
pause-café
destinée aux informaticiens sur plateforme IBM i.
Pause-café #79
UNICODE.
Unicode ?
A l'origine, sur nos machines, était le CCSID.
Avec un jeu de caractères donné (Latin-1, cyrillique, hébreu par ex.) définition d'une grille de codification de tous les caractères pour un pays donné :
Nous avons le même jeu de caractères que les espagnols, nous n'avons pas le même code page (codification).
Le CCSID est la codification du jeu de caractères et du code page d'origine d'une donnée."Cette données est Française ! " (CCSID au niveau zone, venant du CCSID du fichier, lui même venant du job de création)
si le CCSID du job (qui lit le fichier) est différent (il vient de la langue de l'utilisateur, sinon de QCCSID), il faut modifier la valeur héxa afin que le "é" Français s'affiche é pour l'utilisateur Espagnol ou Danois et non "{" (par exemple).
La codification UNICODE est une codification sur plusieurs octets permettant dans une même grille, de coder tous les caractères du monde
(y compris chinois, bengali, braille, symboles mathématiques et notes de musique !)
Définition
Le standard Unicode est constitué d'un répertoire de plus de 110 000 caractères couvrant 100 écritures, d'un ensemble de tableaux de codes pour référence visuelle (braille), d'une méthode de codage et de plusieurs codages de caractères standard, d'une énumération des propriétés de caractère (lettres majuscules, minuscules, symboles, ponctuation, etc.) d'un ensemble de fichiers de référence des données informatiques, et d'un certain nombre d'éléments liés, tels que des règles de normalisation, de décomposition, de tri, de rendu et d'ordre d'affichage bidirectionnel (pour l'affichage correct de texte contenant à la fois des caractères d'écritures droite à gauche, comme l'arabe et l'hébreu, et de gauche à droite).En pratique, Unicode reprend intégralement la norme ISO/CEI 10646, puisque cette dernière ne normalise que les caractères individuels en leur assignant un nom et un numéro normatif (appelé point de code) et une description informative très limitée.
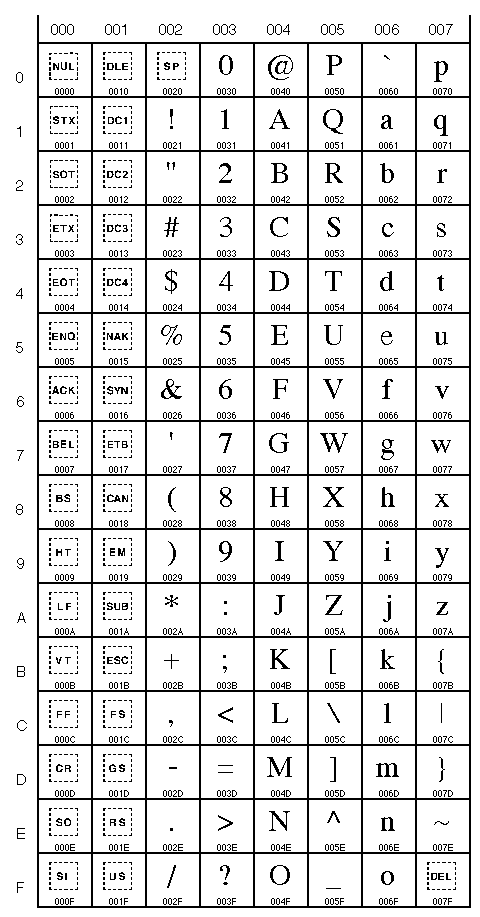
Voici une toute petite partie des tables UNICODE (les nombres sont présentés en notation hexadécimal):
Caractères Unicode
0000 à 007F (0 à 127)
(caractères latins)Caractères Unicode
0080 à 00FF (128 à 255)
(caractères latins, dont accentués)Caractères Unicode
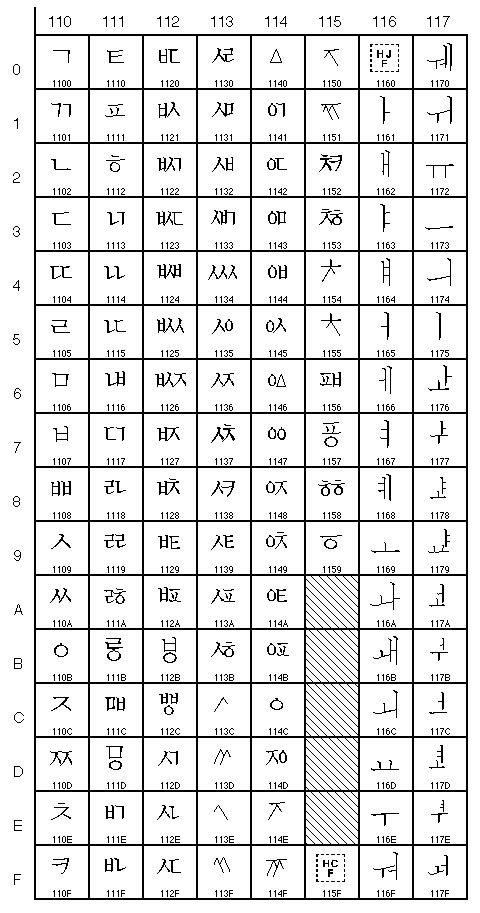
0900 à 097F (2304 à 2431)
(caractères devanagari/sanskrit)Caractères Unicode
1100 à 117F (4352 à 4479)
(caractères hangul jamo/coréen)Vous pourrez trouver plus d'informations sur l'UNICODE sur http://www.unicode.org.
