mappuis Editez le fichier CustomUIMap.xml
et ajoutez une ligne par fichier geojson
<Map file="fichier.geojson" name="Titre du fichier"> </Map>
Exemples
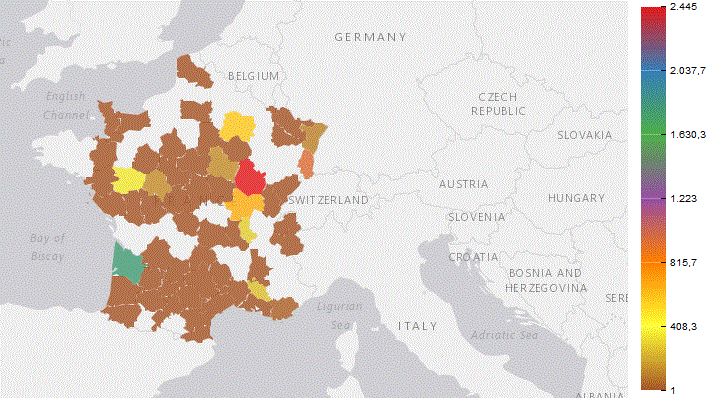
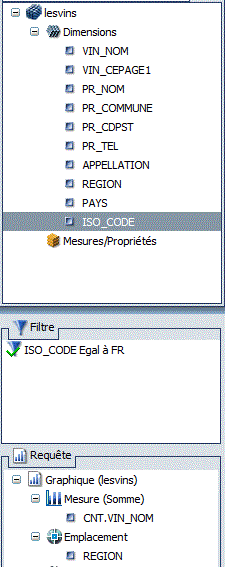
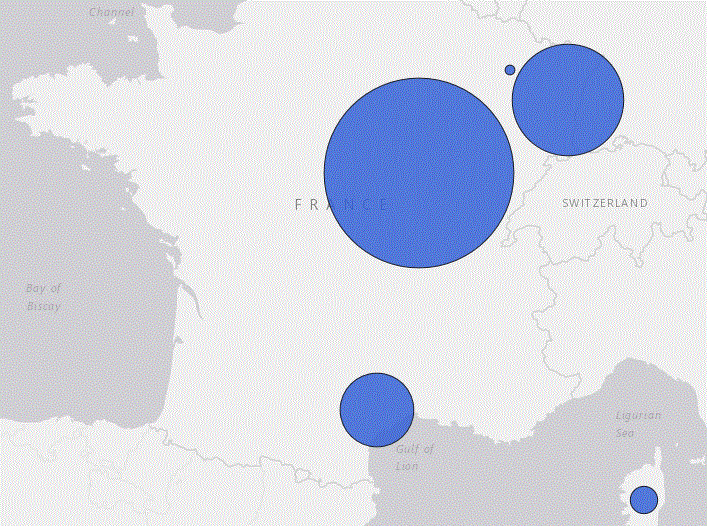
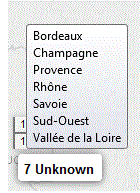
• avec les régions Françaises
Nous avons ici
- le nbr de vins par Régions
- un filtre pour sélecter uniquement
les producteurs Français
Résultat
Les Régions vinicoles ne coïncident pas parfaitement avec les régions administratives, nous avons 7 manquants
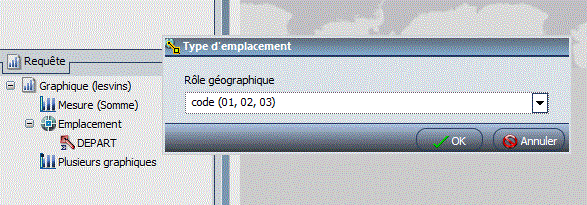
• par Départements
DEPART est un substring sur les deux premiers caractères de Code Postal
Résultat