Dans la table des caractères Unicode on ajoute un index numérique associé à chaque caractère. Notons bien qu’il ne s’agit pas d’une représentation en mémoire, juste d’un nombre entier, appelé point de code. L'espace de codage de ces nombres est divisé en 17 zones de 65 536 points de codes. Ces zones sont appelées plans.
Le point de code est noté U+xxxx où xxxx est en hexadécimal, et comporte 4 à 6 chiffres :
- 4 chiffres pour le premier plan, appelé plan multilingue de base (donc entre U+0000 et U+FFFF);
- 5 chiffres pour les 15 plans suivants (entre U+10000 et U+FFFFF);
- 6 chiffres pour le dernier plan (entre U+100000 et U+10FFFF).
Ainsi, le caractère nommé « Lettre majuscule latine c cédille » a un index de U+00C7.
Il appartient au premier plan.
En principe toutes les positions de code entre U+0000 et U+10FFFF sont disponibles, mais certains intervalles sont perpétuellement réservés à des usages particuliers, notamment une zone d'indirection exclue pour permettre le codage UTF-16 (cf. ci-dessous), les zones à usage privé et quelques régions (par exemple U+FFFE ou U+FFFF) contenant des non-caractères dont l'usage est interdit dans un échange de données conforme. Les autres positions de code sont soit déjà assignées à des caractères, soit réservées pour normalisation future.
Unicode v6 a 7 catégories de caractères:
- Letter (L) Mark (M)
- Number (N) Punctuation (P)
- Symbol (S) Separator (Z)
- Other (C): caractères de contrôle , etc…
UTF-8
Techniquement, il s’agit de coder les caractères Unicode sous forme de séquences de un à quatre codets d’un octet chacun. La norme Unicode définit entre autres un ensemble (ou répertoire) de caractères. Chaque caractère est repéré dans cet ensemble par un index entier aussi appelé « point de code ». Par exemple le caractère « € » (euro) est le 8365e caractère du répertoire Unicode, son index, ou point de code, est donc 8364 (on commence à compter à partir de 0).
Le répertoire Unicode peut contenir plus d’un million de caractères, ce qui est bien trop grand pour être codé par un seul octet (limité à des valeurs entre 0 et 255). La norme Unicode définit donc des méthodes standardisées pour coder et stocker cet index sous forme de séquence d’octets : UTF-8 est l'une d’entre elles, avec UTF-16, UTF-32 et leurs différentes variantes.
La principale caractéristique d’UTF-8 est qu’elle est rétro-compatible avec la norme ASCII, c’est-à-dire que tout caractère ASCII se code en UTF-8 sous forme d’un unique octet, identique au code ASCII. Par exemple « A » (A majuscule) a pour code ASCII 65 et se code en UTF-8 par l'octet 65. Chaque caractère dont le point de code est supérieur à 127 (caractère non ASCII) se code sur 2 à 4 octets. Le caractère « € » (euro) se code par exemple sur 3 octets : 226, 130, et 172.
UTF-16
L’UTF-16 est un bon compromis lorsque la place mémoire n’est pas trop restreinte, car la grande majorité des caractères Unicode assignés pour les écritures des langues modernes (dont les caractères les plus fréquemment utilisés) le sont dans le plan multilingue de base et peuvent donc être représentés sur 16 bits.
Codage UTF-16hi \ lo
DC00
DC01
…
DFFF
D800
10000
10001
…
103FF
D801
10400
10401
…
107FF
:
/
/
...
/
DBFF
10FC00
10FC01
…
10FFFF
Les points de code des seize plans supplémentaires nécessitent une transformation sur deux mots de 16 bits :
- on soustrait 0x10000 au point de code, ce qui laisse un nombre de 20 bits dans l'étendue 0..0xFFFFF
- les 10 bits de poids fort (un nombre entre 0 et 0x3FF) sont additionnés à 0xD800, et donnent la première unité de code dans la demi-zone haute (0xD800..0xDBFF)
- les 10 bits de poids faible (un nombre entre 0 et 0x3FF) sont additionnés à 0xDC00, et donnent la seconde unité de code dans la demi-zone basse (0xDC00..0xDFFF)
En résumé, il y a 2 plages réservées :Haute : X'D800' – X'DBFF' = 4 * 256 combinaisonsBasse : X'DC00' – X'DFFF' = 4 * 256 combinaisonssoit 1024 * 1024 caractères supplémentaires
codage sur 2 octets pour les 63488 premiers caractères (comme UCS-2 ci-dessous)codage sur 4 octets pour les autres caractères (subrogate characters)
UCS-2 est la version simplifiée de UTF-16 ne prévoyant pas les indirections et ne permet donc que de stocker des caractères appartenant au premier plan. (arrivée avant UTF-16, c'est un peu obsolète aujourd’hui)
• UTF-16 intège le sens de lecture droite->gauche/gauche->droite, pas UCS2
• UTF-16 intègre une normalisaiton (un nommage) de chaque caractère, pas UCS2
• UCS2 peut être transformé en UTF-16, le contraire n'est pas forcément vrai
• voir ici les plans supplémentaires d'UTF-16, non implémentés par UCS2
UTF-32L’UTF-32 est utilisé lorsque la place mémoire n’est pas un problème et que l’on a besoin d’avoir accès à des caractères de manière directe et sans changement de taille (hiéroglyphes par ex.).
Sur IBM i , les différentes versions Unicode sont représentées par un code page
UCS-2 -> CCSID(13488)
UTF-8 -> CCSID(1208)
UTF-16 -> CCSID(1200)
UTF-32 -> (non implémentée)Il faut parallèlement avoir installé la bibliothèque ICU (option 39 du système)
Voir https://www-01.ibm.com/software/globalization/ccsid/ccsid_registered.html
Avec UCS-2 et UTF-16, une zone base de données de 20 caractères = 40 Octets
Avec UTF-8 une zone 20 caractères = 20 Octets, donc potentiellement trop courte, pour les caractères accentués
à réserver au VARCHAR, CLOB et fichiers IFS.A UCS2 10G CCSID(13488)
A* Lg de stockage = 20 octets
A UTF16 10G CCSID(1200)
A* Lg de stockage = 20 octets
A UTF8 10A CCSID(1208)
A* Lg de stockage = 10 octets
Soit une base de données (vinicole) en EBCDIC

DSPFFD

Une version UTF-8

DSPFFD identique

ET une version UTF-16

DSPFFD

La taille des champs NCHAR (ou GRAPHIC) est doublée

Pour alimenter la version UTF-16, nous ne rencontrons pas de problèmes

Puis

Par contre pour la version UTF-8, nous rencontrons le message SQL0404, pour cause de caractère accentué qui prend 2 octets.
Nous sommes obligés d'écrire :
Bref, mieux vaut utiliser UCS-2 ou UTF-16 dans la base de données.
Quelques questions existentielles




- DDS
ET si je dois faire un test?
Testez le(s) caractère(s) de votre choix, la constante sera passée en unicode afin d'être comparée correctement à la variable
ET si je dois faire un SST

pensez "position du caractère" (ici le 3eme) jamais en octet...

- SQL
- ET pour les vues SQL

les constantes seront, là aussi, transformées en UNICODE (expressions et/ou tests), la fonction SPACE(n) produit n caractères ' ' en Unicode, etc...
Notez que concaténer de l'UCS2 (13488) et de l'UTF-16 (1200) produit de l'UTF-16


- FTP
- les transferts de fichiers se font suivant le type de transfert demandé :
- ASCII ou TYPE A (dft)
fichiers texte, transformé du CCSID de DB2 vers ASCII international (819) sauf paramétrage particulier dans CHGFTPA
- EBCDIC ou TYPE B (rare)
Transfert en BBCDIC
- Bin ou TYPE I (binaire)
pas de conversion lors du transfert
- ASCII ou TYPE A (dft)
- les transferts de fichiers se font suivant le type de transfert demandé :
Affichage et impression
RDI sait partiellement traiter l'Unicode
- pas de problèmes, dans la perspective base de données
- LPEX reconnait les fichiers sources en Unicode
- LPEX reconnait le type RPG UCS2 et la fonction %UCS2()
- le debugger affiche une zone Unicode avec de l'alphabet occidental, mais pas les autres alphabets

ACS, sait afficher de l'UNICODE
les DSPF connaissent les CCSID 13488 et 1200, par le biais du mot-clé CCSID
CCSID
- un CCSID UNICODE
- 1200 ou 13488
- *REFC quand vous faites référence
- Taille
- une taille d'affichage.
- *LEN ou non précisé : le double de la taille de stockage
- *MIN : la taille de la zone (pratique si c'est majoritairement de l'alphabet occidental)
Soit un fichier Base de données avec des zones GRAPHIC CCSID(13488)
CREATE TABLE AF4TEST.UNITEST13 (
CODECLI INTEGER NOT NULL ,
RAISOC GRAPHIC(80) CCSID 13488 DEFAULT NULL ,
VILLE GRAPHIC(50) CCSID 13488 DEFAULT NULL ,
DEPCLI DECIMAL(2, 0) DEFAULT NULL )
RCDFMT UNITEST ;
Le DSPF est construit en faisant Référence
Le programme de test fait un simple affichage
si vos fichier sont codés avec CCSID(1200) la conversion 1200 -> 13488 se fera souvent sans problèmes, les caractères étant largement communs.
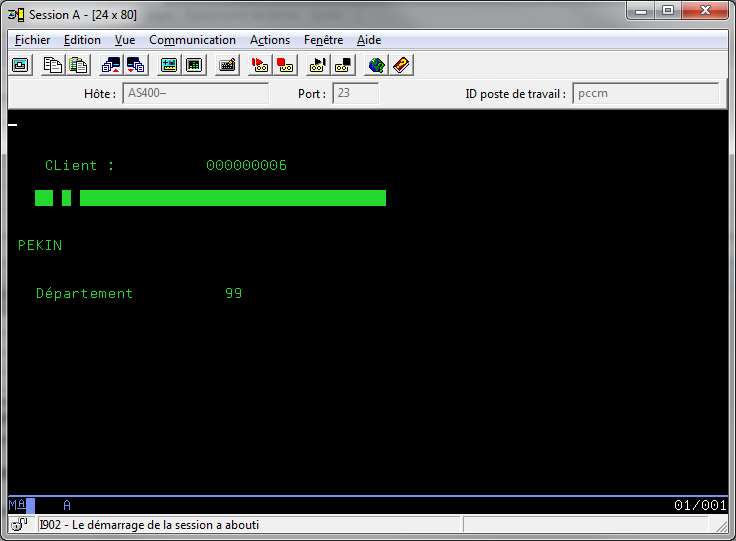
Sur une session 5250 de Client Access :
Il fallait avant utiliser l'émulateur de Web Access (Client Access for the Web) qui est un émulateur 5250 compatible Unicode.
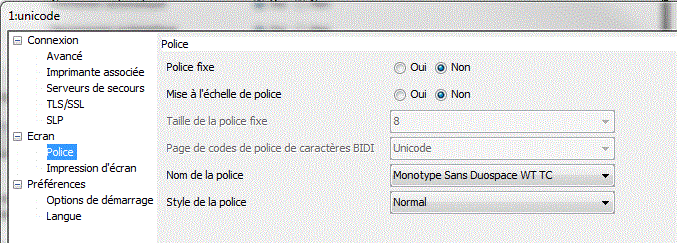
Avec L'émulateur de IBM i Access Client Solution :
- il vous faudra les options suivantes
Lors de la définition de la session 5250 HOD
il faut activer le support d'Unicode.
et utilisez la police adéquat
Pour afficher du Chinois (Police WT SansDuo TW ou WT SerifDuo TW en 7.2)
S'il le faut téléchargez les polices dans /QIBM/ProdData/OS400/Fonts/TTFonts (option 43 de SS1)
Malgrès cela, même sur une session configurée pour Unicode, vous oubliez DFU et QUERY...
Pour imprimer de l'UNICODE, voyez ce PRTF :
Rappel : la police 'Monotype Sans Duospace WT SC' est apportée par l'installation de l'option 43
Il faut ensuite le compiler avec DEVTYPE(*AFPDS)
ici visualisation du résultat avec AFP Workbench Viewer.
Pour l'impression utilisez une Imprimante Réseau AVEC MFRTYPMDL(*HPDBCS), voyez :
- un scan de l'impression
- le résultat de la commande CPYSPLF TOSMTF(*STMF) TOSTMF(unitesti.pdf) WSCST(*PDF)
Exportation
Exportez par CPYTOSTMF ou CPYTOIMPF
SI le CCSID d'origine est connu laissez *FILE dans FROMCCSID, sinon (65535) forcez un CCSID.Indiquez 1200 dans TOCCSID (*PCASCII aurait transformé tout le texte en ANSI de Windows, cela ne serait plus de l'Unicode)
Résultat

Pour voir le fichier, faites un partage Windows et utilisez Word (par exemple)
- Commencez par activer cette option
- Menu Option
- Confirmer la conversion de format lors de l'ouverture
- Ouvrez le fichier csv
- Lors de l'ouverture vous verrez
- Indiquez ensuite "Autre codage" -> Unicode (Big-Endian)

L'unicode par défaut est Litte-Endian (LE), chaque caractère se lit de droite à gauche
(non implémenté sur IBM i)
- Et voilà



















Importation (depuis Excel, par exemple)
- sauvegardez votre document, sur un répertoire partagé, au format texte unicode

cela génère de l'Unicode LE (Litte Endian, non reconnu par IBM i)
- Demandez à Notepad de le convertir en Unicode Big Endian ou UTF-8 (au choix)

Malheureusement NetServer a sauvegardé ce document en 1252 (Ansi), la notion de CCSID n'étant pas implémentée par Windows

- Modifiez le CCSID en 1208, si vous avez sauvegardé en UTF-8 sous Notepad, 1200 si vous avez sauvegardé en Unicode Big Endian

- Importez par CPYFRMIMPF (vers une table avec des champs GRAPHIC ou NCHAR)

Et voilà 
Langage de contrôle (CL) et commandes système
CPYF
- fonctionne, CRTFILE(*YES) créé un fichier à l'identique (zones Unicode)
- la commande de copie fonctionne avec des CCSID différents, si FMTOPT(*MAP)
- d'EBCDIC vers Unicode sans problème
- de Unicode vers EBCDIC quand l'alphabet est compatible
- le paramètre INCREL (permettant de ne copier que les champs répondant à un test) ne supporte pas Unicode
OPNQRYF
- si vous faites des tests, vos données sont transformées en UNICODE pour pouvoir être comparées (sauf CCSID à 65535)
OPNQRYF FILE((AF4TEST/JAPONAIS)) QRYSLT('code *EQ "ABC"')
- la commande CPYFRMQRYF fonctionne, mais TOFILE(*PRINT) ne produit pas un résultat lisible
De manière générale,
la documentation indique que le CL admet l'Unicode depuis la 7.3. (bien partiellement à notre avis)
https://www.ibm.com/support/knowledgecenter/en/ssw_ibm_i_73/rbam6/rbam6unicode.htm
En effet :
- Les variables CL ne peuvent pas être en Unicode, seules les constantes sont admises
- Et encore, voyez ci-dessous les limites de RDI avec un QCLSRC en UTF-8, qui le seul codage Unicode admis pour les sources
- Et encore, voyez ci-dessous les limites de RDI avec un QCLSRC en UTF-8, qui le seul codage Unicode admis pour les sources
- Les paramètres des commandes peuvent être en Unicode (peu nombreuses, mais vous pouvez en créer))
PARM KWD(&MOTCLE) TYPE(*CHAR) LEN(200) CCSID(*UTF16) PROMPT('Paramètre en UNICODE')
Si vous saisissez une valeur EBCDIC elle sera transformée et envoyée en UNICODE
- Si vous avez besoin, vous trouverez ici un exemple d'utilisation de l'Api iconv pour convertir, en CL, de l'EBCDIC en UNICODE
- QCMD ne sait pas traiter de l'UNICODE
- QCMDEXC non plus, utilisez QCAPCMD (voyez un exemple en CL)
- La ligne de commande de RDI est "Unicode compatible"

- Sinon, il faut passer par un source CL (compilé ou lancé par SBMDBJOB)
- QCLSRC peut-être déclaré en UTF-8 (Vous ne pourrez plus utiliser SEU)

Vos données serons transformées en EBCDIC pour les commandes ayant CCSID(*JOB)
en UTF-16 pour celles ayant CCSID(*UTF16)
- par exemple, MKDIR admet de l'Unicode (ici sous RDI)

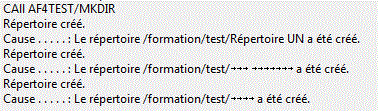
A ce jour RDI contient un bug (sauvegarde mal les données UTF-8), ce qui génère des noms illisibles

- Si vous avez des soucis avec des noms "exotiques", l'API QP0FTPOS permet de "Dumper" les noms d'un répertoire
http://www-01.ibm.com/support/docview.wss?crawler=1&uid=nas8N1019639
- QCLSRC peut-être déclaré en UTF-8 (Vous ne pourrez plus utiliser SEU)
- Nous nous y sommes donc pris autrement :
- Saisie du source via notepad dans l'IFS

- Copie dans QCLSRC (version UTF-8)

- Lancement par SBMDBJOB
SBMDBJOB FILE(AF4TEST/QCLSRCUTF8)
MBR(MKDIRCL)
Résultat

Sous ACS ( Système de fichier intégré)
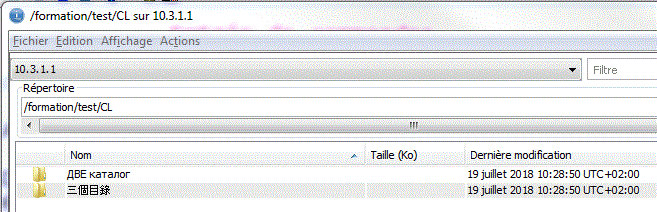
- Nous avons aussi installé les langues Russe et Chinoise sur un Windows et demandé la création d'un répertoire
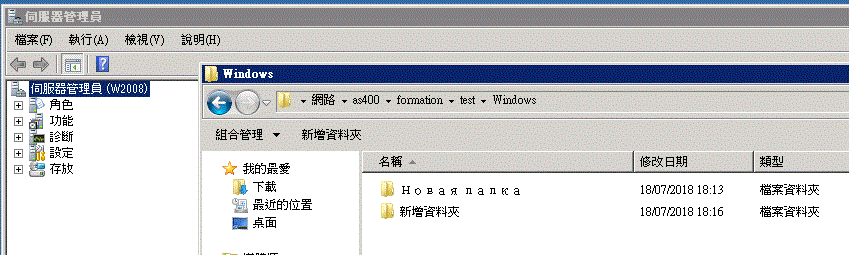
Là aussi, ACS sait l'afficher

Ainsi que Navigator for i

- Saisie du source via notepad dans l'IFS
Traitement en RPG
- RPG reconnait les champs Graphic
DCL-S nom-variable type mots-clés ;-
Type remarque équivalent D paramètres BINDEC binaire "décimal" B Bindec(lg [:décimales]) CHAR alphanumérique A Char(lg) DATE date D Date(format [séparateur]) FLOAT notation scientifique F Float(lg) GRAPH DBCS (codification IBM) G Graph(lg) IND Indicateur N INT Binaire (compatible C et API) I Int(lg) OBJECT pour Java (JNI) O Object(*JAVA : classe) PACKED numérique packé P Packed(lg [:décimales]) POINTER pointeur * [*PROC] TIME heure T Time(format [:séparateur]) TIMESTAMP horodatage Z UCS2 <- Unicode C UCS2(lg) UNS binaire non signé U Uns(lg) VARCHAR Alphanumérique à taille variable A + VARYING Varchar(lg) VARGRAPH DBCS à taille variable G + VARYING Vargraph(lg) VARUCS2 <- Unicode à taille variable C + VARYING Varucs2(lg) ZONED Numérique étendu S Zoned(lg[:décimales])
-
- %CHAR transforme l'Unicode en EBCDIC, quand c'est possible => même encodage (même jeu de caractères)
- %UCS2 fait le contraire (toujours possible)
Exemple, lecture d'un champ XML en RPG, puis recherche d'une chaîne
*(rappel, par défaut les champs XML sont en UNICODE)
* récupération du XML dans une variable du langage
*=================================================
D MON_XML S SQLTYPE(XML_DBCLOB:2500)
D pos S 5i 0
/free
exec sql
select info into :mon_xml from posample/customer
where cid = 1000;
eval pos = %scan(%ucs2('phone') :mon_xml_data);
*inlr = *on;
/end-free
SyntaxeEVAL isLess = ufield < %UCS2(ufield2:13488)
Le second paramètre précise le CCSID à produire, par défaut celui indiqué par CCSID(*UCS2) en spécif H ou ctl-opt
- Puis, des efforts ont été fait sur la gestion du CCSID en 7.2
- Bien sur, toute cette gestion des CCSID ne pourra avoir lieu, que si votre CCSID est connu, donc pas de CCSID à 65535 !
- CCSID au niveau spécif H, précise le code page par défaut
- AVEC CCSID(*EXACT) c'est le CCSID de compilation qui est utilisé, sinon celui du job à l'exécution
- Une conversion implicite est réalisée dans de nombreux cas :
• par exemple, si une donnée déclarée UTF-8 était comparée à *BLANKS, c'était le blanc EBCDIC -> X'40, ce n'est plus le cas.
• par exemple, lors des concaténations, une convertion implicite sera réalisée si le CCSID des variables est connu.
- AVEC CCSID(*EXACT) c'est le CCSID de compilation qui est utilisé, sinon celui du job à l'exécution
- Avant le CCSID par défaut était celui du JOB, quand une donnée avait un CCSID différent, elle était convertie dans celui du JOB
(Uniquement pour un même système de codification, par exemple EBCDIC Français -> EBCDIC Espagnol = jeux de caractère identique : Latin-1)
Démonstration avec un fichier un code page Espagnol (284) - Sous ce CCSID é = x'51' et ñ = x'6A'
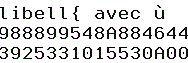 <- DSPPFM
<- DSPPFM
- En Français (297) é = x'C0' et ñ = x'49'
lecture du fichier par pgm

En debug

Résultat
 '
'
- maintenant (7.2) avec le mot-clé CCSID, une variable peut avoir une codification spécifique :
- Bien sur, toute cette gestion des CCSID ne pourra avoir lieu, que si votre CCSID est connu, donc pas de CCSID à 65535 !
- CCSID(*UTF8) , donnée unicode
- CCSID(819) , données ASCII standard
- CCSID(37), EBCDIC Américain (rappel : 297 pour la France)
- CCSID(*HEX), pas de gestion du CCSID pour cette zone
- L'adaptation des constantes au CCSID de la variable est automatique en 7.2, plus besoin des fonctions %UCS2()

X'62' en ASCII = 'b' , en Unicode X'0062', ...
- Les fonctions %Date, %Dec ne transforment pas directement de l'UNICODE, mais en passant d'abord par %CHAR, cela fonctionne


- Si vous recevez les données lues par le biais de DS, vous utiliserez probablement des data-structures externes (EXTNAME ou LIKEREC)
- CCSID(*EXACT) demande à ce que les zones de la DS aient le même CCSID que le fichier d'origine
- Désormais, , vous pouvez enlever la conversion explicite lors des lectures
- OPENOPT(*NOCVTDATA), niveau spécif H ou ctl-opt, pour tous les fichiers
- DATA(*NOCVT), niveau spécif F ou déclaration de fichier (dcl-f), fichier par fichier
Exemple avec le pgm suivant

En débug RDI

En débug 5250

- CCSIDVT est nouveau Ctl-Opt ou en spécif H
- *LIST : indique les pertes potentielles de données lors de la compilation
- *EXCP : indique les pertes potentielles de données lors de l’exécution
- Et il y a des nouvelles directives de compilation en 7.2
- /SET permet de définir le CCSID (ou le format date/heure) à partir de cette ligne
- /SET CCSID(*CHAR : n°-de-ccsid)
- /SET CCSID(*GRAPH : n°-de-ccsid)
- /RESTORE, pour annuler le précédent /SET
- /SET permet de définir le CCSID (ou le format date/heure) à partir de cette ligne
- Enfin, web services
- Ce programme va être exposé en tant que web service REST

- Définition des paramètres

- Fichier swagger généré

- Résultat

- Ce programme va être exposé en tant que web service REST

{kind=link}